Skala HDInsight automatiskt på AKS-kluster
Storleken på alla kluster för att uppfylla jobbprestanda och hantera kostnader i förväg är alltid svårt och svårt att avgöra! En av de lukrativa fördelarna med att bygga Data Lake House över Molnet är dess elasticitet, vilket innebär att använda funktionen autoskalning för att maximera användningen av resurser till hands. Automatisk skalning med Kubernetes är en nyckel för att upprätta ett kostnadsoptimerad ekosystem. Med varierande användningsmönster i alla företag kan det finnas variationer i klusterbelastningar över tid som kan leda till att kluster underetableras (dåliga prestanda) eller överetableras (onödiga kostnader på grund av inaktiva resurser).
Autoskalningsfunktionen som erbjuds i HDInsight på AKS kan automatiskt öka eller minska antalet arbetsnoder i klustret. Automatisk skalning använder klustermått och skalningsprincip som används av kunderna.
Den här funktionen passar bra för verksamhetskritiska arbetsbelastningar, som kan ha
- Varierande eller oförutsägbara trafikmönster och kräver serviceavtal för höga prestanda och skalning eller
- Fördefinierat schema för att nödvändiga arbetsnoder ska vara tillgängliga för att köra jobben i klustret.
Automatisk skalning med HDInsight i AKS-kluster gör klustren kostnadseffektiva och elastiska i Azure.
Med automatisk skalning kan kunder skala ned kluster utan att påverka arbetsbelastningar. Den är aktiverad med avancerade funktioner som graciös inaktivering och kylningsperiod. Dessa funktioner gör det möjligt för användare att göra välgrundade val vid tillägg och borttagning av noder baserat på klustrets aktuella belastning.
Hur det fungerar
Den här funktionen fungerar genom att skala antalet noder inom förinställda gränser baserat på klustermått eller ett definierat schema för uppskalnings- och nedskalningsåtgärder. Det finns två typer av villkor för att utlösa autoskalningshändelser: tröskelvärdesbaserade utlösare för olika klusterprestandamått (kallas belastningsbaserad skalning) och tidsbaserade utlösare (kallas schemabaserad skalning).
Belastningsbaserad skalning ändrar antalet noder i klustret, inom ett intervall som du anger, för att säkerställa optimal CPU-användning och minimera driftskostnaderna.
Schemabaserad skalning ändrar antalet noder i klustret baserat på ett schema med uppskalnings- och nedskalningsåtgärder.
Kommentar
Automatisk skalning stöder inte ändring av SKU-typen för ett befintligt kluster.
Klusterkompatibilitet
I följande tabell beskrivs de klustertyper som är kompatibla med funktionen Automatisk skalning och vad som är tillgängligt eller planerat.
| Arbetsbelastning | Belastningsbaserad | Schemabaserat |
|---|---|---|
| Flink | Planerat | Ja |
| Trino | Ja** | Ja** |
| Spark | Ja** | Ja** |
**Graciös inaktivering kan konfigureras.
Skalningsmetoder
Schemabaserad skalning:
När dina jobb förväntas köras enligt fasta scheman och under en förutsägbar varaktighet eller när du förväntar dig låg användning under specifika tider på dagen Till exempel testa och utvecklar miljöer i jobb efter arbetstid och slut på dagen.
