Vad är automatisk maskininlärning (AutoML)?
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Automatiserad maskininlärning, även kallad automatiserad ML eller AutoML, är processen att automatisera de tidskrävande, iterativa uppgifterna för utveckling av maskininlärningsmodeller. Det gör det möjligt för dataforskare, analytiker och utvecklare att skapa ML-modeller med hög skala, effektivitet och produktivitet samtidigt som modellkvaliteten bibehålls. Automatiserad ML i Azure Mašinsko učenje baseras på ett genombrott från Microsoft Research-divisionen.
- Installera Azure Mašinsko učenje Python SDK för kodanvända kunder. Kom igång med Självstudie: Träna en objektidentifieringsmodell (förhandsversion) med AutoML och Python.
Hur fungerar AutoML?
Under träningen skapar Azure Mašinsko učenje många pipelines parallellt som provar olika algoritmer och parametrar åt dig. Tjänsten itererar via ML-algoritmer i kombination med funktionsval, där varje iteration genererar en modell med en träningspoäng. Ju bättre poäng för det mått du vill optimera för, desto bättre anses modellen "passa" dina data. Den stoppas när den når det avslutsvillkor som definierats i experimentet.
Med Hjälp av Azure Mašinsko učenje kan du utforma och köra dina automatiserade ML-träningsexperiment med följande steg:
Identifiera ml-problemet som ska lösas: klassificering, prognostisering, regression, visuellt innehåll eller NLP.
Välj om du vill ha en kod-första upplevelse eller en studiowebbupplevelse utan kod: Användare som föredrar en kod-första upplevelse kan använda Azure Mašinsko učenje SDKv2 eller Azure Mašinsko učenje CLIv2. Kom igång med Självstudie: Träna en objektidentifieringsmodell med AutoML och Python. Användare som föredrar en begränsad eller kodfri upplevelse kan använda webbgränssnittet i Azure Mašinsko učenje studio på https://ml.azure.com. Kom igång med Självstudie: Skapa en klassificeringsmodell med automatiserad ML i Azure Mašinsko učenje.
Ange källan för de märkta träningsdata: Du kan ta dina data till Azure Mašinsko učenje på många olika sätt.
Konfigurera de automatiserade maskininlärningsparametrarna som avgör hur många iterationer som finns i olika modeller, inställningar för hyperparameter, avancerad förbearbetning/funktionalisering och vilka mått du bör titta på när du fastställer den bästa modellen.
Skicka träningsjobbet.
Granska resultaten.
Följande diagram illustrerar den här processen.
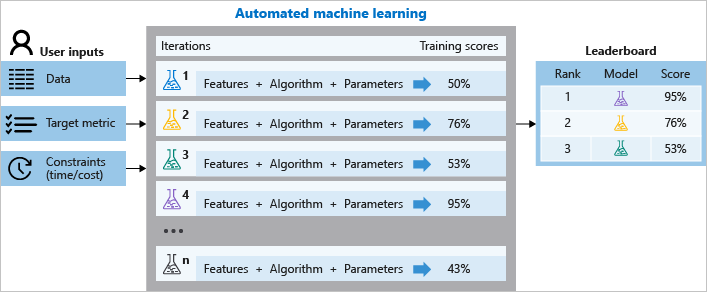
Du kan också granska den loggade jobbinformationen, som innehåller mått som samlats in under jobbet. Träningsjobbet genererar ett Python-serialiserat objekt (.pkl fil) som innehåller modellen och förbearbetning av data.
Även om modellskapandet automatiseras kan du också lära dig hur viktiga eller relevanta funktioner är för de genererade modellerna.
När du ska använda AutoML: klassificering, regression, prognostisering, visuellt innehåll och NLP
Använd automatiserad ML när du vill att Azure Mašinsko učenje ska träna och finjustera en modell åt dig med hjälp av det målmått som du anger. Automatiserad ML demokratiserar utvecklingsprocessen för maskininlärningsmodellen och ger användarna möjlighet att, oavsett deras expertis inom datavetenskap, identifiera en maskininlärningspipeline från slutpunkt till slutpunkt för eventuella problem.
