Analysera Application Insights-telemetriloggar med Apache Spark i HDInsight
Lär dig hur du använder Apache Spark i HDInsight för att analysera Application Insight-telemetridata.
Visual Studio Application Insights är en analystjänst som övervakar dina webbprogram. Telemetridata som genereras av Application Insights kan exporteras till Azure Storage. När data finns i Azure Storage kan HDInsight användas för att analysera dem.
Förutsättningar
Ett program som är konfigurerat för att använda Application Insights.
Kunskaper om att skapa ett Linux-baserat HDInsight-kluster. Mer information finns i Skapa Apache Spark på HDInsight.
En webbläsare.
Följande resurser användes för att utveckla och testa det här dokumentet:
Application Insights-telemetridata genererades med hjälp av en Node.js webbapp som konfigurerats för att använda Application Insights.
En Linux-baserad Spark på HDInsight-klusterversion 3.5 användes för att analysera data.
Arkitektur och planering
Följande diagram illustrerar tjänstarkitekturen i det här exemplet:
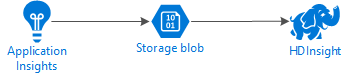
Azure Storage
Application Insights kan konfigureras för att kontinuerligt exportera telemetriinformation till blobar. HDInsight kan sedan läsa data som lagras i blobarna. Det finns dock vissa krav som du måste följa:
Plats: Om lagringskontot och HDInsight finns på olika platser kan svarstiden öka. Det ökar också kostnaderna eftersom utgående avgifter tillämpas på data som flyttas mellan regioner.
Varning
Det går inte att använda ett lagringskonto på en annan plats än HDInsight.
Blobtyp: HDInsight stöder endast blockblobar. Application Insights använder som standard blockblobar, så bör fungera som standard med HDInsight.
Information om hur du lägger till lagring i ett befintligt kluster finns i dokumentet Lägg till ytterligare lagringskonton .
Dataschema
Application Insights tillhandahåller information om exportdatamodell för telemetridataformatet som exporteras till blobar. Stegen i det här dokumentet använder Spark SQL för att arbeta med data. Spark SQL kan automatiskt generera ett schema för JSON-datastrukturen som loggas av Application Insights.
Exportera telemetridata
Följ stegen i Konfigurera kontinuerlig export för att konfigurera Application Insights för att exportera telemetriinformation till en Azure Storage-blob.
Konfigurera HDInsight för åtkomst till data
Om du skapar ett HDInsight-kluster lägger du till lagringskontot när klustret skapas.
Om du vill lägga till Azure Storage-kontot i ett befintligt kluster använder du informationen i dokumentet Lägg till ytterligare lagringskonton .
Analysera data: PySpark
Från en webbläsare navigerar du till
https://CLUSTERNAME.azurehdinsight.net/jupyterplatsen där CLUSTERNAME är namnet på klustret.I det övre högra hörnet på Sidan Jupyter väljer du Ny och sedan PySpark. En ny webbläsarflik som innehåller en Python-baserad Jupyter Notebook öppnas.
I det första fältet (kallas cell) på sidan anger du följande text:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Den här koden konfigurerar Spark för rekursiv åtkomst till katalogstrukturen för indata. Application Insights-telemetri loggas till en katalogstruktur som liknar
/{telemetry type}/YYYY-MM-DD/{##}/.Använd SKIFT+RETUR för att köra koden. Till vänster i cellen visas ett *-värde mellan hakparenteserna för att indikera att koden i den här cellen körs. När det är klart ändras "*" till ett tal och utdata som liknar följande text visas under cellen:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...En ny cell skapas under den första. Ange följande text i den nya cellen. Ersätt
CONTAINERochSTORAGEACCOUNTmed namnet på Azure Storage-kontot och namnet på blobcontainern som innehåller Application Insights-data.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Använd SKIFT+RETUR för att köra den här cellen. Du ser ett resultat som liknar följande text:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Sökvägen wasbs som returneras är platsen för Application Insights-telemetridata.
hdfs dfs -lsÄndra raden i cellen så att den använder sökvägen wasbs som returneras och använd sedan SKIFT+RETUR för att köra cellen igen. Den här gången ska resultaten visa de kataloger som innehåller telemetridata.Kommentar
Under resten av stegen i det här avsnittet
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsanvändes katalogen. Katalogstrukturen kan vara annorlunda.I nästa cell anger du följande kod: Ersätt
WASB_PATHmed sökvägen från föregående steg.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Den här koden skapar en dataram från JSON-filerna som exporteras av den kontinuerliga exportprocessen. Använd SKIFT+RETUR för att köra den här cellen.