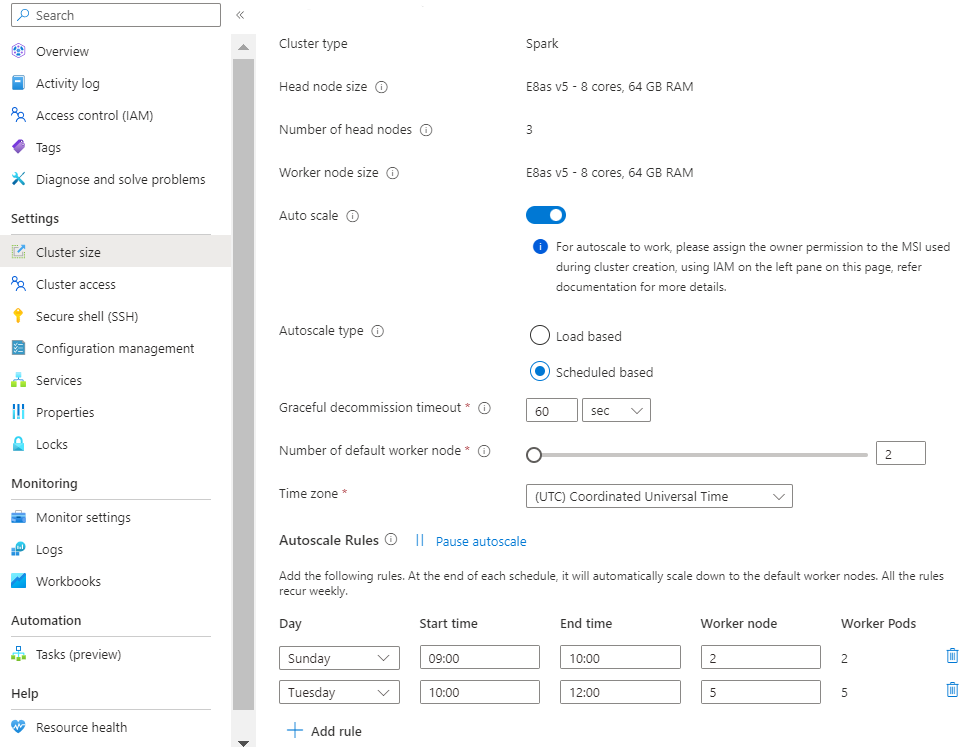
Belastningsbaserad skala:
När belastningsmönstren varierar avsevärt och oförutsägbart under dagen, till exempel orderdatabearbetning med slumpmässiga variationer i belastningsmönster baserat på olika faktorer.
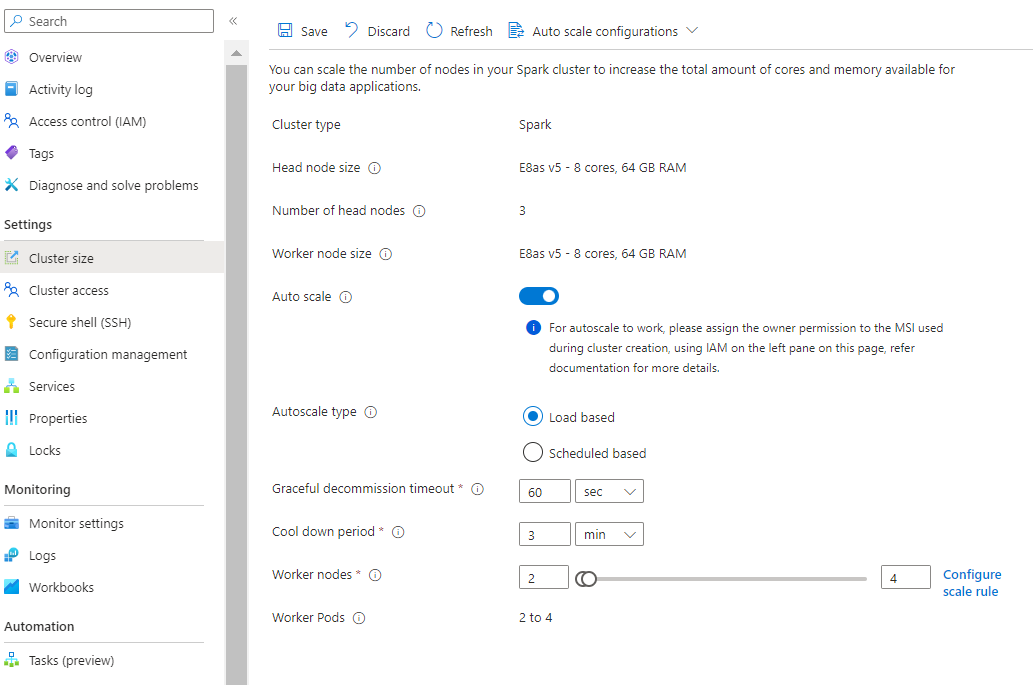
Med det nya, konfigurera skalningsregelalternativet kan du nu anpassa skalningsreglerna.
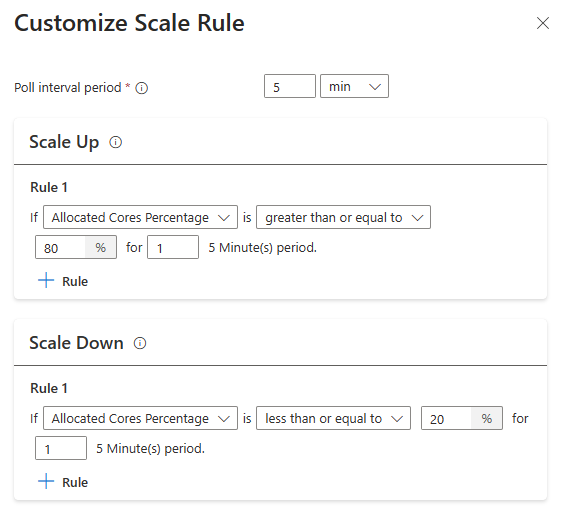
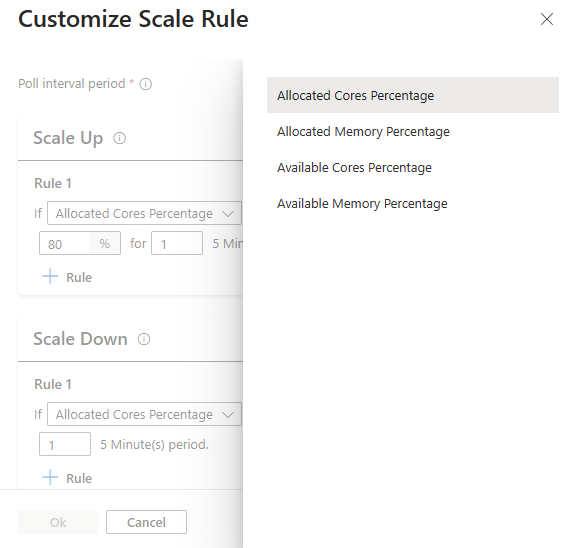
Dricks
- Uppskalningsregler har företräde när en eller flera regler utlöses. Även om bara en av reglerna för uppskalning tyder på att klustret är underetablerade försöker klustret skala upp. För att nedskalning ska ske ska ingen uppskalningsregel utlösas.


Belastningsbaserade skalningsvillkor
När följande villkor identifieras utfärdar automatisk skalning en skalningsbegäran
| Skala upp | Skala ned |
|---|---|
| Allokerade kärnor är större än 80 % för 5 minuters avsökningsintervall (1 minuts kontrollperiod) | Allokerade kärnor är mindre än eller lika med 20 % för 5 minuters avsökningsintervall (1 minuts kontrollperiod) |
Vid uppskalning utfärdar automatisk skalning en uppskalningsbegäran för att lägga till det nödvändiga antalet noder. Uppskalningen baseras på hur många nya arbetsnoder som behövs för att uppfylla de aktuella processor- och minneskraven. Det här värdet är begränsat till det maximala antalet arbetsnoder som angetts.
Vid nedskalning utfärdar automatisk skalning en begäran om att ta bort vissa noder. Övervägandena för nedskalning omfattar antalet poddar per nod, aktuella processor- och minneskrav och arbetsnoder, som är kandidater för borttagning baserat på aktuell jobbkörning. Skalningsåtgärden inaktiverar först noderna och tar sedan bort dem från klustret.
Viktigt!
Regelmotorn för automatisk skalning rensar proaktivt gamla händelser var 30:e minut för att optimera systemminnet. Därför finns det en övre gräns på 30 minuter för skalningsregelintervallet. För att säkerställa konsekvent och tillförlitlig utlösande av skalningsåtgärder är det absolut nödvändigt att ange skalningsregelintervallet till ett värde som är mindre än gränsen. Genom att följa den här riktlinjen kan du garantera en smidig och effektiv skalningsprocess samtidigt som du effektivt hanterar systemresurser.
