Djupinlärning med AutoML-prognostisering
Den här artikeln fokuserar på djupinlärningsmetoderna för tidsserieprognoser i AutoML. Instruktioner och exempel för modeller för träningsprognoser i AutoML finns i vår artikel om att konfigurera AutoML för tidsserieprognoser .
Djupinlärning har gjort stor inverkan inom allt från språkmodellering till proteindelegering, bland många andra. Tidsserieprognoser har också dragit nytta av de senaste framstegen inom djupinlärningsteknik. Till exempel har DNN-modeller (deep neural network) en framträdande roll i de bäst presterande modellerna från den fjärde och femte iterationen av den högprofilerade Makridakis-prognostiseringskonkurrensen.
I den här artikeln beskriver vi strukturen och driften av TCNForecaster-modellen i AutoML för att hjälpa dig att tillämpa modellen på ditt scenario på bästa sätt.
Introduktion till TCNForecaster
TCNForecaster är ett temporalt convolutional-nätverk, eller TCN, som har en DNN-arkitektur som är särskilt utformad för tidsseriedata. Modellen använder historiska data för en målkvantitet, tillsammans med relaterade funktioner, för att göra probabilistiska prognoser för målet upp till en angiven prognoshorisont. Följande bild visar huvudkomponenterna i TCNForecaster-arkitekturen:
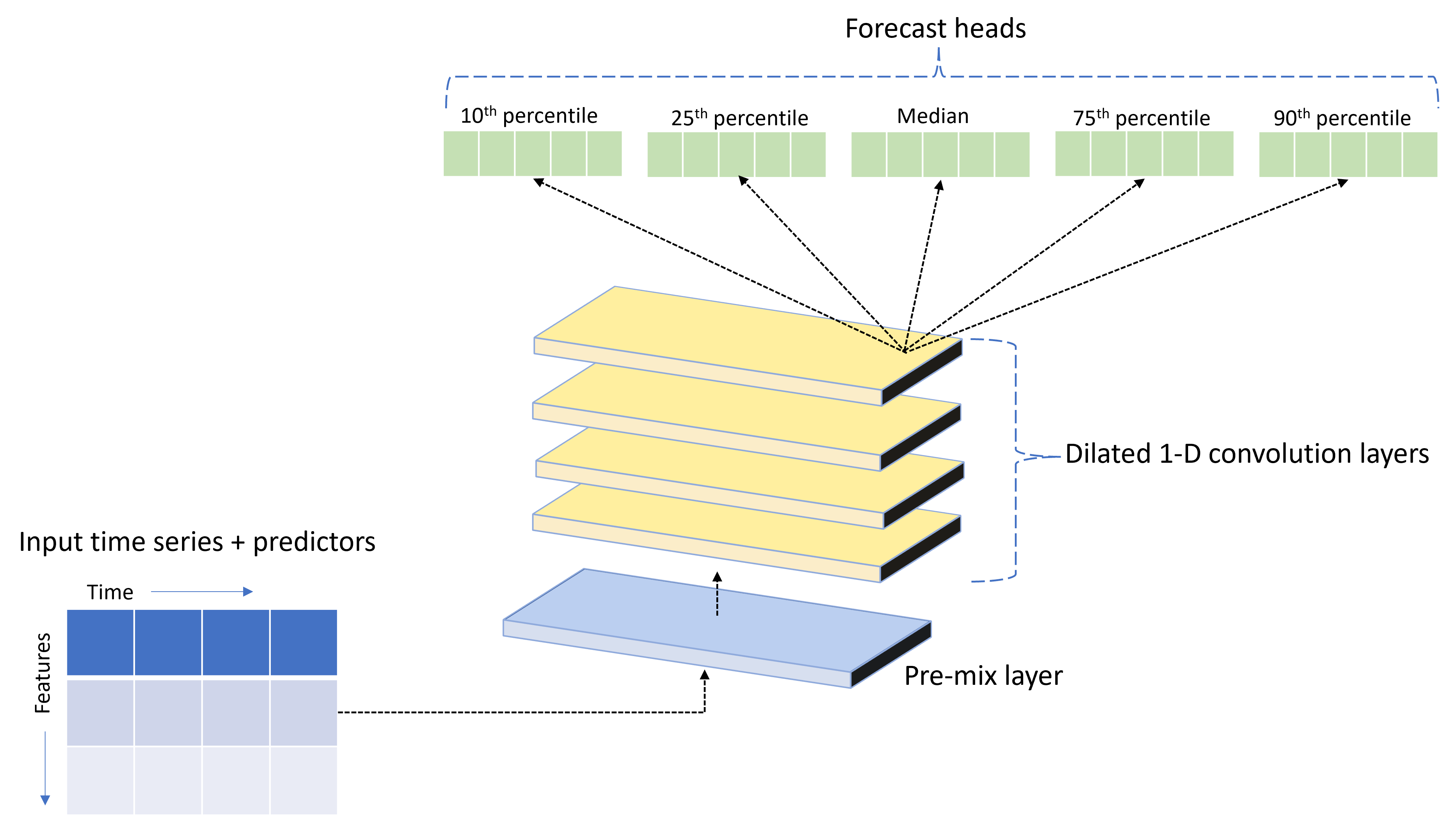
TCNForecaster har följande huvudkomponenter:
- Ett förblandat lager som blandar indatatidsserien och funktionsdata till en matris med signalkanaler som den convolutional stacken ska bearbeta.
- En stack med dilated convolution-skikt som bearbetar kanalmatrisen sekventiellt. varje lager i stacken bearbetar utdata från föregående lager för att skapa en ny kanalmatris. Varje kanal i den här utdatan innehåller en blandning av faltningsfiltrerade signaler från indatakanalerna.
- En samling prognoshuvudenheter som sammanser utdatasignalerna från decentraliseringsskikten och genererar prognoser för målkvantiteten från denna latenta representation. Varje huvudenhet producerar prognoser fram till horisonten för en kvantil av förutsägelsefördelningen.
Dilated causal convolution
Den centrala driften av ett TCN är en dilaterad orsakssamband längs tidsdimensionen för en indatasignal. Intuitivt blandar convolution värden från närliggande tidpunkter i indata. Proportionerna i blandningen är kärnan, eller vikterna, av decentraliseringen medan separationen mellan punkter i blandningen är dilationen. Utdatasignalen genereras från indata genom att kerneln skjuts i tid längs indata och ackumuleras blandningen vid varje position. Ett orsakssamband är ett där kärnan endast blandar indatavärden i det förflutna i förhållande till varje utdatapunkt, vilket hindrar utdata från att "titta" in i framtiden.
Genom att stapla dilaterade faltningar kan TCN modellera korrelationer över långa varaktigheter i indatasignaler med relativt få kernelvikter. Följande bild visar till exempel tre staplade lager med en kernel med två vikter i varje lager och exponentiellt ökande dilationsfaktorer:
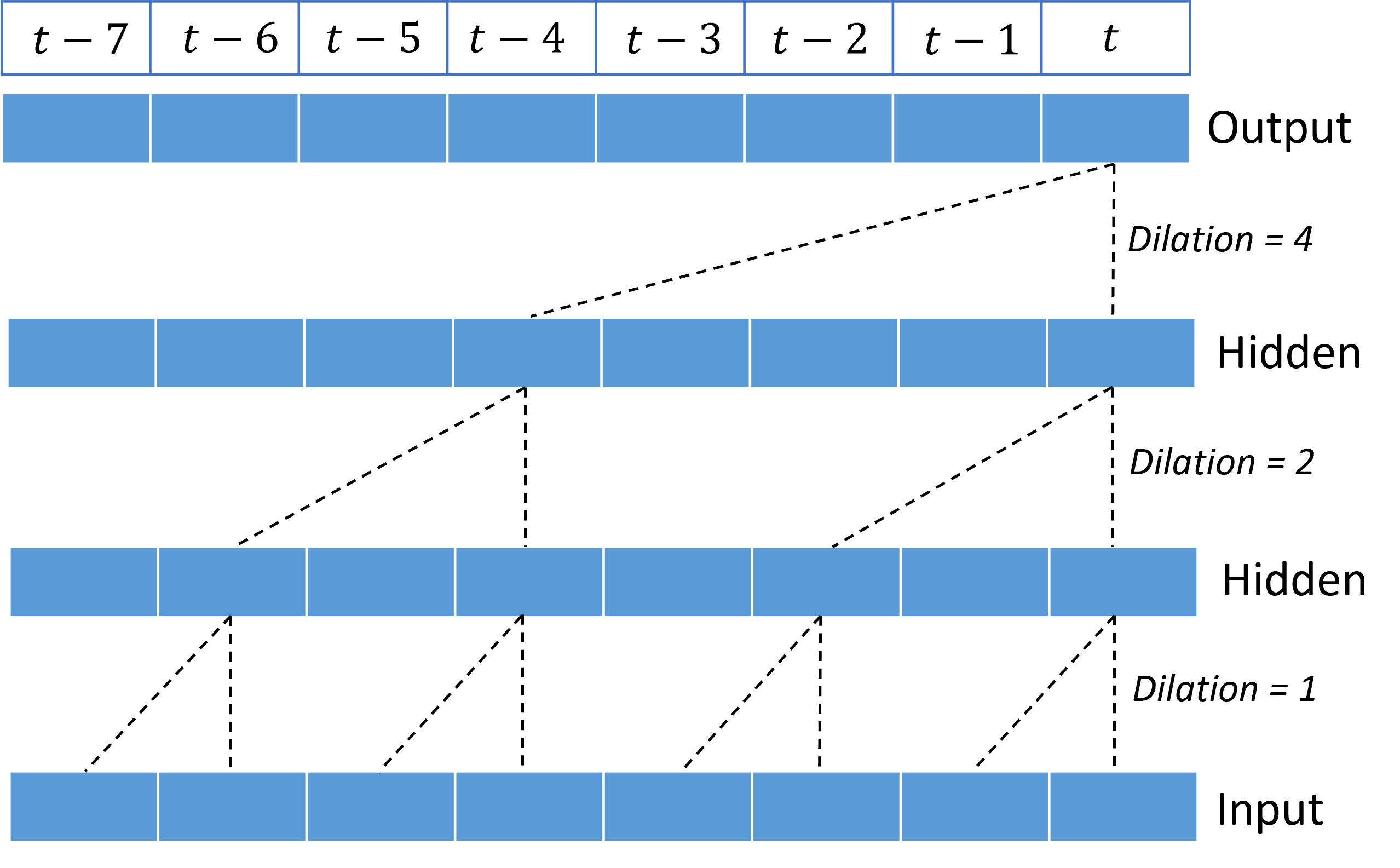
