Konfigurera Apache Spark-inställningar
Ett HDInsight Spark-kluster innehåller en installation av Apache Spark-biblioteket. Varje HDInsight-kluster innehåller standardkonfigurationsparametrar för alla installerade tjänster, inklusive Spark. En viktig aspekt av att hantera ett HDInsight Apache Hadoop-kluster är övervakning av arbetsbelastningar, inklusive Spark-jobb. Om du vill köra Spark-jobb på bästa sätt bör du överväga konfigurationen av det fysiska klustret när du fastställer klustrets logiska konfiguration.
Standard-HDInsight Apache Spark-klustret innehåller följande noder: tre Apache ZooKeeper-noder, två huvudnoder och en eller flera arbetsnoder:
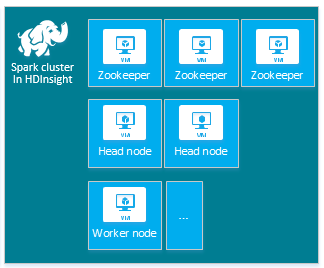
Antalet virtuella datorer och VM-storlekar för noderna i HDInsight-klustret kan påverka Spark-konfigurationen. HdInsight-konfigurationsvärden som inte är standard kräver ofta spark-konfigurationsvärden som inte är standard. När du skapar ett HDInsight Spark-kluster visas föreslagna VM-storlekar för var och en av komponenterna. För närvarande är de minnesoptimerade vm-storlekarna för Linux för Azure D12 v2 eller större.
Apache Spark-versioner
Använd den bästa Spark-versionen för klustret. HDInsight-tjänsten innehåller flera versioner av både Spark och HDInsight. Varje version av Spark innehåller en uppsättning standardklusterinställningar.
När du skapar ett nytt kluster finns det flera Spark-versioner att välja mellan. Om du vill se hela listan, HDInsight-komponenter och versioner.
Kommentar
Standardversionen av Apache Spark i HDInsight-tjänsten kan ändras utan föregående meddelande. Om du har ett versionsberoende rekommenderar Microsoft att du anger den specifika versionen när du skapar kluster med hjälp av .NET SDK, Azure PowerShell och klassiska Azure CLI.
Apache Spark har tre systemkonfigurationsplatser:
- Spark-egenskaper styr de flesta programparametrar och kan anges med hjälp av ett
SparkConfobjekt eller via Java-systemegenskaper. - Miljövariabler kan användas för att ange inställningar per dator, till exempel IP-adressen, via skriptet
conf/spark-env.shpå varje nod. - Loggning kan konfigureras via
log4j.properties.
När du väljer en viss version av Spark innehåller klustret standardkonfigurationsinställningarna. Du kan ändra standardvärdena för Spark-konfigurationen med hjälp av en anpassad Spark-konfigurationsfil. Ett exempel på detta visas nedan.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
Exemplet ovan åsidosätter flera standardvärden för fem Spark-konfigurationsparametrar. Dessa värden är komprimeringskodc, Apache Hadoop MapReduce dela minsta storlek och parquet blockstorlekar. Dessutom standardvärden för Spark SQL-partition och öppna filstorlekar. Dessa konfigurationsändringar väljs eftersom associerade data och jobb (i det här exemplet genomiska data) har särskilda egenskaper. De här egenskaperna fungerar bättre med de här anpassade konfigurationsinställningarna.
Visa konfigurationsinställningar för kluster
Kontrollera de aktuella konfigurationsinställningarna för HDInsight-klustret innan du utför prestandaoptimering i klustret. Starta HDInsight-instrumentpanelen från Azure-portalen genom att klicka på länken Instrumentpanel i fönstret Spark-kluster. Logga in med klusteradministratörens användarnamn och lösenord.
Apache Ambari-webbgränssnittet visas med en instrumentpanel med nyckelklusterresursanvändningsmått. Ambari-instrumentpanelen visar Apache Spark-konfigurationen och andra installerade tjänster. Instrumentpanelen innehåller fliken Konfigurationshistorik där du visar information för installerade tjänster, inklusive Spark.