Klustermått
Automatisk skalning övervakar klustret kontinuerligt och samlar in följande mått för belastningsbaserad autoskalning:
Klustermått som är tillgängliga för skalning
| Mätvärde | Beskrivning |
|---|---|
| Procentandel tillgängliga kärnor | Det totala antalet tillgängliga kärnor i klustret jämfört med det totala antalet kärnor i klustret. |
| Tillgängligt minne i procent | Det totala minnet (i MB) som är tillgängligt i klustret jämfört med den totala mängden minne i klustret. |
| Procent för allokerade kärnor | Det totala antalet kärnor som allokerats i klustret jämfört med det totala antalet kärnor i klustret. |
| Allokerat minne i procent | Mängden minne som allokeras i klustret jämfört med den totala mängden minne i klustret. |
Som standard kontrolleras ovanstående mått var 300:e sekund. Det kan också konfigureras när du anpassar avsökningsintervallet med alternativet anpassa autoskalning. Automatisk skalning fattar beslut om uppskalning eller nedskalning baserat på dessa mått.
Kommentar
Som standard använder automatisk skalning standardresurskalkylatorn för YARN för Apache Spark. Belastningsbaserad skalning är tillgänglig för Apache Spark-kluster.
Graciös avveckling
Företag behöver sätt att uppnå petabyteskalning med automatisk skalning och inaktivera resurser på ett smidigt sätt när de inte längre behövs. I ett sådant scenario är det praktiskt med en graciös inaktiveringsfunktion.
Med en korrekt inaktivering kan jobb slutföras även efter att autoskalning har utlöst avaktivering av arbetsnoderna. Med den här funktionen kan noder fortsätta att etableras tills jobben har slutförts.
Trino : Arbetare har en korrekt avaktivering aktiverad som standard. Med koordinatorn kan arbetstagaren avsluta sina uppgifter under en konfigurerad tid innan arbetaren tas bort från klustret. Du kan konfigurera tidsgränsen antingen med den interna Trino-parametern
shutdown.grace-periodeller på konfigurationssidan för Azure Portal-tjänsten.Apache Spark : Nedskalning kan påverka/stoppa alla jobb som körs i klustret. Om du aktiverar graceful Decommissioning-inställningar på Azure-portalen innehåller den en graciös avaktivering av YARN-noder och ser till att allt arbete som pågår på en arbetsnod är slutfört innan noden tas bort från HDInsight i AKS-klustret.
Nedkylningsperiod
För att undvika kontinuerliga uppskalningsåtgärder väntar autoskalningsmotorn på ett konfigurerbart intervall innan en annan uppsättning uppskalningsåtgärder initieras. Standardvärdet är inställt på 180 sekunder
Kommentar
- I anpassade skalningsregler kan ingen regelutlösare ha ett utlösarintervall som är större än 30 minuter. När en automatisk skalningshändelse inträffar kan det ta lång tid att vänta innan du tillämpar en annan skalningsprincip.
- Nedkylningsperioden bör vara större än principintervallet, så att klustermåtten kan återställas.
Kom igång
För att autoskalning ska fungera måste du tilldela behörigheten ägare eller deltagare till MSI (används när klustret skapas) på klusternivå med hjälp av IAM i den vänstra rutan.
Se följande bild och steg i listan över hur du lägger till rolltilldelning
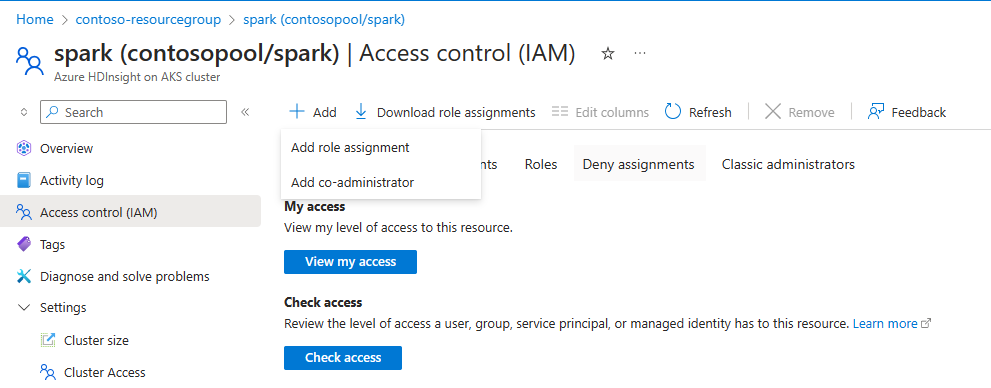
Välj Lägg till rolltilldelning,
- Tilldelningstyp: Privilegierade administratörsroller
- Roll: Ägare eller deltagare
- Medlemmar: Välj Hanterad identitet och välj den användartilldelade hanterade identiteten, som angavs under klusterskapandefasen.
