Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
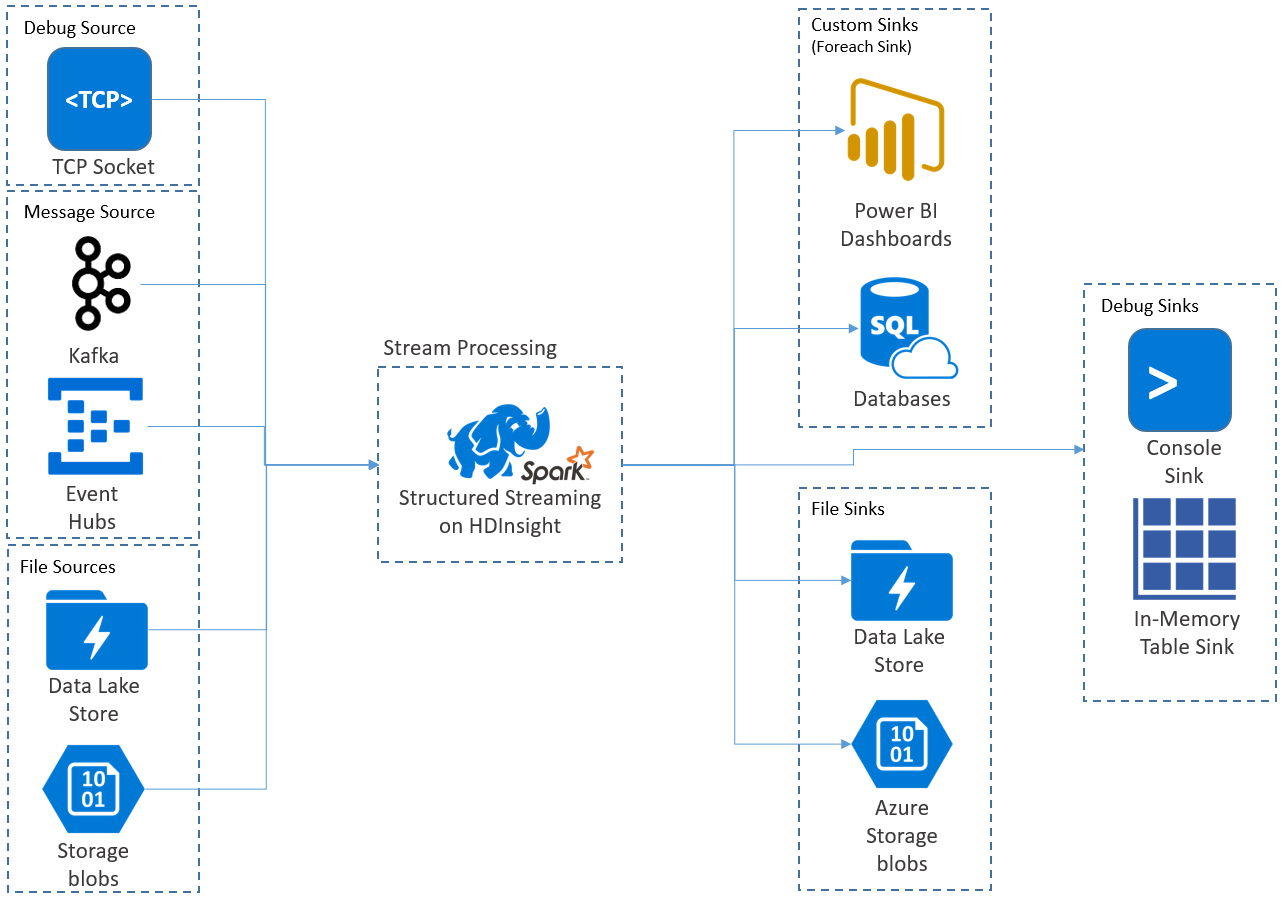
Med Apache Spark Structured Streaming kan du implementera skalbara program med högt dataflöde och feltoleranta program för bearbetning av dataströmmar. Strukturerad direktuppspelning bygger på Spark SQL-motorn och förbättrar konstruktionerna från Spark SQL-dataramar och datauppsättningar så att du kan skriva strömmande frågor på samma sätt som du skriver batchfrågor.
Strukturerade direktuppspelningsprogram körs på HDInsight Spark-kluster och ansluter till strömmande data från Apache Kafka, en TCP-socket (för felsökning), Azure Storage eller Azure Data Lake Storage. De två senare alternativen, som förlitar sig på externa lagringstjänster, gör att du kan titta efter nya filer som lagts till i lagringen och bearbeta deras innehåll som om de strömmades.
Structured Streaming skapar en långvarig förfrågan där du tillämpar operationer på indata, såsom selection, projection, aggregation, windowing och att koppla ihop den strömmande DataFrame med referensdataramar. Därefter matar du ut resultatet till fillagring (Azure Storage Blobs eller Data Lake Storage) eller till ett datalager med hjälp av anpassad kod (till exempel SQL Database eller Power BI). Strukturerad direktuppspelning ger också utdata till konsolen för felsökning lokalt och till en minnesintern tabell så att du kan se de data som genereras för felsökning i HDInsight.
Anteckning
Spark Structured Streaming ersätter Spark Streaming (DStreams). Framöver får Structured Streaming förbättringar och underhåll, medan DStreams endast är i underhållsläge. Strukturerad direktuppspelning är för närvarande inte lika funktions komplett som DStreams för de källor och mottagare som den stöder direkt, så utvärdera dina krav för att välja lämpligt alternativ för Bearbetning av Spark-dataström.
Strömmar som tabeller
Spark Structured Streaming representerar en dataström som en tabell som är obunden, dvs. tabellen fortsätter att växa när nya data tas emot. Den här indatatabellen bearbetas kontinuerligt av en tidskrävande fråga och resultaten skickas till en utdatatabell:

I Strukturerad direktuppspelning anländer data till systemet och matas omedelbart in i en indatatabell. Du skriver frågor (med hjälp av API:er för DataFrame och datauppsättning) som utför åtgärder mot den här indatatabellen. Frågeutdata ger en annan tabell, resultattabellen. Resultattabellen innehåller resultatet av din fråga, från vilken du ritar data för ett externt datalager, till exempel en relationsdatabas. Tidpunkten för när data bearbetas från indatatabellen styrs av utlösarintervallet. Som standard är utlösarintervallet noll, så Structured Streaming försöker bearbeta data så snart de kommer. I praktiken innebär det att så fort structured Streaming är klar med bearbetningen av körningen av den föregående frågan startar den en annan bearbetningskörning mot nyligen mottagna data. Du kan konfigurera utlösaren så att den körs med ett intervall, så att strömmande data bearbetas i tidsbaserade batchar.
Data i resultattabellerna kan bara innehålla data som är nya sedan den senaste gången frågan bearbetades (tilläggsläge), eller så kan tabellen uppdateras varje gång det finns nya data så att tabellen innehåller alla utdata sedan den strömmande frågan började (fullständigt läge).
Lägg till-läge
I tilläggsläge finns endast de rader som lagts till i resultattabellen sedan den senaste frågekörningen i resultattabellen och skrivs till extern lagring. Den enklaste frågan kopierar till exempel bara alla data från indatatabellen till resultattabellen oförändrad. Varje gång ett utlösarintervall förflutit bearbetas de nya data och raderna som representerar dessa nya data visas i resultattabellen.
Tänk dig ett scenario där du bearbetar telemetri från temperatursensorer, till exempel en termostat. Anta att den första utlösaren bearbetade en händelse vid tidpunkten 00:01 för enhet 1 med en temperaturavläsning på 95 grader. I den första utlösaren av frågan visas endast raden med tid 00:01 i resultattabellen. Vid tidpunkten 00:02 när en annan händelse kommer är den enda nya raden raden med tid 00:02 och därför innehåller resultattabellen bara den raden.
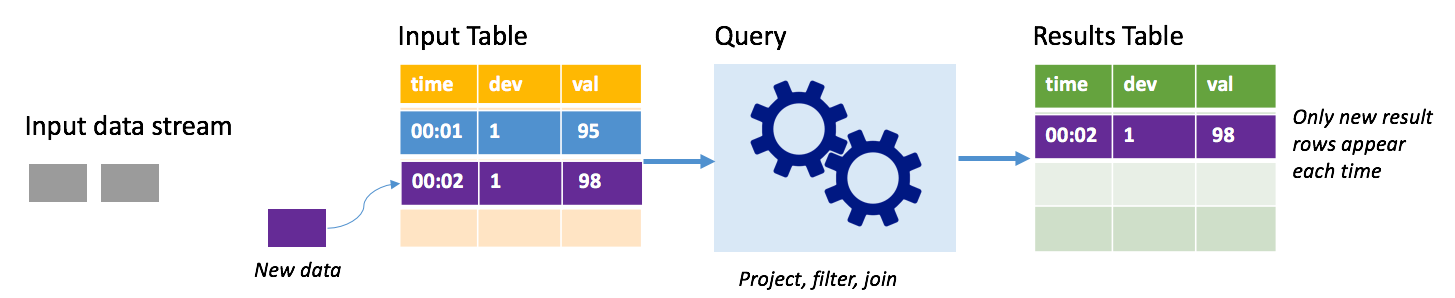
När du använder tilläggsläget använder frågan projektioner (väljer de kolumner som den bryr sig om), filtrerar (väljer endast rader som matchar vissa villkor) eller ansluter (utökar data med data från en statisk uppslagstabell). Tilläggsläget gör det enkelt att endast överföra relevanta nya datapunkter till extern lagring.
