Självstudie 2: Träna kreditriskmodeller – Machine Learning Studio (klassisk)
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
I den här självstudien tittar vi närmare på hur du utvecklar en lösning för förutsägelseanalys. Du utvecklar en enkel modell i Machine Learning Studio (klassisk). Sedan distribuerar du modellen som en Machine Learning-webbtjänst. Den här distribuerade modellen kan göra förutsägelser med nya data. Självstudien är del två i en självstudieserie i tre delar.
Anta att du behöver förutsäga kreditrisken för en person baserat på den information som han eller hon fyller i på en kreditansökan.
Kreditriskbedömning är ett komplext problem, men den här självstudien kommer att förenkla processen. Du använder den som ett exempel på hur du kan skapa en lösning för förutsägelseanalys med hjälp av Machine Learning Studio (klassisk). Du använder Machine Learning Studio (klassisk) och en Machine Learning-webbtjänst för den här lösningen.
I den här självstudien i tre delar börjar du med offentligt tillgängliga kreditriskdata. Därefter utvecklar du och tränar en förutsägelsemodell. Slutligen distribuerar du modellen som en webbtjänst.
I del ett av självstudien skapade du en Machine Learning Studio-arbetsyta (klassisk), laddade upp data och skapade ett experiment.
I den här delen av självstudien ska du:
- Träna flera modeller
- Poängsätta och utvärdera modellerna
I del tre av självstudien ska du distribuera modellen som en webbtjänst.
Förutsättningar
Slutför del ett av självstudien.
Träna flera modeller
En av fördelarna med att använda Machine Learning Studio (klassisk) för att skapa maskininlärningsmodeller är möjligheten att prova mer än en typ av modell i taget i ett enda experiment och jämföra resultaten. Den här typen av experimentering hjälper dig att hitta den bästa lösningen för ditt problem.
I experimentet som vi utvecklar i den här självstudien ska du skapa två olika typer av modeller och sedan jämföra deras bedömningsresultat för att avgöra vilken algoritm som du vill använda i vårt slutliga experiment.
Det finns olika modeller som du kan välja mellan. Du visar de tillgängliga modellerna genom att expandera noden Machine Learning på modulpaletten och sedan Initialize Model (Initiera modell) och noderna under den. I det här experimentet ska du välja modulerna Tvåklassig dator för vektorstöd (SVM) och Tvåklassigt förbättrat beslutsträd.
Du ska lägga till både modulen Tvåklassigt förbättrat beslutsträd och modulen Tvåklassig dator för vektorstöd i det här experimentet.
Tvåklassigt förbättrat beslutsträd
Först konfigurerar du modellen för det förbättrade beslutsträdet.
Leta upp modulen Tvåklassigt förbättrat beslutsträd på modulpaletten och dra den till arbetsytan.
Leta upp träningsmodellmodulen, dra den till arbetsytan och anslut den sedan till utdata från modulen Tvåklassigt förbättrat beslutsträd till vänster indataport för träningsmodellmodulen.
Modulen Tvåklassigt förbättrat beslutsträd initierar den allmänna modellen, och träningsmodellen använder träningsdata för att träna modellen.
Anslut den vänstra Kör R-skript-modulens utdataport till den högra träningsmodellmodulens indataport (i den här självstudien använde du data från vänster sida av modulen Dela data för träning).
Tips
Du behöver inte två av dessa indata och en av Kör R-skript-modulens utdata i det här experimentet, så du kan lämna dem frånkopplade.
Nu ser den här delen av experimentet ut ungefär så här:
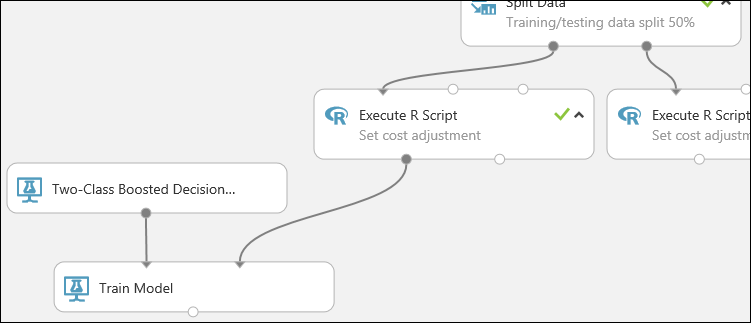
Nu måste du meddela träningsmodellmodulen att du vill att modellen ska förutsäga kreditriskvärdet.