ML-proffs och utvecklare i olika branscher kan använda automatiserad ML för att:
- Implementera ML-lösningar utan omfattande programmeringskunskaper
- Spara tid och resurser
- Tillämpa metodtips för datavetenskap
- Tillhandahålla smidig problemlösning
Klassificering
Klassificering är en typ av övervakad inlärning där modeller lär sig att använda träningsdata och tillämpa dessa lärdomar på nya data. I Azure Machine Learning finns särskilda funktioner för dessa uppgifter, till exempel textfunktioner för djupt neuralt nätverk. Mer information om funktionaliseringsalternativ finns i Funktionalisering av data. Du hittar också listan över algoritmer som stöds av AutoML på algoritmer som stöds.
Huvudmålet med klassificeringsmodeller är att förutsäga vilka kategorier nya data hamnar i baserat på lärdomar från dess träningsdata. Klassificering används till exempel för identifiering av bedrägerier, handskriftsigenkänning och objektidentifiering.
Se ett exempel på klassificering och automatiserad maskininlärning i den här Python-anteckningsboken: Bank Marketing.
Regression
Precis som med klassificering är regressionsaktiviteter också en vanlig övervakad inlärningsuppgift. Azure Mašinsko učenje erbjuder funktionalisering som är specifik för regressionsproblem. Läs mer om funktionaliseringsalternativ. Du hittar också listan över algoritmer som stöds av AutoML på algoritmer som stöds.
Regressionsmodeller skiljer sig från klassificering där förutsagda utdatavärden är kategoriska och förutsäger numeriska utdatavärden baserat på oberoende prediktorer. I regression är målet att hjälpa till att upprätta en relation mellan dessa oberoende prediktorvariabler genom att uppskatta hur en variabel påverkar de andra. Modellen kan till exempel förutsäga bilpriser baserat på funktioner som gasmil och säkerhetsklassificering.
Se ett exempel på regression och automatiserad maskininlärning för förutsägelser i dessa Python-notebook-filer: Maskinvaruprestanda.
Tidsserieprognoser
Att skapa prognoser är ett viktigt område för alla företag, oavsett om det gäller intäkter, lager, försäljning eller kundefterfrågan. Du kan använda automatiserad ML för att kombinera tekniker och metoder och få en rekommenderad tidsserieprognos av hög kvalitet. Du hittar listan över algoritmer som stöds av AutoML på algoritmer som stöds.
Ett automatiserat tidsserieexperiment behandlas som ett problem med multivariatregression. Tidigare tidsserievärden "pivoteras" för att bli fler dimensioner för regressorn tillsammans med andra prediktorer. Den här metoden, till skillnad från klassiska tidsseriemetoder, har en fördel med att naturligt införliva flera kontextuella variabler och deras relation till varandra under träningen. Automatiserad ML lär sig en enda, men ofta internt förgrenad, modell för alla objekt i datauppsättningen och förutsägelsehorisonter. Mer data är därför tillgängliga för att uppskatta modellparametrar och det blir möjligt att generalisera till osedda serier.
Avancerad prognoskonfiguration omfattar:
- Funktionalisering och identifiering av helgdagar
- Tidsserier och DNN-elever (Auto-ARIMA, Prophet, ForecastTCN)
- Många modeller stöder gruppering
- Korsvalidering av rullande ursprung
- Konfigurerbara förskjutningar
- Aggregeringsfunktioner för rullande fönster
Se ett exempel på prognostisering och automatiserad maskininlärning i den här Python-anteckningsboken: Energibehov.
Visuellt innehåll
Med stöd för uppgifter för visuellt innehåll kan du enkelt generera modeller som tränats på bilddata för scenarier som bildklassificering och objektidentifiering.
Med den här funktionen kan du:
- Integrera sömlöst med azure-Mašinsko učenje dataetiketter.
- Använd etiketterade data för att generera bildmodeller.
- Optimera modellprestanda genom att ange modellalgoritmen och justera hyperparametrar.
- Ladda ned eller distribuera den resulterande modellen som en webbtjänst i Azure Mašinsko učenje.
- Operationalisera i stor skala och utnyttja funktionerna i Azure Mašinsko učenje MLOps och ML Pipelines.
Redigering av AutoML-modeller för visionsuppgifter stöds via Azure Mašinsko učenje Python SDK. Resulterande experimenteringsjobb, modeller och utdata kan nås från Användargränssnittet för Azure Mašinsko učenje Studio.