I nästa cell anger och kör du följande för att visa schemat som Spark skapade för JSON-filerna:
jsonData.printSchema()Schemat för varje typ av telemetri är olika. Följande exempel är det schema som genereras för webbbegäranden (data som lagras i underkatalogen
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Använd följande för att registrera dataramen som en tillfällig tabell och köra en fråga mot data:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Den här frågan returnerar ortsinformationen för de 20 främsta posterna där context.location.city inte är null.
Kommentar
Kontextstrukturen finns i all telemetri som loggas av Application Insights. Stadselementet kanske inte fylls i i loggarna. Använd schemat för att identifiera andra element som du kan köra frågor mot som kan innehålla data för dina loggar.
Den här frågan returnerar information som liknar följande text:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analysera data: Scala
Från en webbläsare navigerar du till
https://CLUSTERNAME.azurehdinsight.net/jupyterplatsen där CLUSTERNAME är namnet på klustret.I det övre högra hörnet på Sidan Jupyter väljer du Ny och sedan Scala. En ny webbläsarflik som innehåller en Scala-baserad Jupyter Notebook visas.
I det första fältet (kallas cell) på sidan anger du följande text:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Den här koden konfigurerar Spark för rekursiv åtkomst till katalogstrukturen för indata. Application Insights-telemetri loggas till en katalogstruktur som liknar
/{telemetry type}/YYYY-MM-DD/{##}/.Använd SKIFT+RETUR för att köra koden. Till vänster i cellen visas ett *-värde mellan hakparenteserna för att indikera att koden i den här cellen körs. När det är klart ändras "*" till ett tal och utdata som liknar följande text visas under cellen:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...En ny cell skapas under den första. Ange följande text i den nya cellen. Ersätt
CONTAINERochSTORAGEACCOUNTmed namnet på Azure Storage-kontot och namnet på blobcontainern som innehåller Application Insights-loggar.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Använd SKIFT+RETUR för att köra den här cellen. Du ser ett resultat som liknar följande text:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Sökvägen wasbs som returneras är platsen för Application Insights-telemetridata.
hdfs dfs -lsÄndra raden i cellen så att den använder sökvägen wasbs som returneras och använd sedan SKIFT+RETUR för att köra cellen igen. Den här gången ska resultaten visa de kataloger som innehåller telemetridata.Kommentar
Under resten av stegen i det här avsnittet
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsanvändes katalogen. Den här katalogen kanske inte finns om inte dina telemetridata är för en webbapp.I nästa cell anger du följande kod: Ersätt
WASB\_PATHmed sökvägen från föregående steg.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Den här koden skapar en dataram från JSON-filerna som exporteras av den kontinuerliga exportprocessen. Använd SKIFT+RETUR för att köra den här cellen.
I nästa cell anger och kör du följande för att visa schemat som Spark skapade för JSON-filerna:
jsonData.printSchemaSchemat för varje typ av telemetri är olika. Följande exempel är det schema som genereras för webbbegäranden (data som lagras i underkatalogen
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Använd följande för att registrera dataramen som en tillfällig tabell och köra en fråga mot data:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Den här frågan returnerar ortsinformationen för de 20 främsta posterna där context.location.city inte är null.
Kommentar
Kontextstrukturen finns i all telemetri som loggas av Application Insights. Stadselementet kanske inte fylls i i loggarna. Använd schemat för att identifiera andra element som du kan köra frågor mot som kan innehålla data för dina loggar.
Den här frågan returnerar information som liknar följande text:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Nästa steg
Fler exempel på hur du använder Apache Spark för att arbeta med data och tjänster i Azure finns i följande dokument:
- Apache Spark med BI: Utföra interaktiv dataanalys med Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Information om hur du skapar och kör Spark-program finns i följande dokument: