Partitions- och exempelkomponent
I den här artikeln beskrivs en komponent i Azure Mašinsko učenje designer.
Använd komponenten Partition och Exempel för att utföra sampling på en datauppsättning eller för att skapa partitioner från datauppsättningen.
Sampling är ett viktigt verktyg inom maskininlärning eftersom du kan minska storleken på en datamängd samtidigt som du behåller samma förhållande mellan värden. Den här komponenten stöder flera relaterade uppgifter som är viktiga inom maskininlärning:
Dela upp dina data i flera underavsnitt av samma storlek.
Du kan använda partitionerna för korsvalidering eller för att tilldela ärenden till slumpmässiga grupper.
Separera data i grupper och sedan arbeta med data från en specifik grupp.
När du slumpmässigt tilldelar ärenden till olika grupper kan du behöva ändra de funktioner som bara är associerade med en grupp.
Provtagning.
Du kan extrahera en procentandel av data, tillämpa slumpmässig sampling eller välja en kolumn som ska användas för att balansera datamängden och utföra stratifierad sampling på dess värden.
Skapa en mindre datauppsättning för testning.
Om du har mycket data kanske du bara vill använda de första n raderna när du konfigurerar pipelinen och sedan växla till att använda den fullständiga datamängden när du skapar din modell. Du kan också använda sampling för att skapa en mindre datauppsättning för användning under utveckling.
Konfigurera komponenten
Den här komponenten stöder följande metoder för att dela upp dina data i partitioner eller för sampling. Välj metoden först och ange sedan ytterligare alternativ som metoden kräver.
- Head
- Sampling
- Tilldela till vikningar
- Välj vik
Hämta ÖVERSTA N rader från en datauppsättning
Använd det här läget om du bara vill hämta de första n raderna. Det här alternativet är användbart om du vill testa en pipeline på ett litet antal rader och du inte behöver att data balanseras eller samplas på något sätt.
Lägg till komponenten Partition och Sample i pipelinen i gränssnittet och anslut datauppsättningen.
Partitions- eller exempelläge: Ställ in det här alternativet på Huvud.
Antal rader att välja: Ange antalet rader som ska returneras.
Antalet rader måste vara ett heltal som inte är negativt. Om antalet markerade rader är större än antalet rader i datamängden returneras hela datamängden.
Skicka pipelinen.
Komponenten matar ut en enskild datamängd som endast innehåller det angivna antalet rader. Raderna läss alltid överst i datamängden.
Skapa ett exempel på data
Det här alternativet stöder enkel slumpmässig sampling eller stratifierad slumpmässig sampling. Det är användbart om du vill skapa en mindre representativ exempeldatauppsättning för testning.
Lägg till komponenten Partition och Sample i pipelinen och anslut datauppsättningen.
Partitions- eller exempelläge: Ställ in det här alternativet på Sampling.
Samplingshastighet: Ange ett värde mellan 0 och 1. Det här värdet anger procentandelen rader från källdatauppsättningen som ska ingå i utdatauppsättningen.
Om du till exempel bara vill ha hälften av den ursprungliga datamängden anger du
0.5att samplingsfrekvensen ska vara 50 procent.Raderna i indatauppsättningen blandas och placeras selektivt i utdatauppsättningen enligt det angivna förhållandet.
Slumpmässigt frö för sampling: Om du vill kan du ange ett heltal som ska användas som startvärde.
Det här alternativet är viktigt om du vill att raderna ska delas upp på samma sätt varje gång. Standardvärdet är 0, vilket innebär att ett startfrö genereras baserat på systemklockan. Det här värdet kan leda till något olika resultat varje gång du kör pipelinen.
Stratifierad delning för sampling: Välj det här alternativet om det är viktigt att raderna i datamängden delas jämnt med någon nyckelkolumn före sampling.
För Stratification-nyckelkolumn för sampling väljer du en enda strata-kolumn som ska användas när du delar upp datamängden. Raderna i datauppsättningen delas sedan upp på följande sätt:
Alla indatarader grupperas (stratifieras) efter värdena i den angivna strata-kolumnen.
Rader blandas i varje grupp.
Varje grupp läggs selektivt till i utdatauppsättningen för att uppfylla det angivna förhållandet.
Skicka pipelinen.
Med det här alternativet matar komponenten ut en enda datamängd som innehåller ett representativt urval av data. Den återstående, osamplade delen av datamängden är inte utdata.
Dela upp data i partitioner
Använd det här alternativet när du vill dela upp datamängden i delmängder av data. Det här alternativet är också användbart när du vill skapa ett anpassat antal veck för korsvalidering eller dela upp rader i flera grupper.
Lägg till komponenten Partition och Sample i pipelinen och anslut datauppsättningen.
För Partitions- eller exempelläge väljer du Tilldela till Folds.
Använd ersättning i partitioneringen: Välj det här alternativet om du vill att den samplade raden ska placeras tillbaka i poolen med rader för eventuell återanvändning. Därför kan samma rad tilldelas till flera veck.
Om du inte använder ersättning (standardalternativet) placeras inte den samplade raden tillbaka i poolen med rader för potentiell återanvändning. Därför kan varje rad endast tilldelas till en vikning.
Slumpmässig delning: Välj det här alternativet om du vill att rader ska tilldelas slumpmässigt till vikningar.
Om du inte väljer det här alternativet tilldelas rader till viks via resursallokeringsmetoden.
