Utvärdera fel i maskininlärningsmodeller
En av de största utmaningarna med aktuella metoder för modellfelsökning är att använda aggregerade mått för att poängsätta modeller på en benchmark-datamängd. Modellens noggrannhet kanske inte är enhetlig mellan undergrupper av data och det kan finnas indatakohorter som modellen misslyckas oftare för. De direkta konsekvenserna av dessa fel är brist på tillförlitlighet och säkerhet, utseendet på rättvisefrågor och en förlust av förtroende för maskininlärning helt och hållet.

Felanalys flyttas bort från mått för aggregerad noggrannhet. Det exponerar distributionen av fel till utvecklare på ett transparent sätt och gör det möjligt för dem att identifiera och diagnostisera fel effektivt.
Komponenten för felanalys i instrumentpanelen för ansvarsfull AI ger maskininlärningsutövare en djupare förståelse för modellfelsdistribution och hjälper dem att snabbt identifiera felaktiga kohorter av data. Den här komponenten identifierar kohorterna av data med en högre felfrekvens jämfört med den övergripande referensfelfrekvensen. Det bidrar till identifieringssteget i modellens livscykelarbetsflöde genom:
- Ett beslutsträd som visar kohorter med höga felfrekvenser.
- En värmekarta som visualiserar hur indatafunktioner påverkar felfrekvensen i kohorter.
Felavvikelser kan uppstå när systemet underpresterar för specifika demografiska grupper eller sällan observerade indatakohorter i träningsdata.
Funktionerna i den här komponenten kommer från paketet Felanalys , som genererar modellfelprofiler.
Använd felanalys när du behöver:
- Få en djup förståelse för hur modellfel distribueras över en datauppsättning och över flera indata- och funktionsdimensioner.
- Dela upp de aggregerade prestandamåtten för att automatiskt identifiera felaktiga kohorter för att informera dina riktade åtgärdssteg.
Felträd
Ofta är felmönster komplexa och omfattar mer än en eller två funktioner. Utvecklare kan ha svårt att utforska alla möjliga kombinationer av funktioner för att upptäcka dolda datafickor med kritiska fel.
För att minska belastningen partitionerar visualiseringen av binärträd automatiskt benchmark-data i tolkningsbara undergrupper som har oväntat höga eller låga felfrekvenser. Med andra ord använder trädet indatafunktionerna för att maximalt separera modellfel från framgång. För varje nod som definierar en dataundergrupp kan användarna undersöka följande information:
- Felfrekvens: En del av instanserna i noden som modellen är felaktig för. Det visas genom intensiteten i den röda färgen.
- Feltäckning: En del av alla fel som hamnar i noden. Den visas genom nodens fyllningshastighet.
- Datarepresentation: Antalet instanser i varje nod i felträdet. Den visas genom tjockleken på den inkommande gränsen till noden, tillsammans med det totala antalet instanser i noden.

