Felsöka Apache Hadoop YARN med Azure HDInsight
Lär dig mer om de viktigaste problemen och deras lösningar när du arbetar med Apache Hadoop YARN-nyttolaster i Apache Ambari.
Hur gör jag för att skapa en ny YARN-kö i ett kluster?
Steg
Använd följande steg i Ambari för att skapa en ny YARN-kö och balansera kapacitetsallokeringen mellan alla köer.
I det här exemplet ändras två befintliga köer (standard och thriftsvr) från 50 % kapacitet till 25 % kapacitet, vilket ger den nya kön (spark) 50 % kapacitet.
| Queue | Kapacitet | Maximal kapacitet |
|---|---|---|
| standard | 25 % | 50 % |
| thrftsvr | 25 % | 50 % |
| spark | 50 % | 50 % |
Välj ikonen Ambari-vyer och välj sedan rutnätsmönstret. Välj sedan YARN Queue Manager.
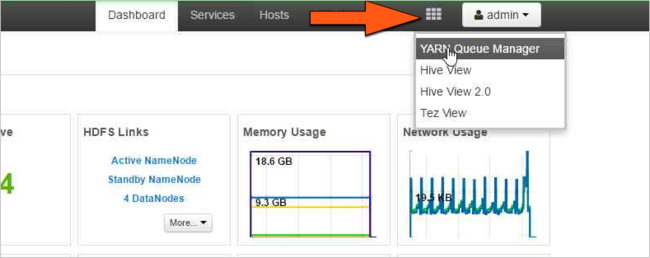
Välj standardkön.
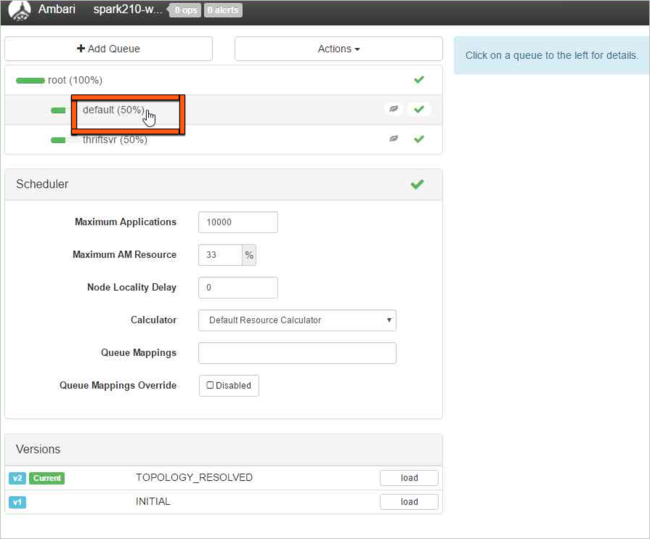
För standardkön ändrar du kapaciteten från 50 % till 25 %. För thriftsvr-kön ändrar du kapaciteten till 25 %.
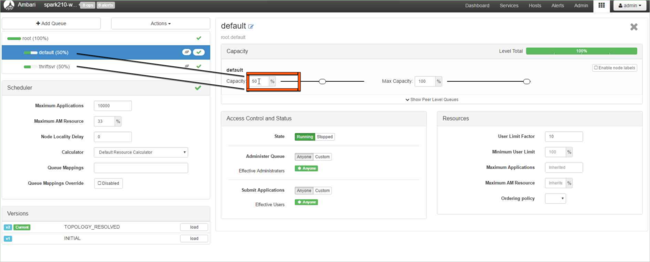
Om du vill skapa en ny kö väljer du Lägg till kö.
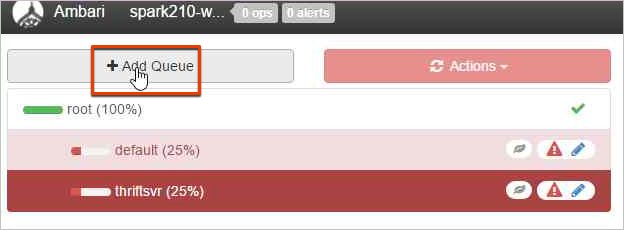
Namnge den nya kön.
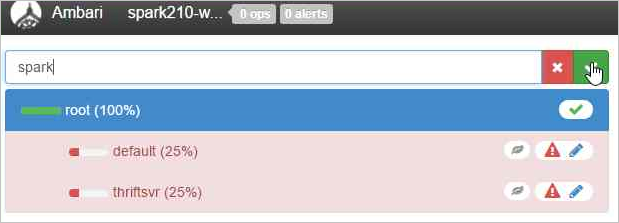
Låt kapacitetsvärdena vara 50 % och välj sedan knappen Åtgärder.
