Datavetenskap med en Windows Data Science Virtual Machine
Windows Data Science Virtual Machine (DSVM) är en kraftfull utvecklingsmiljö för datavetenskap som stöder datautforskning och modelleringsuppgifter. Miljön levereras fördefinierad och fördefinierad med flera populära dataanalysverktyg som gör det enkelt att starta din analys för lokala distributioner, molndistributioner eller hybriddistributioner.
DSVM har ett nära samarbete med Azure-tjänster. Den kan läsa och bearbeta data som redan lagras i Azure, i Azure Synapse (tidigare SQL DW), Azure Data Lake, Azure Storage eller Azure Cosmos DB. Den kan också dra nytta av andra analysverktyg, till exempel Azure Mašinsko učenje.
I den här artikeln får du lära dig hur du använder din DSVM för att både hantera datavetenskapsuppgifter och interagera med andra Azure-tjänster. Det här är ett exempel på uppgifter som DSVM kan omfatta:
- Använd en Jupyter Notebook för att experimentera med dina data i en webbläsare med hjälp av Python 2, Python 3 och Microsoft R. (Microsoft R är en företagsklar version av R som är utformad för höga prestanda.)
- Utforska data och utveckla modeller lokalt på DSVM med hjälp av Microsoft Mašinsko učenje Server och Python.
- Administrera dina Azure-resurser med hjälp av Azure-portalen eller PowerShell.
- Utöka ditt lagringsutrymme och dela storskaliga datauppsättningar/kod i hela teamet, med en Azure Files-resurs som en monteringsbar enhet på din DSVM.
- Dela kod med ditt team med GitHub. Få åtkomst till din lagringsplats med förinstallerade Git-klienter: Git Bash och Git GUI.
- Få åtkomst till Azures data- och analystjänster:
- Azure Blob Storage
- Azure Cosmos DB
- Azure Synapse (tidigare SQL DW)
- Azure SQL Database
- Skapa rapporter och en instrumentpanel med Power BI Desktop-instansen – förinstallerad på DSVM – och distribuera dem i molnet.
- Installera fler verktyg på den virtuella datorn.
Kommentar
Ytterligare användningsavgifter gäller för många av de datalagrings- och analystjänster som anges i den här artikeln. Gå till sidan med Azure-priser för mer information.
Förutsättningar
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- En etablerad DSVM på Azure-portalen. Mer information finns i resursen Skapa en virtuell dator .
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Information om hur du kommer igång finns i Installera Azure PowerShell. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Använda Jupyter Notebooks
Jupyter Notebook innehåller en webbläsarbaserad IDE för datautforskning och modellering. Du kan använda Python 2, Python 3 eller R i en Jupyter Notebook.
Starta Jupyter Notebook genom att välja ikonen Jupyter Notebook på Start-menyn eller på skrivbordet. I kommandotolken för DSVM kan du också köra kommandot jupyter notebook från katalogen som är värd för befintliga notebook-filer eller där du vill skapa nya notebook-filer.
När du har startat Jupyter går du till /notebooks katalogen. Den här katalogen är värd för exempelanteckningsböcker som är förpaketerade till DSVM. Du kan:
- Välj anteckningsboken för att se koden.
- Välj Skift+Retur för att köra varje cell.
- Välj Cellkörning> för att köra hela anteckningsboken.
- Skapa en ny notebook-fil. välj Jupyter-ikonen (övre vänstra hörnet), välj knappen Nytt och välj sedan notebook-språket (kallas även kernels).
Kommentar
För närvarande stöds Python 2.7-, Python 3.6-, R-, Julia- och PySpark-kernels i Jupyter. R-kerneln stöder programmering i både R med öppen källkod och Microsoft R. I notebook-filen kan du utforska dina data, skapa din modell och testa modellen med valfritt bibliotek.
Utforska data och utveckla modeller med Microsoft Mašinsko učenje Server
Kommentar
Supporten för Mašinsko učenje Server Standalone upphörde den 1 juli 2021. Vi tog bort den från DSVM-avbildningarna efter den 30 juni 2021. Befintliga distributioner kan fortfarande komma åt programvaran, men supporten upphörde efter den 1 juli 2021.
