Extrahera N-Gram-funktioner från textkomponentreferensen
I den här artikeln beskrivs en komponent i Azure Machine Learning-designern. Använd komponenten Extrahera N-Gram-funktioner från text för att funktionalisera ostrukturerade textdata.
Konfiguration av komponenten Extrahera N-Gram-funktioner från text
Komponenten stöder följande scenarier för att använda en n-gram-ordlista:
Skapa en ny n-gram-ordlista från en kolumn med fritext.
Använd en befintlig uppsättning textfunktioner för att funktionalisera en fritextkolumn.
Poängsätt eller distribuera en modell som använder n-gram.
Skapa en ny n-gram-ordlista
Lägg till komponenten Extract N-Gram Features from Text (Extrahera N-Gram-funktioner från text) i pipelinen och anslut den datauppsättning som innehåller den text som du vill bearbeta.
Använd textkolumnen för att välja en kolumn av strängtyp som innehåller den text som du vill extrahera. Eftersom resultaten är utförliga kan du bara bearbeta en enda kolumn i taget.
Ange Ordförrådsläge till Skapa för att ange att du skapar en ny lista över n-gram-funktioner.
Ange N-gramstorlek för att ange den maximala storleken på n-gram som ska extraheras och lagras.
Om du till exempel anger 3 skapas unigram, bigrams och trigram.
Viktningsfunktionen anger hur du skapar dokumentets funktionsvektor och hur du extraherar vokabulär från dokument.
Binär vikt: Tilldelar ett binärt närvarovärde till extraherade n-gram. Värdet för varje n-gram är 1 när det finns i dokumentet och 0 i övrigt.
TF-vikt: Tilldelar en TF-poäng (termfrekvens) till extraherade n-gram. Värdet för varje n-gram är dess förekomstfrekvens i dokumentet.
IDF-vikt: Tilldelar en IDF-poäng (inverterad dokumentfrekvens) till extraherade n-gram. Värdet för varje n-gram är loggen med corpusstorlek dividerat med dess förekomstfrekvens i hela korpusen.
IDF = log of corpus_size / document_frequencyTF-IDF-vikt: Tilldelar en tf/IDF-poäng (termfrekvens/inverterad dokumentfrekvens) till extraherade n-gram. Värdet för varje n-gram är dess TF-poäng multiplicerat med dess IDF-poäng.
Ange Minsta ordlängd till det minsta antalet bokstäver som kan användas i valfritt enstaka ord i ett n-gram.
Använd Maximal ordlängd för att ange det maximala antalet bokstäver som kan användas i valfritt enstaka ord i ett n-gram.
Som standard tillåts upp till 25 tecken per ord eller token.
Använd minsta n-gram dokument absolut frekvens för att ange de minsta förekomster som krävs för n-gram som ska ingå i ordlistan n-gram.
Om du till exempel använder standardvärdet 5 måste alla n-gram visas minst fem gånger i corpus för att inkluderas i ordlistan n-gram.
Ange Maximalt n-gram dokumentförhållande till det maximala förhållandet mellan antalet rader som innehåller ett visst n-gram, över antalet rader i den övergripande korpusen.
Till exempel skulle förhållandet 1 indikera att även om ett specifikt n-gram finns i varje rad, kan n-gram läggas till i ordlistan n-gram. Vanligtvis skulle ett ord som förekommer på varje rad betraktas som ett brusord och tas bort. Om du vill filtrera bort domänberoende brusord kan du prova att minska det här förhållandet.
Viktigt
Förekomsten av vissa ord är inte enhetlig. Det varierar från dokument till dokument. Om du till exempel analyserar kundkommenterar om en viss produkt kan produktnamnet vara mycket högt och nära ett brusord, men vara en viktig term i andra sammanhang.
Välj alternativet Normalisera n-gram-funktionsvektorer för att normalisera funktionsvektorerna. Om det här alternativet är aktiverat delas varje n-gram funktionsvektor med dess L2-norm.
Skicka pipelinen.
Använda en befintlig n-gram-ordlista
Lägg till komponenten Extrahera N-Gram-funktioner från text i pipelinen och anslut den datauppsättning som innehåller den text som du vill bearbeta till datauppsättningsporten .
Använd textkolumnen för att markera den textkolumn som innehåller den text som du vill funktionalisera. Som standard väljer komponenten alla kolumner av typen sträng. För bästa resultat kan du bearbeta en enskild kolumn i taget.
Lägg till den sparade datauppsättningen som innehåller en tidigare genererad n-gram-ordlista och anslut den till porten för vokabulär för indata . Du kan också ansluta resultatförrådsutdata från en överordnad instans av komponenten Extract N-Gram Features from Text (Extrahera N-Gram-funktioner från text).
För Vokabulärläge väljer du alternativet ReadOnly update i listrutan.
Alternativet ReadOnly representerar indatakorusen för indatavokabulären. I stället för att beräkna termfrekvenser från den nya textdatauppsättningen (till vänster) tillämpas n-gram-vikterna från indatavokabulären som de är.
