Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer om i det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i generell tillgänglighet. Information om den här specifika förhandsversionen finns i förhandsversionsinformationen för Azure HDInsight på AKS. För frågor eller funktionsförslag, skicka en begäran på AskHDInsight med detaljerna och följ oss för fler uppdateringar om Azure HDInsight Community.
Det är viktigt att dela data och metaarkiv över flera tjänster. Ett av de vanligt använda metastore i Hive-metastore. HDInsight på AKS gör det möjligt för användare att ansluta till externt metaarkiv. Det här steget gör det möjligt för HDInsight-användare att sömlöst ansluta till andra tjänster i ekosystemet.
Azure HDInsight på AKS stöder anpassade metadatabutiker, som rekommenderas för användning i produktionskluster. De viktigaste stegen är
- Skapa Azure SQL-databas
- Skapa ett nyckelvalv för att lagra autentiseringsuppgifterna
- Konfigurera metaarkiv när du skapar en HDInsight på AKS-kluster med Apache Spark™
- Arbeta på externt metadatalager (Visar databaser och gör en begränsad selektion med 1).
När du skapar klustret måste HDInsight-tjänsten ansluta till det externa metaarkivet och verifiera dina autentiseringsuppgifter.
Skapa Azure SQL-databas
Skapa eller ha en befintlig Azure SQL Database innan du konfigurerar ett anpassat Hive-metaarkiv för ett HDInsight-kluster.
Notis
För närvarande stöder vi endast Azure SQL Database for HIVE-metaarkiv. På grund av Hive-begränsning stöds inte "-" (bindestreck) i metaarkivdatabasens namn.
Skapa ett nyckelvalv för att lagra autentiseringsuppgifterna
Skapa ett Azure Key Vault.
Syftet med Key Vault är att du ska kunna lagra sql Server-administratörslösenordet som angavs när SQL-databasen skapades. HDInsight på AKS-plattformen hanterar inte autentiseringsuppgifterna direkt. Därför är det nödvändigt att lagra dina viktiga autentiseringsuppgifter i Azure Key Vault. Lär dig stegen för att skapa ett Azure Key Vault.
Tilldela följande roller efter skapandet av Azure Key Vault
Objekt Roll Anmärkningar Användartilldelad hanterad identitet (samma UAMI som används av HDInsight-klustret) Användare av Nyckelvalvets hemligheter Lär dig hur du tilldelar roll till UAMI Användare (som skapar hemlighet i Azure Key Vault) Key Vault-administratör Lär dig hur du Tilldela rollen till användaren. Notis
Utan den här rollen kan användaren inte skapa en hemlighet.
-
Med det här steget kan du behålla ditt SQL Server-administratörslösenord som en hemlighet i Azure Key Vault. Lägg till ditt lösenord (samma lösenord som anges i SQL DB för administratör) i fältet "Värde" när du lägger till en hemlighet.