Du kan använda R och Python för din dataanalys direkt på DSVM.
För R kan du använda R Tools för Visual Studio. Microsoft tillhandahåller andra bibliotek utöver CRAN R-resursen med öppen källkod. Dessa bibliotek möjliggör både skalbar analys och möjlighet att analysera datamassor som överskrider minnesstorleksbegränsningarna för parallell segmenterad analys.
För Python kan du använda en IDE – till exempel Visual Studio Community Edition – som har tillägget Python Tools for Visual Studio (PTVS) förinstallerat. Som standard konfigureras endast Python 3.6, conda-rotmiljön, på PTVS. Så här aktiverar du Anaconda Python 2.7:
- Skapa anpassade miljöer för varje version. Välj Verktyg>Python Tools>Python-miljöer och välj sedan + Anpassad i Visual Studio Community Edition.
- Ange en beskrivning och ange miljöprefixsökvägen som c:\anaconda\envs\python2 för Anaconda Python 2.7.
- Välj Använd automatiskt för>att spara miljön.
Besök PTVS-dokumentationsresursen för mer information om hur du skapar Python-miljöer.
Nu kan du skapa ett nytt Python-projekt. Välj Arkiv>Nytt>projekt>Python och välj den typ av Python-program som du vill skapa. Du kan ange Python-miljön för det aktuella projektet till önskad version (Python 2.7 eller 3.6) genom att högerklicka på Python-miljöer och sedan välja Lägg till/ta bort Python-miljöer. Mer information om hur du arbetar med PTVS finns i produktdokumentationen.
Hantera Azure-resurser
Med DSVM kan du skapa din analyslösning lokalt på den virtuella datorn. Du kan också komma åt tjänster på Azure-molnplattformen. Azure tillhandahåller flera tjänster, inklusive beräkning, lagring, dataanalys med mera, som du kan administrera och komma åt från din DSVM.
Du har två tillgängliga alternativ för att administrera din Azure-prenumeration och dina molnresurser:
Besök Azure-portalen i webbläsaren.
Använd PowerShell-skript. Kör Azure PowerShell från en genväg eller från Start-menyn . Mer information finns i dokumentationsresursen för Microsoft Azure PowerShell.
Utöka lagringen med hjälp av delade filsystem
Dataexperter kan dela stora datamängder, kod eller andra resurser i teamet. DSVM har cirka 45 GB ledigt utrymme. Om du vill utöka lagringen kan du använda Azure Files och antingen montera den på en eller flera DSVM-instanser eller komma åt den med ett REST-API. Du kan också använda Azure-portalen eller använda Azure PowerShell för att lägga till extra dedikerade datadiskar.
Kommentar
Det maximala utrymmet på en Azure-filresurs är 5 TB. Varje fil har en storleksgräns på 1 TB.
Det här Azure PowerShell-skriptet skapar en Azure Files-resurs:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Du kan montera en Azure Files-resurs på valfri virtuell dator i Azure. Vi föreslår att du placerar den virtuella datorn och lagringskontot i samma Azure-datacenter för att undvika svarstider och avgifter för dataöverföring. Dessa Azure PowerShell-kommandon monterar enheten på DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Du kan komma åt den här enheten på samma sätt som vilken normal enhet som helst på den virtuella datorn.
Dela kod i GitHub
GitHub-kodlagringsplatsen är värd för kodexempel och kodkällor för många verktyg som utvecklarcommunityn delar. Den använder Git som teknik för att spåra och lagra versioner av kodfilerna. GitHub fungerar också som en plattform för att skapa en egen lagringsplats. Din egen lagringsplats kan lagra teamets delade kod och dokumentation, implementera versionskontroll och kontrollera åtkomstbehörigheter för intressenter som vill visa och bidra med kod. GitHub stöder samarbete inom ditt team, användning av kod som utvecklats av communityn och bidrag av kod tillbaka till communityn. Besök GitHub-hjälpsidorna för mer information om Git.
