Konfigurera AutoML för att träna en prognosmodell för tidsserier med Python (SDKv1)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du konfigurerar AutoML-träning för prognosmodeller för tidsserier med automatiserad ML i Azure Machine Learning Python SDK.
Det gör du på följande sätt:
- Förbereda data för tidsseriemodellering.
- Konfigurera specifika tidsserieparametrar i ett
AutoMLConfigobjekt. - Kör förutsägelser med tidsseriedata.
En låg kodupplevelse finns i Självstudie: Prognostisera efterfrågan med automatiserad maskininlärning för ett prognostiseringsexempel för tidsserier med automatiserad ML i Azure Machine Learning-studio.
Till skillnad från klassiska tidsseriemetoder "pivoteras" tidigare tidsserievärden i automatiserad ML för att bli ytterligare dimensioner för regressorn tillsammans med andra prediktorer. Den här metoden innehåller flera kontextvariabler och deras relation till varandra under träningen. Eftersom flera faktorer kan påverka en prognos överensstämmer den här metoden väl med verkliga prognosscenarier. När du till exempel prognostiserade försäljningar driver interaktioner mellan historiska trender, växelkurser och priser försäljningsresultatet gemensamt.
Förutsättningar
För den här artikeln behöver du
En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
Den här artikeln förutsätter viss kunskap om hur du konfigurerar ett automatiserat maskininlärningsexperiment. Följ instruktionerna för att se de huvudsakliga designmönstren för automatiserade maskininlärningsexperiment.
Viktigt!
Python-kommandona i den här artikeln kräver den senaste
azureml-train-automlpaketversionen.- Installera det senaste
azureml-train-automlpaketet i din lokala miljö. - Mer information om det senaste
azureml-train-automlpaketet finns i viktig information.
- Installera det senaste
Tränings- och valideringsdata
Den viktigaste skillnaden mellan en prognostiserad regressionsaktivitetstyp och regressionsaktivitetstyp i automatiserad ML är att inkludera en funktion i dina träningsdata som representerar en giltig tidsserie. En vanlig tidsserie har en väldefinierad och konsekvent frekvens och har ett värde vid varje exempelpunkt under ett kontinuerligt tidsintervall.
Viktigt!
När du tränar en modell för att prognostisera framtida värden ska du se till att alla funktioner som används i träning kan användas när du kör förutsägelser för din avsedda horisont. När du till exempel skapar en efterfrågeprognos, inklusive en funktion för aktuell aktiekurs, kan träningsnoggrannheten öka kraftigt. Men om du tänker prognostisera med en lång horisont kanske du inte kan förutsäga framtida aktievärden som motsvarar framtida tidsseriepunkter, och modellnoggrannheten kan bli lidande.
Du kan ange separata träningsdata och valideringsdata direkt i objektet AutoMLConfig . Läs mer om AutoMLConfig.
För tidsserieprognoser används endast ROCV (Rolling Origin Cross Validation) för validering som standard. ROCV delar in serien i tränings- och valideringsdata med hjälp av en ursprungstidspunkt. Om du skjuter ursprunget i tid genereras korsvalideringsvecken. Den här strategin bevarar dataintegriteten för tidsserier och eliminerar risken för dataläckage.
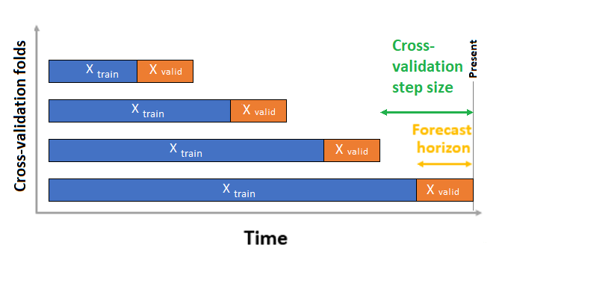
Skicka dina tränings- och valideringsdata som en datauppsättning till parametern training_data. Ange antalet korsvalideringsdelegeringar med parametern n_cross_validations och ange antalet perioder mellan två på varandra följande korsvalideringsdelegeringar med cv_step_size. Du kan också lämna antingen eller båda parametrarna tomma och AutoML ställer in dem automatiskt.
