Vad en hanterad funktionsbutik är för något?
För hanterad funktionsbutik vill vi att maskininlärningspersonal som du självständigt utvecklar och produktionsanpassar funktioner. Du anger en funktionsuppsättningsspecifikation. Systemet hanterar servering, skydd och övervakning av funktionerna. Detta frigör dig från den underliggande funktionstekniska pipelineuppsättningen och hanteringskostnaderna.
Tack vare integreringen av vår funktionsbutik i maskininlärningslivscykeln kan du experimentera och leverera modeller snabbare, öka tillförlitligheten för dina modeller och minska dina driftskostnader. Omdefinitionen av maskininlärningsupplevelsen ger dessa fördelar.
Mer information om entiteter på toppnivå i funktionsarkivet, inklusive specifikationer för funktionsuppsättningar, finns i Förstå entiteter på toppnivå i hanterad funktionsbutik.
Vad är funktioner?
En funktion fungerar som indata för din modell. För datadrivna användningsfall i en företagskontext transformerar en funktion ofta historiska data (enkla aggregeringar, fönsteraggregat, transformeringar på radnivå osv.). Tänk dig till exempel en maskininlärningsmodell för kundomsättning. Modellindata kan inkludera kundinteraktionsdata – till exempel 7day_transactions_sum (antal transaktioner under de senaste sju dagarna) eller 7day_complaints_sum (antal klagomål under de senaste sju dagarna). Båda dessa aggregeringsfunktioner beräknas på de senaste sju dagarnas data.
Problem som löses av funktionsarkivet
För att bättre förstå hanterad funktionsbutik bör du först förstå de problem som ett funktionsarkiv kan lösa.
Med ett funktionsarkiv kan du söka efter och återanvända funktioner som ditt team skapar, för att undvika redundant arbete och leverera konsekventa förutsägelser.
Du kan skapa en ny funktion med möjlighet till omvandlingar för att hantera funktionsutvecklingskrav på ett agilt och dynamiskt sätt.
Systemet operationaliserar och hanterar de funktionstekniska pipelines som krävs för omvandling och materialisering för att befria ditt team från driftaspekterna.
Du kan använda samma funktionspipeline, som ursprungligen användes för att träna datagenerering, för ny användning i slutsatsdragningssyfte för att ge konsekvens online/offline och för att undvika skev träning/servering.
Dela hanterad funktionsbutik
