Felsöka Apache Hadoop HDFS med Azure HDInsight
Lär dig de vanligaste problemen och lösningarna när du arbetar med Hadoop Distributed File System (HDFS). En fullständig lista över kommandon finns i guiden för HDFS-kommandon och filsystemgränssnittsguiden.
Hur gör jag för att komma åt den lokala HDFS-filen inifrån ett kluster?
Problem
Få åtkomst till den lokala HDFS från kommandoraden och programkoden i stället för med hjälp av Azure Blob Storage eller Azure Data Lake Storage inifrån HDInsight-klustret.
Steg
I kommandotolken använder du
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...bokstavligen, som i följande kommando:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userFrån källkoden använder du URI
hdfs://mycluster/:n bokstavligen, som i följande exempelprogram:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Kör den kompilerade .jar -filen (till exempel en fil med namnet
java-unit-tests-1.0.jar) i HDInsight-klustret med följande kommando:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Lagringsfel för skrivning på blob
Problem
När du använder hadoop kommandona eller hdfs dfs för att skriva filer som är ~12 GB eller större i ett HBase-kluster kan du stöta på följande fel:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Orsak
HBase i HDInsight-kluster är som standard en blockstorlek på 256 kB när du skriver till Azure Storage. Även om det fungerar för HBase-API:er eller REST-API:er resulterar det i ett fel när du använder kommandoradsverktygen hadoop eller hdfs dfs .
Åtgärd
Använd fs.azure.write.request.size för att ange en större blockstorlek. Du kan göra den här ändringen per användning med hjälp av parametern -D . Följande kommando är ett exempel med den här parametern hadoop med kommandot :
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
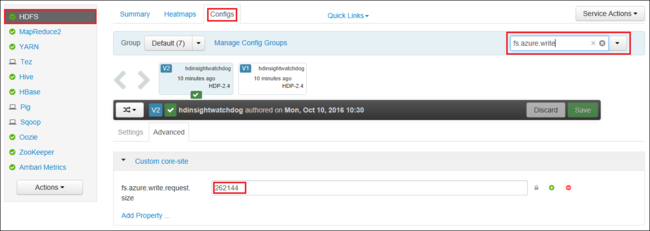
Du kan också öka värdet fs.azure.write.request.size för globalt med hjälp av Apache Ambari. Följande steg kan användas för att ändra värdet i webbgränssnittet för Ambari:
I webbläsaren går du till Ambari-webbgränssnittet för klustret. URL:en är
https://CLUSTERNAME.azurehdinsight.net, därCLUSTERNAMEär namnet på klustret. När du uppmanas till det anger du administratörsnamnet och lösenordet för klustret.Välj HDFS till vänster på skärmen och välj sedan fliken Konfigurationer.
I fältet Filter... anger du
fs.azure.write.request.size.Ändra värdet från 262144 (256 KB) till det nya värdet. Till exempel 4194304 (4 MB).
Mer information om hur du använder Ambari finns i Hantera HDInsight-kluster med apache Ambari-webbgränssnittet.
du du
Kommandot -du visar storlekar på filer och kataloger som finns i den angivna katalogen eller längden på en fil om det bara är en fil.
Alternativet -s ger en aggregerad sammanfattning av fillängder som visas.
Alternativet -h formaterar filstorlekarna.
Exempel:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
Rm
Kommandot -rm tar bort filer som angetts som argument.
Exempel:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Nästa steg
Om du inte ser problemet eller inte kan lösa problemet går du till någon av följande kanaler för mer support:
Få svar från Azure-experter via Azure Community Support.
Anslut med @AzureSupport – det officiella Microsoft Azure-kontot för att förbättra kundupplevelsen. Anslut azure-communityn till rätt resurser: svar, support och experter.
Om du behöver mer hjälp kan du skicka en supportbegäran från Azure-portalen. Välj Support i menyraden eller öppna hubben Hjälp + support . Mer detaljerad information finns i Skapa en Azure-supportbegäran. Tillgång till support för prenumerationshantering och fakturering ingår i din Microsoft Azure-prenumeration och teknisk support ges via ett supportavtal för Azure.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för