Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här självstudien lär du dig hur du skapar en dataram från en csv-fil och kör interaktiva Spark SQL-frågor mot ett Apache Spark-kluster i Azure HDInsight. I Spark är en dataram en distribuerad datasamling som har ordnats i namngivna kolumner. Begreppsmässigt motsvarar dataramen en tabell i en relationsdatabas eller en dataram i R/Python.
I den här handledningen lär du dig att:
- Skapa en dataram från en csv-fil
- Köra frågor i dataramen
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Se Skapa ett Apache Spark-kluster.
Skapa en Jupyter Notebook
Jupyter Notebook är en interaktiv anteckningsboksmiljö som stöder flera olika datorspråk. Du kan använda anteckningsboken för att interagera med dina data, kombinera kod med markdown-text och utföra enkla visualiseringar.
Redigera URL:en
https://SPARKCLUSTER.azurehdinsight.net/jupytergenom attSPARKCLUSTERersätta med namnet på ditt Spark-kluster. Ange sedan den redigerade URL:en i en webbläsare. Ange autentiseringsuppgifterna för klustret om du uppmanas att göra det.På Jupyter-webbsidan för Spark 2.4-kluster väljer du Ny>PySpark för att skapa en notebook. För Spark 3.1-versionen väljer du Ny>PySpark3 i stället för att skapa en notebook-fil eftersom PySpark-kerneln inte längre är tillgänglig i Spark 3.1.
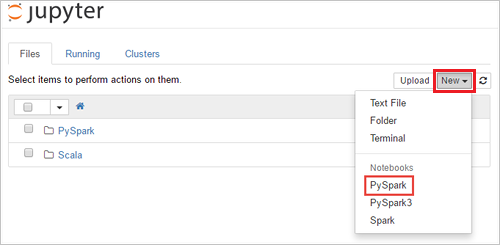
En ny notebook-fil skapas och öppnas med namnet Untitled(
Untitled.ipynb).Anteckning
Genom att använda PySpark eller PySpark3-kerneln för att skapa en notebook-fil
sparkskapas sessionen automatiskt åt dig när du kör den första kodcellen. Du behöver inte uttryckligen skapa sessionen.
Skapa en dataram från en csv-fil
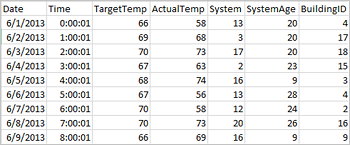
Program kan skapa dataramar direkt från filer eller mappar på fjärrlagringen, till exempel Azure Storage eller Azure Data Lake Storage. från en Hive-tabell; eller från andra datakällor som stöds av Spark, till exempel Azure Cosmos DB, Azure SQL DB, DW och så vidare. Följande skärmbild visar ett utdrag av HVAC.csv-filen som används i denna handledning. Csv-filen finns i alla HDInsight Spark-kluster. Datan visar temperaturvariationer i vissa byggnader.
Klistra in följande kod i en tom cell i Jupyter Notebook och tryck sedan på SKIFT + RETUR för att köra koden. Koden importerar de typer som krävs för det här scenariot:
from pyspark.sql import * from pyspark.sql.types import *När du kör en interaktiv fråga i Jupyter visar webbläsarfönstret eller flikrubriken statusen (Upptagen) tillsammans med anteckningsbokens rubrik. Du ser även en fylld cirkel bredvid PySpark-texten i det övre högra hörnet. När jobbet har slutförts ändras detta till en tom cirkel.