Lär dig hur du konfigurerar AutoML-träning för modeller för visuellt innehåll.
 Bild från: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Bild från: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
AutoML för bilder har stöd för följande uppgifter med datorseende:
| Uppgift | beskrivning |
|---|---|
| Bildklassificering i flera klasser | Uppgifter där en bild endast klassificeras med en enda etikett från en uppsättning klasser – till exempel klassificeras varje bild som antingen en bild av en "katt" eller en "hund" eller en "anka". |
| Bildklassificering med flera etiketter | Uppgifter där en bild kan ha en eller flera etiketter från en uppsättning etiketter – till exempel kan en bild märkas med både "katt" och "hund". |
| Objektidentifiering | Uppgifter för att identifiera objekt i en bild och hitta varje objekt med en avgränsningsruta, till exempel leta upp alla hundar och katter i en bild och rita en avgränsningsruta runt var och en. |
| Instanssegmentering | Uppgifter för att identifiera objekt i en bild på pixelnivå och rita en polygon runt respektive objekt i bilden. |
Bearbetning av naturligt språk: NLP
Med stöd för nlp-uppgifter (natural language processing) i automatiserad ML kan du enkelt generera modeller som tränats på textdata för textklassificering och namngivna scenarier för entitetsigenkänning. Redigering av automatiserade ML-tränade NLP-modeller stöds via Azure Mašinsko učenje Python SDK. Resulterande experimenteringsjobb, modeller och utdata kan nås från Användargränssnittet för Azure Mašinsko učenje Studio.
NLP-funktionen stöder:
- NlP-träning från slutpunkt till slutpunkt med de senaste förtränade BERT-modellerna
- Sömlös integrering med Azure Mašinsko učenje-dataetiketter
- Använda etiketterade data för att generera NLP-modeller
- Flerspråkigt stöd med 104 språk
- Distribuerad träning med Horovod
Lär dig hur du konfigurerar AutoML-träning för NLP-modeller.
Tränings-, validerings- och testdata
Med automatiserad ML tillhandahåller du träningsdata för att träna ML-modeller och du kan ange vilken typ av modellverifiering som ska utföras. Automatiserad ML utför modellverifiering som en del av träningen. Automatiserad ML använder valideringsdata för att finjustera modellhyperparametrar baserat på den tillämpade algoritmen för att hitta den kombination som passar bäst för träningsdata. Samma valideringsdata används dock för varje iteration av justering, vilket introducerar modellutvärderingsfördomar eftersom modellen fortsätter att förbättras och anpassas till valideringsdata.
För att bekräfta att sådan bias inte tillämpas på den slutliga rekommenderade modellen stöder automatiserad ML användning av testdata för att utvärdera den slutliga modell som automatiserad ML rekommenderar i slutet av experimentet. När du anger testdata som en del av autoML-experimentkonfigurationen testas den här rekommenderade modellen som standard i slutet av experimentet (förhandsversion).
Viktigt!
Att testa dina modeller med en testdatauppsättning för att utvärdera genererade modeller är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Lär dig hur du konfigurerar AutoML-experiment för att använda testdata (förhandsversion) med SDK eller med Azure Mašinsko učenje studio.
Funktionsframställning
Funktionsutveckling är processen att använda domänkunskaper om data för att skapa funktioner som hjälper ML-algoritmer att lära sig bättre. I Azure Mašinsko učenje används skalnings- och normaliseringstekniker för att underlätta funktionsframställning. Tillsammans kallas dessa tekniker och funktionstekniker för funktionalisering.
För automatiserade maskininlärningsexperiment tillämpas funktionalisering automatiskt, men kan också anpassas baserat på dina data. Läs mer om vad funktionalisering ingår (SDK v1) och hur AutoML hjälper till att förhindra överanpassning och obalanserade data i dina modeller.
Kommentar
Automatiserade maskininlärningssteg (till exempel funktionsnormalisering, hantering av saknade data och konvertering av text till numerisk) blir en del av den underliggande modellen. När du använder modellen för förutsägelser tillämpas samma funktionaliseringssteg som tillämpas under träningen på dina indata automatiskt.
