Modellsopning och val för prognostisering i AutoML
Den här artikeln fokuserar på hur AutoML söker efter och väljer prognosmodeller. Mer allmän information om prognosmetoder i AutoML finns i artikeln om metodöversikt för metoder . Instruktioner och exempel för modeller för träningsprognoser i AutoML finns i vår artikel om att konfigurera AutoML för prognostisering av tidsserier .
Modellsopning
Den centrala uppgiften för AutoML är att träna och utvärdera flera modeller och välja den bästa med avseende på det angivna primära måttet. Ordet "modell" här refererar till både modellklassen – till exempel ARIMA eller Slumpmässig skog – och de specifika hyperparameterinställningarna som särskiljer modeller i en klass. Till exempel refererar ARIMA till en klass med modeller som delar en matematisk mall och en uppsättning statistiska antaganden. Träning eller anpassning av en ARIMA-modell kräver en lista över positiva heltal som anger modellens exakta matematiska form. det här är hyperparametrarna. ARIMA(1, 0, 1) och ARIMA(2, 1, 2) har samma klass, men olika hyperparametrar och kan därför passas separat med träningsdata och utvärderas mot varandra. AutoML-sökningar, eller genomsökningar, över olika modellklasser och inom klasser efter olika hyperparametrar.
I följande tabell visas de olika svepmetoder för hyperparametrar som AutoML använder för olika modellklasser:
| Modellklassgrupp | Modelltyp | Svepmetod för hyperparametrar |
|---|---|---|
| Naive, Seasonal Naive, Average, Seasonal Average | Tidsserier | Ingen svepning i klassen på grund av modell enkelhet |
| Exponentiell utjämning, ARIMA(X) | Tidsserier | Rutnätssökning efter svepning inom klassen |
| Profeten | Regression | Ingen svepning inom klassen |
| Linjär SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | Regression | AutoML:s modellrekommendationstjänst utforskar dynamiskt hyperparameterutrymmen |
| ForecastTCN | Regression | Statisk lista över modeller följt av slumpmässig sökning över nätverksstorlek, avhoppsförhållande och inlärningstakt. |
En beskrivning av de olika modelltyperna finns i avsnittet prognosmodeller i översiktsartikeln om metoder.
Mängden svepning som AutoML gör beror på konfigurationen av prognostiseringsjobbet. Du kan ange stoppkriterierna som en tidsgräns eller en gräns för antalet utvärderingsversioner, eller motsvarande antal modeller. Logik för tidig avslutning kan användas i båda fallen för att sluta svepa om det primära måttet inte förbättras.
Modellval
Sökning och val av autoML-prognosmodell fortsätter i följande tre faser:
- Svep över tidsseriemodeller och välj den bästa modellen från varje klass med hjälp av straffade sannolikhetsmetoder.
- Svep över regressionsmodeller och rangordna dem, tillsammans med de bästa tidsseriemodellerna från fas 1, enligt deras primära måttvärden från valideringsuppsättningar.
- Skapa en ensemblemodell från de högst rankade modellerna, beräkna dess valideringsmått och rangordna den med de andra modellerna.
Modellen med det högst rankade måttvärdet i slutet av fas 3 utses till den bästa modellen.
Viktigt
AutoML:s sista fas av modellval beräknar alltid mått på out-of-sample-data . Data som inte användes för att passa modellerna. Detta hjälper till att skydda mot överanpassning.
AutoML har två valideringskonfigurationer – korsvalidering och explicita valideringsdata. I korsvalideringsfallet använder AutoML indatakonfigurationen för att skapa datadelningar i tränings- och valideringsdelegeringar. Tidsordningen måste bevaras i dessa delningar, så AutoML använder så kallad rullande korsvalidering av ursprung som delar in serien i tränings- och valideringsdata med hjälp av en ursprungstidspunkt. Om du skjuter ursprunget i tid genereras korsvalideringsvecken. Varje valideringsveck innehåller nästa horisont av observationer omedelbart efter ursprungets position för den angivna vikningen. Den här strategin bevarar dataintegriteten för tidsserier och minskar risken för informationsläckage.
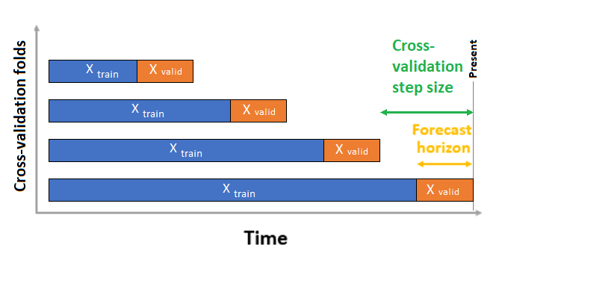
AutoML följer den vanliga korsvalideringsproceduren och tränar en separat modell för varje vikning och medelvärde av valideringsmått från alla vik.
Korsvalidering för prognostiseringsjobb konfigureras genom att ange antalet korsvalideringsdelegeringar och, om du vill, antalet tidsperioder mellan två på varandra följande korsvalideringsdelegeringar. Mer information och ett exempel på hur du konfigurerar korsvalidering för prognostisering finns i guiden för anpassade inställningar för korsvalidering .
Du kan också ta med egna valideringsdata. Läs mer i artikeln konfigurera datadelningar och korsvalidering i AutoML (SDK v1).
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för