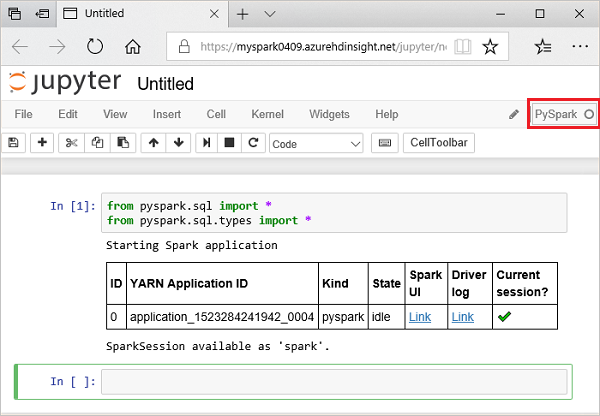
Observera sessions-ID:t som returnerades. Från bilden ovan är sessions-ID:t 0. Om du vill kan du hämta sessionsinformationen genom att navigera till
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsplatsen där CLUSTERNAME är namnet på ditt Spark-kluster och ID är ditt sessions-ID-nummer.Kör följande kod för att skapa en dataram och en tillfällig tabell (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Utföra databasfrågeställningar på datanami
När tabellen har skapats kan du köra en interaktiv fråga på datan.
Kör följande kod i en tom cell i anteckningsboken:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Följande tabellutdata visas.
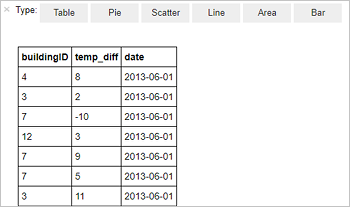
Du kan också visa resultaten i andra visualiseringar. Om du vill se ett ytdiagram för samma utdata väljer du Yta och anger sedan de andra värden som visas.
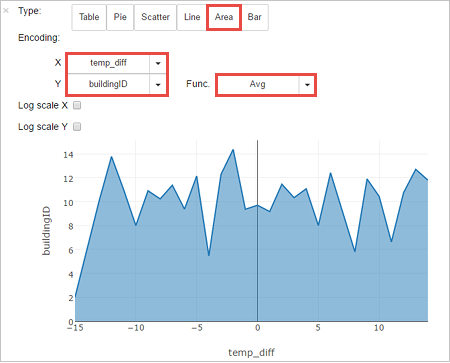
Från menyraden för anteckningsbok navigerar du till Fil>Spara och Kontrollpunkt.
Om du ska starta nästa självstudie direkt kan du lämna anteckningsboken öppen. Om inte, stäng av anteckningsboken för att frigöra klusterresurserna: från menyraden för anteckningsboken går du till Arkiv>Stäng och Avbryt.
Rensa resurser
Med HDInsight lagras dina data och Jupyter Notebooks i Azure Storage eller Azure Data Lake Storage, så att du på ett säkert sätt kan ta bort ett kluster när det inte används. Du debiteras också för ett HDInsight-kluster, även om det inte används. Eftersom avgifterna för klustret är många gånger högre än avgifterna för lagring är det ekonomiskt klokt att ta bort kluster när de inte används. Om du tänker arbeta med nästa självstudie direkt kan du behålla klustret.
Öppna klustret i Azure Portal och välj Ta bort.
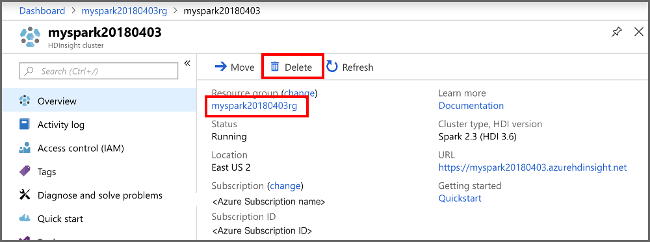
Du kan också välja resursgruppnamnet för att öppna resursgruppsidan. Välj sedan Ta bort resursgrupp. När du tar bort resursgruppen tar du bort både HDInsight Spark-klustret och standardkontot för lagring.
Nästa steg
I den här självstudien har du lärt dig hur du skapar en dataram från en csv-fil och hur du kör interaktiva Spark SQL-frågor mot ett Apache Spark-kluster i Azure HDInsight. Gå vidare till nästa artikel för att se hur de data som du har registrerat i Apache Spark kan hämtas till ett BI-analysverktyg såsom Power BI.