Om du vill se konfigurationsvärden för Apache Spark väljer du Konfigurationshistorik och sedan Spark2. Välj fliken Konfigurationer och välj Spark sedan länken (eller Spark2, beroende på din version) i tjänstlistan. Du ser en lista med konfigurationsvärden för klustret:
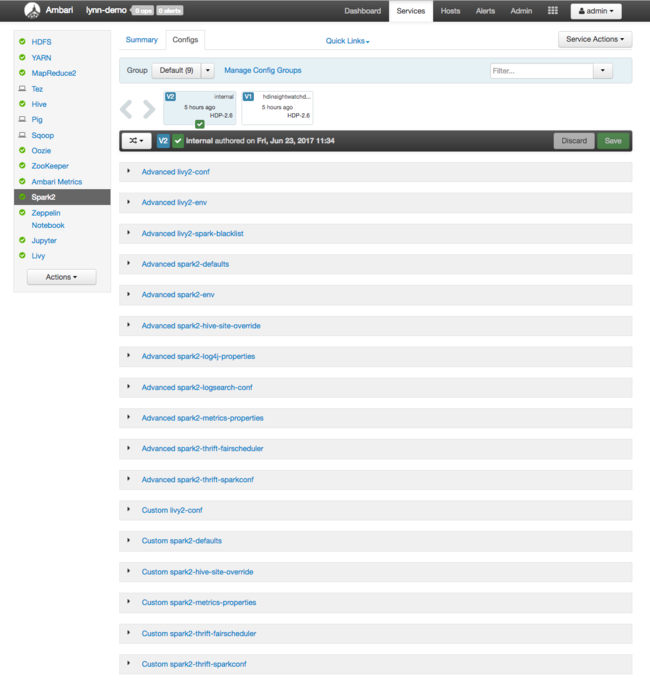
Om du vill se och ändra enskilda Spark-konfigurationsvärden väljer du valfri länk med "spark" i rubriken. Konfigurationer för Spark innehåller både anpassade och avancerade konfigurationsvärden i följande kategorier:
- Anpassade Spark2-standardvärden
- Anpassade Egenskaper för Spark2-metrics-properties
- Avancerade Spark2-standardvärden
- Avancerad Spark2-env
- Avancerad spark2-hive-site-override
Om du skapar en uppsättning konfigurationsvärden som inte är standard visas uppdateringshistoriken. Den här konfigurationshistoriken kan vara användbar för att se vilken icke-standardkonfiguration som har optimala prestanda.
Kommentar
Om du vill se, men inte ändra, vanliga konfigurationsinställningar för Spark-kluster väljer du fliken Miljö i gränssnittet för Spark-jobb på den översta nivån.
Konfigurera Spark-köre
Följande diagram visar viktiga Spark-objekt: drivrutinsprogrammet och dess associerade Spark-kontext samt klusterhanteraren och dess n arbetsnoder. Varje arbetsnod innehåller en executor, en cache och n aktivitetsinstanser.
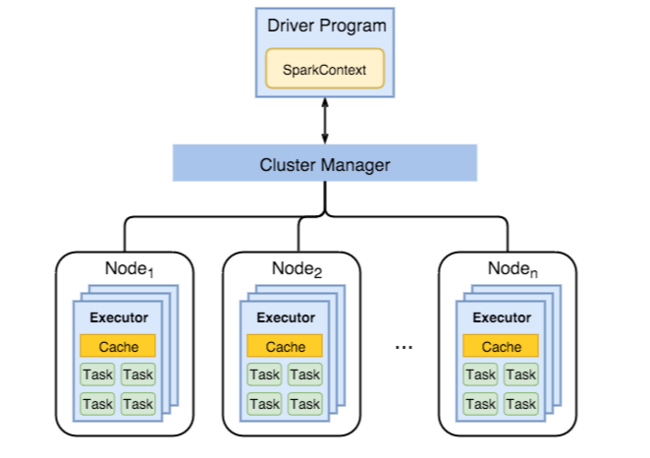
Spark-jobb använder arbetsresurser, särskilt minne, så det är vanligt att justera Spark-konfigurationsvärden för körbara arbetsnoder.
Tre viktiga parametrar som ofta justeras för att justera Spark-konfigurationer för att förbättra programkraven är spark.executor.instances, spark.executor.coresoch spark.executor.memory. En körprocess är en process som startas för ett Spark-program. En executor körs på arbetsnoden och ansvarar för programmets uppgifter. Antalet arbetsnoder och storleken på arbetsnoden avgör antalet kör- och körstorlekar. Dessa värden lagras i spark-defaults.conf på klusterhuvudnoderna. Du kan redigera dessa värden i ett kluster som körs genom att välja Anpassade spark-standardvärden i Ambari-webbgränssnittet. När du har ändrat uppmanas du av användargränssnittet att starta om alla berörda tjänster.
Kommentar
Dessa tre konfigurationsparametrar kan konfigureras på klusternivå (för alla program som körs i klustret) och även anges för varje enskilt program.
En annan informationskälla om resurser som används av Spark Executors är Spark-programmets användargränssnitt. I användargränssnittet visar körarna sammanfattnings- och detaljvyer av konfigurationen och förbrukade resurser. Avgör om du vill ändra körvärden för hela klustret eller en viss uppsättning jobbkörningar.