- Tilldela rollen.

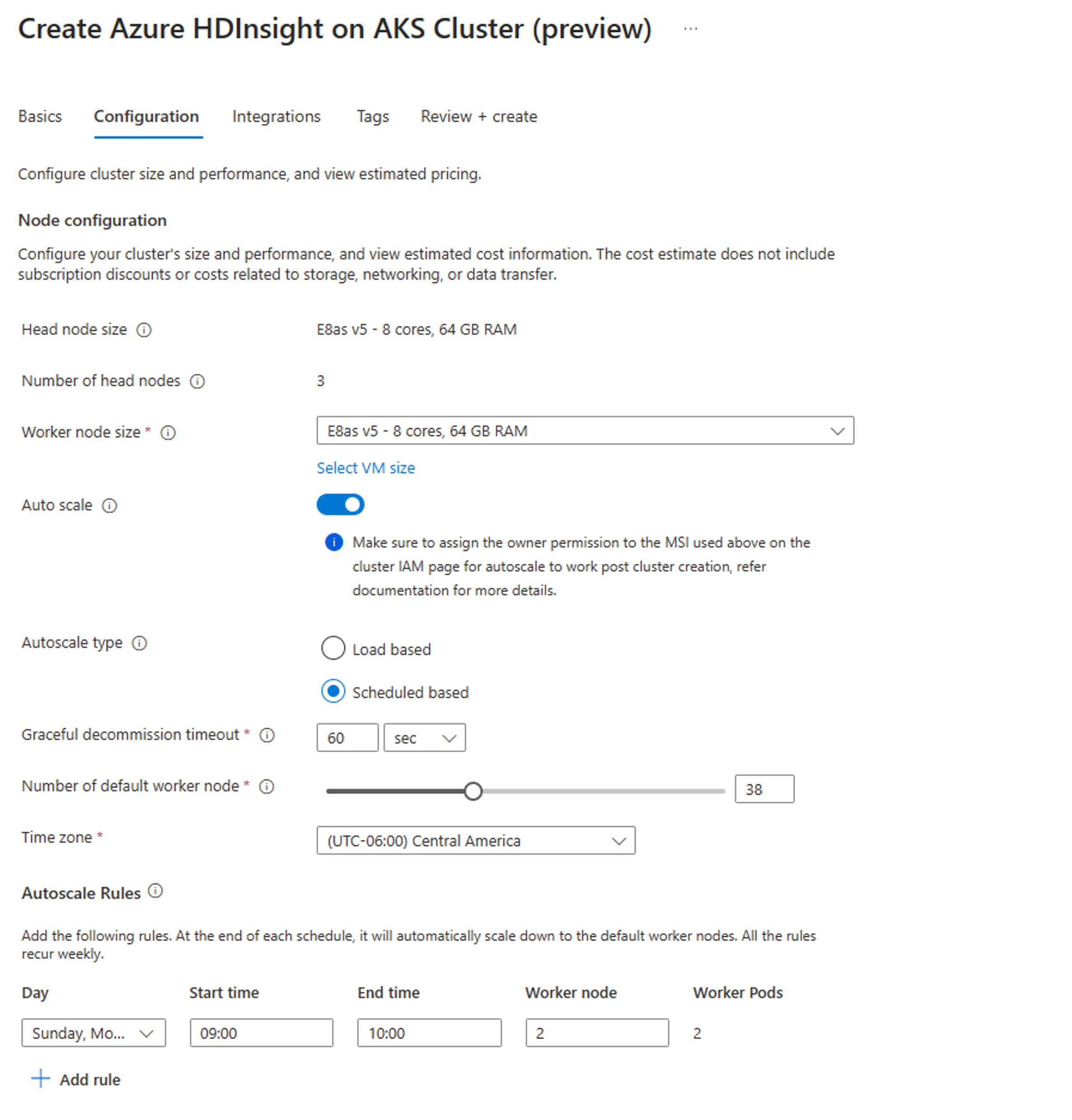
Skapa ett kluster med schemabaserad automatisk skalning
När klusterpoolen har skapats skapar du ett nytt kluster med önskad arbetsbelastning (på klustertypen) och slutför de andra stegen som en del av den normala processen för att skapa kluster.