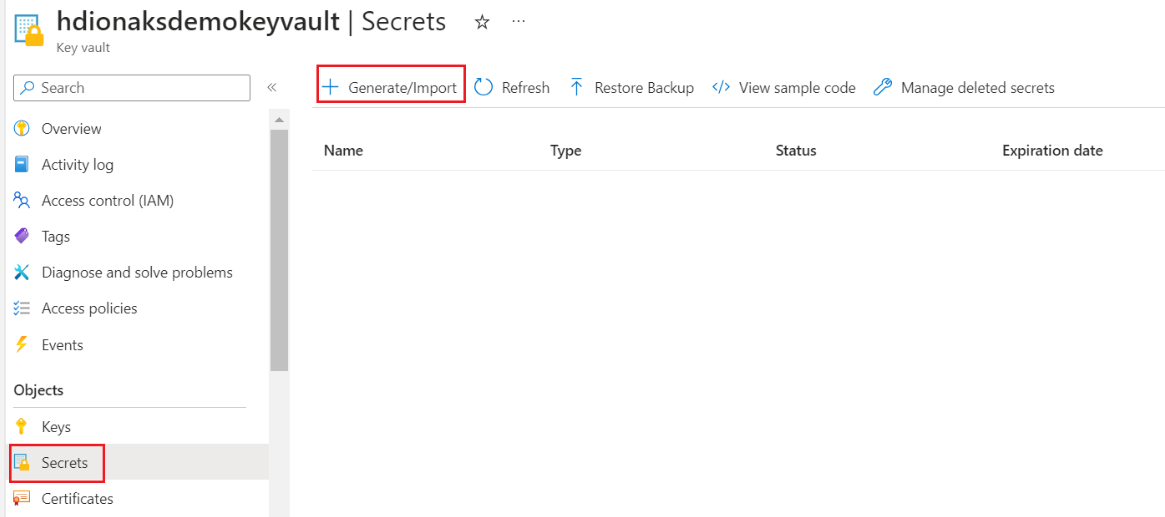
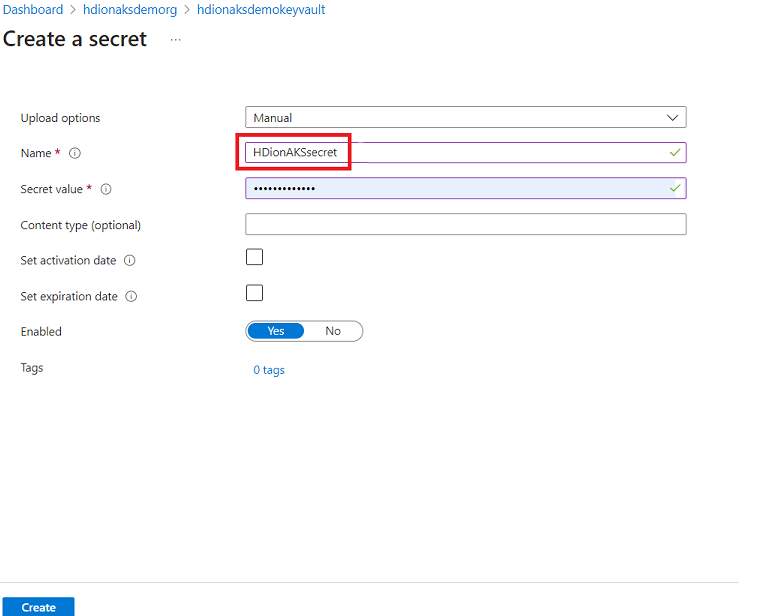
Notis
Observera det hemliga namnet eftersom du behöver det när klustret skapas.


Konfigurera metaarkiv när du skapar ett HDInsight Spark-kluster
Gå till HDInsight i AKS-klusterpoolen för att skapa kluster.
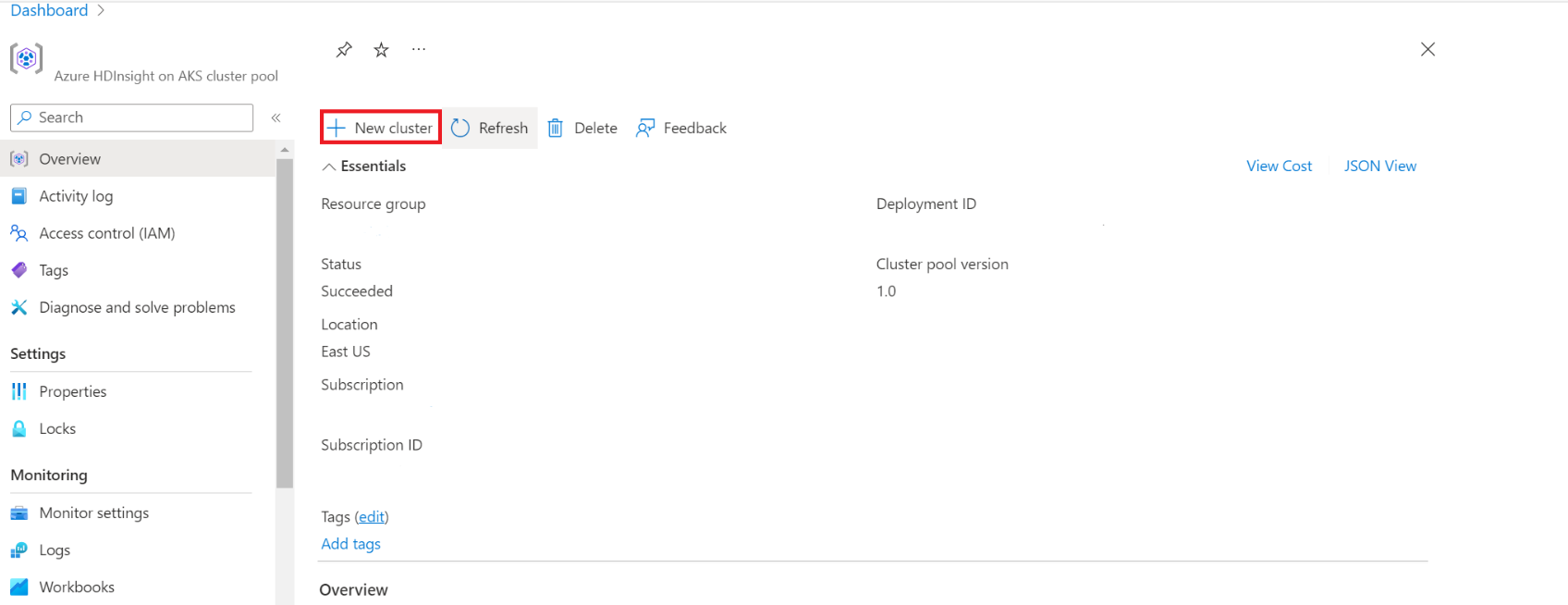
Aktivera växlingsknappen för att lägga till externt hive-metaarkiv och fyll i följande information.

Resten av informationen ska fyllas i enligt reglerna för att skapa kluster för Apache Spark-kluster i HDInsight på AKS.
Klicka på Granska och skapa.
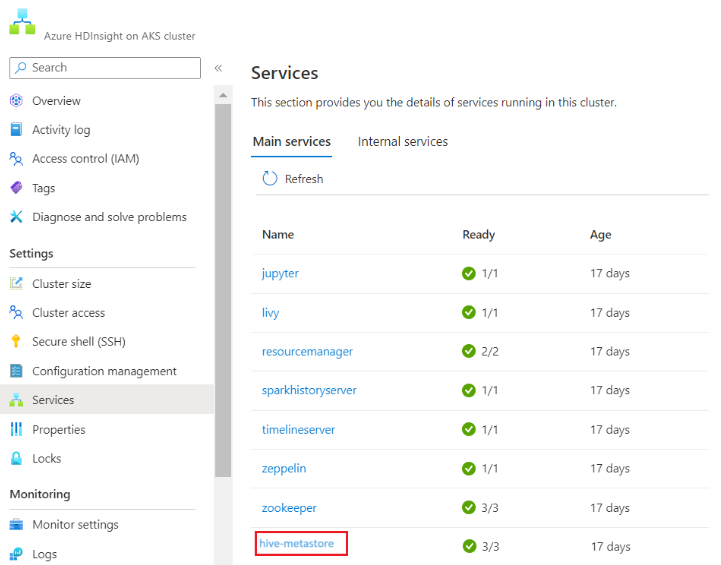
Notis
- Livscykeln för metaarkivet är inte kopplad till en klusterlivscykel, så du kan skapa och ta bort kluster utan att förlora metadata. Metadata som dina Hive-scheman bevaras även efter att du har tagit bort och återskapat HDInsight-klustret.
- Med ett anpassat metaarkiv kan du koppla flera kluster och klustertyper till metaarkivet.



Arbeta med externt metaarkiv
Skapa en tabell
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")
Lägga till data i tabellen
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Läs tabellen
>> spark.sql("select * from sampleTable").show()



Hänvisning
- Apache, Apache Spark, Spark och associerade projektnamn med öppen källkod är varumärken av Apache Software Foundation (ASF).