De streckade linjerna visar sökvägar genom nätverket som slutar på utdata i taget $t$. De här sökvägarna täcker de sista åtta punkterna i indata, vilket illustrerar att varje utdatapunkt är en funktion av de åtta senaste punkterna i indata. Längden på historiken, eller "tillbakablick", som ett convolutional-nätverk använder för att göra förutsägelser kallas det mottagliga fältet och bestäms helt av TCN-arkitekturen.
TCNForecaster-arkitektur
Kärnan i TCNForecaster-arkitekturen är stacken med konvolutionala lager mellan förmixen och prognoshuvudena. Stacken är logiskt uppdelad i upprepade enheter som kallas block som i sin tur består av residualceller. En residualcell tillämpar orsakssamband vid en angivna diilation tillsammans med normalisering och icke-linjär aktivering. Viktigt är att varje residualcell lägger till sina utdata till sina indata med hjälp av en så kallad residualanslutning. Dessa anslutningar har visat sig vara till nytta för DNN-utbildning, kanske för att de underlättar ett effektivare informationsflöde genom nätverket. Följande bild visar arkitekturen för de convolutional lagren för ett exempelnätverk med två block och tre residualceller i varje block:
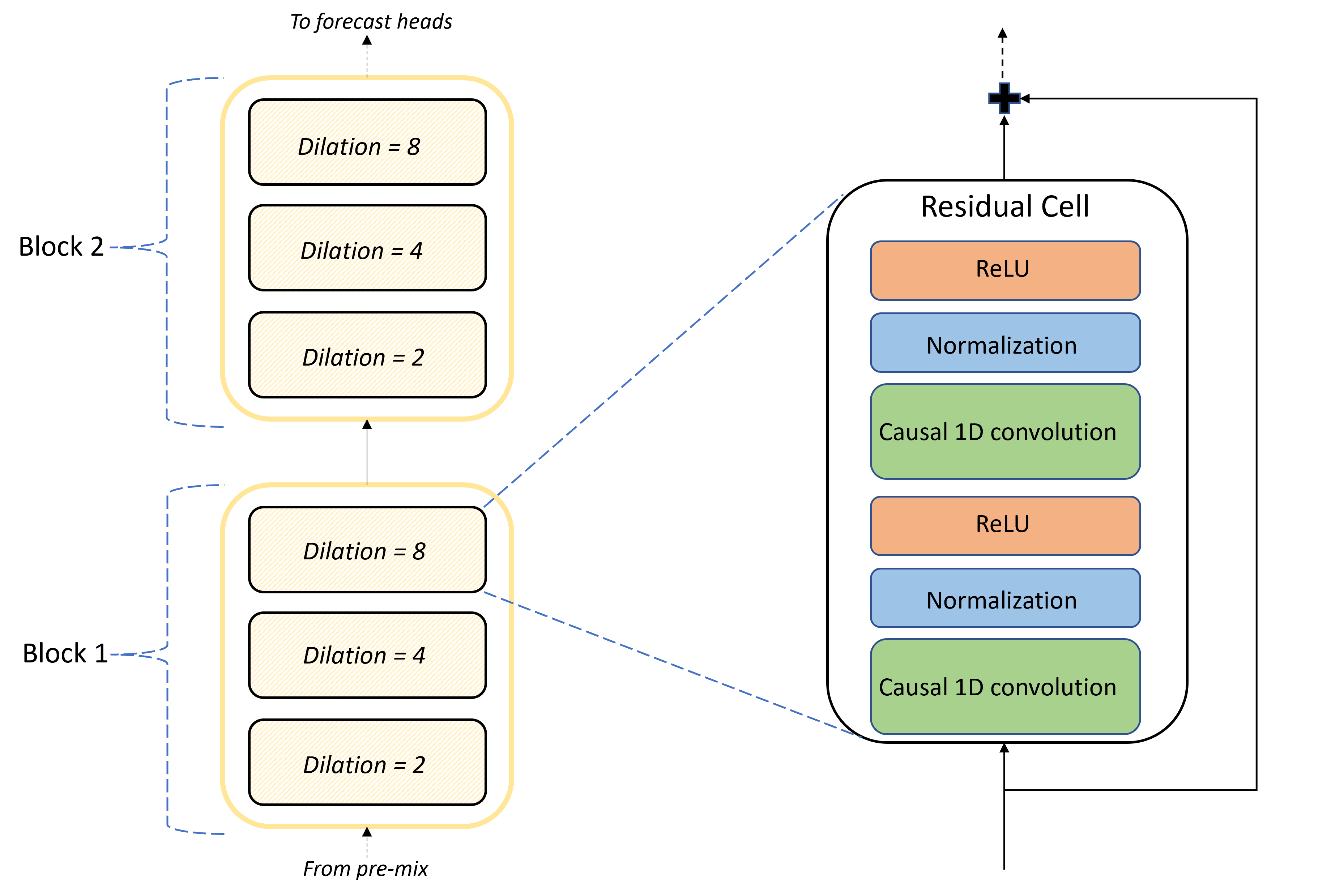
Antalet block och celler, tillsammans med antalet signalkanaler i varje lager, styr nätverkets storlek. Arkitekturparametrarna för TCNForecaster sammanfattas i följande tabell:
| Parameter | Beskrivning |
|---|---|
| $n_{b}$ | Antal block i nätverket. kallas även djup |
| $n_{c}$ | Antal celler i varje block |
| $n_{\text{ch}}$ | Antal kanaler i de dolda lagren |