GÄLLER FÖR:Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Du kan också ta med egna valideringsdata, lära dig mer i Konfigurera datadelningar och korsvalidering i AutoML.
Läs mer om hur AutoML tillämpar korsvalidering för att förhindra överanpassning av modeller.
Konfigurera experiment
Objektet AutoMLConfig definierar de inställningar och data som krävs för en automatiserad maskininlärningsuppgift. Konfigurationen för en prognosmodell liknar konfigurationen av en standardregressionsmodell, men vissa modeller, konfigurationsalternativ och funktionaliseringssteg finns specifikt för tidsseriedata.
Modeller som stöds
Automatiserad maskininlärning provar automatiskt olika modeller och algoritmer som en del av processen för att skapa och justera modellen. Som användare behöver du inte ange algoritmen. För prognostiseringsexperiment ingår både interna tidsserier och djupinlärningsmodeller i rekommendationssystemet.
Dricks
Traditionella regressionsmodeller testas också som en del av rekommendationssystemet för prognostiseringsexperiment. Se en fullständig lista över modeller som stöds i SDK-referensdokumentationen.
Konfigurationsinställningar
Precis som ett regressionsproblem definierar du standardträningsparametrar som aktivitetstyp, antal iterationer, träningsdata och antal korsvalideringar. Prognostiseringsuppgifter kräver parametrarna time_column_name och forecast_horizon för att konfigurera experimentet. Om data innehåller flera tidsserier, till exempel försäljningsdata för flera lager eller energidata i olika tillstånd, identifierar automatiserad ML automatiskt detta och anger parametern time_series_id_column_names (förhandsversion) åt dig. Du kan också inkludera ytterligare parametrar för att bättre konfigurera körningen. Mer information om vad som kan ingå finns i avsnittet om valfria konfigurationer .
Viktigt!
Automatisk tidsserieidentifiering finns för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
| Parameternamn | beskrivning |
|---|---|
time_column_name |
Används för att ange kolumnen datetime i indata som används för att skapa tidsserierna och härleda dess frekvens. |
forecast_horizon |
Definierar hur många perioder framåt du vill prognostisera. Horisonten är i enheter för tidsseriefrekvensen. Enheterna baseras på tidsintervallet för dina träningsdata, till exempel varje månad, varje vecka som prognosmakaren ska förutsäga. |
Följande kod:
- Använder klassen för att definiera prognosparametrarna för experimentträningen
ForecastingParameters time_column_nameAnger till fältetday_datetimei datauppsättningen.forecast_horizonAnger till 50 för att förutsäga för hela testuppsättningen.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Dessa forecasting_parameters skickas sedan till standardobjektet AutoMLConfig tillsammans med uppgiftstypen forecasting , det primära måttet, avslutskriterierna och träningsdata.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Mängden data som krävs för att träna en prognosmodell med automatiserad ML påverkas av värdena forecast_horizon, n_cross_validationsoch target_lags eller target_rolling_window_size som anges när du konfigurerar .AutoMLConfig
Följande formel beräknar mängden historiska data som skulle behövas för att konstruera tidsseriefunktioner.
Minsta antal historiska data som krävs: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
En Error exception höjs för alla serier i datauppsättningen som inte uppfyller den mängd historiska data som krävs för de angivna inställningarna.
Funktionaliseringssteg
I varje automatiserat maskininlärningsexperiment tillämpas automatiska skalnings- och normaliseringstekniker på dina data som standard. Dessa tekniker är typer av funktionalisering som hjälper vissa algoritmer som är känsliga för funktioner i olika skalor. Läs mer om standardsteg för funktionalisering i Featurization i AutoML
Följande steg utförs dock endast för forecasting aktivitetstyper:
- Identifiera exempelfrekvens för tidsserier (till exempel varje timme, varje dag, varje vecka) och skapa nya poster för frånvarande tidspunkter för att göra serien kontinuerlig.
- Impute saknade värden i målet (via framåtfyllning) och funktionskolumner (med mediankolumnvärden)
- Skapa funktioner baserat på tidsserieidentifierare för att aktivera fasta effekter i olika serier
- Skapa tidsbaserade funktioner för att lära dig säsongsmönster
- Koda kategoriska variabler till numeriska kvantiteter
- Identifiera den icke-stationära tidsserien och skilja dem automatiskt för att minska effekten av enhetsrötter.
Om du vill visa en fullständig lista över möjliga konstruerade funktioner som genererats från tidsseriedata läser du Klassen TimeIndexFeaturizer.
Kommentar
Automatiserade maskininlärningssteg (funktionsnormalisering, hantering av saknade data, konvertering av text till numeriska osv.) blir en del av den underliggande modellen. När du använder modellen för förutsägelser tillämpas samma funktionaliseringssteg som tillämpas under träningen på dina indata automatiskt.
Anpassa funktionalisering
Du har också möjlighet att anpassa dina funktionaliseringsinställningar för att säkerställa att de data och funktioner som används för att träna ML-modellen resulterar i relevanta förutsägelser.
Anpassningar som stöds för forecasting uppgifter är:
| Anpassning | Definition |
|---|---|
| Uppdatering av kolumnsyfte | Åsidosätt den automatiskt identifierade funktionstypen för den angivna kolumnen. |
| Uppdatering av transformeringsparameter | Uppdatera parametrarna för den angivna transformatorn. Stöder för närvarande Imputer (fill_value och median). |
| Ta bort kolumner | Anger kolumner som ska tas bort från funktionalisering. |
Om du vill anpassa funktionaliseringar med SDK anger du "featurization": FeaturizationConfig i objektet AutoMLConfig . Läs mer om anpassade funktionaliseringar.
Kommentar
Funktionen för släppkolumner är inaktuell från och med SDK version 1.19. Släpp kolumner från datauppsättningen som en del av datarensningen innan du använder den i ditt automatiserade ML-experiment.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Om du använder Azure Machine Learning-studio för experimentet kan du läsa om hur du anpassar funktionalisering i studion.
Valfria konfigurationer
Fler valfria konfigurationer är tillgängliga för prognostiseringsuppgifter, till exempel att aktivera djupinlärning och ange en målsammanfattning för rullande fönster. En fullständig lista över fler parametrar finns i referensdokumentationen för ForecastingParameters SDK.
Frekvens- och måldataaggregering
Använd parametern frequency , freqför att undvika fel som orsakas av oregelbundna data. Oregelbundna data innehåller data som inte följer en fast takt, till exempel data varje timme eller varje dag.
För mycket oregelbundna data eller för varierande affärsbehov kan användarna välja att ange önskad prognosfrekvens och freqange target_aggregation_function för att aggregera målkolumnen i tidsserien. Med de här två inställningarna i objektet AutoMLConfig kan du spara lite tid på dataförberedelser.
Sammansättningsåtgärder som stöds för målkolumnvärden är:
| Function | beskrivning |
|---|---|
sum |
Summan av målvärden |
mean |
Medelvärde eller medelvärde för målvärden |
min |
Minimivärde för ett mål |
max |
Maximalt värde för ett mål |
Aktivera djupinlärning
Kommentar
DNN-stöd för prognostisering i Automatiserad maskininlärning finns i förhandsversion och stöds inte för lokala körningar eller körningar som initieras i Databricks.
Du kan också använda djupinlärning med djupa neurala nätverk, DNN, för att förbättra poängen för din modell. Automatiserad ML:s djupinlärning möjliggör prognostisering av univariate- och multivariate-tidsseriedata.
Djupinlärningsmodeller har tre inbyggda funktioner:
- De kan lära sig av godtyckliga mappningar från indata till utdata
- De stöder flera indata och utdata
- De kan automatiskt extrahera mönster i indata som sträcker sig över långa sekvenser.
Om du vill aktivera djupinlärning anger du enable_dnn=True i AutoMLConfig -objektet.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Varning
När du aktiverar DNN för experiment som skapats med SDK inaktiveras de bästa modellförklaringarna .
Om du vill aktivera DNN för ett AutoML-experiment som skapats i Azure Machine Learning-studio läser du inställningarna för aktivitetstyp i studiogränssnittet.
Aggregering av rullande målfönster
Ofta är den bästa informationen för en prognosmakare det senaste värdet för målet. Med målsammansättningar för rullande fönster kan du lägga till en löpande aggregering av datavärden som funktioner. Att generera och använda dessa funktioner som extra kontextuella data hjälper till med precisionen i träningsmodellen.
Anta till exempel att du vill förutsäga energiefterfrågan. Du kanske vill lägga till en funktion för rullande fönster på tre dagar för att ta hänsyn till värmeförändringar i uppvärmda utrymmen. I det här exemplet skapar du det här fönstret genom att ange target_rolling_window_size= 3 i AutoMLConfig konstruktorn.
Tabellen visar resulterande funktionsframställning som inträffar när fönsteraggregering tillämpas. Kolumner för minimum, maximum och sum genereras i ett skjutfönster med tre baserat på de definierade inställningarna. Varje rad har en ny beräknad funktion, för tidsstämpeln för den 8 september 2017 04:00 beräknas de högsta, lägsta och totala värdena med hjälp av efterfrågevärdena för 8 september 2017 01:00–03:00. Det här fönstret med tre skift för att fylla i data för de återstående raderna.

Visa ett Python-kodexempel som tillämpar den rullande målfönstrets mängdfunktion.
Kort seriehantering
Automatiserad ML betraktar en tidsserie som en kort serie om det inte finns tillräckligt med datapunkter för att genomföra tränings- och valideringsfaserna för modellutveckling. Antalet datapunkter varierar för varje experiment och beror på max_horizon, antalet korsvalideringsdelningar och längden på modellåtersökningen, vilket är det maximala antal historik som behövs för att skapa tidsseriefunktionerna.
Automatiserad ML erbjuder kort seriehantering som standard med parametern short_series_handling_configuration i ForecastingParameters objektet.
För att aktivera kortseriehantering måste parametern freq också definieras. Om du vill definiera en timfrekvens anger freq='H'vi . Visa alternativen för frekvenssträngen genom att gå till avsnittet DataOffset-objekt på pandas-tidsseriesidan. Om du vill ändra standardbeteendet short_series_handling_configuration = 'auto'uppdaterar du parametern short_series_handling_configuration i objektet ForecastingParameter .
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
I följande tabell sammanfattas de tillgängliga inställningarna för short_series_handling_config.