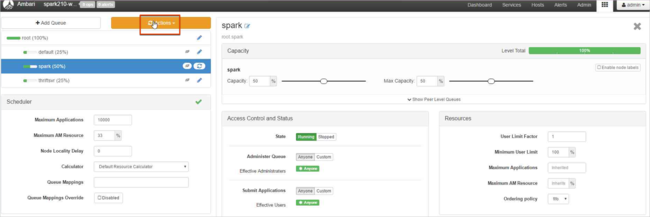
Välj Spara och uppdatera köer.
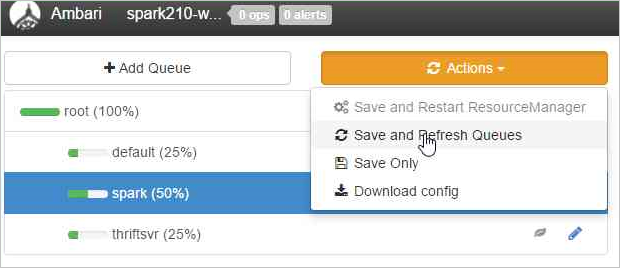
Dessa ändringar visas direkt i YARN Scheduler-användargränssnittet.
Ytterligare läsning
Hur gör jag för att ladda ned YARN-loggar från ett kluster?
Steg
Anslut till HDInsight-klustret med hjälp av en SSH-klient (Secure Shell). Mer information finns i Ytterligare läsning.
Kör följande kommando för att visa en lista över alla program-ID:t för YARN-programmen som körs:
yarn topID:na visas i kolumnen APPLICATIONID . Du kan ladda ned loggar från kolumnen APPLICATIONID .
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerOm du vill ladda ned YARN-containerloggar för alla programhanterare använder du följande kommando:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtDet här kommandot skapar en loggfil med namnet amlogs.txt.
Om du bara vill ladda ned YARN-containerloggar för den senaste programhanteraren använder du följande kommando:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtDet här kommandot skapar en loggfil med namnet latestamlogs.txt.
Om du vill ladda ned YARN-containerloggar för de två första programbakgrunderna använder du följande kommando:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtDet här kommandot skapar en loggfil med namnet first2amlogs.txt.
Om du vill ladda ned alla YARN-containerloggar använder du följande kommando:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtDet här kommandot skapar en loggfil med namnet logs.txt.
Om du vill ladda ned YARN-containerloggen för en specifik container använder du följande kommando:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtDet här kommandot skapar en loggfil med namnet containerlogs.txt.
Mer att läsa
Hur gör jag för att kontrollera information om yarnprogramdiagnostik?
Diagnostik i Yarn-användargränssnittet är en funktion som gör att du kan visa status och loggar för dina program som körs på Yarn. Diagnostik kan hjälpa dig att felsöka och felsöka dina program samt övervaka deras prestanda och resursanvändning.
Om du vill visa diagnostiken för ett visst program kan du klicka på program-ID:t i programlistan. På sidan programinformation kan du också se en lista över alla försök som har gjorts för att köra programmet. Du kan klicka på alla försök att se mer information, till exempel försöks-ID, container-ID, nod-ID, starttid, sluttid och diagnostik