Det mottagliga fältet beror på djupparametrarna och anges av formeln,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Vi kan ge en mer exakt definition av TCNForecaster-arkitekturen när det gäller formler. Låt $X$ vara en indatamatris där varje rad innehåller funktionsvärden från indata. Vi kan dela $X$ i numeriska och kategoriska funktionsmatriser, $X_{\text{num}}$ och $X_{\text{cat}}$. Sedan ges TCNForecaster av formler,
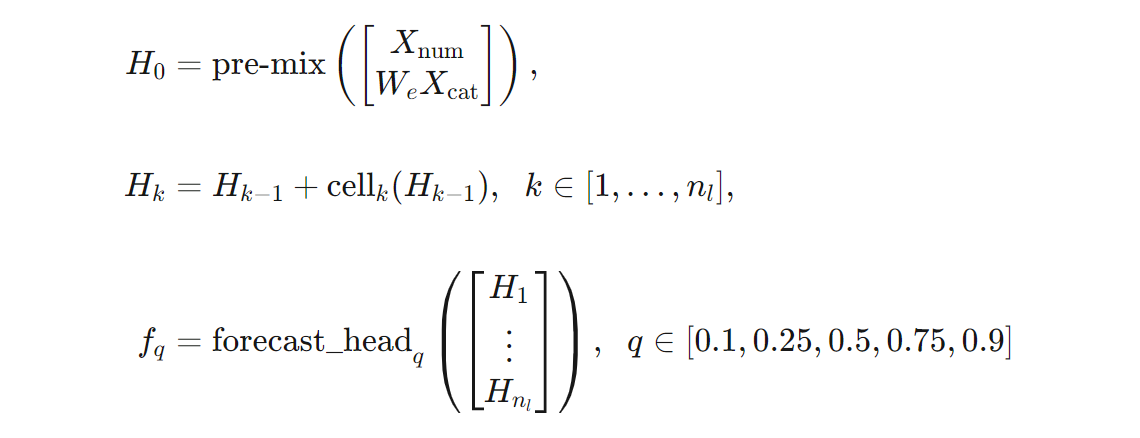
där $W_{e}$ är en inbäddningsmatris för kategoriska funktioner, $n_{l} = n_{b}n_{c}$ är det totala antalet residualceller, anger $H_{k}$ dolda lagerutdata och $f_{q}$ är prognosutdata för angivna quantiles för förutsägelsefördelningen. För att underlätta förståelsen finns dimensionerna för dessa variabler i följande tabell:
| Variabel | Beskrivning | Dimensioner |
|---|---|---|
| $X$ | Indatamatris | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Dolda lagerutdata för $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Prognostisera utdata för kvantil $q$ | $h$ |
I tabellen $n_{\text{input}} = n_{\text{features}} + 1$, antalet prediktor-/funktionsvariabler plus målkvantiteten. Prognoshuvudena genererar alla prognoser upp till maximal horisont, $h$, i ett enda pass, så TCNForecaster är en direkt prognosmakare.
TCNForecaster i AutoML
TCNForecaster är en valfri modell i AutoML. Information om hur du använder den finns i Aktivera djupinlärning.
I det här avsnittet beskriver vi hur AutoML skapar TCNForecaster-modeller med dina data, inklusive förklaringar av förbearbetning av data, träning och modellsökning.
Förbearbetningssteg för data
AutoML kör flera förbearbetningssteg på dina data för att förbereda för modellträning. I följande tabell beskrivs de här stegen i den ordning de utförs:
| Steg | Beskrivning |
|---|---|
| Fyll i saknade data | Impute missing values and observation gaps and optionally pad or drop short time series (Impute missing values and observation gaps and optionally pad or drop short time series) |
| Skapa kalenderfunktioner | Utöka indata med funktioner som härleds från kalendern som veckodag och, om du vill, helgdagar för ett visst land/en viss region. |
| Koda kategoriska data | Etikettkodningssträngar och andra kategoriska typer; Detta inkluderar kolumner med alla tidsserie-ID:t. |
| Måltransformering | Du kan också använda funktionen naturlig logaritm på målet beroende på resultatet av vissa statistiska tester. |
| Normalisering | Z-score normaliserar alla numeriska data. normalisering utförs per funktion och per tidsseriegrupp, enligt definitionen i kolumnerna för tidsserie-ID. |
De här stegen ingår i AutoML:s transformeringspipelines, så de tillämpas automatiskt vid behov vid slutsatsdragning. I vissa fall ingår inverteringsåtgärden i ett steg i slutsatsdragningspipelinen. Om AutoML till exempel tillämpade en $\log$ -transformering på målet under träningen, exponenteras råprognoserna i slutsatsdragningspipelinen.
Utbildning
TCNForecaster följer metodtips för DNN-utbildning som är gemensamma för andra program i bilder och språk. AutoML delar in förbearbetade träningsdata i exempel som blandas och kombineras i batchar. Nätverket bearbetar batcharna sekventiellt med hjälp av bakåtspridning och stochastic gradient descent för att optimera nätverksvikterna med avseende på en förlustfunktion. Träning kan kräva många pass genom fullständiga träningsdata. varje pass kallas en epok.