| Inställning | beskrivning |
|---|---|
auto |
Standardvärdet för kort seriehantering. - Om alla serier är korta kan du fylla på data. - Om inte alla serier är korta släpper du den korta serien. |
pad |
Om short_series_handling_config = padlägger automatiserad ML till slumpmässiga värden till varje kort serie som hittas. Följande listar kolumntyperna och vad de är vadderade med: - Objektkolumner med NaN – Numeriska kolumner med 0 – Booleska/logiska kolumner med false - Målkolumnen är vadderad med slumpmässiga värden med medelvärdet noll och standardavvikelsen 1. |
drop |
Om short_series_handling_config = drop, tar automatiserad ML bort den korta serien och den kommer inte att användas för träning eller förutsägelse. Förutsägelser för dessa serier returnerar NaN:er. |
None |
Ingen serie är vadderad eller tappad |
Varning
Utfyllnad kan påverka den resulterande modellens noggrannhet, eftersom vi introducerar artificiella data bara för att komma förbi träningen utan fel. Om många av serierna är korta kan du också se en viss inverkan på förklaringsresultaten
Identifiering och hantering av icke-stationära tidsserier
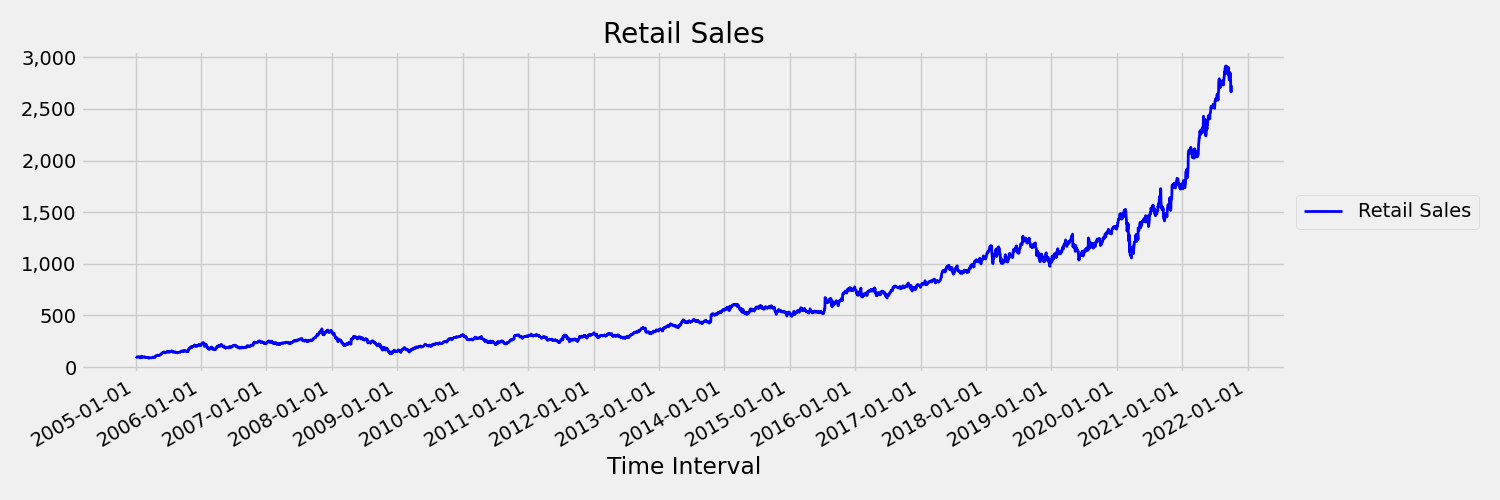
En tidsserie vars ögonblick (medelvärde och varians) ändras över tid kallas för icke-stationära. Till exempel är tidsserier som uppvisar stokastiska trender icke-stationära av naturen. För att visualisera detta ritar bilden nedan en serie som vanligtvis trendar uppåt. Beräkna och jämför nu medelvärdet (medelvärdet) för den första och andra halvan av serien. Är de likadana? Här är medelvärdet av serien under den första halvan av diagrammet mindre än i andra halvlek. Det faktum att medelvärdet för serien beror på tidsintervallet man tittar på är ett exempel på de tidsberoende ögonblicken. Här är medelvärdet av en serie det första ögonblicket.
