Slutsatsdragning och utvärdering av prognosmodeller
Den här artikeln beskriver begrepp som rör modellinferens och utvärdering i prognostiseringsuppgifter. Anvisningar och exempel för modeller för träningsprognoser i AutoML finns i Konfigurera AutoML för att träna en prognosmodell för tidsserier med SDK och CLI.
När du har använt AutoML för att träna och välja en bästa modell är nästa steg att generera prognoser. Utvärdera sedan om möjligt deras noggrannhet på en testuppsättning som hålls ut från träningsdata. Information om hur du konfigurerar och kör utvärdering av prognosmodeller i automatiserad maskininlärning finns i Orkestrering av utbildning, slutsatsdragning och utvärdering.
Slutsatsdragningsscenarier
Inom maskininlärning är slutsatsdragning processen för att generera modellförutsägelser för nya data som inte används i träning. Det finns flera sätt att generera förutsägelser i prognostisering på grund av datans tidsberoende. Det enklaste scenariot är när inferensperioden omedelbart följer träningsperioden och du genererar förutsägelser ut till prognoshorisonten. Följande diagram illustrerar det här scenariot:
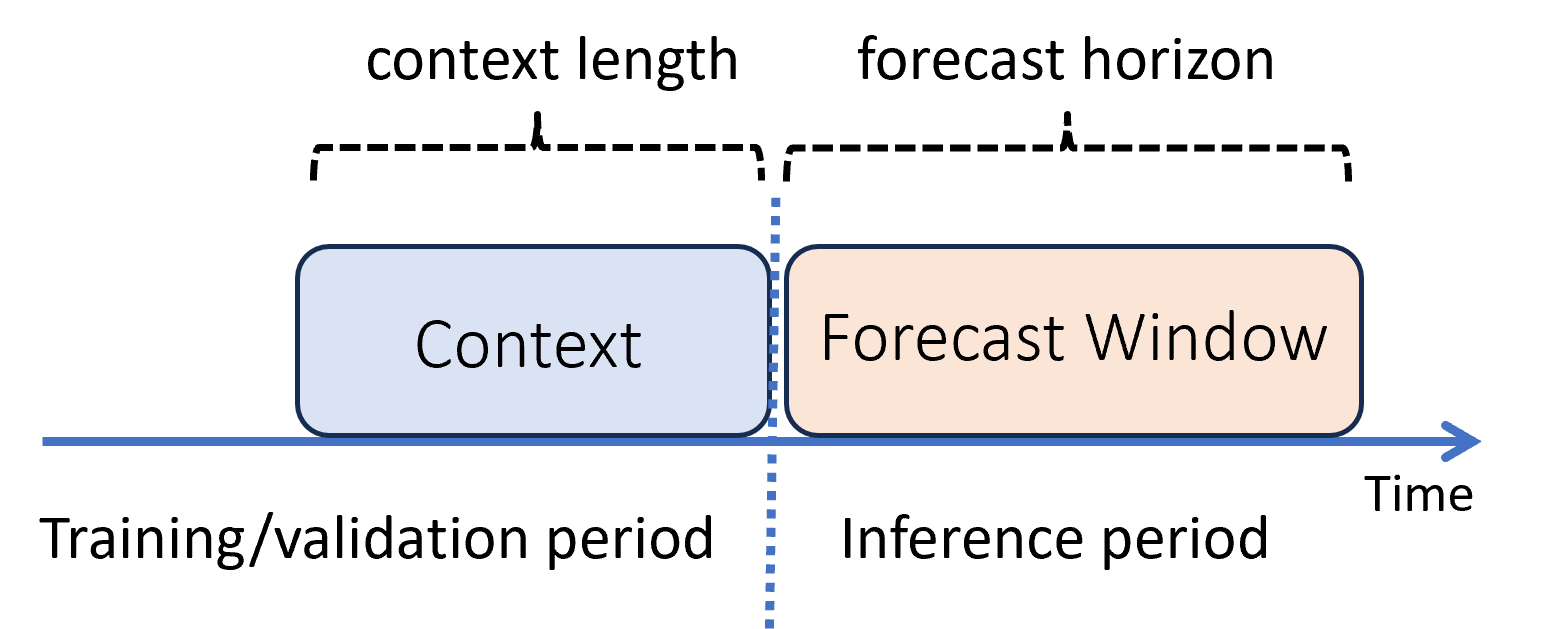
Diagrammet visar två viktiga slutsatsparametrar:
- Kontextlängden är den mängd historik som modellen kräver för att göra en prognos.
- Prognoshorisonten är hur långt framåt prognosmakaren är tränad att förutsäga.
Prognosmodeller använder vanligtvis viss historisk information, kontexten, för att göra förutsägelser framåt i tid fram till prognoshorisonten. När kontexten är en del av träningsdata sparar AutoML det som behövs för att göra prognoser. Du behöver inte uttryckligen ange det.
Det finns två andra slutsatsdragningsscenarier som är mer komplicerade:
- Generera förutsägelser längre in i framtiden än prognoshorisonten
- Få förutsägelser när det finns en lucka mellan tränings- och slutsatsdragningsperioderna
Följande underavsnitt granskar dessa fall.
Förutsäga efter prognoshorisonten: rekursiv prognostisering
När du behöver prognoser efter horisonten tillämpar AutoML modellen rekursivt under inferensperioden. Förutsägelser från modellen matas tillbaka som indata för att generera förutsägelser för efterföljande prognostiseringsfönster. Följande diagram visar ett enkelt exempel:
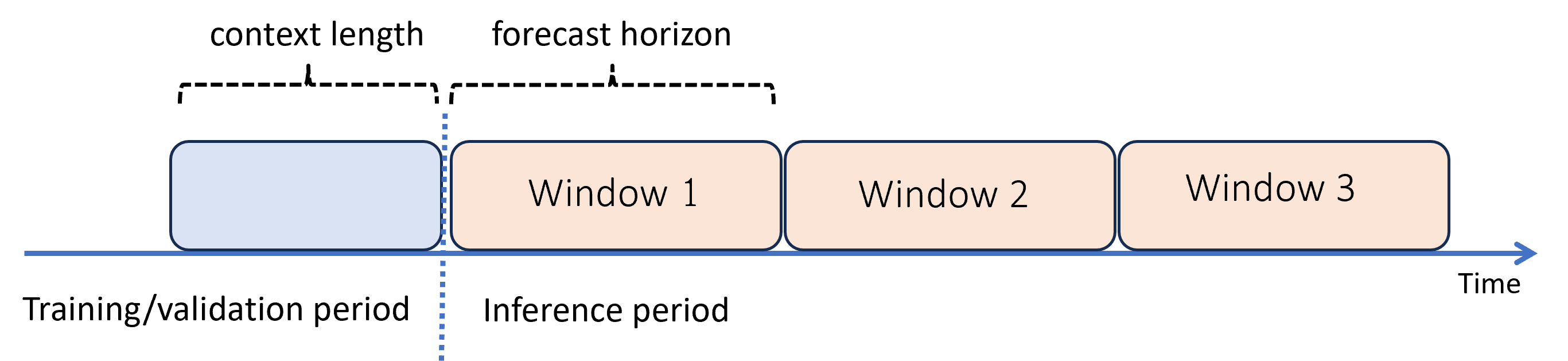
Här genererar maskininlärning prognoser för en period som är tre gånger så lång som horisonten. Den använder förutsägelser från ett fönster som kontext för nästa fönster.
Varning
Rekursiva prognostiseringsföreningar modellerar fel. Förutsägelser blir mindre exakta ju längre de kommer från den ursprungliga prognoshorisonten. Du kan hitta en mer exakt modell genom att träna om med en längre horisont.
Förutsäga med en lucka mellan tränings- och slutsatsdragningsperioder
Anta att när du har tränat en modell vill du använda den för att göra förutsägelser från nya observationer som ännu inte var tillgängliga under träningen. I det här fallet finns det ett tidsgap mellan tränings- och slutsatsdragningsperioderna:
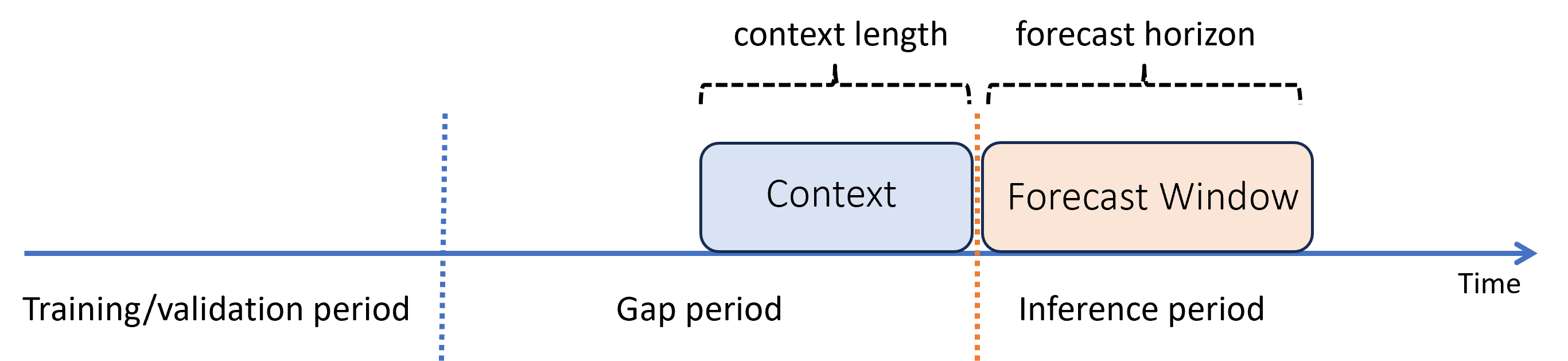
AutoML stöder det här slutsatsdragningsscenariot, men du måste ange kontextdata under gapperioden, som du ser i diagrammet. Förutsägelsedata som skickas till inferenskomponenten behöver värden för funktioner och observerade målvärden i gapet och saknade värden eller NaN värden för målet under inferensperioden. Följande tabell visar ett exempel på det här mönstret:
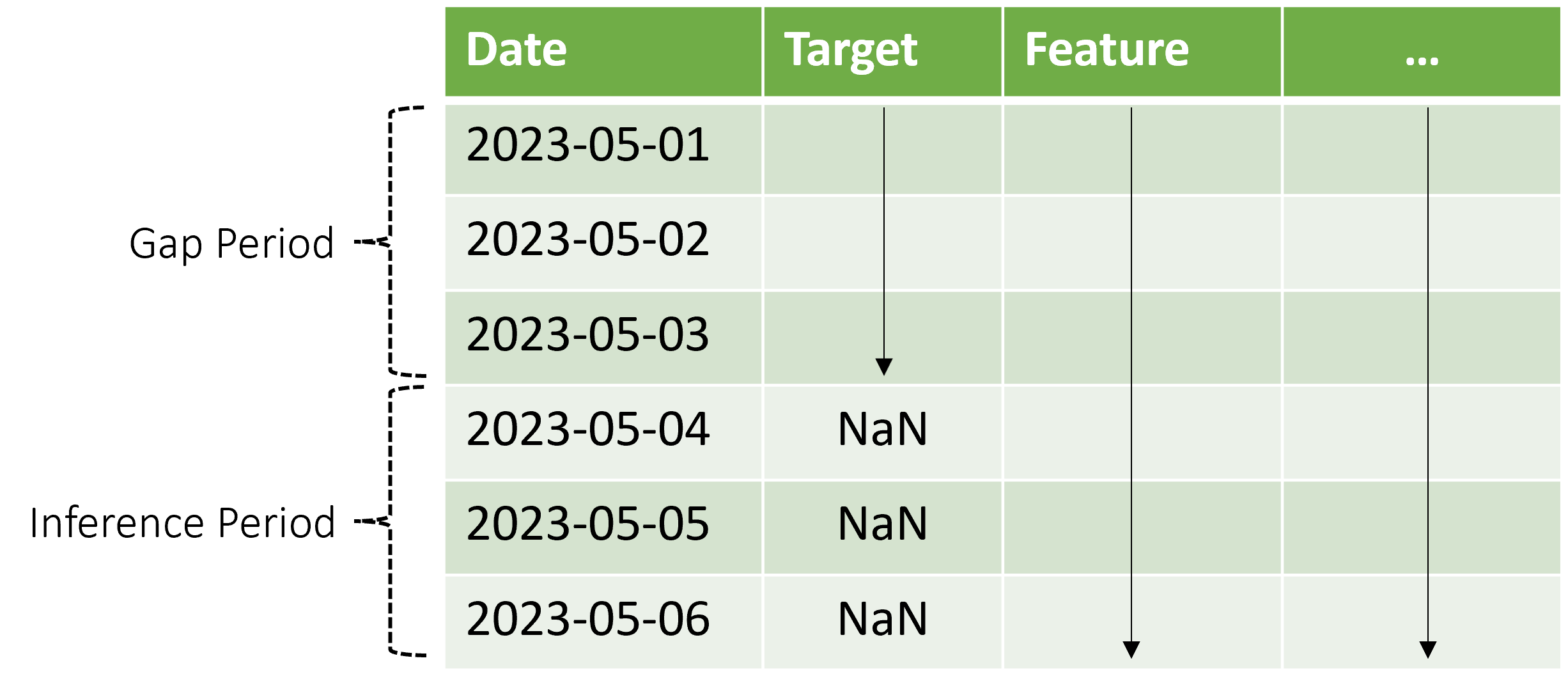
Kända värden för 2023-05-01 målet och funktionerna tillhandahålls via 2023-05-03. Saknade målvärden som börjar vid 2023-05-04 indikerar att inferensperioden börjar vid det datumet.
AutoML använder nya kontextdata för att uppdatera fördröjning och andra återblicksfunktioner, och även för att uppdatera modeller som ARIMA som behåller ett internt tillstånd. Den här åtgärden uppdaterar eller uppdaterar inte modellparametrar.