Välj träningsmodellmodulen. Klicka på Starta kolumnväljaren i fönstret Egenskaper.
I dialogrutan Select a single column (Välj en enskild kolumn) skriver du ”credit risk” (kreditrisk) i sökfältet under Tillgängliga kolumner, väljer ”Credit risk” nedan och klickar sedan på högerpilen (>) för att flytta ”Credit risk” till Valda kolumner.
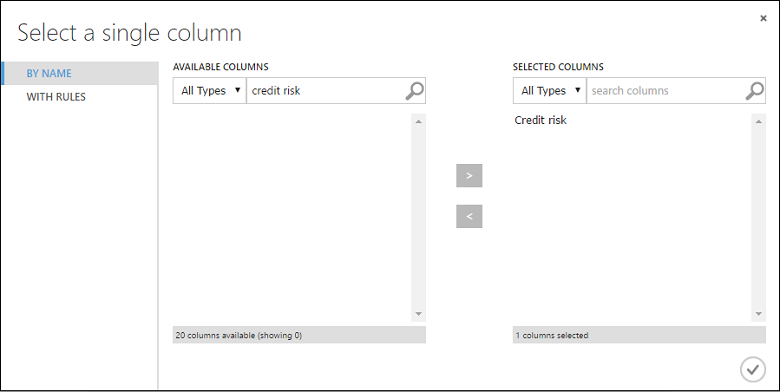
Klicka på kryssmarkeringen OK.
Tvåklassig dator för vektorstöd
Nu ska du ställa in SVM-modellen.
Men först en kort beskrivning av SVM. Förbättrade beslutsträd fungerar bra med alla slags funktioner. Men eftersom SVM-modulen genererar en linjär klassificerare, har modellen som den genererar det bästa testfelet när alla numeriska funktioner har samma skala. Om du vill konvertera alla numeriska funktioner till samma skala använder du en ”Tanh”-transformation (med modulen Normalisera data). På så sätt omvandlas våra tal till intervallet [0,1]. SVM-modulen konverterar strängfunktioner till kategoriska funktioner och sedan till binära 0/1-funktioner, så att du inte behöver transformera strängfunktioner manuellt. Dessutom vill du inte transformera kolumnen Credit Risk (kolumn 21) – den är numerisk, men det är det värdet som vi tränar modellen att förutsäga, så du lämnar det som det är.
För att konfigurera SVM-modellen gör du följande:
Leta upp modulen Tvåklassig dator för stödvektor på modulpaletten och dra den till arbetsytan.
Högerklicka på träningsmodellmodulen, välj Kopiera och högerklicka sedan på arbetsytan och välj Klistra in. Kopian av träningsmodellmodulen har samma kolumnurval som originalet.
Anslut utdata från modulen tvåklassig dator för stödvektor till den andra träningsmodellmodulens vänstra indataport.
Leta upp modulen Normalize Data (Normalisera data) och dra den till arbetsytan.
Anslut vänster utdata från Kör R-skript-modulens vänstra utdata till indata för den här modulen (observera att utdataporten för en modul kan anslutas till mer än en modul).
Anslut den vänstra utdataporten för modulen Normalize Data (Normalisera data) till den andra träningsmodellmodulens högra indataport.
Den här delen av vårt experiment bör nu se ut ungefär så här:
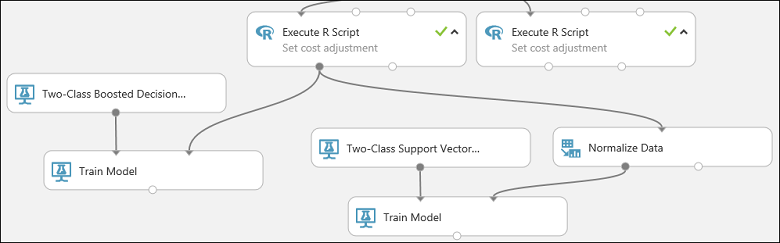
Konfigurera nu modulen Normalize Data (Normalisera data):
Klicka för att välja modulen Normalize Data (Normalisera data). I fönstret Egenskaper väljer du Tanh för parametern Transformation method (Transformeringsmetod).