Fullständigt läge
Tänk på samma scenario, den här gången i fullständigt läge. I fullständigt läge uppdateras hela utdatatabellen på varje utlösare, så tabellen innehåller data inte bara från den senaste utlösarkörningen, utan från alla körningar. Du kan använda kompletteringsläge för att kopiera data oförändrat från indatatabellen till resultattabellen. På varje utlöst körning visas de nya resultatraderna tillsammans med alla föregående rader. Utdataresultattabellen kommer att lagra alla data som samlats in sedan frågan började, och du skulle så småningom få slut på minne. Fullständigt läge är avsett för användning med aggregerade frågor som sammanfattar inkommande data på något sätt, så vid varje utlösare uppdateras resultattabellen med en ny sammanfattning.
Anta att det hittills finns fem sekunders data som redan har bearbetats och att det är dags att bearbeta data för den sjätte sekunden. Indatatabellen har händelser för tid 00:01 och tid 00:03. Målet med den här exempelfrågan är att ge enhetens medeltemperatur var femte sekund. Implementeringen av den här frågan tillämpar en aggregering som tar alla värden som faller inom varje 5-sekundersfönster, medelvärder temperaturen och genererar en rad för medeltemperaturen över det intervallet. I slutet av det första 5-sekundersfönstret finns det två tupplar: (00:01, 1, 95) och (00:03, 1, 98). Så för tidsintervallet 00:00-00:05 producerar aggregeringen en tupel med en medeltemperatur på 96,5 grader. I nästa 5-sekundersfönster finns det bara en datapunkt vid tidpunkten 00:06, så den resulterande medeltemperaturen är 98 grader. Vid tidpunkten 00:10, med fullständigt läge, har resultattabellen raderna för både windows 00:00-00:05 och 00:05-00:10 eftersom frågan matar ut alla aggregerade rader, inte bara de nya. Därför fortsätter resultattabellen att växa när nya fönster läggs till.
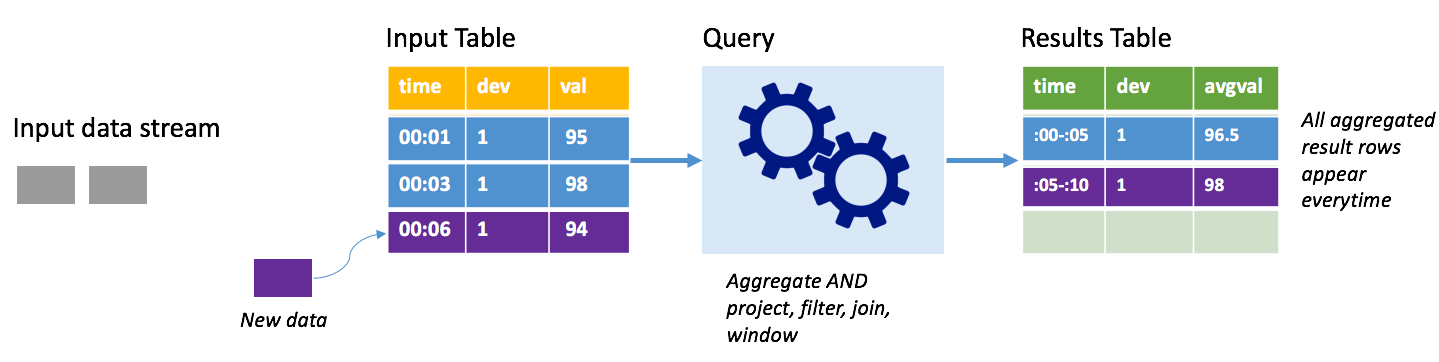
Det är inte alla frågor som använder fullständigt läge som gör att tabellen växer utan gränser. Tänk i det föregående exemplet på att istället för att beräkna medeltemperaturen per tidsfönster, så beräknades den istället per enhets-ID. Resultattabellen innehåller ett fast antal rader (en per enhet) med medeltemperaturen för enheten över alla datapunkter som tas emot från den enheten. När nya temperaturer tas emot uppdateras resultattabellen så att medelvärdena i tabellen alltid är aktuella.