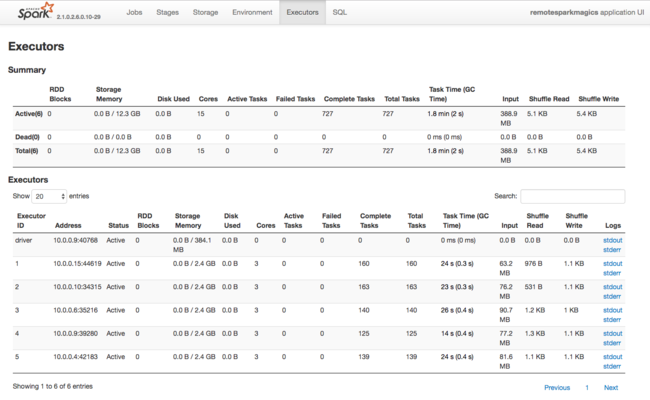
Eller så kan du använda Ambari REST API för att programmatiskt verifiera konfigurationsinställningarna för HDInsight- och Spark-kluster. Mer information finns i Apache Ambari API-referensen på GitHub.
Beroende på din Spark-arbetsbelastning kan du bestämma att en icke-standardmässig Spark-konfiguration ger mer optimerade Spark-jobbkörningar. Utför benchmark-testning med exempelarbetsbelastningar för att verifiera eventuella klusterkonfigurationer som inte är standard. Några av de vanliga parametrar som du kan överväga att justera är:
| Parameter | Description |
|---|---|
| --num-executors | Anger antalet utförare. |
| --executor-cores | Anger antalet kärnor för varje köre. Vi rekommenderar att du använder medelstora körbara filer, eftersom andra processer även förbrukar en del av det tillgängliga minnet. |
| --executor-memory | Styr minnesstorleken (heapstorleken) för varje köre på Apache Hadoop YARN, och du måste lämna lite minne för körningskostnaderna. |
Här är ett exempel på två arbetsnoder med olika konfigurationsvärden:

I följande lista visas nyckelparametrar för Spark-körminne.
| Parameter | Description |
|---|---|
| spark.executor.memory | Definierar den totala mängden minne som är tillgängligt för en köre. |
| spark.storage.memoryFraction | (standardvärdet ~60 %) definierar mängden minne som är tillgängligt för lagring av bevarade RDD:er. |
| spark.shuffle.memoryFraction | (standardvärdet ~20 %) definierar mängden minne som är reserverat för shuffle. |
| spark.storage.unrollFraction och spark.storage.safetyFraction | (totalt ~30 % av det totala minnet) – dessa värden används internt av Spark och bör inte ändras. |
YARN styr den maximala mängden minne som används av containrarna på varje Spark-nod. Följande diagram visar relationerna per nod mellan YARN-konfigurationsobjekt och Spark-objekt.
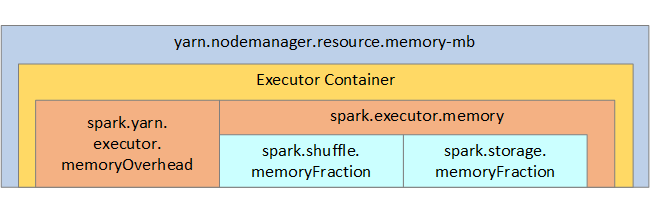
Ändra parametrar för ett program som körs i Jupyter Notebook
Spark-kluster i HDInsight innehåller ett antal komponenter som standard. Var och en av dessa komponenter innehåller standardkonfigurationsvärden som kan åsidosättas efter behov.
| Komponent | beskrivning |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark-strömmande API:er, GraphX och Apache Spark MLlib. |
| Anaconda | En Python-pakethanterare. |
| Apache Livy | Apache Spark REST API, som används för att skicka fjärrjobb till ett HDInsight Spark-kluster. |
| Jupyter Notebooks och Apache Zeppelin Notebooks | Interaktivt webbläsarbaserat användargränssnitt för att interagera med ditt Spark-kluster. |
| ODBC-drivrutin | Anslut Spark-kluster i HDInsight till BI-verktyg (Business Intelligence), till exempel Microsoft Power BI och Tableau. |
För program som körs i Jupyter Notebook använder du %%configure kommandot för att göra konfigurationsändringar inifrån själva notebook-filen. De här konfigurationsändringarna tillämpas på Spark-jobben som körs från notebook-instansen. Gör sådana ändringar i början av programmet innan du kör din första kodcell. Den ändrade konfigurationen tillämpas på Livy-sessionen när den skapas.
Kommentar
Om du vill ändra konfigurationen i ett senare skede i programmet använder du parametern -f (force). Alla framsteg i programmet går dock förlorade.
Koden nedan visar hur du ändrar konfigurationen för ett program som körs i en Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Slutsats
Övervaka grundläggande konfigurationsinställningar för att säkerställa att dina Spark-jobb körs på ett förutsägbart och högpresterande sätt. De här inställningarna hjälper dig att fastställa den bästa Spark-klusterkonfigurationen för dina specifika arbetsbelastningar. Du måste också övervaka körningen av långvariga och resurskrävande Spark-jobbkörningar. De vanligaste utmaningarna är minnestryck från felaktiga konfigurationer, till exempel felaktigt stora utförare. Dessutom tidskrävande åtgärder och uppgifter, vilket resulterar i kartesiska åtgärder.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för