Använda virtuella datorer med låg prioritet i batchdistributioner
GÄLLER FÖR: Azure CLI ml extension v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure Batch Distributioner stöder virtuella datorer med låg prioritet för att minska kostnaden för batchinferensarbetsbelastningar. Virtuella datorer med låg prioritet gör det möjligt att använda en stor mängd beräkningskraft för en låg kostnad. Virtuella datorer med låg prioritet drar nytta av överkapacitet i Azure. När du anger virtuella datorer med låg prioritet i dina pooler kan Azure använda det här överskottet när det är tillgängligt.
Kompromissen med att använda dem är att de virtuella datorerna kanske inte alltid är tillgängliga för allokering, eller att de kan föregripas när som helst, beroende på tillgänglig kapacitet. Därför är de lämpligast för batch- och asynkrona bearbetningsarbetsbelastningar där jobbets slutförandetid är flexibel och arbetet distribueras över många virtuella datorer.
Virtuella datorer med låg prioritet erbjuds till ett betydligt lägre pris jämfört med dedikerade virtuella datorer. Prisinformation finns i Priser för Azure Machine Learning.
Så här fungerar batchdistribution med virtuella datorer med låg prioritet
Azure Machine Learning Batch Deployments innehåller flera funktioner som gör det enkelt att använda och dra nytta av virtuella datorer med låg prioritet:
- Batch-distributionsjobb förbrukar virtuella datorer med låg prioritet genom att köra på Azure Machine Learning-beräkningskluster som skapats med virtuella datorer med låg prioritet. När en distribution är associerad med ett kluster med låg prioritet för virtuella datorer använder alla jobb som skapas av en sådan distribution virtuella datorer med låg prioritet. Konfiguration per jobb är inte möjligt.
- Batch-distributionsjobb söker automatiskt efter målantalet virtuella datorer i det tillgängliga beräkningsklustret baserat på antalet uppgifter som ska skickas. Om virtuella datorer är förinställda eller otillgängliga försöker batchdistributionsjobb ersätta den förlorade kapaciteten genom att köa de misslyckade uppgifterna till klustret.
- Virtuella datorer med låg prioritet har en separat vCPU-kvot som skiljer sig från den för dedikerade virtuella datorer. Lågprioritetskärnor per region har en standardgräns på 100 till 3 000, beroende på vilken typ av prenumerationserbjudande du har. Antalet lågprioritetskärnor per prenumeration kan ökas och är ett enskilt värde för VM-familjer. Se Beräkningskvoter för Azure Machine Learning.
Överväganden och användningsfall
Många batcharbetsbelastningar passar bra för virtuella datorer med låg prioritet. Även om detta kan medföra ytterligare körningsfördröjningar när frigörande av virtuella datorer sker, kan potentiella kapacitetssänkningar tolereras på kostnader för att köras med en lägre kostnad om det finns flexibilitet i tiden jobb måste slutföra.
När du distribuerar modeller under batchslutpunkter kan du schemalägga om på batchnivå. Det har den extra fördelen att frigöring endast påverkar de mini-batchar som för närvarande bearbetas och inte slutförs på den berörda noden. Alla slutförda förlopp behålls.
Skapa batchdistributioner med virtuella datorer med låg prioritet
Batch-distributionsjobb förbrukar virtuella datorer med låg prioritet genom att köra på Azure Machine Learning-beräkningskluster som skapats med virtuella datorer med låg prioritet.
Anteckning
När en distribution är associerad med ett kluster med låg prioritet för virtuella datorer använder alla jobb som skapas av en sådan distribution virtuella datorer med låg prioritet. Konfiguration per jobb är inte möjligt.