Komponenter i ett Spark Structured Streaming-program
En enkel exempelfråga kan sammanfatta temperaturavläsningarna efter timslånga fönster. I det här fallet lagras data i JSON-filer i Azure Storage (bifogas som standardlagring för HDInsight-klustret):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Dessa JSON-filer lagras i undermappen temps under HDInsight-klustrets container.
Definiera indatakällan
Konfigurera först en DataFrame som beskriver datakällan och eventuella inställningar som krävs av den källan. Det här exemplet bygger på JSON-filerna i Azure Storage och tillämpar ett schema på dem vid lästillfället.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Tillämpa frågan
Tillämpa sedan en fråga som innehåller önskade åtgärder mot strömmande dataram. I det här fallet grupperar en aggregering alla rader i 1-timmarsfönster och beräknar sedan den lägsta, genomsnittliga och högsta temperaturen i det 1-timmarsfönstret.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definiera utdatamottagaren
Definiera sedan målet för de rader som läggs till i resultattabellen inom varje utlösarintervall. Det här exemplet matar bara ut alla rader till en minnesintern tabell temps som du senare kan köra frågor mot med SparkSQL. Fullständigt utdataläge säkerställer att alla rader för alla fönster matas ut varje gång.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Starta frågan
Starta strömningsfrågan och kör tills en avslutningssignal tas emot.
val query = streamingOutDF.start()
Visa resultatet
När frågan körs kan du i samma SparkSession köra en SparkSQL-fråga mot tabellen temps där frågeresultatet lagras.
select * from temps
Den här frågan ger resultat som liknar följande:
| fönster | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Mer information om Spark Structured Stream API, tillsammans med indatakällor, åtgärder och utdatamottagare som stöds finns i Apache Spark Structured Streaming Programming Guide.
Loggar för kontrollpunkter och framåtskrivning
För att leverera återhämtning och feltolerans förlitar sig Structured Streaming på kontrollpunkter för att säkerställa att dataströmbearbetningen kan fortsätta oavbruten, även med nodfel. I HDInsight skapar Spark kontrollpunkter för beständig lagring, antingen Azure Storage eller Data Lake Storage. Dessa kontrollpunkter lagrar förloppsinformationen om strömningsfrågan. Dessutom använder Structured Streaming en förskrivningslogg (WAL). WAL samlar in data som mottagits men ännu inte bearbetats av en sökfråga. Om ett fel inträffar och bearbetningen startas om från WAL går inga händelser som tas emot från källan förlorade.
Implementera Spark Streaming-applikationer
Du skapar vanligtvis ett Spark Streaming-program lokalt i en JAR-fil och distribuerar det sedan till Spark i HDInsight genom att kopiera JAR-filen till standardlagringen som är kopplad till HDInsight-klustret. Du kan starta ditt program med Apache Livy REST API:er som är tillgängliga från klustret med hjälp av en POST-åtgärd. Brödtexten i POST innehåller ett JSON-dokument som tillhandahåller sökvägen till din JAR, namnet på klassen vars huvudmetod definierar och kör det strömmande programmet och eventuellt resurskraven för jobbet (till exempel antalet körbara filer, minne och kärnor) och eventuella konfigurationsinställningar som programkoden kräver.
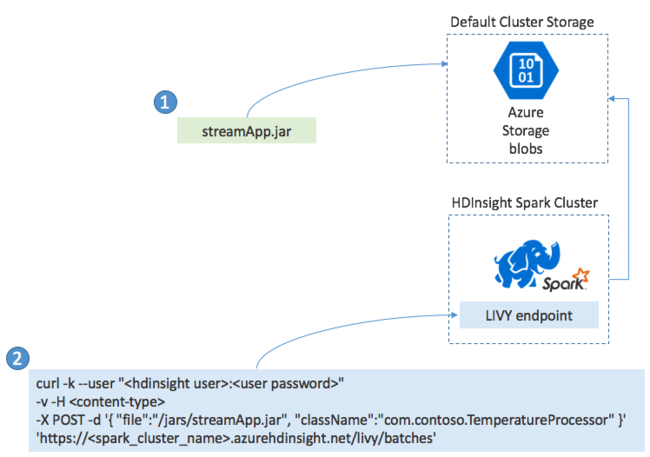
Status för alla program kan också kontrolleras med en GET-begäran mot en LIVY-slutpunkt. Slutligen kan du avsluta ett program som körs genom att utfärda en DELETE-begäran mot LIVY-slutpunkten. Mer information om LIVY-API :et finns i Fjärrjobb med Apache LIVY