Vad är kontextualisering i förhandsversionen av Azure IoT Data Processor?
Viktigt!
Förhandsversion av Azure IoT Operations – aktiverad av Azure Arc finns för närvarande i FÖRHANDSVERSION. Du bör inte använda den här förhandsgranskningsprogramvaran i produktionsmiljöer.
Juridiska villkor för Azure-funktioner i betaversion, förhandsversion eller som av någon annan anledning inte har gjorts allmänt tillgängliga ännu finns i kompletterande användningsvillkor för Microsoft Azure-förhandsversioner.
Kontextualisering lägger till information i meddelanden i en pipeline. Kontextualisering kan:
- Förbättra värdet, innebörden och insikterna som härleds från data som flödar genom pipelinen.
- Utöka dina källdata så att de blir mer begripliga och meningsfulla.
- Gör det enklare att tolka dina data och underlätta ett mer korrekt och effektivt beslutsfattande.
Temperatursensorn i din fabrik skickar till exempel en datapunkt som läser 250 °F. Utan kontextualisering är det svårt att härleda någon betydelse från dessa data. Men om du lägger till kontext som "Temperaturen för ugnstillgången under morgonskiftet var 250 °F" ökar datavärdet avsevärt eftersom du nu kan härleda användbara insikter från den.
Kontextualiserade data ger en mer omfattande bild av åtgärderna som hjälper dig att fatta mer välgrundade beslut. Den sammanhangsbaserade informationen berikar data som gör dataanalys enklare. Det hjälper dig att optimera processer, förbättra effektiviteten och minska stilleståndstiden.
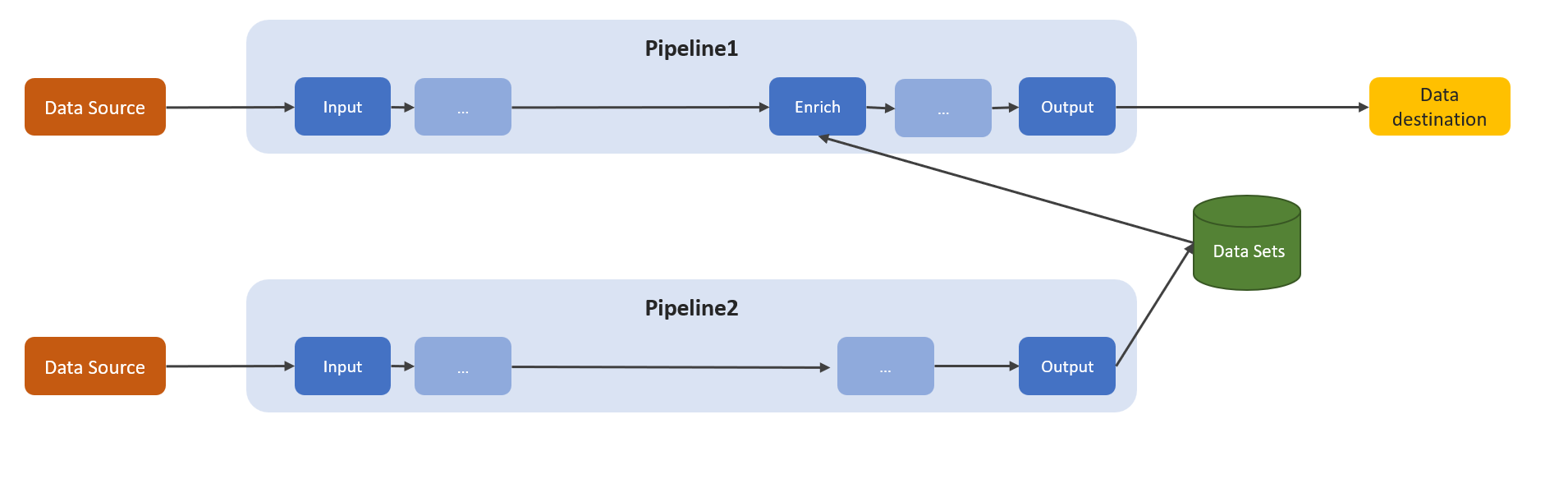
Meddelandeberikning
En azure IoT Data Processor Preview-pipeline kontextualiserar data genom att utöka meddelandena som flödar genom pipelinen med tidigare lagrade referensdata. Kontextualisering använder det inbyggda referensdatalagret. Du kan dela upp processen med att använda referensdatalagret i en pipeline i tre steg:
Skapa och konfigurera en datauppsättning. Det här steget skapar och konfigurerar dina datauppsättningar i referensdatalagret. Konfigurationen innehåller de nycklar som ska användas för kopplingar och förfalloprinciper för referensdata.
Mata in dina referensdata. När du har konfigurerat dina datauppsättningar är nästa steg att mata in data i referensdatalagret. Använd utdatasteget i referensdatapipelinen för att mata in data i dina datauppsättningar.
Utöka dina data. I ett berikande skede använder du data som lagras i referensdatalagret för att utöka data som passerar genom dataprocessorns pipeline. Den här processen förbättrar värdet och relevansen för data, vilket ger dig bättre insikter och förbättrade funktioner för dataanalys.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för