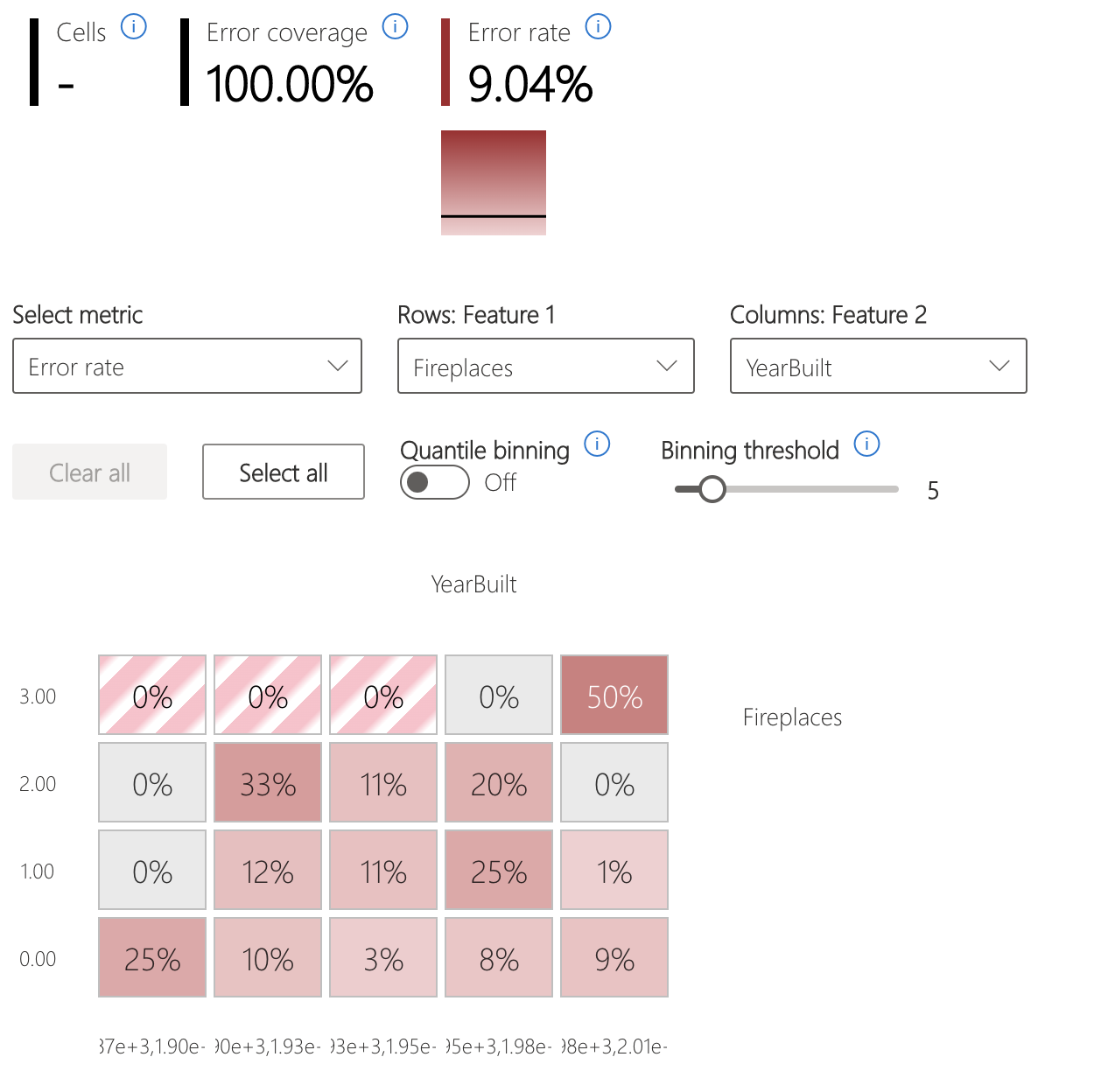
Fel på värmekarta
Vyn segmentar data baserat på ett endimensionellt eller tvådimensionellt rutnät med indatafunktioner. Användare kan välja de indatafunktioner som är intressanta för analys.
Värmekartan visualiserar celler med höga fel genom att använda en mörkare röd färg för att uppmärksamma användaren på dessa regioner. Den här funktionen är särskilt fördelaktig när felteman skiljer sig mellan partitioner, vilket ofta sker i praktiken. I den här felidentifieringsvyn vägleds analysen starkt av användarna och deras kunskaper eller hypoteser om vilka funktioner som kan vara viktigast för att förstå fel.
Nästa steg
- Lär dig hur du genererar instrumentpanelen ansvarsfull AI via CLI och SDK eller Azure Mašinsko učenje Studio UI.
- Utforska de felanalysvisualiseringar som stöds.
- Lär dig hur du genererar ett ansvarsfullt AI-styrkort baserat på de insikter som observerats på instrumentpanelen ansvarsfull AI.