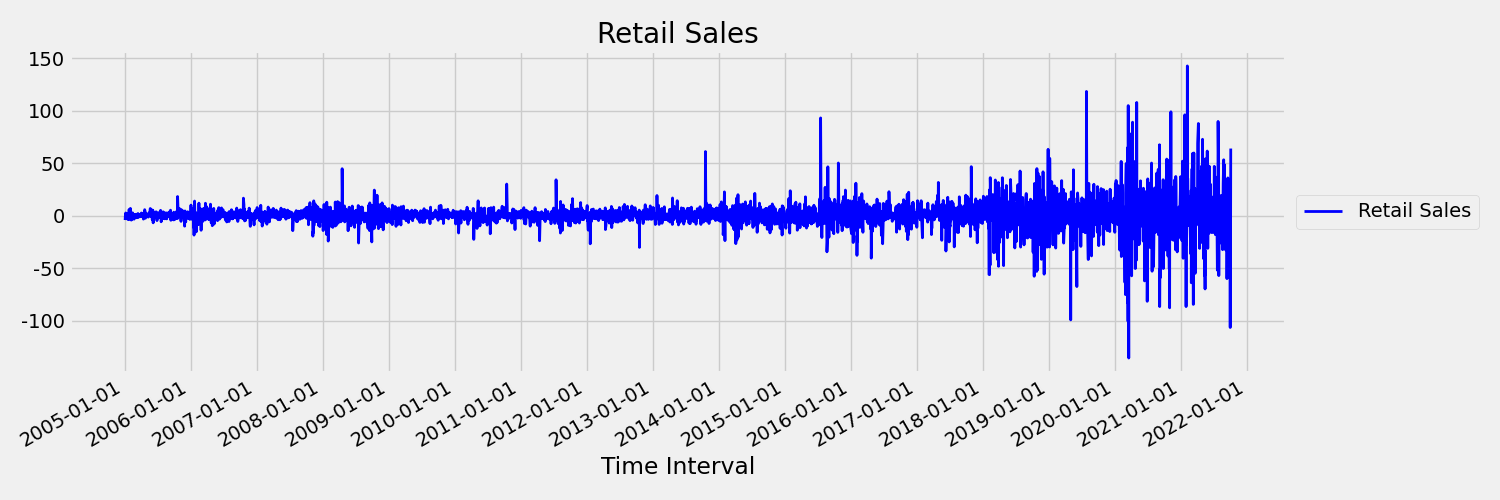
Nu ska vi undersöka bilden, som ritar den ursprungliga serien i första skillnaderna, $x_t = y_t – y_{t-1}$ där $x_t$ är ändringen i detaljhandelsförsäljning och $y_t$ och $y_{t-1}$ representerar den ursprungliga serien respektive dess första fördröjning. Medelvärdet för serien är ungefär konstant oavsett vilken tidsram man tittar på. Detta är ett exempel på en första ordningens stationära tidsserie. Anledningen till att vi lade till den första ordertermen är att det första ögonblicket (medelvärdet) inte ändras med tidsintervallet, detsamma kan inte sägas om variansen, vilket är ett andra ögonblick.
AutoML Machine Learning-modeller kan inte hantera stokastiska trender eller andra välkända problem som är associerade med icke-stationära tidsserier. Därför är deras out-of-sample prognosnoggrannhet "dålig" om sådana trender finns.
AutoML analyserar automatiskt tidsseriedatauppsättningen för att kontrollera om den är stationär eller inte. När icke-stationära tidsserier identifieras tillämpar AutoML automatiskt en differentieringstransformering för att minimera effekten av icke-stationära tidsserier.
Kör experimentet
När du har ditt AutoMLConfig objekt klart kan du skicka experimentet. När modellen är klar hämtar du iterationen för bästa körning.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Prognostisering med bästa modell
Använd den bästa modell-iterationen för att prognostisera värden för data som inte användes för att träna modellen.