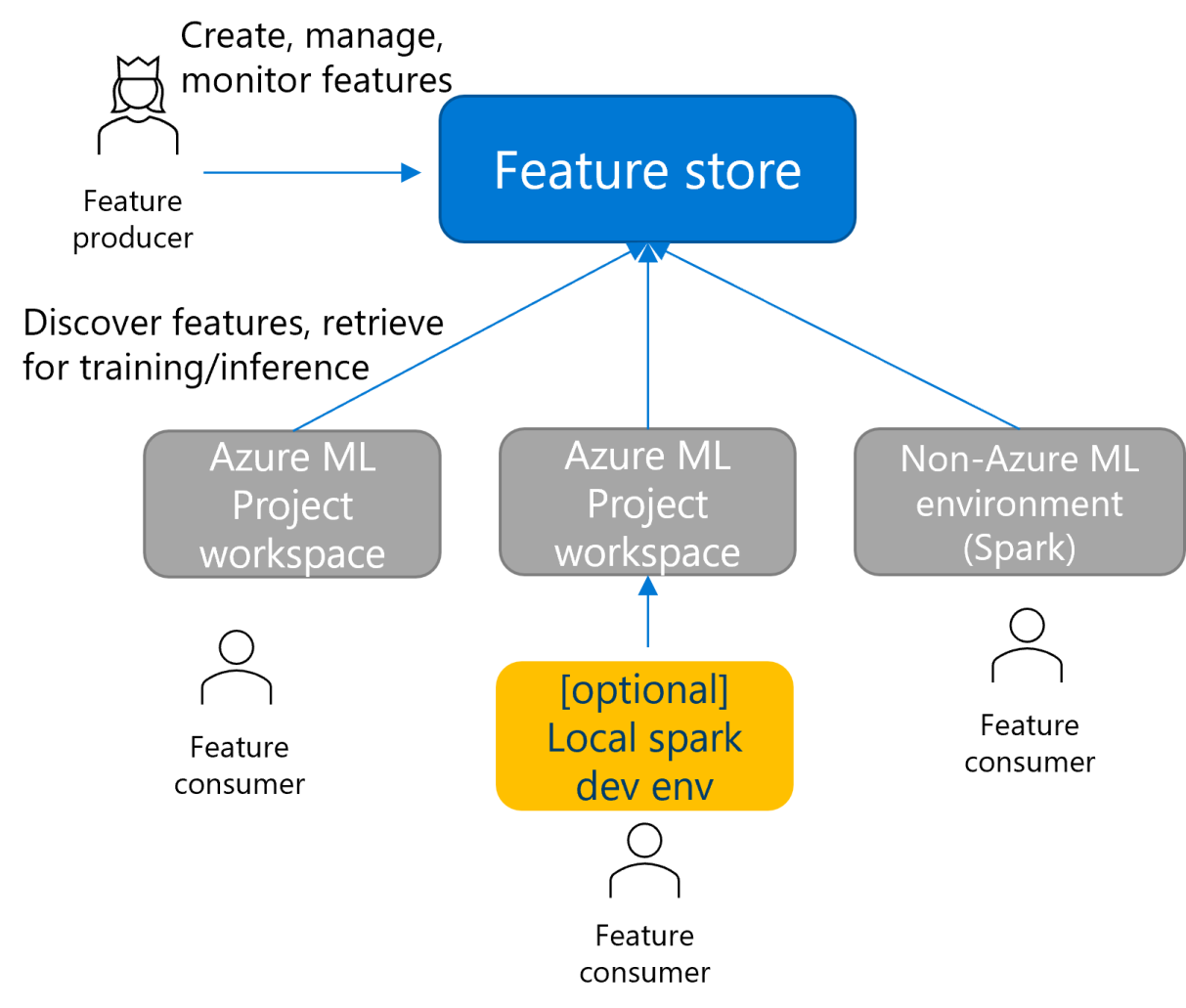
Funktionsarkiv är en ny typ av arbetsyta som flera projektarbetsytor kan använda. Du kan använda funktioner från Andra Spark-baserade miljöer än Azure Machine Learning, till exempel Azure Databricks. Du kan också utföra lokal utveckling och testning av funktioner.
Översikt över funktionsarkiv
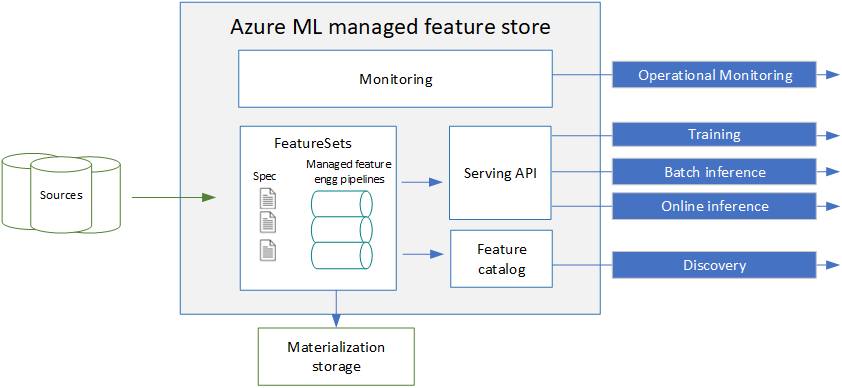
För hanterad funktionsbutik anger du en funktionsuppsättningsspecifikation. Sedan hanterar systemet servering, skydd och övervakning av dina funktioner. En funktionsuppsättningsspecifikation innehåller funktionsdefinitioner och valfri transformeringslogik. Du kan också deklarativt ange materialiseringsinställningar för materialisering till ett offlinearkiv (ADLS Gen2). Systemet genererar och hanterar de underliggande pipelines för funktionsmaterialisering. Du kan använda funktionskatalogen för att söka efter, dela och återanvända funktioner. Med api:et för servering kan användarna söka efter funktioner för att generera data för träning och slutsatsdragning. Det betjänande API:et kan hämta data direkt från källan eller från ett materialiseringslager offline för träning/batch-slutsatsdragning. Systemet innehåller också funktioner för att övervaka funktionsmaterialiseringsjobb.
Fördelar med att använda Azure Machine Learning-hanterad funktionsbutik
- Ökar flexibiliteten vid leverans av modellen (prototyper till operationalisering):
- Identifiera och återanvända funktioner i stället för att skapa funktioner från grunden
- Snabbare experimentering med lokal utveckling/testning av nya funktioner med transformeringsstöd och användning av funktionshämtningsspecifikation som bindväv i MLOps-flödet
- Deklarativ materialisering och återfyllnad
- Fördefinierade konstruktioner: funktionshämtningskomponent och funktionshämtningsspecifikation
- Förbättrar tillförlitligheten för ML-modeller
- En konsekvent funktionsdefinition för affärsenhet/organisation
- Funktionsuppsättningar är versionshanterade och oföränderliga: Nyare modeller kan använda nyare funktionsversioner utan att störa den äldre versionen av modellen
- Övervaka materialisering av funktionsuppsättningar
- Materialisering undviker träning/serveringssnedvridning
- Funktionshämtning stöder tidsmässiga kopplingar (kallas även tidsresor) för att undvika dataläckage.
