Använda extern metadatalagring i Azure HDInsight
Viktigt!
Standardmetaarkivet tillhandahåller en Azure SQL Database på grundläggande nivå med endast 5 DTU och 2 GB data maxstorlek (INTE UPPGRADERINGSBAR)! Använd endast detta för kvalitetskontroll och testning. För produktion eller stora arbetsbelastningar rekommenderar vi att du migrerar till ett externt metaarkiv.
Med HDInsight kan du ta kontroll över dina data och metadata med externa datalager. Den här funktionen är tillgänglig för Apache Hive-metaarkiv, Apache Oozie-metaarkiv och Apache Ambari-databas.
Apache Hive-metaarkivet i HDInsight är en viktig del av Apache Hadoop-arkitekturen. Ett metaarkiv är den centrala schemalagringsplatsen. Metaarkivet används av andra stordataåtkomstverktyg som Apache Spark, Interactive Query (LLAP), Presto eller Apache Pig. HDInsight använder en Azure SQL Database som Hive-metaarkiv.
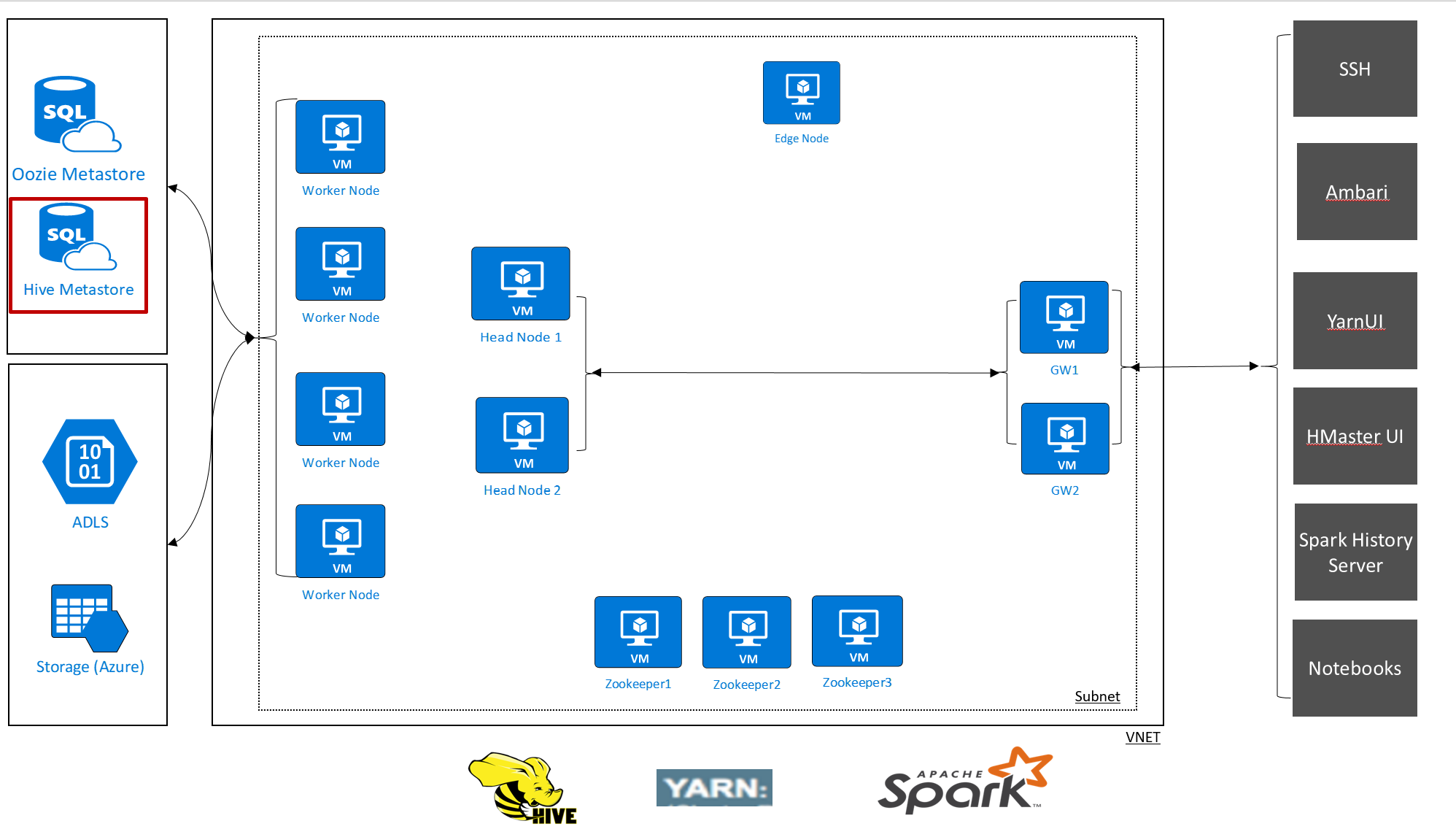
Det finns två sätt att konfigurera ett metaarkiv för dina HDInsight-kluster:
Standardmetaarkiv
Som standard skapar HDInsight ett metaarkiv med varje klustertyp. Du kan i stället ange ett anpassat metaarkiv. Standardmetaarkivet innehåller följande överväganden:
Begränsade resurser. Se meddelande överst på sidan.
Ingen extra kostnad. HDInsight skapar ett metaarkiv med varje klustertyp utan extra kostnad för dig.
Standardmetaarkivet är en del av klusterlivscykeln. När du tar bort ett kluster tas även motsvarande metaarkiv och metadata bort.
Standardmetaarkivet rekommenderas endast för enkla arbetsbelastningar. Arbetsbelastningar som inte kräver flera kluster och inte behöver metadata som bevaras utanför klustrets livscykel.
Standardmetaarkivet kan inte delas med andra kluster.
Anpassat metaarkiv
HDInsight har också stöd för anpassade metaarkiv, som rekommenderas för produktionskluster:
Du anger din egen Azure SQL Database som metaarkiv.
Livscykeln för metaarkivet är inte kopplad till en klusterlivscykel, så du kan skapa och ta bort kluster utan att förlora metadata. Metadata som dina Hive-scheman bevaras även efter att du har tagit bort och återskapat HDInsight-klustret.
Med ett anpassat metaarkiv kan du koppla flera kluster och klustertyper till metaarkivet. Till exempel kan ett enda metaarkiv delas mellan interaktiva fråge-, Hive- och Spark-kluster i HDInsight.
Du betalar för kostnaden för ett metaarkiv (Azure SQL Database) enligt den prestandanivå du väljer.