Utvärdera modellens noggrannhet med en löpande prognos
Innan du sätter en modell i produktion bör du utvärdera dess noggrannhet på en testuppsättning som hålls ut från träningsdata. En metod för bästa praxis är en så kallad rullande utvärdering som rullar den tränade prognosmakaren framåt i tiden över testuppsättningen, med medelvärde av felmått över flera förutsägelsefönster för att få statistiskt robusta uppskattningar för vissa valda mått. Helst är testuppsättningen för utvärderingen lång i förhållande till modellens prognoshorisont. Uppskattningar av prognosfel kan annars vara statistiskt bullriga och därför mindre tillförlitliga.
Anta till exempel att du tränar en modell för daglig försäljning för att förutsäga efterfrågan upp till två veckor (14 dagar) in i framtiden. Om det finns tillräckligt med historiska data kan du reservera de sista månaderna till och med ett år med data för testuppsättningen. Den rullande utvärderingen börjar med att generera en prognos på 14 dagar i förväg för testuppsättningens två första veckor. Sedan avanceras prognosmakaren med ett antal dagar till testuppsättningen och du genererar ytterligare en prognos på 14 dagar i förväg från den nya positionen. Processen fortsätter tills du kommer till slutet av testuppsättningen.
Om du vill göra en löpande utvärdering anropar rolling_forecast du metoden för fitted_modeloch beräknar sedan önskade mått för resultatet. Anta till exempel att du har testuppsättningsfunktioner i en Pandas DataFrame-anropad test_features_df och att testet anger faktiska värden för målet i en numpy-matris med namnet test_target. En löpande utvärdering med hjälp av det genomsnittliga kvadratfelet visas i följande kodexempel:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
I det här exemplet är stegstorleken för den rullande prognosen inställd på en, vilket innebär att prognosmakaren är avancerad en period eller en dag i vårt exempel på förutsägelse av efterfrågan vid varje iteration. Det totala antalet prognoser som returneras av rolling_forecast beror på längden på testuppsättningen och den här stegstorleken. Mer information och exempel finns i dokumentationen rolling_forecast() och notebook-filen Forecasting away from training data (Prognostisering bort från träningsdata).
Förutsägelse in i framtiden
Funktionen forecast_quantiles() tillåter specifikationer för när förutsägelser ska starta, till skillnad från predict() metoden, som vanligtvis används för klassificerings- och regressionsaktiviteter. Metoden forecast_quantiles() genererar som standard en punktprognos eller en medelvärde/medianprognos, som inte har en kon av osäkerhet runt sig. Läs mer i notebook-filen Forecasting away from training data (Prognostisering bort från anteckningsboken för träningsdata).
I följande exempel ersätter du först alla värden i y_pred med NaN. Prognosens ursprung ligger i slutet av träningsdata i det här fallet. Men om du bara ersatte den andra halvan av y_pred med NaNskulle funktionen lämna de numeriska värdena i den första halvan oförändrade, men prognostisera NaN värdena i den andra halvan. Funktionen returnerar både de prognostiserade värdena och de justerade funktionerna.
Du kan också använda parametern forecast_destinationforecast_quantiles() i funktionen för att prognostisera värden upp till ett angivet datum.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Ofta vill kunderna förstå förutsägelserna i en specifik kvantil av fördelningen. Till exempel när prognosen används för att kontrollera inventering som matvaror eller virtuella datorer för en molntjänst. I sådana fall är kontrollpunkten vanligtvis något i stil med "vi vill att objektet ska finnas i lager och inte ta slut 99 % av tiden". Följande visar hur du anger vilka quantiles du vill se för dina förutsägelser, till exempel den 50:e eller 95:e percentilen. Om du inte anger någon kvantil, som i det ovan nämnda kodexemplet, genereras endast de 50:e percentilförutsägelserna.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Du kan beräkna modellmått som RMSE (Root Mean Squared Error) eller MAPE (Mean Absolute Percentage Error) för att beräkna modellernas prestanda. Ett exempel finns i avsnittet Utvärdera i notebook-filen för cykelresursefterfrågan.
När den övergripande modellnoggrannheten har fastställts är det mest realistiska nästa steg att använda modellen för att förutsäga okända framtida värden.