Klicka på Starta kolumnväljaren, välj ”Inga kolumner” för Börja med, välj Inkludera i den första listrutan, välj kolumntyp i den andra listrutan och välj Numerisk i den tredje listrutan. Detta anger att alla numeriska kolumner (endast numeriska) transformeras.
Klicka på plustecknet (+) till höger om den här raden – när du gör det skapas en rad med listrutor. Välj Exkludera i den första listrutan, välj kolumnnamn i den andra listrutan och ange ”Credit Risk” (Kreditrisk) i textfältet. Detta anger att kolumnen Credit Risk (Kreditrisk) bör ignoreras (du måste göra detta eftersom den här kolumnen är numerisk och därför skulle transformeras om du inte uteslöt den).
Klicka på kryssmarkeringen OK.
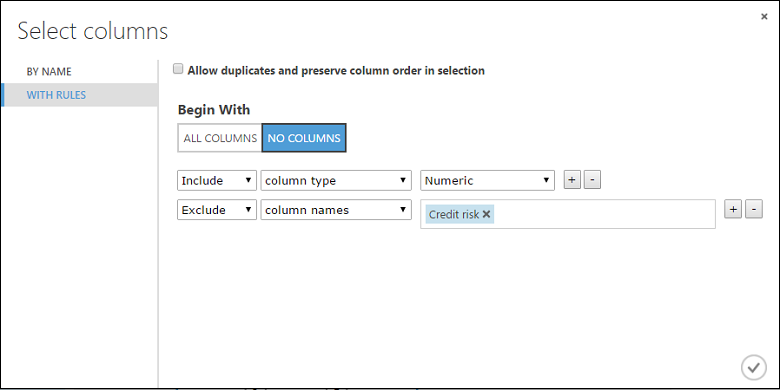
Nu är modulen Normalize Data inställd på att utföra en Tanh-transformering på alla numeriska kolumner utom för kolumnen Credit Risk (Kreditrisk).
Poängsätta och utvärdera modellerna
Du bedömer våra tränade modeller genom att använda de testdata som separerades ut av modulen Dela data. Du kan sedan jämföra resultaten av de två modellerna för att se vilken som genererat bäst resultat.
Lägga till modulerna av typen Poängsätta modell
Leta upp modulen Poängsätta modell och dra den till arbetsytan.
Anslut träningsmodellmodulen som är ansluten till modulen Tvåklassigt förbättrat beslutsträd till den vänstra indataporten för modulen Poängsätta modell.
Anslut den högra Kör R-skript-modulen (våra testdata) till höger indataport för modulen Poängsätta modell.
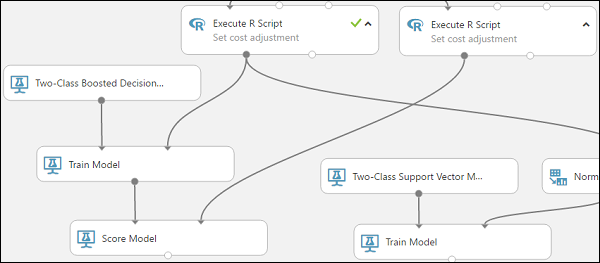
Nu kan modulen Poängsätta modell hämta kreditinformationen från testdata, köra den genom modellen och jämföra de förutsägelser som modellen genererar med den faktiska kreditriskkolumnen i testdata.
Kopiera och klistra in modulen Poängsätta modell för att skapa en andra kopia.
Anslut utdataporten för SVM-modellen (det vill säga utdataporten för träningsmodellmodulen som är ansluten till modulen Tvåklassig dator för stödvektor) till indataporten för den andra Poängsätta modell-modulen.
För SVM-modellen måste du göra samma transformering av testdata som du gjorde för träningsdata. Så, du kopierar och klistrar in modulen Normalize Data (Normalisera data) för att skapa en andra kopia och ansluter den till den högra Kör R-skript-modulen.