DSVM läses in med klientverktyg på kommandoraden och i GUI för att få åtkomst till GitHub-lagringsplatsen. Git Bash-kommandoradsverktyget fungerar med Git och GitHub. Visual Studio är installerat på DSVM och har Git-tilläggen. Både Start-menyn och skrivbordet har ikoner för dessa verktyg.
git clone Använd kommandot för att ladda ned kod från en GitHub-lagringsplats. Om du vill ladda ned data science-lagringsplatsen som publicerats av Microsoft till den aktuella katalogen kör du till exempel det här kommandot i Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio kan hantera samma kloningsåtgärd. Den här skärmbilden visar hur du kommer åt Git- och GitHub-verktyg i Visual Studio:

Du kan arbeta med tillgängliga github.com resurser på din GitHub-lagringsplats. Mer information finns i resursen för GitHub-fuskarket .
Få åtkomst till Azures data- och analystjänster
Azure Blob Storage
Azure Blob Storage är en tillförlitlig, ekonomisk molnlagringstjänst för både stora och små dataresurser. I det här avsnittet beskrivs hur du flyttar data till Blob Storage och får åtkomst till data som lagras i en Azure-blob.
Förutsättningar
Ett Azure Blob Storage-konto som skapats i Azure-portalen.
Bekräfta att kommandoradsverktyget AzCopy är förinstallerat med det här kommandot:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeKatalogen som är värd för azcopy.exe finns redan i path-miljövariabeln, så du kan undvika att skriva den fullständiga kommandosökvägen när du kör det här verktyget. Mer information om AzCopy-verktyget finns i AzCopy-dokumentationen.
Starta Azure Storage Explorer-verktyget. Du kan ladda ned den från webbsidan för Storage Explorer.


Flytta data från en virtuell dator till en Azure-blob: AzCopy
Om du vill flytta data mellan dina lokala filer och Blob Storage kan du använda AzCopy på kommandoraden eller i PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Ersätt C:\myfolder med katalogsökvägen som är värd för filen
- Ersätt mystorageaccount med namnet på ditt Blob Storage-konto
- Ersätt mycontainer med containernamnet
- Ersätt lagringskontonyckeln med åtkomstnyckeln för Blob Storage
Du hittar dina autentiseringsuppgifter för lagringskontot i Azure-portalen.
Kör AzCopy-kommandot i PowerShell eller från en kommandotolk. Det här är AzCopy-kommandoexempel:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
När du har kört Kommandot AzCopy för att kopiera filen till en Azure-blob visas filen i Azure Storage Explorer.

Flytta data från en virtuell dator till en Azure-blob: Azure Storage Explorer
Du kan också ladda upp data från den lokala filen på den virtuella datorn med Azure Storage Explorer:
Om du vill ladda upp data till en container väljer du målcontainern och väljer knappen Ladda upp .
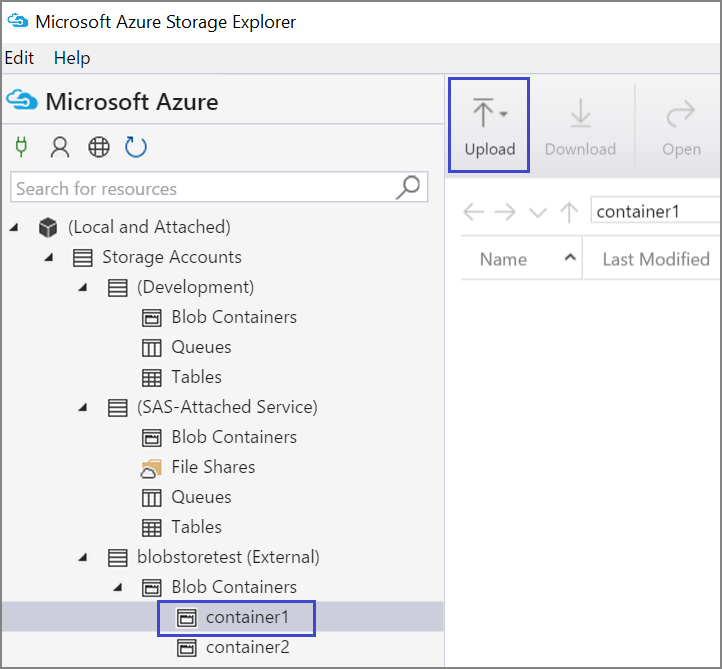
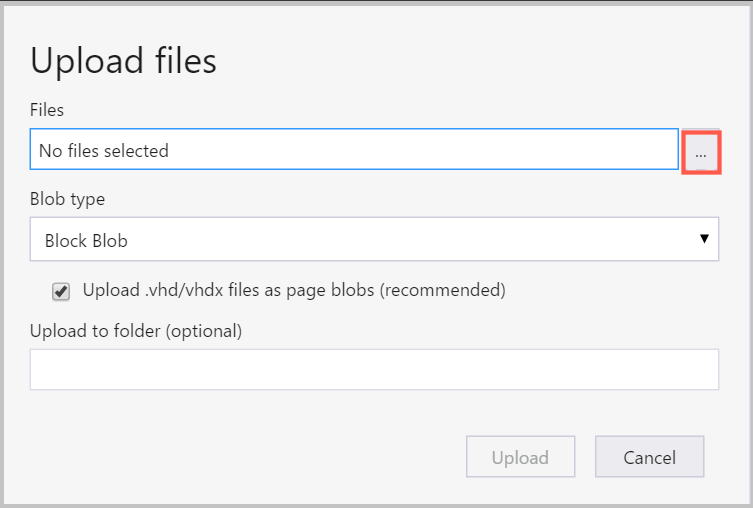
