Köra R-skriptkomponent
Den här artikeln beskriver hur du använder komponenten Execute R Script (Kör R-skript) för att köra R-kod i din Azure Machine Learning-designerpipeline.
Med R kan du utföra uppgifter som inte stöds av befintliga komponenter, till exempel:
- Skapa anpassade datatransformeringar
- Använda dina egna mått för att utvärdera förutsägelser
- Skapa modeller med algoritmer som inte implementeras som fristående komponenter i designern
Stöd för R-version
Azure Machine Learning-designern använder CRAN-distributionen (Comprehensive R Archive Network) av R. Den version som används för närvarande är CRAN 3.5.1.
R-paket som stöds
R-miljön är förinstallerad med fler än 100 paket. En fullständig lista finns i avsnittet Förinstallerade R-paket.
Du kan också lägga till följande kod i valfri Execute R Script-komponent för att se de installerade paketen.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Anteckning
Om din pipeline innehåller flera Execute R Script-komponenter som behöver paket som inte finns i den förinstallerade listan installerar du paketen i varje komponent.
Installera R-paket
Om du vill installera ytterligare R-paket använder du install.packages() metoden . Paket installeras för varje Execute R Script-komponent. De delas inte mellan andra Execute R Script-komponenter.
Anteckning
Vi rekommenderar INTE att du installerar R-paketet från skriptpaketet. Vi rekommenderar att du installerar paket direkt i skriptredigeraren.
Ange CRAN-lagringsplatsen när du installerar paket, till exempel install.packages("zoo",repos = "https://cloud.r-project.org").
Varning
Excute R Script-komponenten stöder inte installation av paket som kräver intern kompilering, till exempel qdap paket som kräver JAVA och drc paket som kräver C++. Det beror på att den här komponenten körs i en förinstallerad miljö med icke-administratörsbehörighet.
Installera inte paket som är förbyggda på/för Windows, eftersom designerkomponenterna körs på Ubuntu. Om du vill kontrollera om ett paket är förbyggt i Windows kan du gå till CRAN och söka i paketet, ladda ned en binär fil enligt operativsystemet och markera Skapad: del i DESCRIPTION-filen . Följande är ett exempel: 
Det här exemplet visar hur du installerar Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Anteckning
Innan du installerar ett paket kontrollerar du om det redan finns så att du inte upprepar en installation. Upprepade installationer kan orsaka att webbtjänstbegäranden överskrider tidsgränsen.
Åtkomst till registrerad datauppsättning
Du kan referera till följande exempelkod för åtkomst till de registrerade datauppsättningarna på din arbetsyta:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Så här konfigurerar du Kör R-skript
Komponenten Execute R Script innehåller exempelkod som utgångspunkt.
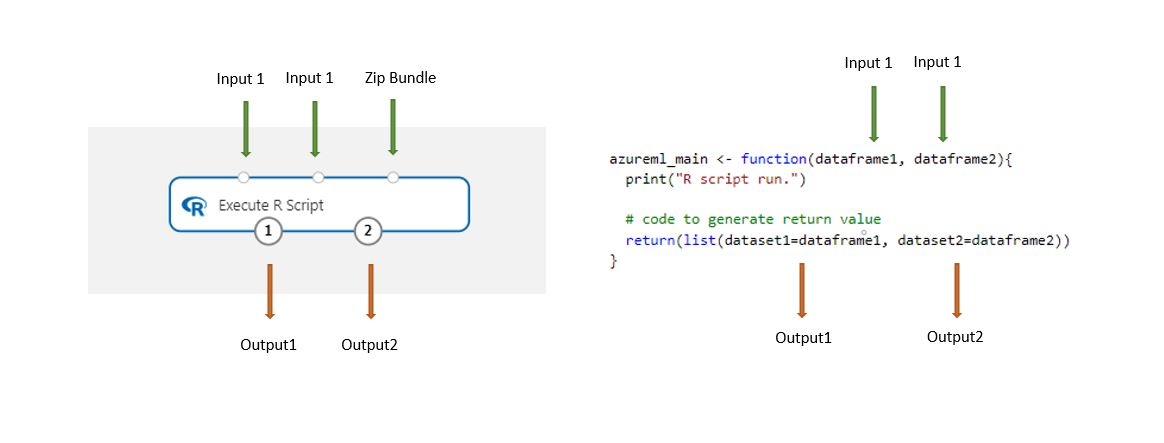
Datauppsättningar som lagras i designern konverteras automatiskt till en R-dataram när de läses in med den här komponenten.
Lägg till komponenten Execute R Script (Kör R-skript) i pipelinen.
Anslut alla indata som skriptet behöver. Indata är valfria och kan innehålla data och ytterligare R-kod.
Dataset1: Referera till de första indata som
dataframe1. Indatauppsättningen måste vara formaterad som en CSV-, TSV- eller ARFF-fil. Eller så kan du ansluta en Azure Machine Learning-datauppsättning.Dataset2: Referera till den andra indatan som
dataframe2. Den här datauppsättningen måste också formateras som en CSV-, TSV- eller ARFF-fil eller som en Azure Machine Learning-datauppsättning.Skriptpaket: Den tredje indatan accepterar .zip filer. En zippad fil kan innehålla flera filer och flera filtyper.
I textrutan R-skript skriver eller klistrar du in ett giltigt R-skript.