- Minskar kostnaden
- Återanvänd funktioner som skapats av andra i organisationen
- Materialisering och övervakning är systemhanterade för att minska tekniska kostnader
Identifiera och hantera funktioner
Det hanterade funktionsarkivet innehåller dessa funktioner för identifiering och hantering av funktioner:
- Sök och återanvända funktioner – Du kan söka efter och återanvända funktioner i funktionslager
- Stöd för versionshantering – Funktionsuppsättningar är versionshanterade och oföränderliga, vilket gör att du oberoende kan hantera funktionsuppsättningens livscykel. Du kan distribuera nya modellversioner med olika funktionsversioner och undvika avbrott i den äldre modellversionen
- Visa kostnader på funktionslagernivå – Den primära kostnaden som är kopplad till användning av funktionslager omfattar hanterade Spark-materialiseringsjobb. Du kan se den här kostnaden på funktionslagringsnivå
- Användning av funktionsuppsättningar – Du kan se listan över registrerade modeller med hjälp av funktionsuppsättningarna.
Funktionstransformering
Funktionstransformering omfattar funktionsändring av datauppsättningar för att förbättra modellens prestanda. Transformeringskoden, som definieras i en funktionsspecifikation, hanterar funktionstransformeringen. För snabbare experimentering utför transformeringskoden beräkningar på källdata och möjliggör lokal utveckling och testning av transformeringar.
I det hanterade funktionsarkivet finns följande funktioner för funktionstransformering:
- Stöd för anpassade transformeringar – Du kan skriva en Spark-transformerare för att utveckla funktioner med anpassade transformeringar , till exempel fönsterbaserade aggregeringar
- Stöd för förberäknade funktioner – Du kan ta in fördefinierade funktioner i funktionsarkivet och hantera dem utan att skriva kod
- Lokal utveckling och testning – Med en Spark-miljö kan du utveckla och testa funktionsuppsättningar lokalt
Materialisering av funktioner
Materialisering omfattar beräkning av funktionsvärden för ett visst funktionsfönster och beständighet för dessa värden i ett materialiseringslager. Nu kan funktionsdata hämtas snabbare och mer tillförlitligt i utbildnings- och slutsatsdragningssyfte.
- Pipeline för materialisering av hanterade funktioner – Du anger materialiseringsschemat deklarativt och systemet hanterar sedan schemaläggning, förkomputation och materialisering av värdena i materialiseringsarkivet
- Stöd för återfyllnad – Du kan utföra materialisering på begäran av funktionsuppsättningar för ett visst funktionsfönster
- Hanterat Spark-stöd för materialisering – Azure Machine Learning managed Spark (i serverlösa beräkningsinstanser) kör materialiseringsjobben. Det frigör dig från konfiguration och hantering av Spark-infrastrukturen.
Kommentar
Både offlinebutiken (ADLS Gen2) och onlinebutiken (Redis) stöds för närvarande.
Funktionshämtning
Azure Machine Learning innehåller en inbyggd komponent som hanterar hämtning av offlinefunktioner. Det tillåter användning av funktionerna i utbildnings- och batchinferensstegen för ett Azure Machine Learning-pipelinejobb.
Det hanterade funktionsarkivet innehåller följande funktioner för hämtning av funktioner:
- Deklarativ träningsdatagenerering – Med den inbyggda komponenten för funktionshämtning kan du generera träningsdata i dina pipelines utan att skriva någon kod
- Deklarativ batchinferensdatagenerering – Med samma inbyggda funktionshämtningskomponent kan du generera batchinferensdata
- Programmatisk funktionshämtning – Du kan också använda Python SDK
get_offline_features()för att generera tränings-/slutsatsdragningsdata
Övervakning
I det hanterade funktionsarkivet finns följande övervakningsfunktioner:
- Status för materialiseringsjobb – Du kan visa status för materialiseringsjobb med hjälp av användargränssnittet, CLI eller SDK
- Meddelande om materialiseringsjobb – Du kan konfigurera e-postaviseringar om materialiseringsjobbens olika status
Säkerhet
Det hanterade funktionsarkivet innehåller följande säkerhetsfunktioner:
- RBAC – rollbaserad åtkomstkontroll för funktionsarkiv, funktionsuppsättning och entiteter.
- Fråga mellan funktionslager – Du kan skapa flera funktionslager med olika åtkomstbehörigheter för användare, men tillåta frågor (till exempel generera träningsdata) från flera funktionslager