Slumpmässigt frö: Om du vill kan du ange ett heltal som ska användas som startvärde. Det här alternativet är viktigt om du vill att raderna ska delas upp på samma sätt varje gång. Annars innebär standardvärdet 0 att ett slumpmässigt startfrö används.
Ange partitionermetoden: Ange hur du vill att data ska fördelas till varje partition med hjälp av följande alternativ:
Partition jämnt: Använd det här alternativet för att placera lika många rader i varje partition. Ange antalet utdatapartitioner genom att ange ett heltal i rutan Ange antal vikningar som ska delas jämnt i rutan.
Partition med anpassade proportioner: Använd det här alternativet om du vill ange storleken på varje partition som en kommaavgränsad lista.
Anta till exempel att du vill skapa tre partitioner. Den första partitionen innehåller 50 procent av data. De återstående två partitionerna innehåller vardera 25 procent av data. I rutan Lista över proportioner avgränsade med kommatecken anger du följande tal: .5, .25, .25.
Summan av alla partitionsstorlekar måste innehålla upp till exakt 1.
Om du anger tal som är mindre än 1 skapas en extra partition för att lagra de återstående raderna. Om du till exempel anger värdena .2 och .3 skapas en tredje partition som innehåller de återstående 50 procenten av alla rader.
Om du anger tal som lägger till fler än 1 utlöses ett fel när du kör pipelinen.
Stratifierad delning: Välj det här alternativet om du vill att raderna ska stratifieras vid delning och sedan välja strata-kolumnen.
Skicka pipelinen.
Med det här alternativet matar komponenten ut flera datauppsättningar. Datauppsättningarna partitioneras enligt de regler som du har angett.
Använda data från en fördefinierad partition
Använd det här alternativet när du har delat upp en datauppsättning i flera partitioner och nu vill läsa in varje partition i tur och ordning för ytterligare analys eller bearbetning.
Lägg till komponenten Partition och Sample i pipelinen.
Anslut komponenten till utdata från en tidigare instans av Partition och Exempel. Den instansen måste ha använt alternativet Tilldela till vikningar för att generera ett antal partitioner.
Partitions- eller exempelläge: Välj Välj Vikning.
Ange vilken vikning som ska samplas från: Välj en partition som ska användas genom att ange dess index. Partitionsindex är 1-baserade. Om du till exempel delade upp datamängden i tre delar skulle partitionerna ha indexen 1, 2 och 3.
Om du anger ett ogiltigt indexvärde utlöses ett designtidsfel: "Fel 0018: Datauppsättningen innehåller ogiltiga data."
Förutom att gruppera datamängden efter vikningar kan du dela upp datamängden i två grupper: en målveckning och allt annat. För att göra detta anger du indexet för en enda vik och väljer sedan alternativet Välj komplement för den valda viken för att hämta allt utom data i den angivna viken.
Om du arbetar med flera partitioner måste du lägga till fler instanser av komponenten Partition och Exempel för att hantera varje partition.
Komponenten Partition och Exempel på den andra raden är till exempel inställd på Tilldela till vikningar, och komponenten på den tredje raden är inställd på Välj vikning.
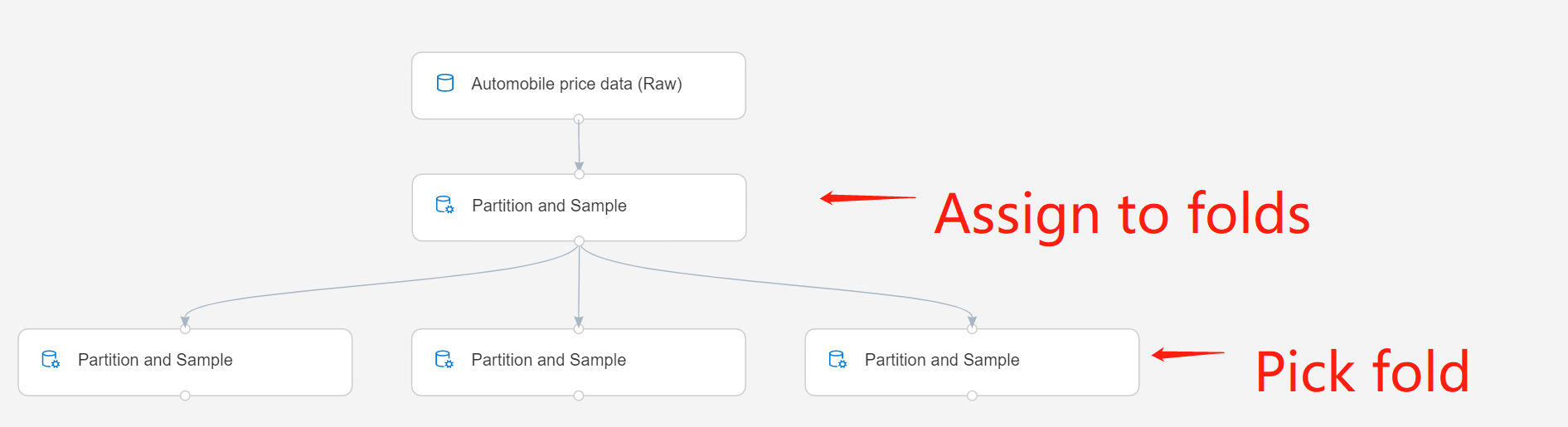
Skicka pipelinen.
Med det här alternativet matar komponenten ut en enda datamängd som endast innehåller de rader som tilldelats den viken.
Kommentar
Du kan inte visa vikbeteckningarna direkt. De finns bara i metadata.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Mašinsko učenje.