I följande tabell visas och beskrivs indatainställningar och parametrar för TCNForecaster-träning:
| Träningsindata | Description | Värde |
|---|---|---|
| Valideringsdata | En del av data som hålls borta från träningen för att vägleda nätverksoptimeringen och minimera överanpassningen. | Tillhandahålls av användaren eller skapas automatiskt från träningsdata om det inte tillhandahålls. |
| Primärt mått | Mått som beräknas från medianvärdesprognoser på valideringsdata i slutet av varje träningsepooch. för tidig stoppning och modellval. | Väljs av användaren; normalized root mean squared error or normalized mean absolute error.or normalized root mean squared error or normalized mean absolute error. |
| Träningsepoker | Maximalt antal epoker som ska köras för optimering av nätverksvikt. | 100; automatisk tidig stopplogik kan avsluta träningen vid ett mindre antal epoker. |
| Tidigt stopp tålamod | Antal epoker som ska vänta på primär måttförbättring innan träningen stoppas. | 20 |
| Förlustfunktion | Målfunktionen för nätverksviktsoptimering. | Kvantilförlusten var i genomsnitt över 10:e, 25:e, 50:e, 75:e och 90:e percentilens prognoser. |
| Batchstorlek | Antal exempel i en batch. Varje exempel har dimensioner $n_{\text{input}} \times t_{\text{rf}}$ för indata och $h$ för utdata. | Bestäms automatiskt från det totala antalet exempel i träningsdata; maximalt värde på 1 024. |
| Inbäddningsdimensioner | Dimensioner för inbäddningsutrymmen för kategoriska funktioner. | Ange automatiskt till den fjärde roten av antalet distinkta värden i varje funktion, avrundat uppåt till närmaste heltal. Tröskelvärden tillämpas med ett minimivärde på 3 och ett maxvärde på 100. |
| Nätverksarkitektur* | Parametrar som styr nätverkets storlek och form: djup, antal celler och antal kanaler. | Bestäms av modellsökning. |
| Nätverksvikter | Parametrar som styr signalblandningar, kategoriska inbäddningar, kernelvikter för faltning och mappningar till prognosvärden. | Initierades slumpmässigt och optimerades sedan med avseende på förlustfunktionen. |
| Inlärningstakt* | Styr hur mycket nätverksvikterna kan justeras i varje iteration av gradient descent; dynamiskt reducerad nära konvergens. | Bestäms av modellsökning. |
| Avlämningsförhållande* | Styr graden av regularisering av avhopp som tillämpas på nätverksvikterna. | Bestäms av modellsökning. |
Indata som markerats med en asterisk (*) bestäms av en hyperparametersökning som beskrivs i nästa avsnitt.
Modellsökning
AutoML använder modellsökmetoder för att hitta värden för följande hyperparametrar:
- Nätverksdjup, eller antalet konvolutionalblock,
- Antal celler per block,
- Antal kanaler i varje dolt lager,
- Dropout ratio for network regularization,
- Inlärningstakt.
Optimala värden för dessa parametrar kan variera avsevärt beroende på problemscenariot och träningsdata, så AutoML tränar flera olika modeller inom utrymmet för hyperparametervärden och väljer det bästa enligt det primära måttresultatet för valideringsdata.
Modellsökningen har två faser:
- AutoML utför en sökning över 12 "landmärkesmodeller". Landmärkesmodellerna är statiska och väljs för att på ett rimligt sätt sträcka sig över hyperparameterutrymmet.
- AutoML fortsätter att söka i hyperparameterutrymmet med hjälp av en slumpmässig sökning.
Sökningen avslutas när stoppvillkoren uppfylls. Stoppvillkoren beror på konfigurationen av prognosträningsjobbet, men vissa exempel är tidsgränser, gränser för antalet sökförsök som ska utföras och tidig stopplogik när valideringsmåttet inte förbättras.
Nästa steg
- Lär dig hur du konfigurerar AutoML för att träna en prognosmodell för tidsserier.
- Lär dig mer om prognostiseringsmetodik i AutoML.
- Bläddra bland vanliga frågor och svar om prognostisering i AutoML.