Modellutvärdering
Utvärdering är processen för att generera förutsägelser på en testuppsättning som hålls ut från träningsdata och databehandlingsmått från dessa förutsägelser som vägleder beslut om modelldistribution. Därför finns det ett slutsatsdragningsläge som lämpar sig för modellutvärdering: en löpande prognos.
En metod för bästa praxis för att utvärdera en prognosmodell är att rulla den tränade prognosmakaren framåt i tid över testuppsättningen, med medelvärde för felmått över flera förutsägelsefönster. Den här proceduren kallas ibland för ett backtest. Helst är testuppsättningen för utvärderingen lång i förhållande till modellens prognoshorisont. Uppskattningar av prognosfel kan annars vara statistiskt bullriga och därför mindre tillförlitliga.
Följande diagram visar ett enkelt exempel med tre prognosfönster:
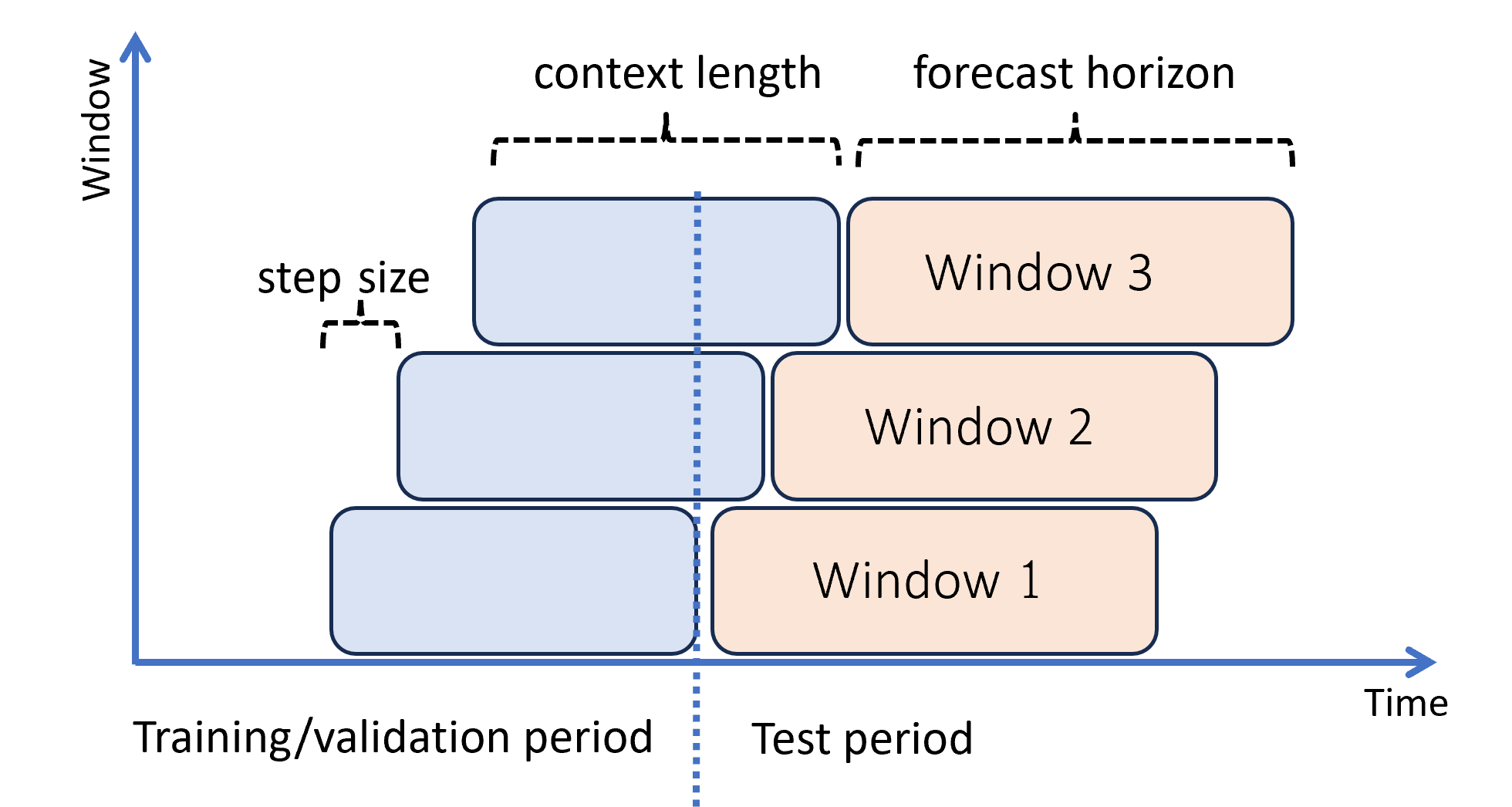
Diagrammet illustrerar tre rullande utvärderingsparametrar:
- Kontextlängden är den mängd historik som modellen kräver för att göra en prognos.
