Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Lär dig hur du konfigurerar antalet hanterade diskar som används av Apache Kafka i HDInsight.
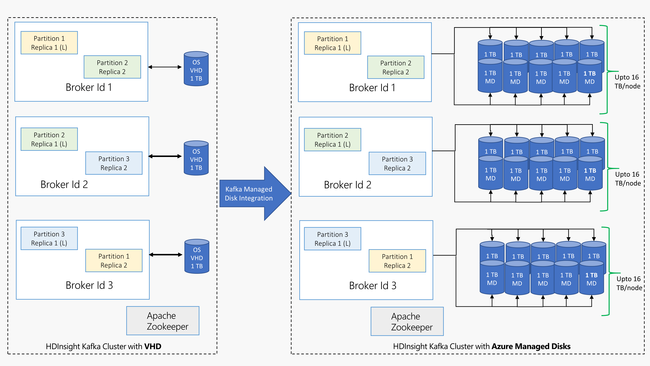
Kafka på HDInsight använder den lokala disken för virtuella datorer i HDInsight-klustret. Eftersom Kafka är mycket I/O-intensiv används Azure Managed Disks för att tillhandahålla hög genomströmning och för att ge mer lagringsutrymme per nod. Om traditionella virtuella hårddiskar (VHD) användes för Kafka skulle varje nod vara begränsad till 1 TB. Du kan använda flera diskar med hanterade diskar för att uppnå 16 TB för varje nod i klustret.
Följande diagram innehåller en jämförelse mellan Kafka på HDInsight före hanterade diskar och Kafka i HDInsight med hanterade diskar:
Konfigurera hanterade diskar: Azure-portalen
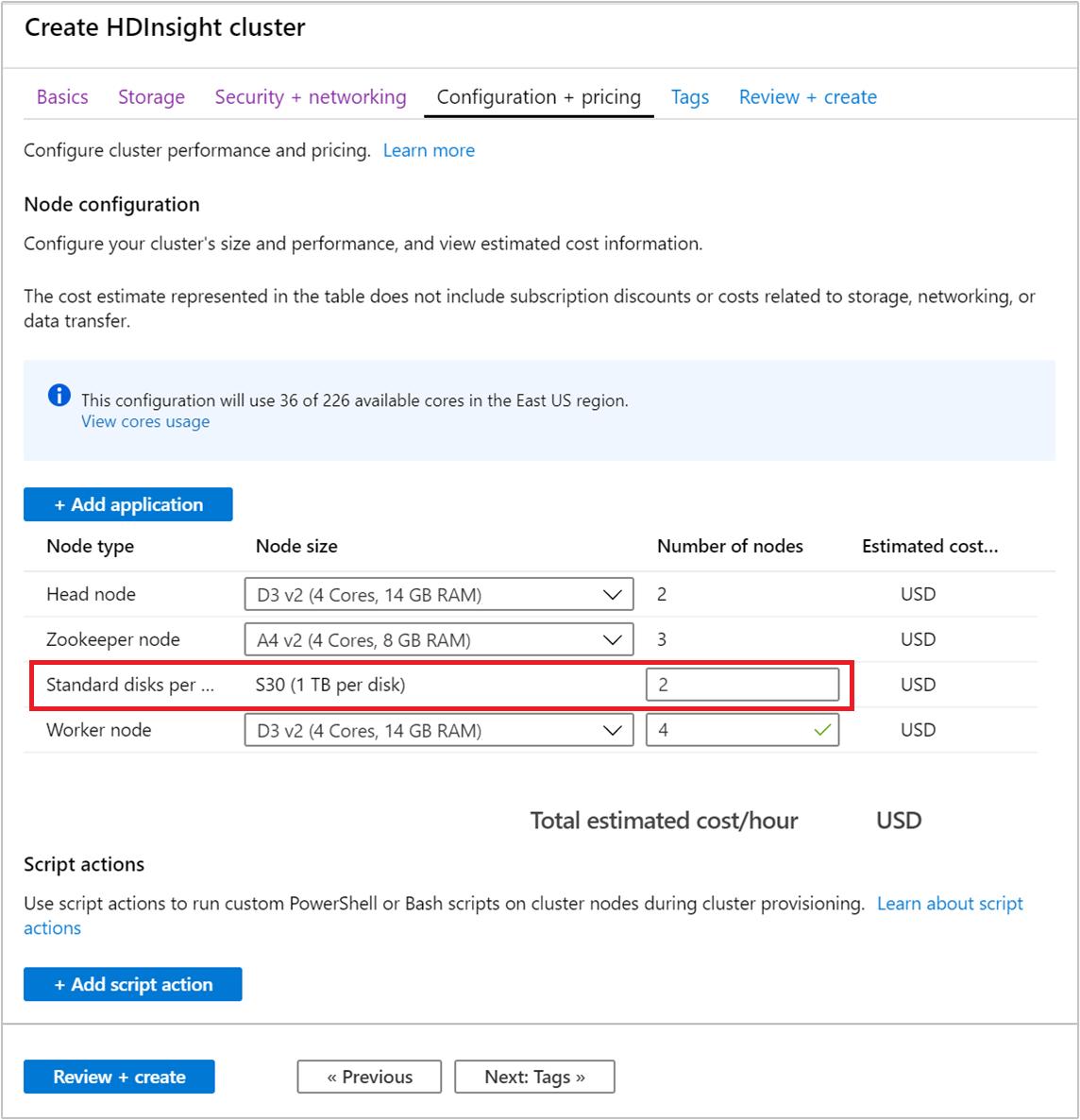
Följ stegen i Skapa ett HDInsight-kluster för att förstå de vanliga stegen för att skapa ett kluster med hjälp av portalen. Slutför inte processen för att skapa portalen.
I avsnittet Konfiguration och prissättning använder du fältet Antal noder för att konfigurera antalet diskar.
Kommentar
Typen av hanterade diskar kan vara antingen Standard (HDD) eller Premium (SSD). Premiumdiskar används med DS- och GS-serien virtuella datorer. Alla andra typer av virtuella dator använder standard.
Konfigurera hanterade diskar: Resource Manager-mall
Använd följande avsnitt i mallen för att styra antalet diskar som används av arbetarnoder i ett Kafka-kluster:
"dataDisksGroups": [
{
"disksPerNode": "[variables('disksPerWorkerNode')]"
}
],
Nästa steg
Mer information om hur du arbetar med Apache Kafka i HDInsight finns i följande dokument: