Konfigurera Apache Ranger-principer för Spark SQL i HDInsight med Enterprise Security Package
Den här artikeln beskriver hur du konfigurerar Apache Ranger-principer för Spark SQL med Enterprise Security Package i HDInsight.
I den här artikeln kan du se hur du:
- Skapa Apache Ranger-principer.
- Verifiera de tillämpade Ranger-principerna.
- Tillämpa riktlinjer för att ange Apache Ranger för Spark SQL.
Förutsättningar
- Ett Apache Spark-kluster i HDInsight version 5.1 med Enterprise Security Package
Anslut till administrationsgränssnittet för Apache Ranger
Från en webbläsare ansluter du till Ranger-administratörens användargränssnitt med hjälp av URL:en
https://ClusterName.azurehdinsight.net/Ranger/.Ändra
ClusterNametill namnet på ditt Spark-kluster.Logga in med dina autentiseringsuppgifter för Microsoft Entra-administratör. Autentiseringsuppgifterna för Microsoft Entra-administratören är inte samma som autentiseringsuppgifter för HDInsight-kluster eller autentiseringsuppgifter för Linux HDInsight-noden Secure Shell (SSH).
Skapa domänanvändare
Information om hur du skapar sparkuser domänanvändare finns i Skapa ett HDInsight-kluster med ESP. I ett produktionsscenario kommer domänanvändare från din Microsoft Entra-klientorganisation.
Skapa en Ranger-princip
I det här avsnittet skapar du två Ranger-principer:
- En åtkomstprincip för åtkomst
hivesampletablefrån Spark SQL - En maskeringsprincip för att dölja kolumnerna i
hivesampletable
Skapa en Ranger-åtkomstprincip
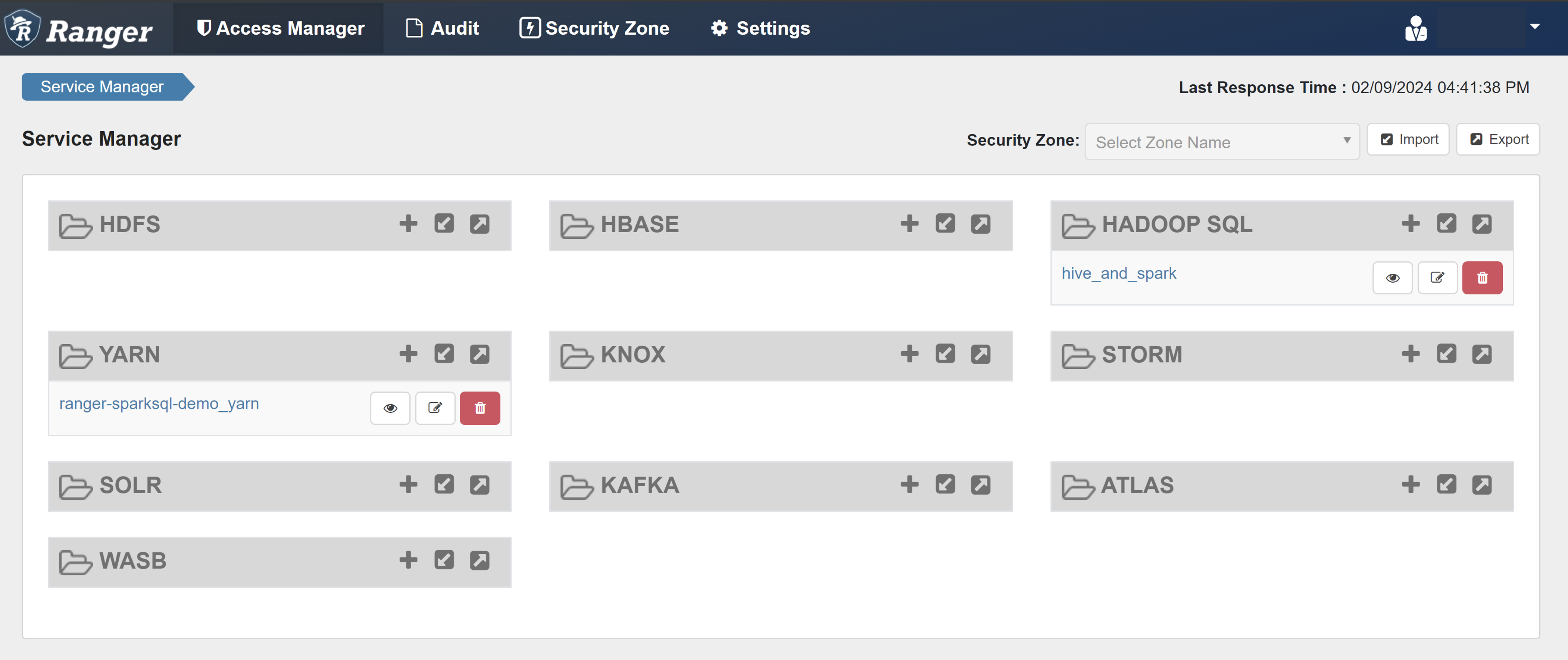
Öppna ranger-administratörsgränssnittet.
Under HADOOP SQL väljer du hive_and_spark.
På fliken Åtkomst väljer du Lägg till ny princip.
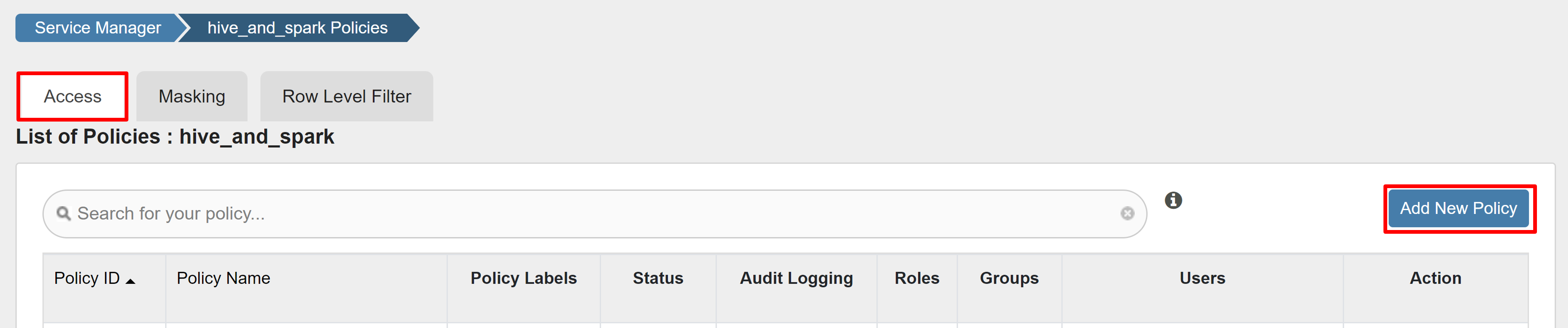
Ange följande värden:
Property Värde Principnamn read-hivesampletable-all database standard table hivesampletable column * Välj användare sparkuserBehörigheter välj 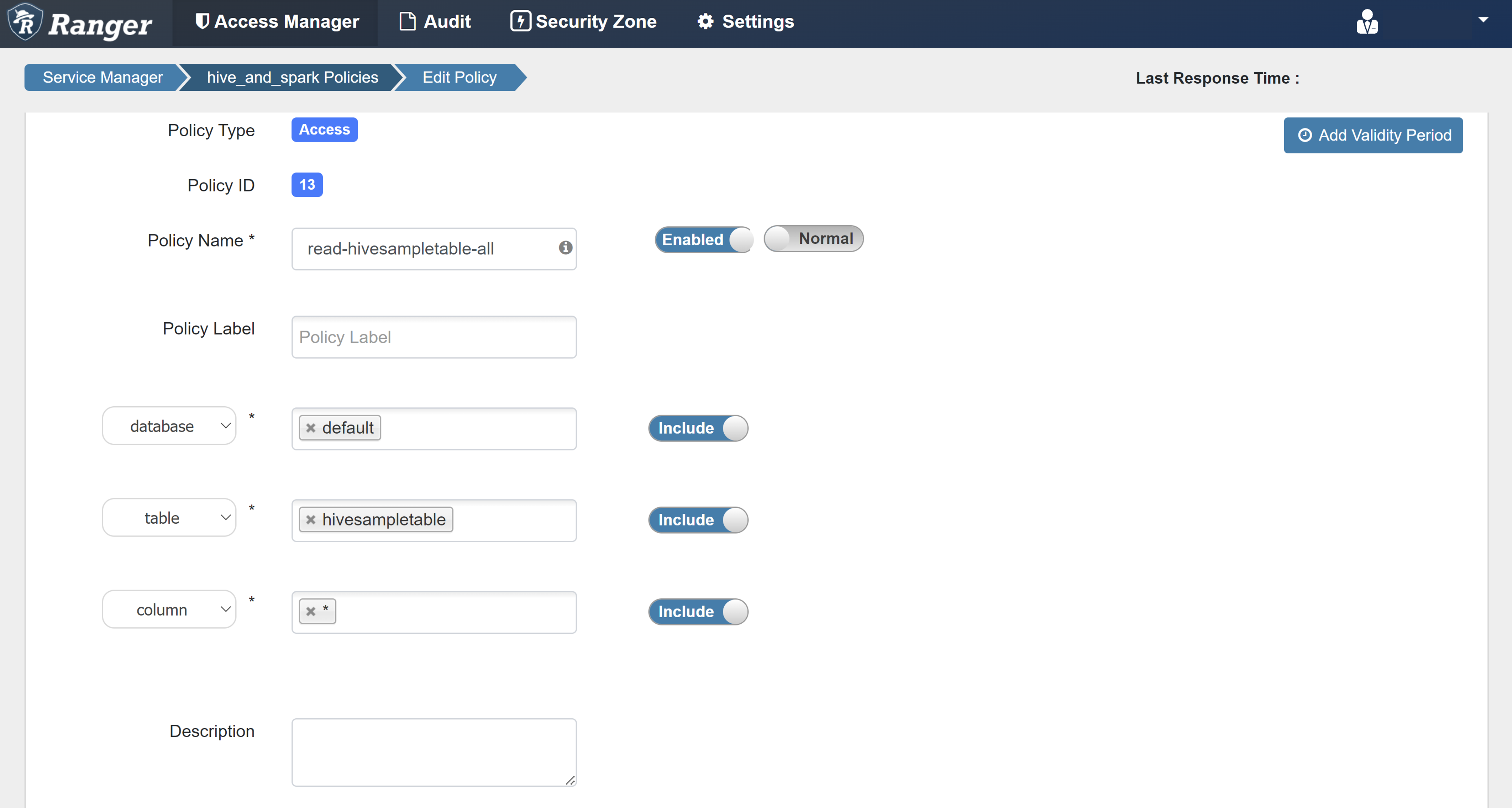
Om en domänanvändare inte fylls i automatiskt för Välj användare väntar du en stund tills Ranger synkroniserar med Microsoft Entra-ID.
Välj Lägg till för att spara principen.
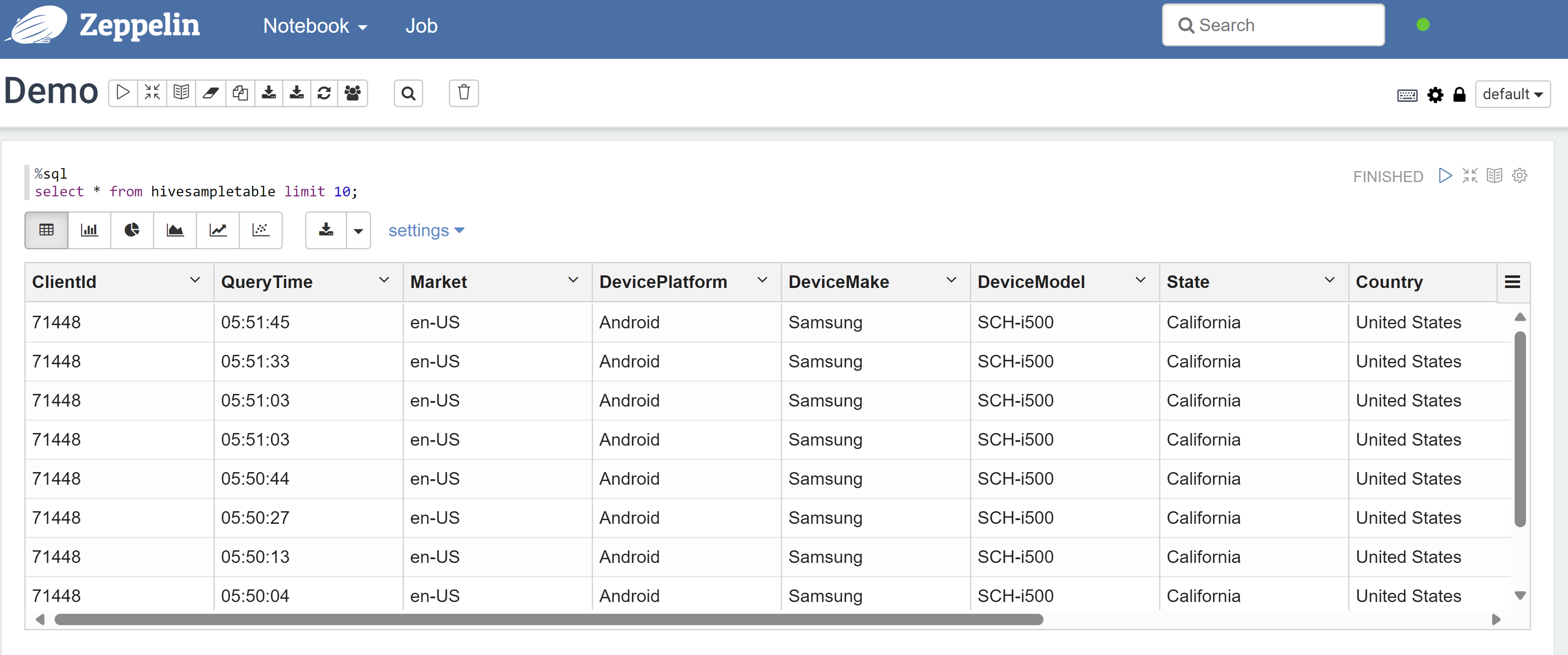
Öppna en Zeppelin-anteckningsbok och kör följande kommando för att verifiera principen:
%sql select * from hivesampletable limit 10;Här är resultatet innan en princip tillämpas:

Här är resultatet efter att en princip har tillämpats:




Skapa en rangermaskeringsprincip
I följande exempel visas hur du skapar en princip för att maskera en kolumn:
På fliken Maskering väljer du Lägg till ny princip.

Ange följande värden:
Property Värde Principnamn mask-hivesampletable Hive Database standard Hive-tabell hivesampletable Hive-kolumn devicemake Välj användare sparkuserÅtkomsttyper välj Välj maskeringsalternativ Hash 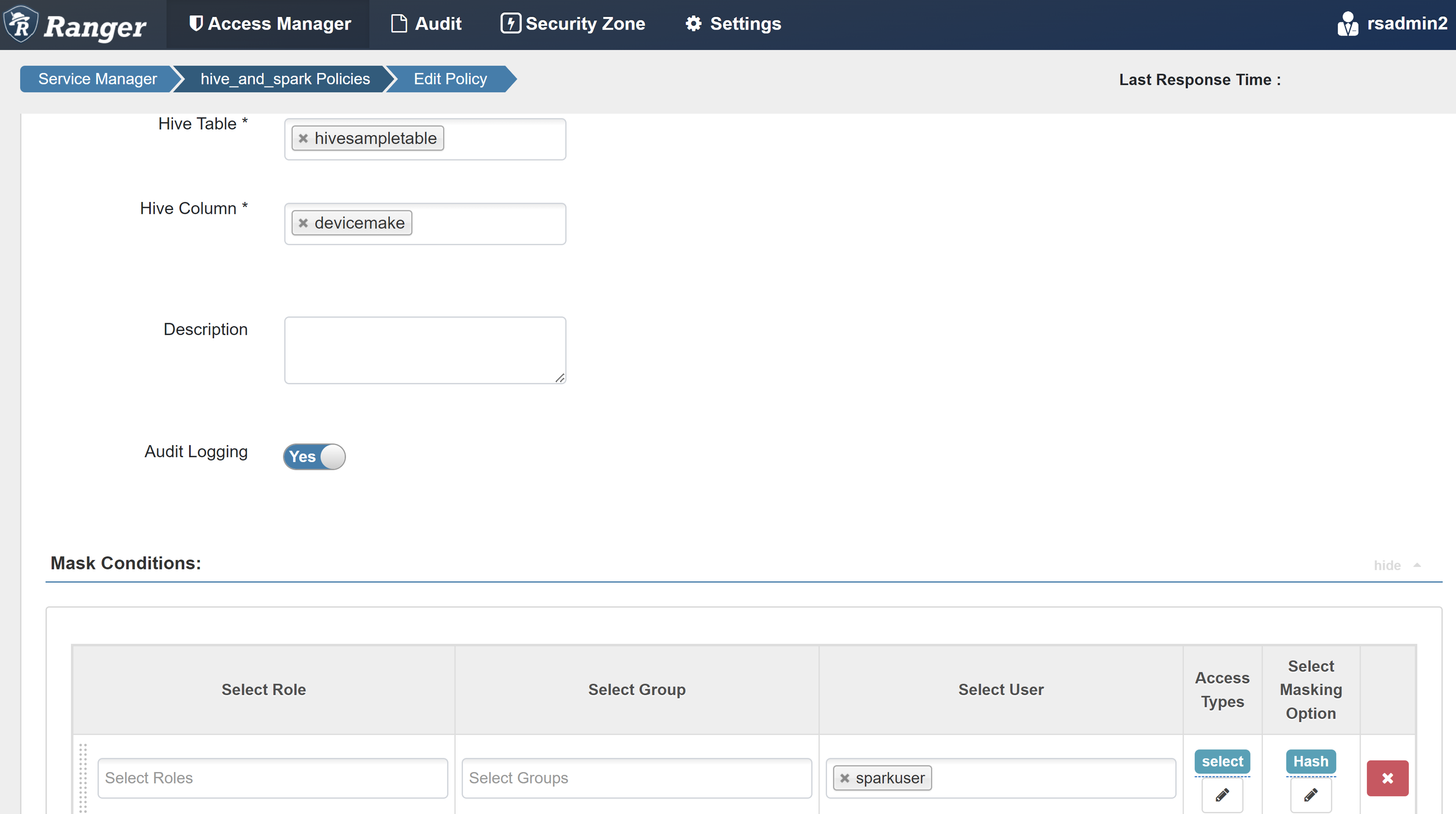
Välj Spara för att spara principen.
Öppna en Zeppelin-anteckningsbok och kör följande kommando för att verifiera principen:
%sql select clientId, deviceMake from hivesampletable;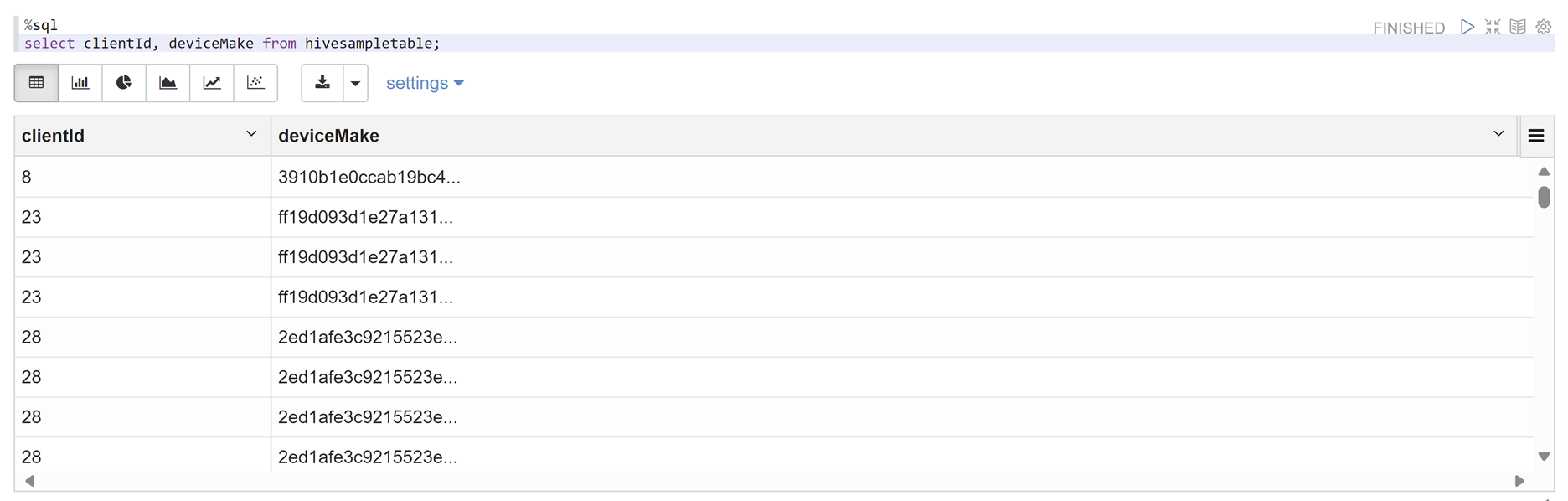



Kommentar
Som standard är principerna för Hive och Spark SQL vanliga i Ranger.
Tillämpa riktlinjer för att konfigurera Apache Ranger för Spark SQL
Följande scenarier utforskar riktlinjer för att skapa ett HDInsight 5.1 Spark-kluster med hjälp av en ny Ranger-databas och med hjälp av en befintlig Ranger-databas.
Scenario 1: Använd en ny Ranger-databas när du skapar ett HDInsight 5.1 Spark-kluster
När du använder en ny Ranger-databas för att skapa ett kluster skapas den relevanta Ranger-lagringsplatsen som innehåller Ranger-principerna för Hive och Spark under namnet hive_and_spark i Hadoop SQL-tjänsten på Ranger-databasen.

Om du redigerar principerna tillämpas de på både Hive och Spark.
Tänk på följande:
Om du har två metaarkivdatabaser med samma namn som används för både Hive-kataloger (till exempel DB1) och Spark -kataloger (till exempel DB1):
- Om Spark använder Spark-katalogen (
metastore.catalog.default=spark) tillämpas principerna på DB1-databasen i Spark-katalogen. - Om Spark använder Hive-katalogen (
metastore.catalog.default=hive) tillämpas principerna på DATABASEN DB1 i Hive-katalogen.
När det gäller Ranger finns det inget sätt att skilja mellan DB1 i Hive- och Spark-katalogerna.
I sådana fall rekommenderar vi att du antingen:
- Använd Hive-katalogen för både Hive och Spark.
- Underhålla olika databas-, tabell- och kolumnnamn för både Hive- och Spark-kataloger så att principerna inte tillämpas på databaser mellan kataloger.
- Om Spark använder Spark-katalogen (
Om du använder Hive-katalogen för både Hive och Spark bör du överväga följande exempel.
Anta att du skapar en tabell med namnet table1 via Hive med den aktuella xyz-användaren . Den skapar en HDFS-fil (Hadoop Distributed File System) med namnet table1.db vars ägare är xyz-användaren .
Anta nu att du använder användaren abc för att starta Spark SQL-sessionen. I den här sessionen av användaren abc, om du försöker skriva något till table1, kommer det säkert att misslyckas eftersom tabellägaren är xyz.
I sådana fall rekommenderar vi att du använder samma användare i Hive och Spark SQL för att uppdatera tabellen. Användaren bör ha tillräcklig behörighet för att utföra uppdateringsåtgärder.
Scenario 2: Använd en befintlig Ranger-databas (med befintliga principer) när du skapar ett HDInsight 5.1 Spark-kluster
När du skapar ett HDInsight 5.1-kluster med hjälp av en befintlig Ranger-databas skapas en ny Ranger-lagringsplats igen på den här databasen med namnet på det nya klustret i det här formatet: hive_and_spark.

Anta att du redan har definierat principerna i Ranger-lagringsplatsen under namnet oldclustername_hive på den befintliga Ranger-databasen i Hadoop SQL-tjänsten. Du vill dela samma principer i det nya HDInsight 5.1 Spark-klustret. Använd följande steg för att uppnå det här målet.
Kommentar
En användare som har administratörsbehörighet för Ambari kan utföra konfigurationsuppdateringar.
Öppna Ambari-användargränssnittet från ditt nya HDInsight 5.1-kluster.
Gå till Spark3-tjänsten och gå sedan till Konfigurationer.
Öppna konfigurationen Advanced ranger-spark-security .

eller Så kan du även öppna den här konfigurationen i /etc/spark3/conf med hjälp av SSH.
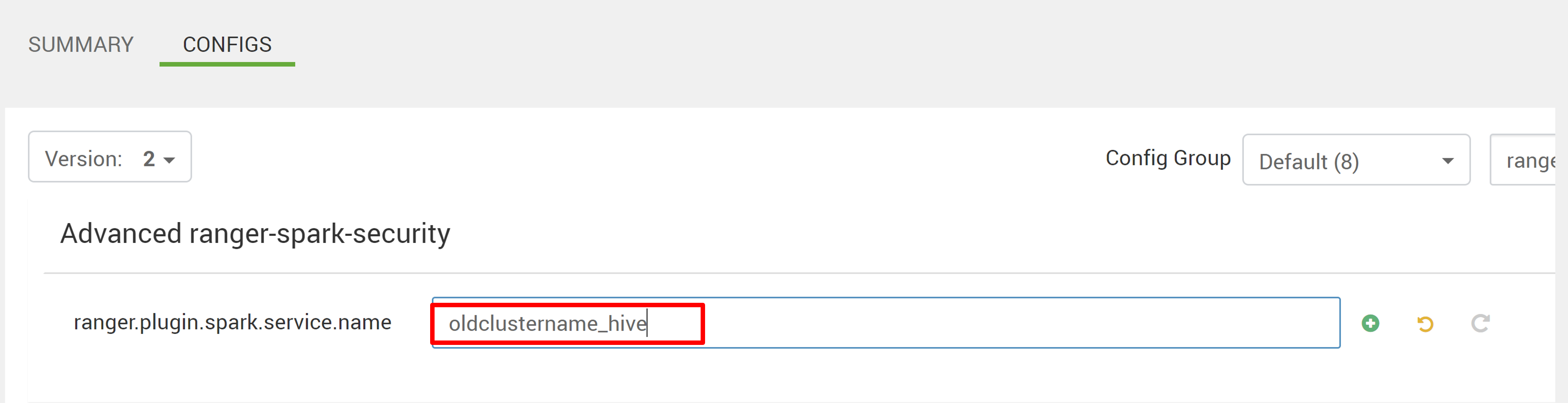
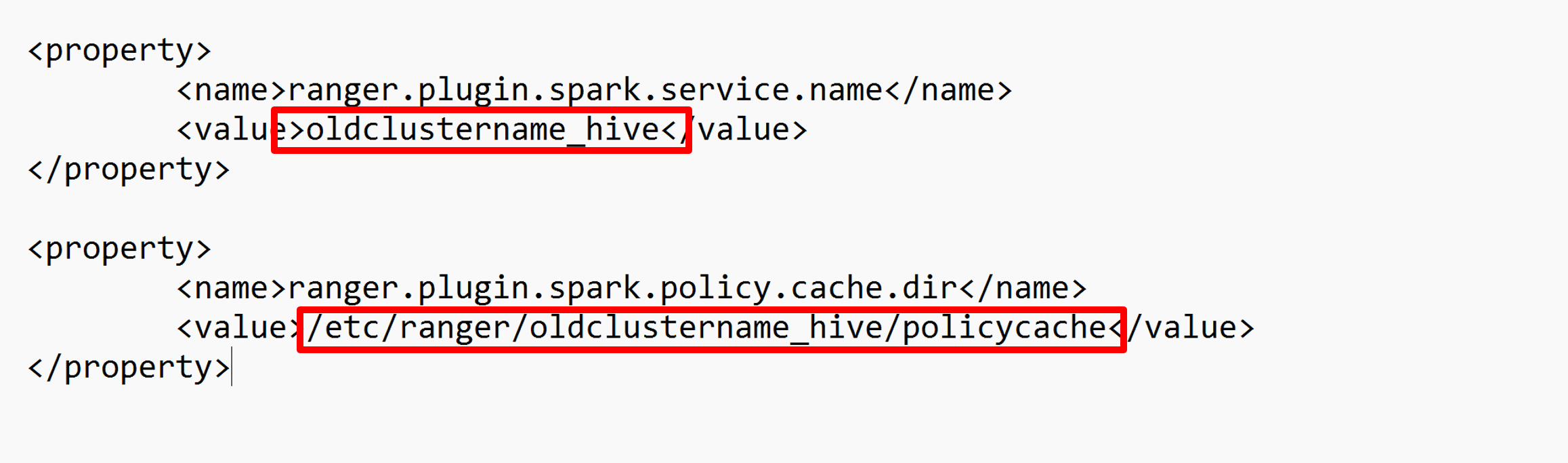
Redigera två konfigurationer (ranger.plugin.spark.service.name och ranger.plugin.spark.policy.cache.dir) för att peka på den gamla principlagringsplatsen oldclustername_hive och spara sedan konfigurationerna.
Ambari:
XML-fil:
Starta om Ranger- och Spark-tjänsterna från Ambari.
Öppna ranger-administratörsgränssnittet och klicka på knappen Redigera under HADOOP SQL-tjänsten .

För oldclustername_hive-tjänsten lägger du till rangersparklookup-användare i listan policy.download.auth.users och tag.download.auth.users och klickar på Spara.






Principerna tillämpas på databaser i Spark-katalogen. Om du vill komma åt databaserna i Hive-katalogen:
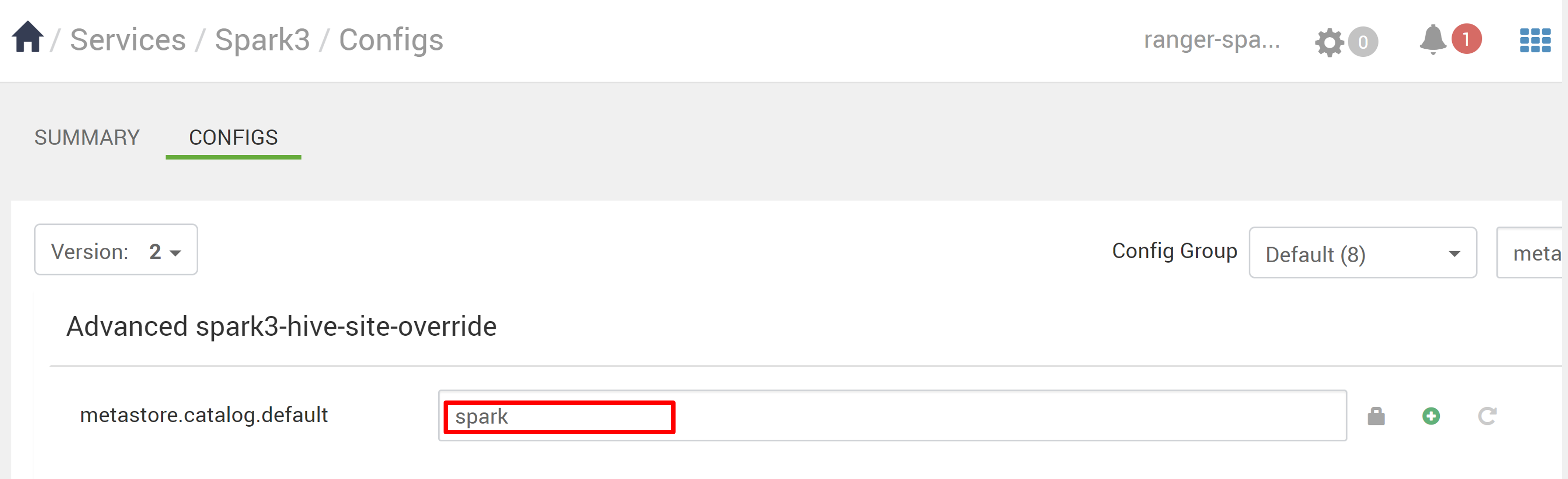
I Ambari går du till Spark3-konfigurationer>.
Ändra metastore.catalog.default från spark till hive.

Kända problem
- Apache Ranger-integrering med Spark SQL fungerar inte om Ranger-administratören är nere.
- När du hovrar över kolumnen Resurs i Ranger-granskningsloggar kan den inte visa hela frågan som du körde.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för