- Prognoshorisonten är hur långt framåt prognosmakaren är tränad att förutsäga.
- Stegstorleken är hur långt fram i tiden det rullande fönstret avancerar för varje iteration i testuppsättningen.
Kontexten utvecklas tillsammans med prognosfönstret. Faktiska värden från testuppsättningen används för att göra prognoser när de faller inom det aktuella kontextfönstret. Det senaste datumet för faktiska värden som används för ett visst prognosfönster kallas fönstrets ursprungstid . Följande tabell visar ett exempel på utdata från den rullande prognosen med tre fönster med en horisont på tre dagar och en stegstorlek på en dag:
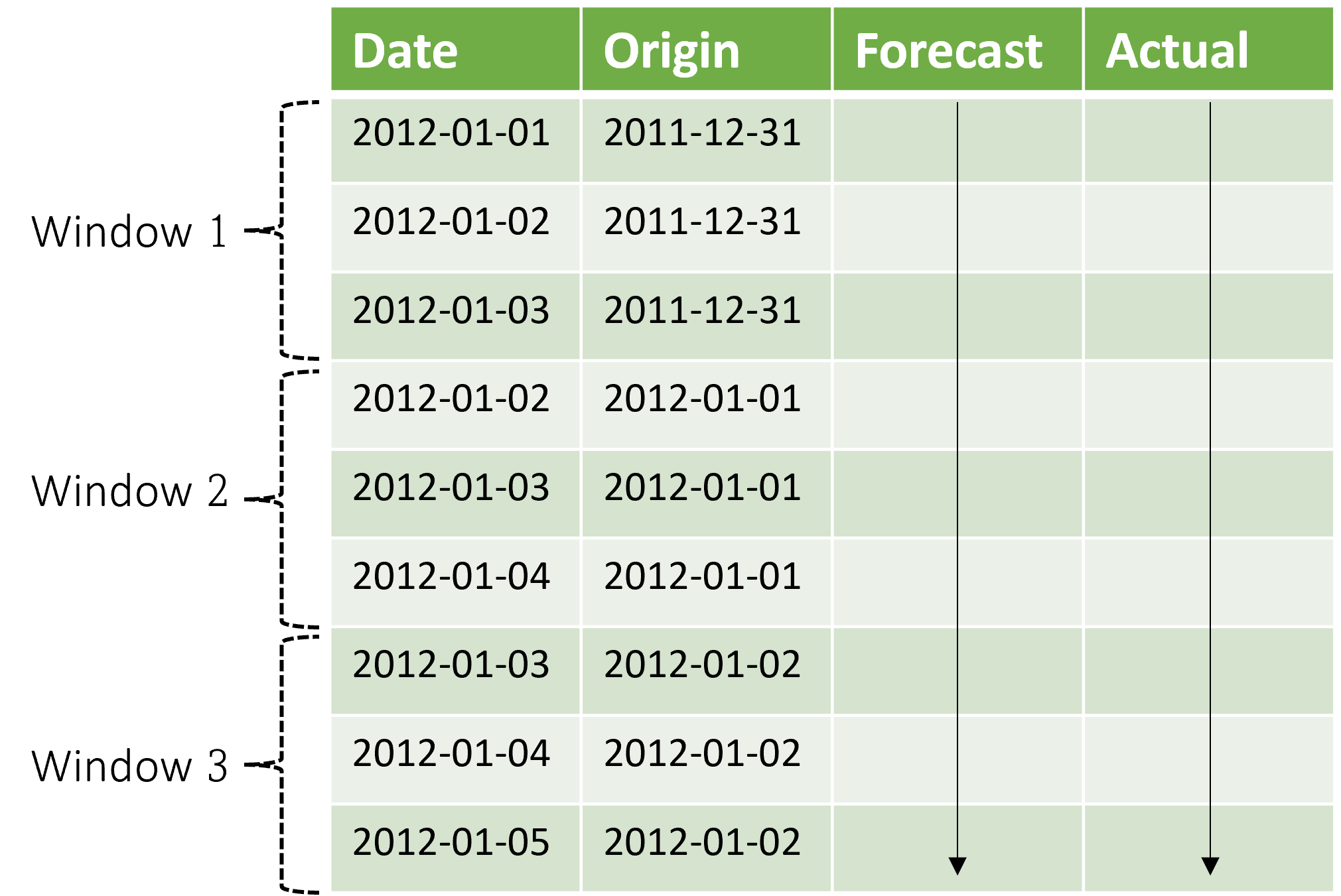
Med en tabell som denna kan du visualisera prognoserna jämfört med de faktiska värdena och beräkna önskade utvärderingsmått. AutoML-pipelines kan generera löpande prognoser på en testuppsättning med en slutsatsdragningskomponent.
Kommentar
När testperioden är lika lång som prognoshorisonten ger en rullande prognos ett enda fönster med prognoser upp till horisonten.
Utvärderingsmått
Det specifika affärsscenariot styr vanligtvis valet av utvärderingssammanfattning eller mått. Några vanliga alternativ är följande exempel:
- Diagram över observerade målvärden jämfört med prognostiserade värden för att kontrollera att viss dynamik i de data som modellen samlar in
- Genomsnittligt absolut procentfel (MAPE) mellan faktiska och prognostiserade värden
- RMSE (Root Mean Squared Error), eventuellt med en normalisering, mellan faktiska och prognostiserade värden
- Genomsnittligt absolut fel (MAE), eventuellt med en normalisering, mellan faktiska och prognostiserade värden
Det finns många andra möjligheter, beroende på affärsscenariot. Du kan behöva skapa egna verktyg efter bearbetning för beräkning av utvärderingsmått från slutsatsdragningsresultat eller löpande prognoser. Mer information om mått finns i Regression/prognostiseringsmått.
Relaterat innehåll
- Läs mer om hur du konfigurerar AutoML för att träna en prognosmodell för tidsserier.
- Lär dig mer om hur AutoML använder maskininlärning för att skapa prognosmodeller.
- Läs svar på vanliga frågor om prognostisering i AutoML.