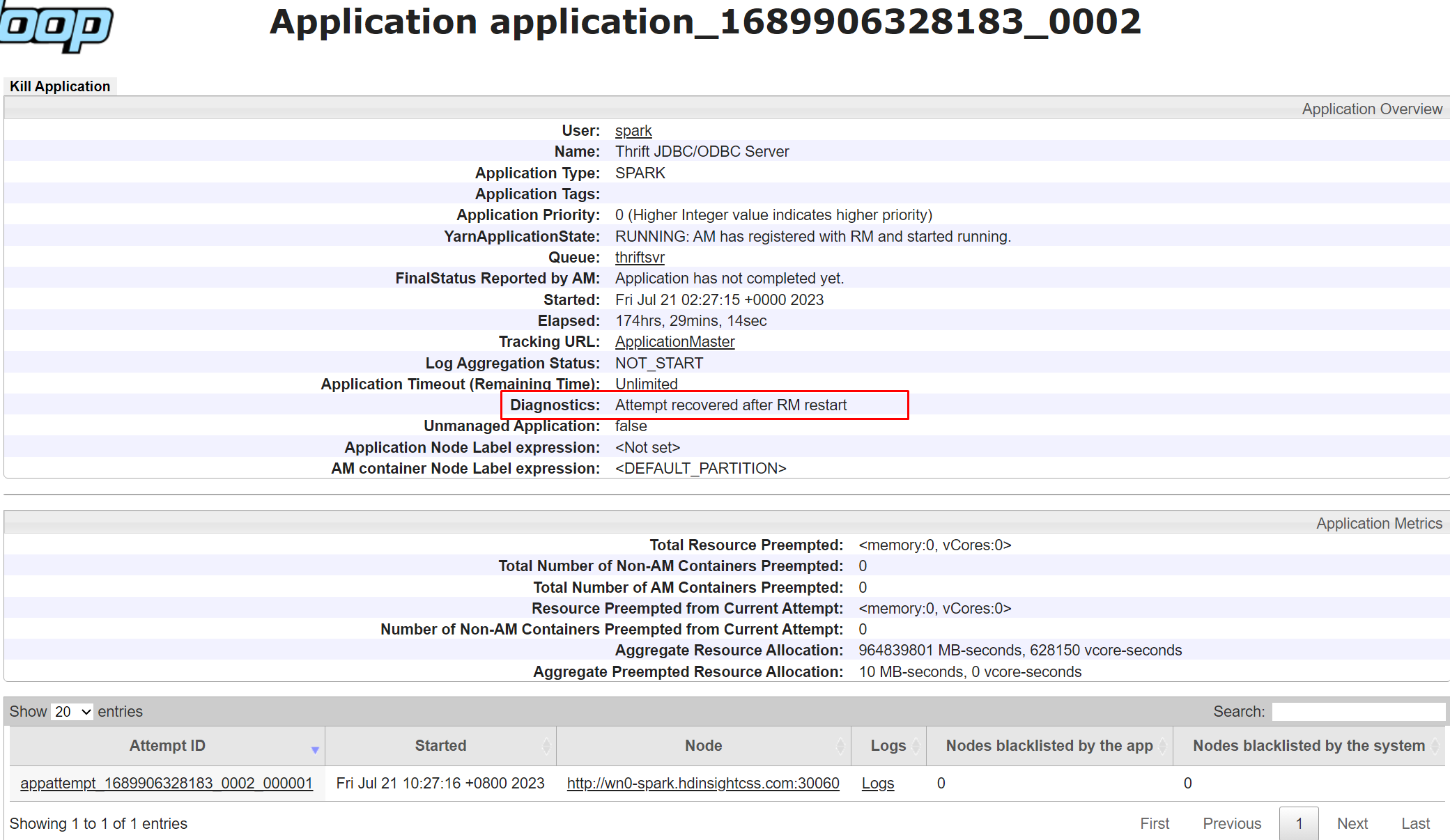
Hur gör jag för att felsöka vanliga YARN-problem?
Yarn-användargränssnittet läses inte in
Om yarn-användargränssnittet inte läses in eller inte kan nås och det returnerar "HTTP-fel 502.3 – felaktig gateway" betyder det starkt att Resource Manager-tjänsten inte är felfri. Åtgärda problemet genom att följa de här stegen:
- Gå till Ambari UI>YARN>SUMMARY och kontrollera om endast den aktiva Resource Manager är i tillståndet Startad. Om inte, försök att minimera genom att starta om den felaktiga eller stoppade Resource Manager.
- Om steg 1 inte löser problemet, SSH den aktiva Resource Manager-huvudnoden och kontrollera skräpinsamlingsstatusen med hjälp av
jstat -gcutil <Resource Manager pid> 1000 100. Om du ser att FGCT ökar avsevärt på bara några sekunder indikerar det att Resource Manager är upptaget i fullständig GC och inte kan bearbeta de andra begärandena. - Gå till Ambari-gränssnittet>YARN>CONFIGS>Advanced och öka
Resource Manager java heap size. - Starta om de tjänster som behövs i Ambari.
Båda resurshanterarna är i vänteläge
- Kontrollera Resource Manager-loggen för att se om liknande fel finns.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Om felet finns kontrollerar du om vissa filer är under replikering eller om det saknas block i HDFS. Du kan köra
hdfs fsck hdfs://mycluster/Kör
hdfs fsck hdfs://mycluster/ -deleteför kraftfullt rensa HDFS och för att bli av med rm-problemet i vänteläge. Du kan också köra PatchYarnNodeLabel på en av huvudnoderna för att korrigera klustret.
Nästa steg
Om du inte ser problemet eller inte kan lösa problemet går du till någon av följande kanaler för mer support:
Få svar från Azure-experter via Azure Community Support.
Anslut med @AzureSupport – det officiella Microsoft Azure-kontot för att förbättra kundupplevelsen. Anslut azure-communityn till rätt resurser: svar, support och experter.
Om du behöver mer hjälp kan du skicka en supportbegäran från Azure-portalen. Välj Support i menyraden eller öppna hubben Hjälp + support . Mer detaljerad information finns i Skapa en Azure-supportbegäran. Tillgång till support för prenumerationshantering och fakturering ingår i din Microsoft Azure-prenumeration och teknisk support ges via ett supportavtal för Azure.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för