Du kan skapa ett Azure Machine Learning-beräkningskluster med låg prioritet på följande sätt:
Skapa en beräkningsdefinition YAML som liknar följande:
low-pri-cluster.yml
$schema: https://azuremlschemas.azureedge.net/latest/amlCompute.schema.json
name: low-pri-cluster
type: amlcompute
size: STANDARD_DS3_v2
min_instances: 0
max_instances: 2
idle_time_before_scale_down: 120
tier: low_priority
Skapa beräkningen med följande kommando:
az ml compute create -f low-pri-cluster.yml
När du har skapat den nya beräkningen kan du skapa eller uppdatera distributionen så att den använder det nya klustret:
Om du vill skapa eller uppdatera en distribution under det nya beräkningsklustret skapar du en YAML konfiguration som liknar följande:
$schema: https://azuremlschemas.azureedge.net/latest/batchDeployment.schema.json
endpoint_name: heart-classifier-batch
name: classifier-xgboost
description: A heart condition classifier based on XGBoost
type: model
model: azureml:heart-classifier@latest
compute: azureml:low-pri-cluster
resources:
instance_count: 2
settings:
max_concurrency_per_instance: 2
mini_batch_size: 2
output_action: append_row
output_file_name: predictions.csv
retry_settings:
max_retries: 3
timeout: 300
Skapa sedan distributionen med följande kommando:
az ml batch-endpoint create -f endpoint.yml
Visa och övervaka nodallokering
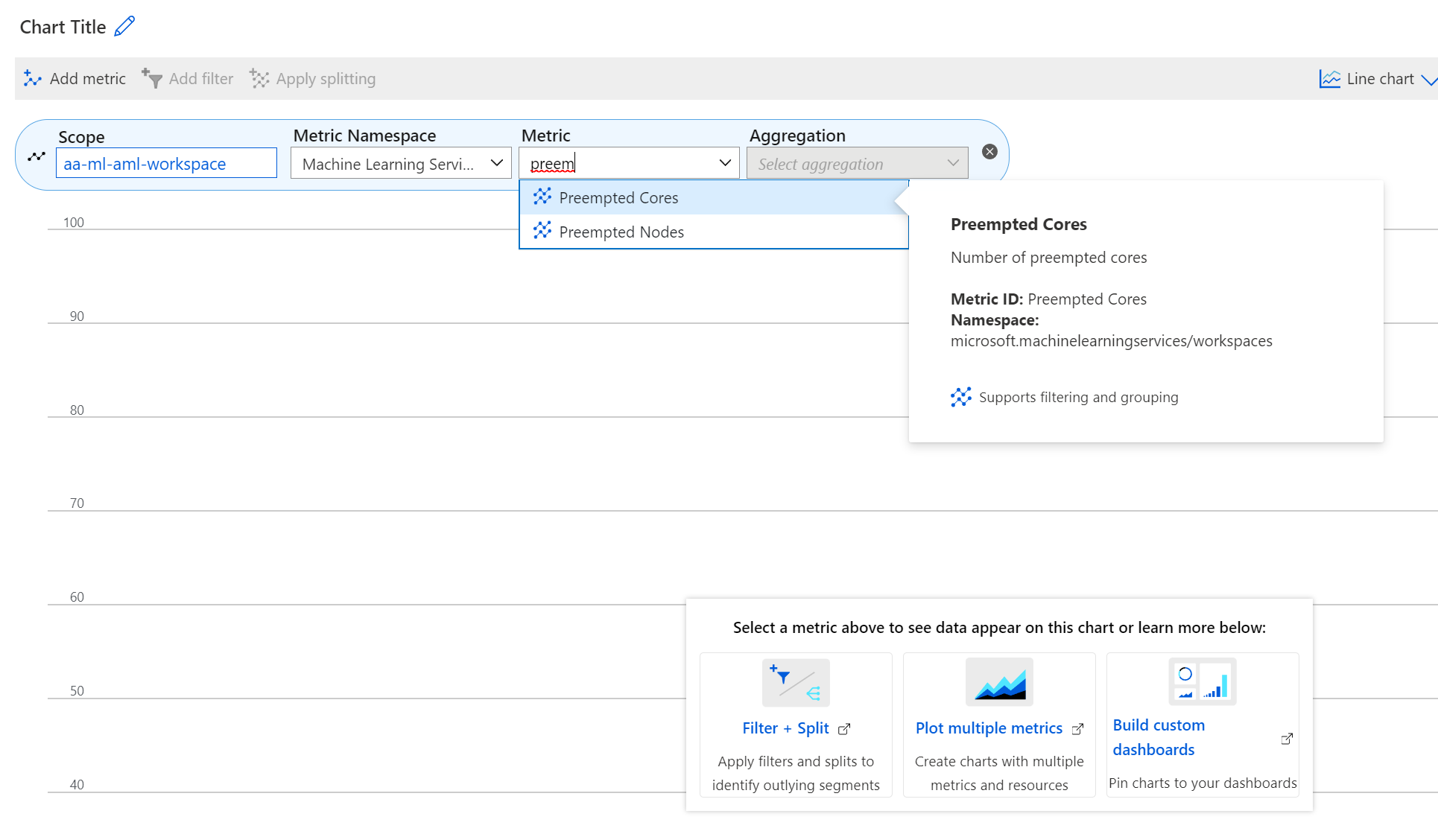
Nya mått är tillgängliga i Azure Portal för virtuella datorer med låg prioritet för att övervaka virtuella datorer med låg prioritet. Dessa mått är:
- Förinstallerade noder
- Förinstallerade kärnor
Så här visar du dessa mått i Azure Portal
- Gå till din Azure Machine Learning-arbetsyta i Azure Portal.
- Välj Mått i avsnittet Övervakning .
- Välj de mått som du vill använda i listan Mått .
Begränsningar
- När en distribution är associerad med ett kluster med låg prioritet för virtuella datorer använder alla jobb som skapas av en sådan distribution virtuella datorer med låg prioritet. Konfiguration per jobb är inte möjligt.
- Omplanering görs på mini-batch-nivå, oavsett förloppet. Det finns ingen kontrollpunktsfunktion.
Varning
I de fall då hela klustret är förinstallerat (eller körs på ett kluster med en nod) avbryts jobbet eftersom det inte finns någon tillgänglig kapacitet för att köra det. Omprenumerering krävs i det här fallet.