Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
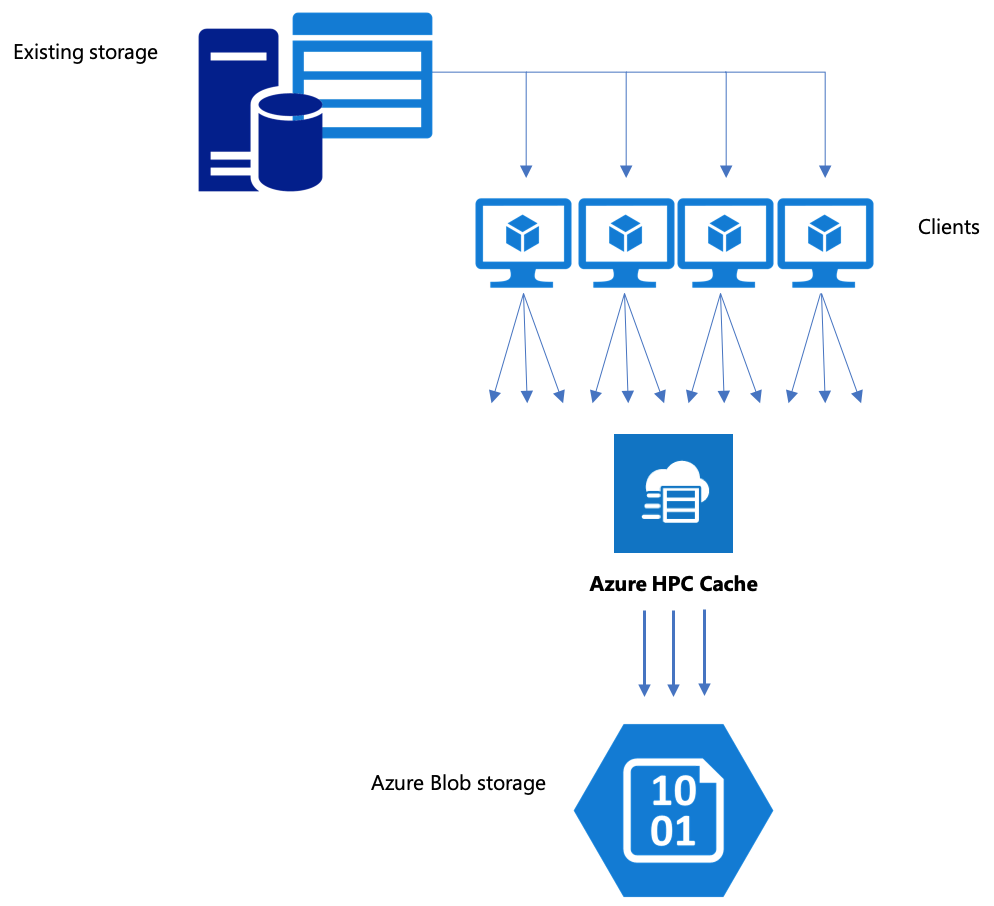
Om arbetsflödet inkluderar att flytta data till Azure Blob Storage kontrollerar du att du använder en effektiv strategi. Du bör skapa cachen, lägga till blobcontainern som lagringsmål och sedan kopiera dina data med Azure HPC Cache.
Den här artikeln beskriver de bästa sätten att flytta data till bloblagring för användning med Azure HPC Cache.
Dricks
Den här artikeln gäller inte för NFS-monterad bloblagring (ADLS-NFS-lagringsmål). Du kan använda valfri NFS-baserad metod för att fylla i en ADLS-NFS-blobcontainer före eller efter att du har lagt till den i HPC Cache. Läs förinlästa data med NFS-protokollet om du vill veta mer.
Tänk på följande fakta:
Azure HPC Cache använder ett specialiserat lagringsformat för att organisera data i bloblagring. Därför måste ett bloblagringsmål antingen vara en ny, tom container eller en blobcontainer som tidigare användes för Azure HPC Cache-data.
Det är effektivare att kopiera data via Azure HPC Cache till ett lagringsmål för serverdelen när du använder flera klienter och parallella åtgärder. Ett enkelt kopieringskommando från en klient flyttar data långsamt.
De strategier som beskrivs i den här artikeln fungerar för att fylla i en tom blobcontainer eller för att lägga till filer i ett tidigare använt lagringsmål.
Kopiera data via Azure HPC Cache
Azure HPC Cache är utformat för att hantera flera klienter samtidigt, så om du vill kopiera data via cacheminnet bör du använda parallella skrivningar från flera klienter.
De cp eller-kommandon copy som du vanligtvis använder för att överföra data från ett lagringssystem till ett annat är entrådade processer som endast kopierar en fil i taget. Det innebär att filservern bara matar in en fil i taget , vilket är slöseri med cachens resurser.
I det här avsnittet beskrivs strategier för att skapa ett filkopieringssystem med flera klienter och flera trådar för att flytta data till bloblagring med Azure HPC Cache. Den förklarar filöverföringsbegrepp och beslutspunkter som kan användas för effektiv datakopiering med flera klienter och enkla kopieringskommandon.
Det förklarar också några verktyg som kan hjälpa. Verktyget msrsync kan användas för att delvis automatisera processen att dela upp en datamängd i bucketar och använda rsync-kommandon. Skriptet parallelcp är ett annat verktyg som läser källkatalogen och utfärdar kopieringskommandon automatiskt.
Strategisk planering
När du skapar en strategi för att kopiera data parallellt bör du förstå kompromisserna i filstorlek, filantal och katalogdjup.
- När filerna är små är måttet av intresse filer per sekund.
- När filer är stora (10MiBi eller större) är måttet av intresse byte per sekund.
Varje kopieringsprocess har en dataflödeshastighet och en filöverföringshastighet, som kan mätas genom att tidsbegränsa längden på kopieringskommandot och beräkna filstorleken och antalet filer. Att förklara hur du mäter priserna ligger utanför omfånget för det här dokumentet, men det är absolut nödvändigt att förstå om du kommer att hantera små eller stora filer.
Strategier för parallell datamatning med Azure HPC Cache är:
Manuell kopiering – Du kan manuellt skapa en flertrådad kopia på en klient genom att köra mer än ett kopieringskommando samtidigt i bakgrunden mot fördefinierade uppsättningar med filer eller sökvägar. Mer information finns i Datamatning i Azure HPC Cache – manuell kopieringsmetod .
Delvis automatiserad kopiering med
msrsync-msrsyncär ett omslutningsverktyg som kör flera parallellarsyncprocesser. Mer information finns i Azure HPC Cache data ingest – msrsync-metoden.Skriptkopiering med
parallelcp– Lär dig hur du skapar och kör ett parallellt kopieringsskript i Azure HPC Cache-datamatning – parallell kopieringsskriptmetod.
Nästa steg
När du har konfigurerat lagringen får du lära dig hur klienter kan montera cacheminnet.