Anslut vänster utdata för den andra Normalize Data-modulen (Normalisera data) till höger indataport för den andra Poängsätta modell-modulen.
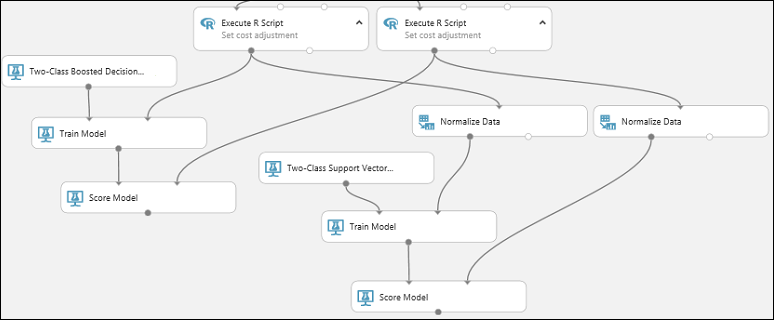
Lägga till modulen Utvärdera modell
För att utvärdera de två bedömningsresultaten och jämföra dem använder du modulen Utvärdera modell.
Leta upp modulen Utvärdera modell och dra den till arbetsytan.
Anslut utdataporten för modulen Poängsätta modell som är associerad med modellen för det förbättrade beslutsträdet till den vänstra indataporten för modulen Utvärdera modell.
Anslut den andra Poängsätta modell-modulen till den högra indataporten.
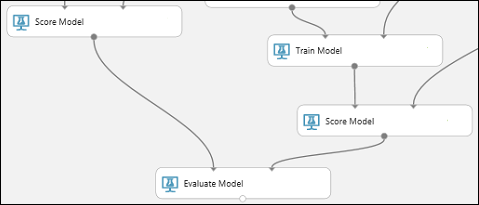
Kör experimentet och kontrollera resultaten
Kör experimentet genom att klicka på knappen Kör nedanför arbetsytan. Det kan ta några minuter. En snurrande indikator på varje modul anger att den körs. Därefter visas en grön bock när modulen har slutförts. När alla moduler visas med en bockmarkering är experimentet klart.
Nu bör experimentet se ut ungefär så här:
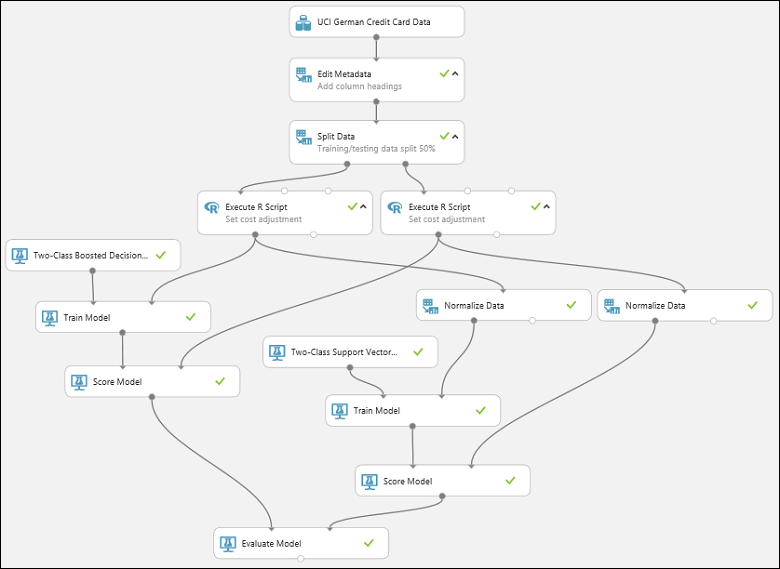
Kontrollera resultaten genom att klicka på utdataporten för modulen Utvärdera modell och välj Visualisera.
Modulen Utvärdera modell genererar ett par kurvor och mått som gör det möjligt att jämföra resultaten av de två poängsatta modellerna. Du kan visa resultaten som ROC-kurvor (egenskaper för mottagaroperator), kurvor av typen Precision/Återkalla eller Lyft. Ytterligare data som visas innehåller en felmatris, kumulativa värden för området under kurvan (AUC) och andra mått. Du kan ändra tröskelvärdet genom att flytta skjutreglaget åt vänster eller höger och se hur det påverkar uppsättningen mått.