Anpassa funktionalisering
Ytterligare tekniker för funktionsutveckling, till exempel kodning och transformeringar, finns också tillgängliga.
Aktivera den här inställningen med:
Azure Mašinsko učenje studio: Aktivera automatisk funktionalisering i avsnittet Visa ytterligare konfiguration med de här stegen.
Python SDK: Ange funktionalisering i autoML-jobbobjektet. Läs mer om att aktivera funktionalisering.
Ensemblemodeller
Automatiserad maskininlärning stöder ensemblemodeller som är aktiverade som standard. Ensembleinlärning förbättrar maskininlärningsresultat och förutsägande prestanda genom att kombinera flera modeller i stället för att använda enkla modeller. Ensemble-iterationerna visas som de sista iterationerna av ditt jobb. Automatiserad maskininlärning använder både röstnings- och staplingsmetoder för att kombinera modeller:
- Röstning: Förutsäger baserat på det viktade genomsnittet av förutsagda klassannolikheter (för klassificeringsuppgifter) eller förutsagda regressionsmål (för regressionsaktiviteter).
- Stapling: Kombinerar heterogena modeller och tränar en metamodell baserat på utdata från de enskilda modellerna. De aktuella standardmetamodellerna är LogisticRegression för klassificeringsuppgifter och ElasticNet för regression/prognostiseringsuppgifter.
Algoritmen för val av Caruana-ensemble med sorterad ensembleinitiering används för att bestämma vilka modeller som ska användas i ensemblen. På hög nivå initierar den här algoritmen ensemblen med upp till fem modeller med bästa individuella poäng och verifierar att dessa modeller ligger inom 5 % tröskelvärde för bästa poäng för att undvika en dålig initial ensemble. För varje ensemble-iteration läggs sedan en ny modell till i den befintliga ensemblen och den resulterande poängen beräknas. Om en ny modell förbättrade den befintliga ensemblepoängen uppdateras ensemblen så att den innehåller den nya modellen.
Se AutoML-paketet för att ändra standardinställningarna för ensemble i automatiserad maskininlärning.
AutoML och ONNX
Med Azure Mašinsko učenje kan du använda automatiserad ML för att skapa en Python-modell och få den konverterad till ONNX-formatet. När modellerna är i ONNX-format kan de köras på olika plattformar och enheter. Läs mer om att accelerera ML-modeller med ONNX.
Se hur du konverterar till ONNX-format i det här Jupyter Notebook-exemplet. Lär dig vilka algoritmer som stöds i ONNX.
ONNX-körningen har också stöd för C#, så du kan använda modellen som skapats automatiskt i dina C#-appar utan att behöva ändra eller någon av de nätverksfördröjningar som REST-slutpunkter introducerar. Läs mer om hur du använder en AutoML ONNX-modell i ett .NET-program med ML.NET och slutsatsdragning av ONNX-modeller med ONNX-körnings-C#-API:et.
Nästa steg
Det finns flera resurser för att komma igång med AutoML.
Självstudier/instruktioner
Självstudier är introduktionsexempel från slutpunkt till slutpunkt för AutoML-scenarier.
För en kod första upplevelse följer du Självstudie: Träna en objektidentifieringsmodell med AutoML och Python
En låg eller ingen kodupplevelse finns i Självstudie: Träna en klassificeringsmodell utan kod AutoML i Azure Mašinsko učenje studio.
Instruktioner innehåller mer information om vilka funktioner automatiserad ML erbjuder. Ett exempel:
Konfigurera inställningarna för automatiska träningsexperiment
Lär dig hur du tränar modeller för visuellt innehåll med Python.
Lär dig hur du visar den genererade koden från dina automatiserade ML-modeller (SDK v1).
Jupyter Notebook-exempel
Granska detaljerade kodexempel och användningsfall på GitHub-lagringsplatsen med automatiserade maskininlärningsexempel.
Python SDK-referens
Fördjupa dina kunskaper om SDK-designmönster och klassspecifikationer med referensdokumentationen för AutoML-jobbklassen.
Kommentar
Automatiserade maskininlärningsfunktioner är också tillgängliga i andra Microsoft-lösningar, till exempel ML.NET, HDInsight, Power BI och SQL Server.