Anteckning
Var försiktig när du skriver skriptet. Kontrollera att det inte finns några syntaxfel, till exempel att använda odeklarerade variabler eller oimporterade komponenter eller funktioner. Var extra uppmärksam på den förinstallerade paketlistan i slutet av den här artikeln. Om du vill använda paket som inte finns med i listan installerar du dem i skriptet. Ett exempel är
install.packages("zoo",repos = "https://cloud.r-project.org").För att hjälpa dig att komma igång fylls textrutan R-skript i med exempelkod som du kan redigera eller ersätta.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Startpunktsfunktionen måste ha indataargumenten
Param<dataframe1>ochParam<dataframe2>, även om dessa argument inte används i funktionen.Anteckning
De data som skickas till komponenten Execute R Script refereras till som
dataframe1ochdataframe2, som skiljer sig från Azure Machine Learning-designern (designerreferensen somdataset1,dataset2). Kontrollera att indata refereras korrekt i skriptet.Anteckning
Befintlig R-kod kan behöva mindre ändringar för att köras i en designerpipeline. Indata som du anger i CSV-format bör till exempel uttryckligen konverteras till en datauppsättning innan du kan använda dem i koden. Data- och kolumntyper som används i R-språket skiljer sig också på vissa sätt från de data- och kolumntyper som används i designern.
Om skriptet är större än 16 KB använder du skriptpaketporten för att undvika fel som att CommandLine överskrider gränsen på 16597 tecken.
- Paketering av skriptet och andra anpassade resurser till en zip-fil.
- Ladda upp zip-filen som en fildatauppsättning till studion.
- Dra datamängdskomponenten från listan Datauppsättningar i det vänstra komponentfönstret på designerredigeringssidan.
- Anslut datamängdskomponenten till skriptpaketportenför komponenten Execute R Script ( Kör R-skript ).
Följande är exempelkoden för att använda skriptet i skriptpaketet:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }För Slumpmässigt startvärde anger du ett värde som ska användas i R-miljön som slumpmässigt startvärde. Den här parametern motsvarar anrop
set.seed(value)i R-kod.Skicka pipelinen.
Resultat
Execute R Script-komponenter kan returnera flera utdata, men de måste anges som R-dataramar. Designern konverterar automatiskt dataramar till datauppsättningar för kompatibilitet med andra komponenter.
Standardmeddelanden och fel från R returneras till komponentens logg.
Om du behöver skriva ut resultat i R-skriptet hittar du de utskrivna resultaten i 70_driver_log under fliken Utdata +loggar i den högra panelen i komponenten.
Exempelskript
Det finns många sätt att utöka din pipeline med hjälp av anpassade R-skript. Det här avsnittet innehåller exempelkod för vanliga uppgifter.
Lägga till ett R-skript som indata
Komponenten Execute R Script stöder godtyckliga R-skriptfiler som indata. Om du vill använda dem måste du ladda upp dem till din arbetsyta som en del av .zip filen.
Om du vill ladda upp en .zip fil som innehåller R-kod till din arbetsyta går du till tillgångssidan datauppsättningar . Välj Skapa datauppsättning och välj sedan Från lokal fil och alternativet Fildatauppsättningstyp.
Kontrollera att den komprimerade filen visas i Mina datauppsättningar under kategorin Datauppsättningar i det vänstra komponentträdet.
Anslut datauppsättningen till indataporten för skriptpaketet .
Alla filer i den .zip filen är tillgängliga under pipelinekörningen.
Om skriptpaketfilen innehåller en katalogstruktur bevaras strukturen. Men du måste ändra koden för att förbereda katalogen ./Script Bundle till sökvägen.
Bearbeta data
Följande exempel visar hur du skalar och normaliserar indata:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Läsa en .zip fil som indata
Det här exemplet visar hur du använder en datauppsättning i en .zip fil som indata till komponenten Execute R Script (Kör R-skript).
- Skapa datafilen i CSV-format och ge den namnet mydatafile.csv.
- Skapa en .zip fil och lägg till CSV-filen i arkivet.
- Ladda upp den komprimerade filen till Din Azure Machine Learning-arbetsyta.
- Anslut den resulterande datauppsättningen till ScriptBundle-indata för komponenten Execute R Script .
- Använd följande kod för att läsa CSV-data från den komprimerade filen.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replikera rader
Det här exemplet visar hur du replikerar positiva poster i en datauppsättning för att balansera exemplet:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Skicka R-objekt mellan Komponenter för körning av R-skript
Du kan skicka R-objekt mellan instanser av komponenten Execute R Script med hjälp av den interna serialiseringsmekanismen. Det här exemplet förutsätter att du vill flytta R-objektet med namnet A mellan två Execute R Script-komponenter.
Lägg till den första Execute R Script-komponenten i pipelinen. Ange sedan följande kod i textrutan R-skript för att skapa ett serialiserat objekt
Asom en kolumn i komponentens utdatatabell:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Den explicita konverteringen till heltalstypen görs eftersom serialiseringsfunktionen matar ut data i R-format
Raw, vilket designern inte stöder.Lägg till en andra instans av komponenten Execute R Script (Kör R-skript ) och anslut den till utdataporten för den tidigare komponenten.
Skriv följande kod i textrutan R-skript för att extrahera objekt
Afrån indatatabellen.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Förinstallerade R-paket
Följande förinstallerade R-paket är för närvarande tillgängliga:
| Paket | Version |
|---|---|
| Askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| cirkumflex | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| klass | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| datauppsättningar | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| Generika | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| grafik | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matris | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| Ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.