Du kan skala upp metaarkivet efter behov.
Klustret och det externa metaarkivet måste finnas i samma region.
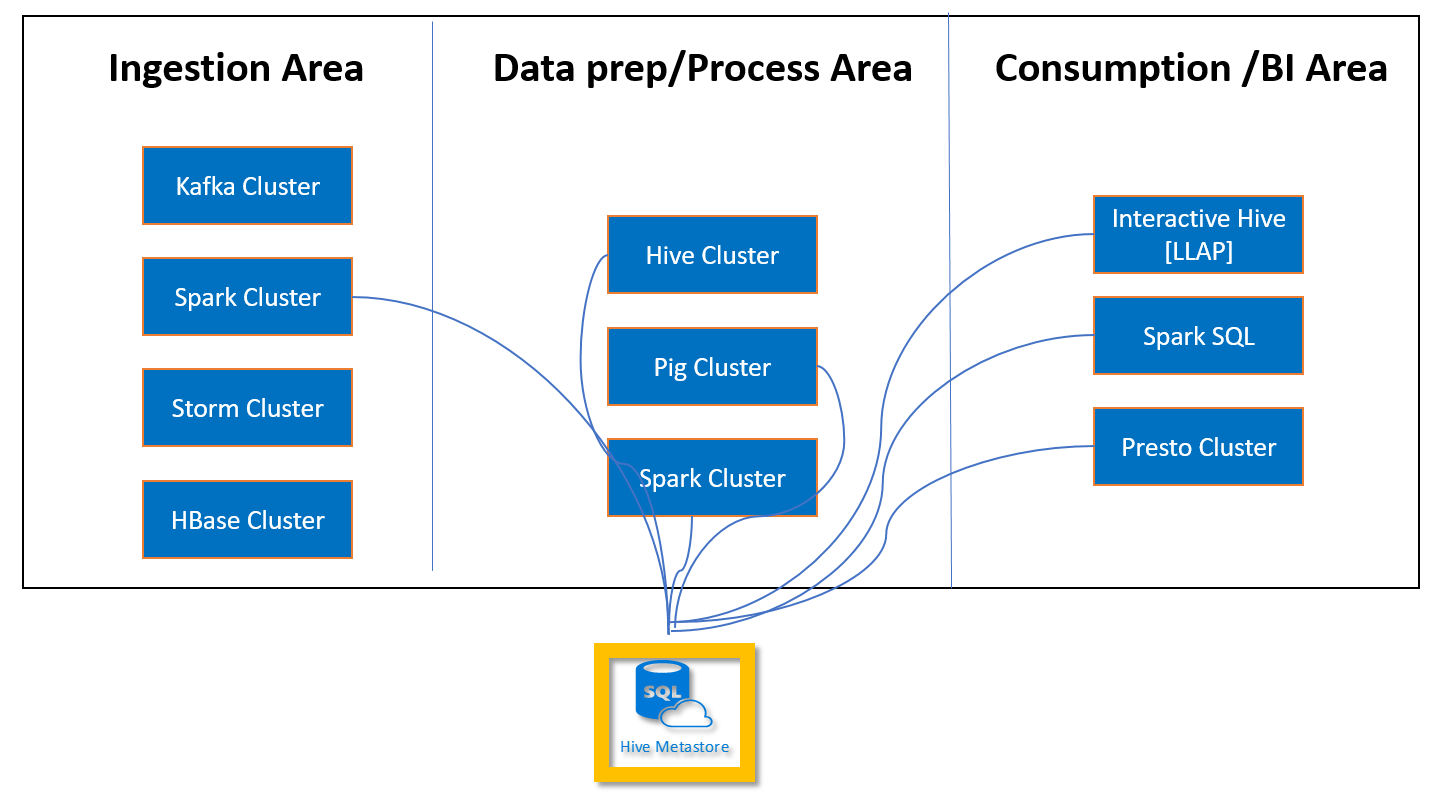
Skapa och konfigurera Azure SQL Database för det anpassade metaarkivet
Skapa eller ha en befintlig Azure SQL Database innan du konfigurerar ett anpassat Hive-metaarkiv för ett HDInsight-kluster. Mer information finns i Snabbstart: Skapa en enkel databas i Azure SQL Database.
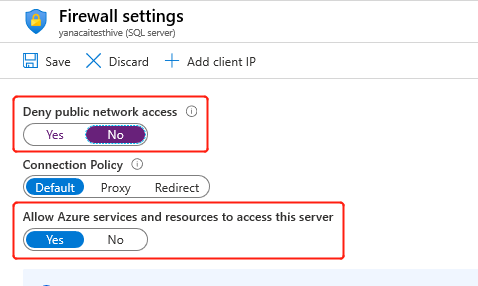
När du skapar klustret måste HDInsight-tjänsten ansluta till det externa metaarkivet och verifiera dina autentiseringsuppgifter. Konfigurera Azure SQL Database-brandväggsregler så att Azure-tjänster och resurser får åtkomst till servern. Aktivera det här alternativet i Azure-portalen genom att välja Ange serverbrandvägg. Välj sedan Nej under Neka åtkomst till offentligt nätverk och Ja under Tillåt Azure-tjänster och resurser att komma åt den här servern för Azure SQL Database. Mer information finns i Skapa och hantera IP-brandväggsregler
Privata slutpunkter för SQL-butiker stöds endast i de kluster som skapats med outbound ResourceProviderConnection. Mer information finns i den här dokumentationen.