Tips
Använd det här alternativet när du poängsätter en textklassificerare.
Alla andra alternativ finns i egenskapsbeskrivningarna i föregående avsnitt.
Skicka pipelinen.
Skapa en slutsatsdragningspipeline som använder n-gram för att distribuera en realtidsslutpunkt
En träningspipeline som innehåller funktionen Extrahera N-gram från text - och poängmodellen för att göra förutsägelser på testdatauppsättningen är inbyggd i följande struktur:
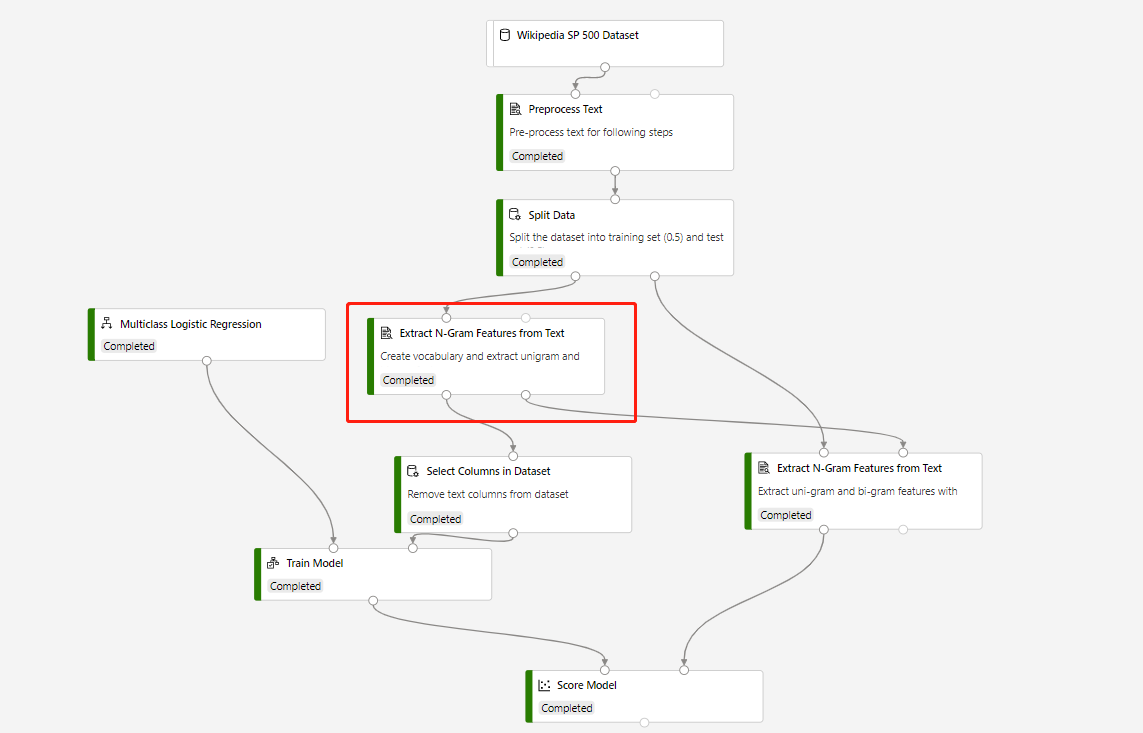
Ordförrådsläget för den inringade funktionen Extrahera N-gram från text-komponenten är Skapa, och vokabulärläget för komponenten som ansluter till komponenten Poängsätta modell är ReadOnly.
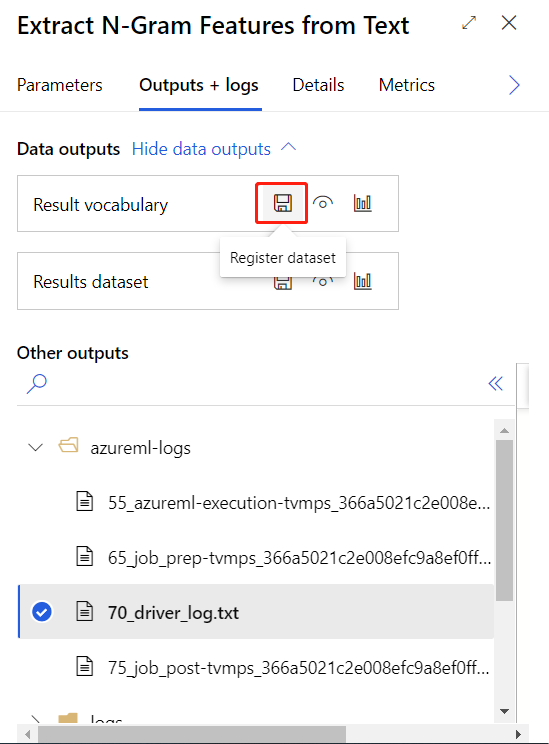
När du har skickat träningspipelinen ovan kan du registrera utdata för den inringade komponenten som datauppsättning.