Till höger om diagrammet klickar du på Scored dataset (Poängsatt datauppsättning) eller Scored dataset to compare (Poängsatt datauppsättning att jämföra) för att markera den associerade kurvan och för att visa de associerade måtten nedan. I förklaringen för kurvorna motsvarar ”Scored dataset” (Poängsatt datauppsättning) den vänstra indataporten för modulen Utvärdera modell – i vårt fall är detta modellen för det förbättrade beslutsträdet. ”Scored dataset to compare” (Poängsatt datauppsättning att jämföra) motsvarar den högra indataporten – SVM-modellen i vårt fall. När du klickar på någon av dessa etiketter markeras kurvan för den modellen och motsvarande mått visas, som du ser i följande bild.
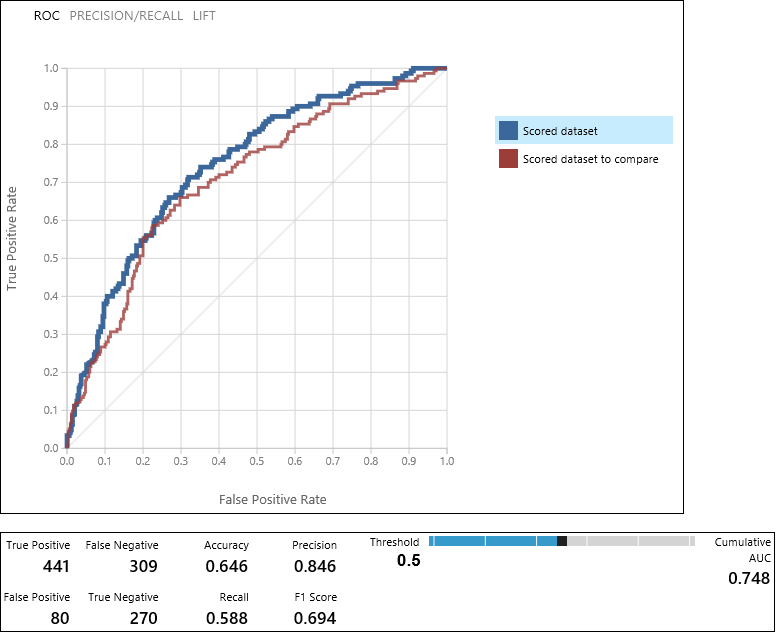
Genom att undersöka dessa värden kan du avgöra vilken modell som bäst kan ge dig de resultat som du letar efter. Du kan gå tillbaka och iterera ditt experiment genom att ändra parametervärden i de olika modellerna.
Vetenskapen och konsten att tolka resultaten och att finjustera modellens prestanda förklaras inte närmare i den här självstudien. Mer information finns i följande artiklar:
- Utvärdera modellprestanda i Machine Learning Studio (klassisk)
- Välj parametrar för att optimera dina algoritmer i Machine Learning Studio (klassisk)
- Tolka modellresultat i Machine Learning Studio (klassisk)
Tips
Varje gång du kör experimentet sparas en post över iterationen i körningshistoriken. Du kan visa dessa iterationer och återgå till någon av dem genom att klicka på View run history (Visa körningshistorik) nedanför arbetsytan. Du kan också klicka på Prior Run (Tidigare körning) i fönstret Egenskaper för att gå tillbaka till iterationen som direkt föregår den som är öppen.
Du kan göra en kopia av valfri iteration av experimentet genom att klicka på Spara som nedanför arbetsytan. Använd experimentets sammanfattning och beskrivning så att du vet vad du har testat i dina iterationer av experimentet.
Mer information finns i Hantera iterationer av experiment i Machine Learning Studio (klassisk).
Rensa resurser
Om du inte behöver de resurser som du skapade i den här artikeln kan du ta bort dem så att du undviker eventuella kostnader. Det kan du lära dig i artikeln om att exportera och ta bort användardata i produkten.
Nästa steg
I den här självstudien har du slutfört dessa steg:
- Skapa ett experiment
- Träna flera modeller
- Poängsätta och utvärdera modellerna
Nu är du redo att distribuera modeller för dessa data.