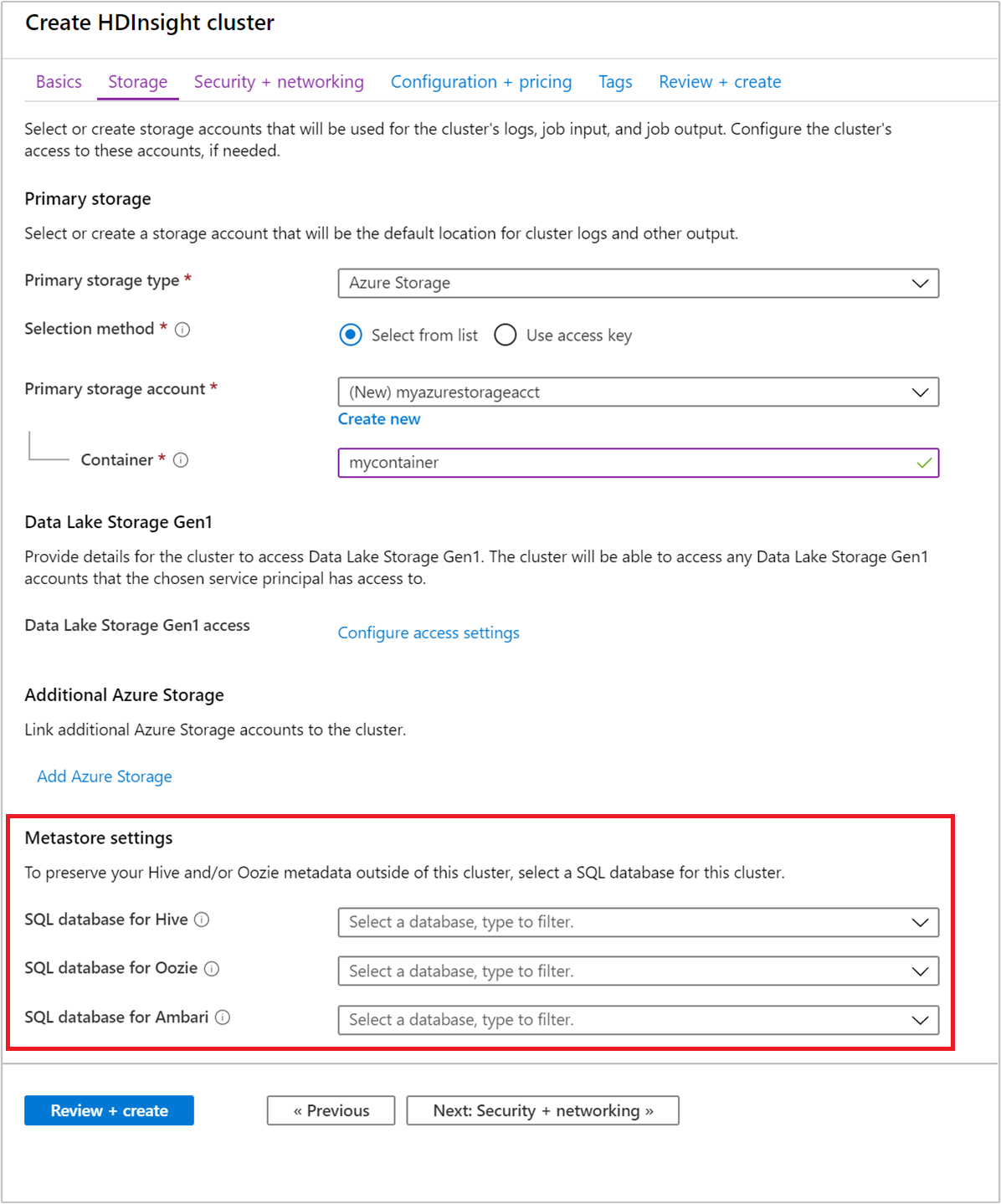
Välj ett anpassat metaarkiv när klustret skapas
Du kan när som helst peka klustret till en tidigare skapad Azure SQL Database. För att skapa kluster via portalen anges alternativet från inställningarna för Lagringsmetaarkiv>.
Riktlinjer för Apache Hive-metaarkiv
Kommentar
Använd ett anpassat metaarkiv när det är möjligt för att separera beräkningsresurser (ditt kluster som körs) och metadata (lagras i metaarkivet). Börja med S2-nivån, som tillhandahåller 50 DTU och 250 GB lagringsutrymme. Om du ser en flaskhals kan du skala upp databasen.
Om du vill att flera HDInsight-kluster ska komma åt separata data använder du en separat databas för metaarkivet i varje kluster. Om du delar ett metaarkiv i flera HDInsight-kluster innebär det att klustren använder samma metadata och underliggande användardatafiler.
Säkerhetskopiera ditt anpassade metaarkiv med jämna mellanrum. Azure SQL Database genererar säkerhetskopieringar automatiskt, men tidsramen för kvarhållning av säkerhetskopior varierar. Mer information finns i Läs mer om automatisk säkerhetskopiering av SQL databaser.
Leta upp ditt metaarkiv och HDInsight-kluster i samma region. Den här konfigurationen ger högsta prestanda och lägsta utgående nätverksavgifter.