På fliken Konfiguration aktiverar du växlingsknappen Automatisk skalning .
Välj Schemabaserad autoskalning
Välj tidszonen och klicka sedan på + Lägg till regel
Välj de veckodagar som det nya villkoret ska gälla för.
Redigera den tid villkoret ska börja gälla och antalet noder som klustret ska skalas till.
Kommentar
- Användaren bör ha rollen "ägare" eller "deltagare" i klustrets MSI för att autoskalning ska fungera.
- Standardvärdet definierar den ursprungliga storleken på klustret när det skapas.
- Skillnaden mellan två scheman är inställd på 30 minuter som standardvärde.
- Tidsvärdet följer 24-timmarsformatet
- Om ett kontinuerligt fönster är längre än 24 timmar över flera dagar måste du ange ett autoskalningsschema över dagar, och autoskalning förutsätter 23:59 som 00:00 (med samma antal noder) som sträcker sig över två dagar från 22:00 till 23:59, 00:00 till 02:00 som 22:00 till 02:00.
- Schemana anges som standard i Coordinated Universal Time (UTC). Du kan alltid uppdatera till tidszon som motsvarar din lokala tidszon i listrutan som är tillgänglig. När du befinner dig i en tidszon som observerar sommartid, justeras inte schemat automatiskt, du måste hantera schemauppdateringarna i enlighet med detta.

Skapa ett kluster med belastningsbaserad automatisk skalning
När klusterpoolen har skapats skapar du ett nytt kluster med önskad arbetsbelastning (på klustertypen) och slutför de andra stegen som en del av den normala processen för att skapa kluster.
På fliken Konfiguration aktiverar du växlingsknappen Automatisk skalning .
Välj Läs in baserad autoskalning
Baserat på typen av arbetsbelastning har du alternativ för att lägga till en respitfri timeout för avaktivering, nedkylningsperiod
Välj de minsta och högsta noderna och konfigurera vid behov skalningsreglerna för att anpassa automatisk skalning efter dina behov.

Dricks
- Din prenumeration har en kapacitetskvot för varje region. Det totala antalet kärnor i huvudnoderna och maximalt antal arbetsnoder får inte överskrida kapacitetskvoten. Den här kvoten är dock en mjuk gräns. Du kan alltid skapa ett supportärende så att det blir enklare att öka.
- Om du överskrider den totala kärnkvotgränsen får du ett felmeddelande om
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Uppskalningsregler har företräde när en eller flera regler utlöses. Även om bara en av reglerna för uppskalning tyder på att klustret är underetablerade försöker klustret skala upp. För att nedskalning ska ske ska ingen uppskalningsregel utlösas.
- I offentlig förhandsversion stöder HDInsight på AKS upp till 500 noder i ett kluster.

Skapa ett kluster med en Resource Manager-mall
Schemabaserad automatisk skalning
Du kan skapa en HDInsight på AKS-kluster med schemabaserad autoskalning med hjälp av en Azure Resource Manager-mall genom att lägga till en autoskalning i avsnittet clusterProfile –> autoscaleProfile.
Noden autoskalning innehåller en upprepning som har en tidszon och ett schema som beskriver när ändringen sker. En fullständig Resource Manager-mall finns i JSON-exempel
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Dricks
- Du måste ange scheman som inte är i konflikt med ARM-distributioner för att undvika skalningsfel.