Till höger om rutan Filer väljer du ellipsen (...), väljer en eller flera filer som ska laddas upp från filsystemet och väljer Ladda upp för att börja ladda upp filerna.


Läsa data från en Azure-blob: Python ODBC
BlobService-biblioteket kan läsa data direkt från en blob som finns i en Jupyter Notebook eller i ett Python-program. Importera först de paket som krävs:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Anslut autentiseringsuppgifterna för ditt Blob Storage-konto och läs data från bloben:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Data läss som en dataram:

Azure Synapse Analytics och databaser
Azure Synapse Analytics är ett elastiskt informationslager som en tjänst med en SQL Server-upplevelse i företagsklass. Den här resursen beskriver hur du etablerar Azure Synapse Analytics. När du har etablerat Azure Synapse Analytics förklarar den här genomgången hur du hanterar dataöverföring, utforskning och modellering med hjälp av data i Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB är en molnbaserad NoSQL-databas. Den kan till exempel hantera JSON-dokument och kan lagra och köra frågor mot dokumenten. De här exempelstegen visar hur du kommer åt Azure Cosmos DB från DSVM:
Azure Cosmos DB Python SDK är redan installerat på DSVM. Om du vill uppdatera den kör du
pip install pydocumentdb --upgradefrån en kommandotolk.Skapa ett Azure Cosmos DB-konto och en databas från Azure-portalen.
Ladda ned Datamigreringsverktyget för Azure Cosmos DB från Microsoft Download Center och extrahera det till valfri katalog.
Importera JSON-data (vulkandata) som lagras i en offentlig blob till Azure Cosmos DB med följande kommandoparametrar till migreringsverktyget. (Använd dtui.exe från katalogen där du installerade Datamigreringsverktyget för Azure Cosmos DB.) Ange käll- och målplatsen med följande parametrar:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
När du har importerat data kan du gå till Jupyter och öppna anteckningsboken med titeln DocumentDBSample. Den innehåller Python-kod för att komma åt Azure Cosmos DB och hantera vissa grundläggande frågor. Besök dokumentationssidan för Azure Cosmos DB-tjänsten för mer information om Azure Cosmos DB.
Använda Power BI-rapporter och instrumentpaneler
Du kan visualisera Volcano JSON-filen som beskrivs i föregående Azure Cosmos DB-exempel i Power BI Desktop för visuella insikter om själva data. Den här Power BI-artikeln innehåller detaljerade steg. Det här är stegen på en hög nivå:
- Öppna Power BI Desktop och välj Hämta data. Ange den här URL:en:
https://cahandson.blob.core.windows.net/samples/volcano.json. - JSON-posterna, som importeras som en lista, bör bli synliga. Konvertera listan till en tabell så att Power BI kan fungera med den.
- Välj ikonen expandera (pil) för att expandera kolumnerna.
- Platsen är ett postfält . Expandera posten och välj endast koordinaterna. Koordinat är en listkolumn.