Övervaka ditt metaarkiv för prestanda och tillgänglighet med hjälp av Azure SQL Database Monitoring-verktyg eller Azure Monitor-loggar.
När en ny, högre version av Azure HDInsight skapas mot en befintlig anpassad metaarkivdatabas uppgraderar systemet schemat för metaarkivet. Uppgraderingen går inte att ångra utan att återställa databasen från säkerhetskopian.
Om du delar ett metaarkiv mellan flera kluster kontrollerar du att alla kluster är samma HDInsight-version. Olika Hive-versioner använder olika metaarkivdatabasscheman. Du kan till exempel inte dela ett metaarkiv i hive 2.1- och Hive 3.1-versionskluster.
I HDInsight 4.0 använder Spark och Hive oberoende kataloger för åtkomst till SparkSQL- eller Hive-tabeller. En tabell som skapats av Spark finns i Spark-katalogen. En tabell som skapats av Hive finns i Hive-katalogen. Det här beteendet skiljer sig från HDInsight 3.6 där Hive och Spark delade gemensam katalog. Hive- och Spark-integrering i HDInsight 4.0 förlitar sig på Hive Warehouse Connector (HWC). HWC fungerar som en brygga mellan Spark och Hive. Läs mer om Hive Warehouse Connector.
Om du vill dela metaarkivet mellan Hive och Spark i HDInsight 4.0 kan du göra det genom att ändra egenskapen metastore.catalog.default till hive i Spark-klustret. Du hittar den här egenskapen i Ambari Advanced spark2-hive-site-override. Det är viktigt att förstå att delning av metaarkiv endast fungerar för externa hive-tabeller, detta fungerar inte om du har interna/hanterade hive-tabeller eller ACID-tabeller.
Uppdatera lösenordet för det anpassade Hive-metaarkivet
När du använder en anpassad Hive-metaarkivdatabas kan du ändra SQL DB-lösenordet. Om du ändrar lösenordet för det anpassade metaarkivet fungerar inte Hive-tjänsterna förrän du uppdaterar lösenordet i HDInsight-klustret.
Så här uppdaterar du Lösenordet för Hive-metaarkivet:
- Öppna Ambari-användargränssnittet.
- Klicka på Tjänster –> Hive –> Konfigurationer –> Databas.
- Uppdatera fälten Databaslösenord till det nya SQL Server-databaslösenordet.
- Klicka på knappen Testa anslutning för att kontrollera att det nya lösenordet fungerar.
- Klicka på knappen Spara.
- Följ Ambari-prompterna för att spara konfigurationen och starta om de tjänster som krävs.
Apache Oozie-metaarkiv
Apache Oozie är ett system för att koordinera arbetsflöden som hanterar Hadoop-jobb. Oozie stöder Hadoop-jobb för Apache MapReduce, Pig, Hive och andra. Oozie använder ett metaarkiv för att lagra information om arbetsflöden. Om du vill öka prestandan när du använder Oozie kan du använda Azure SQL Database som ett anpassat metaarkiv. Metaarkivet ger åtkomst till Oozie-jobbdata när du har tagit bort klustret.
Anvisningar om hur du skapar ett Oozie-metaarkiv med Azure SQL Database finns i Använda Apache Oozie för arbetsflöden.
Uppdatera lösenordet för det anpassade Oozie-metaarkivet
När du använder en anpassad Oozie-metaarkivdatabas kan du ändra SQL DB-lösenordet. Om du ändrar lösenordet för det anpassade metaarkivet fungerar inte Oozie-tjänsterna förrän du uppdaterar lösenordet i HDInsight-klustret.
Så här uppdaterar du lösenordet för Oozie-metaarkivet:
- Öppna Ambari-användargränssnittet.
- Klicka på Tjänster –> Oozie –> Konfigurationer –> Databas.
- Uppdatera fälten Databaslösenord till det nya SQL Server-databaslösenordet.
- Klicka på knappen Testa anslutning för att kontrollera att det nya lösenordet fungerar.
- Klicka på knappen Spara.
- Följ Ambari-prompterna för att spara konfigurationen och starta om de tjänster som krävs.
Anpassad Ambari-databas
Information om hur du använder din egen externa databas med Apache Ambari i HDInsight finns i Anpassad Apache Ambari-databas.