Belastningsbaserad automatisk skalning
Du kan skapa en HDInsight på AKS-kluster med belastningsbaserad autoskalning med hjälp av en Azure Resource Manager-mall genom att lägga till en autoskalning i avsnittet clusterProfile –> autoscaleProfile.
Noden autoskalning innehåller
- ett avsökningsintervall, nedkylningsperiod,
- graciös avveckling,
- minsta och högsta noder.
- standardtröskelregler,
- skalningsmått som beskriver när ändringen sker.
En fullständig Resource Manager-mall finns i JSON-exempel på följande sätt
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Använda REST API
Om du vill aktivera eller inaktivera automatisk skalning i ett kluster som körs med hjälp av REST-API:et gör du en PATCH-begäran till slutpunkten för automatisk skalning: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Använd lämpliga parametrar i nyttolasten för begäran. Json-nyttolasten kan användas för att aktivera automatisk skalning.
- Använd nyttolasten (autoscaleProfile: null) eller använd flaggan (aktiverad, false) för att inaktivera automatisk skalning.
- Referens finns i JSON-exemplen som nämns i ovanstående steg.
Pausa automatisk skalning för ett kluster som körs
Vi har introducerat pausfunktionen i automatisk skalning. Med hjälp av Azure-portalen kan du nu pausa automatisk skalning i ett kluster som körs. Diagrammet nedan visar hur du väljer pausa och återuppta autoskalning

Du kan återuppta när du vill återuppta autoskalningsåtgärderna.

Dricks
När du konfigurerar flera scheman och pausar autoskalningen utlöser det inte nästa schema. Antalet noder förblir detsamma, även om noderna är i ett inaktiverat tillstånd.
Kopiera konfigurationer för automatisk skalning
Med hjälp av Azure-portalen kan du nu kopiera samma autoskalningskonfigurationer för samma klusterform i klusterpoolen. Du kan använda den här funktionen och exportera eller importera samma konfigurationer.

Övervaka aktiviteter för automatisk skalning
Klusterstatus
Klusterstatusen i Azure-portalen kan hjälpa dig att övervaka aktiviteter för automatisk skalning. Alla klusterstatusmeddelanden som du kan se förklaras i listan.
| Klusterstatus | beskrivning |
|---|---|
| Lyckades | Klustret fungerar normalt. Alla tidigare aktiviteter för automatisk skalning har slutförts. |
| Har godkänts | Klusteråtgärden (till exempel uppskalning) godkänns i väntan på att åtgärden ska slutföras. |
| Misslyckad | Det innebär att en aktuell åtgärd misslyckades på grund av någon anledning, klustret kanske inte fungerar. |
| Avbruten | Den aktuella åtgärden har avbrutits. |
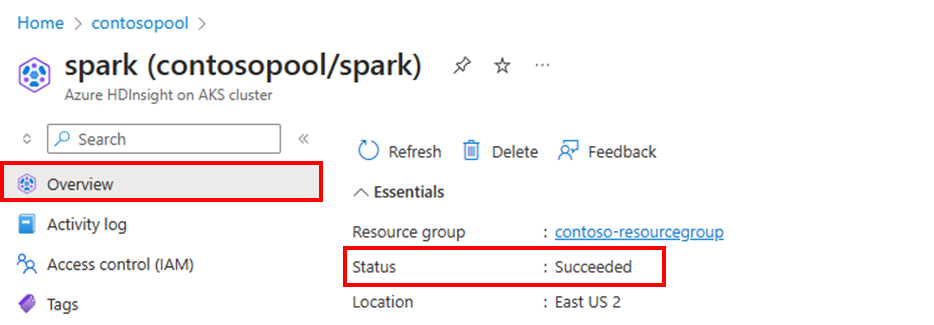
Om du vill visa det aktuella antalet noder i klustret går du till diagrammet Klusterstorlek på sidan Översikt för klustret.

Åtgärdshistorik
Du kan visa historiken för klusterskalning och nedskalning som en del av klustermåtten. Du kan också visa en lista över alla skalningsåtgärder under den senaste dagen, veckan eller andra perioder.

Ytterligare resurser
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för