- Lägg till en ny kolumn för att konvertera kolumnen för listkoordinaten till en kommaavgränsad LatLong-kolumn . Använd formeln
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})för att sammanfoga de två elementen i fältet koordinatlista. - Konvertera kolumnen Elevation till decimal och välj knapparna Stäng och Använd.
Du kan använda följande kod som ett alternativ till föregående steg. Den skriptar de steg som används i Napredni uređivač i Power BI för att skriva datatransformationerna på ett frågespråk:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Nu har du data i din Power BI-datamodell. Din Power BI Desktop-instans bör visas på följande sätt:

Du kan börja skapa rapporter och visualiseringar med datamodellen. Den här Power BI-artikeln beskriver hur du skapar en rapport.
Skala DSVM dynamiskt
Du kan skala DSVM upp och ned för att uppfylla behoven i projektet. Om du inte behöver använda den virtuella datorn på kvällen eller på helgerna kan du stänga av den virtuella datorn från Azure-portalen.
Kommentar
Du debiteras beräkningsavgifter om du bara använder avstängningsknappen för operativsystemet på den virtuella datorn. I stället bör du frigöra din DSVM med hjälp av Azure-portalen eller Cloud Shell.
För ett storskaligt analysprojekt kan du behöva mer processor-, minnes- eller diskkapacitet. I så fall kan du hitta virtuella datorer med olika antal processorkärnor, minneskapacitet, disktyper (inklusive solid state-enheter) och GPU-baserade instanser för djupinlärning som uppfyller dina beräknings- och budgetbehov. Prissättningssidan för Azure Virtual Machines visar en fullständig lista över virtuella datorer, tillsammans med deras beräkningspriser per timme.
Lägga till fler verktyg
DSVM erbjuder fördefinierade verktyg som kan hantera många vanliga dataanalysbehov. De sparar tid eftersom du inte behöver installera och konfigurera dina miljöer individuellt. De sparar också pengar, eftersom du bara betalar för resurser som du använder.
Du kan använda andra Azure-data- och analystjänster som är profilerade i den här artikeln för att förbättra din analysmiljö. I vissa fall kan du behöva andra verktyg, inklusive specifika proprietära partnerverktyg. Du har fullständig administrativ åtkomst på den virtuella datorn för att installera de verktyg du behöver. Du kan också installera andra paket i Python och R som inte är förinstallerade. För Python kan du använda antingen conda eller pip. För R kan du använda install.packages() i R-konsolen eller använda IDE och välja Paket>Installera paket.
Djupinlärning
Förutom de ramverksbaserade exemplen kan du få en uppsättning omfattande genomgångar som har verifierats på DSVM. De här genomgångarna hjälper dig att komma igång med utvecklingen av djupinlärningsprogram i bild- och text-/språkanalysdomäner.
Köra neurala nätverk i olika ramverk: Den här genomgången visar hur du migrerar kod från ett ramverk till ett annat. Den visar också hur du jämför modeller och körningsprestanda mellan ramverk.
En guide för att skapa en lösning från slutpunkt till slutpunkt för att identifiera produkter i bilder: Bildidentifieringstekniken kan hitta och klassificera objekt i bilder. Den här tekniken har potential att ge enorma belöningar i många verkliga affärsdomäner. Återförsäljare kan till exempel använda den här tekniken för att identifiera en produkt som en kund hämtade från hyllan. Den här informationen hjälper butiker att hantera produktinventering.
Djupinlärning för ljud: Den här självstudien visar hur du tränar en djupinlärningsmodell för identifiering av ljudhändelser i datauppsättningen urbana ljud. Den ger också en översikt över hur du arbetar med ljuddata.
Klassificering av textdokument: Den här genomgången visar hur du skapar och tränar två neurala nätverksarkitekturer: Hierarkiskt uppmärksamhetsnätverk och LSTM-nätverk (Long Short Term Memory). Dessa neurala nätverk använder Keras API för djupinlärning för att klassificera textdokument.
Sammanfattning
I den här artikeln beskrivs några av de saker du kan göra på Microsoft Data Science Virtual Machine. Det finns många fler saker du kan göra för att göra DSVM till en effektiv analysmiljö.