Sedan kan du skapa en pipeline för slutsatsdragning i realtid. När du har skapat en slutsatsdragningspipeline måste du justera din slutsatsdragningspipeline manuellt så här:
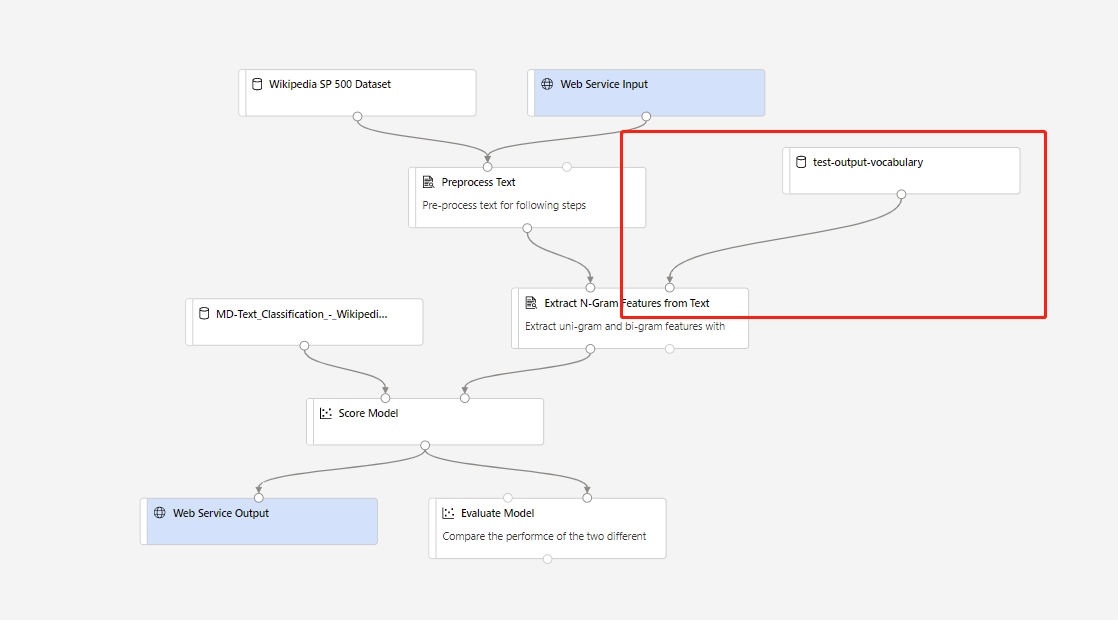
Skicka sedan slutsatsdragningspipelinen och distribuera en realtidsslutpunkt.
Resultat
Komponenten Extrahera N-Gram-funktioner från text skapar två typer av utdata:
Resultatdatauppsättning: Dessa utdata är en sammanfattning av den analyserade texten i kombination med n-gram som extraherades. Kolumner som du inte valde i alternativet Textkolumn skickas till utdata. För varje textkolumn som du analyserar genererar komponenten dessa kolumner:
- Matris med n-gram-förekomster: Komponenten genererar en kolumn för varje n-gram som finns i det totala antalet corpus och lägger till en poäng i varje kolumn för att ange vikten på n-gram för den raden.
Resultatvokabulär: Vokabulären innehåller den faktiska n-gram-ordlistan, tillsammans med termfrekvenspoängen som genereras som en del av analysen. Du kan spara datauppsättningen för återanvändning med en annan uppsättning indata eller för en senare uppdatering. Du kan också återanvända vokabulären för modellering och bedömning.
Vokabulär för resultat
Vokabulären innehåller ordlistan n-gram med de termfrekvenspoäng som genereras som en del av analysen. DF- och IDF-poängen genereras oavsett andra alternativ.
- ID: En identifierare som genereras för varje unikt n-gram.
- NGram: N-gram. Blanksteg eller andra ordavgränsare ersätts med understreckstecknet.
- DF: Termfrekvenspoängen för n-gram i den ursprungliga korpusen.
- IDF: Inverterad dokumentfrekvenspoäng för n-gram i den ursprungliga korpusen.
Du kan uppdatera den här datauppsättningen manuellt, men du kan introducera fel. Exempel:
- Ett fel utlöses om komponenten hittar dubblettrader med samma nyckel i indatavokabulären. Se till att inga två rader i vokabulären har samma ord.
- Indataschemat för vokabulärdatauppsättningarna måste matcha exakt, inklusive kolumnnamn och kolumntyper.
- ID-kolumnen och DF-kolumnen måste vara av heltalstyp.
- IDF-kolumnen måste vara av flyttaltyp.
Anteckning
Anslut inte datautdata till komponenten Train Model direkt. Du bör ta bort kolumner med fritext innan de matas in i träningsmodellen. Annars behandlas kolumnerna med fritext som kategoriska funktioner.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.