Ange en datauppsättning i samma format som testuppsättningen test_dataset , men med framtida datetimes, och den resulterande förutsägelseuppsättningen är de prognostiserade värdena för varje steg i tidsserier. Anta att de senaste tidsserieposterna i datauppsättningen var för 2018-03-12. Om du vill prognostisera efterfrågan för nästa dag (eller så många perioder som du behöver prognostisera, <= forecast_horizon), skapar du en enda tidsseriepost för varje butik för 2019-01-01.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Upprepa de steg som krävs för att läsa in framtida data till en dataram och kör best_run.forecast_quantiles(test_dataset) sedan för att förutsäga framtida värden.
Kommentar
Förutsägelser i exemplet stöds inte för prognostisering med automatiserad ML när target_lags och/eller target_rolling_window_size är aktiverade.
Prognostisering i stor skala
Det finns scenarier där en enskild maskininlärningsmodell är otillräcklig och flera maskininlärningsmodeller behövs. Du kan till exempel förutsäga försäljningen för varje enskild butik för ett varumärke eller skräddarsy en upplevelse för enskilda användare. Att skapa en modell för varje instans kan leda till bättre resultat på många maskininlärningsproblem.
Gruppering är ett begrepp i tidsserieprognoser som gör att tidsserier kan kombineras för att träna en enskild modell per grupp. Den här metoden kan vara särskilt användbar om du har tidsserier som kräver utjämning, fyllning eller entiteter i gruppen som kan dra nytta av historik eller trender från andra entiteter. Många modeller och hierarkisk tidsserieprognoser är lösningar som drivs av automatiserad maskininlärning för dessa storskaliga prognosscenarier.
Många modeller
Med Azure Machine Learning många modeller med automatiserad maskininlärning kan användarna träna och hantera miljontals modeller parallellt. Många modeller Lösningsacceleratorn använder Azure Machine Learning-pipelines för att träna modellen. Mer specifikt används ett Pipeline-objekt och ParalleRunStep och kräver specifika konfigurationsparametrar som anges via ParallelRunConfig.
Följande diagram visar arbetsflödet för lösningen med många modeller.

Följande kod visar de nyckelparametrar som användarna behöver för att konfigurera sina många modeller. Mer information om prognostiseringsexempel för många modeller finns i Den automatiserade ML-notebook-filen
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Prognostisering för hierarkisk tidsserie
I de flesta program behöver kunderna förstå sina prognoser på makro- och mikronivå i verksamheten. Forcasts kan förutsäga försäljning av produkter på olika geografiska platser eller förstå den förväntade efterfrågan på personal för olika organisationer på ett företag. Det är viktigt att du kan träna en maskininlärningsmodell för att på ett intelligent sätt prognostisera hierarkidata.
En hierarkisk tidsserie är en struktur där var och en av de unika serierna är ordnade i en hierarki baserat på dimensioner som geografi eller produkttyp. I följande exempel visas data med unika attribut som utgör en hierarki. Vår hierarki definieras av: produkttypen, till exempel hörlurar eller surfplattor, produktkategorin, som delar upp produkttyper i tillbehör och enheter och den region som produkterna säljs i.

För att ytterligare visualisera detta innehåller lövnivåerna i hierarkin alla tidsserier med unika kombinationer av attributvärden. Varje högre nivå i hierarkin tar hänsyn till en mindre dimension för att definiera tidsserierna och aggregerar varje uppsättning underordnade noder från den lägre nivån till en överordnad nod.

Den hierarkiska tidsserielösningen bygger på lösningen Många modeller och delar en liknande konfigurationskonfiguration.
Följande kod visar nyckelparametrarna för att konfigurera dina hierarkiska tidsserieprognoskörningar. Se Hierarkisk tidsserie – Automatiserad ML-notebook-fil för ett exempel från slutpunkt till slutpunkt.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Exempelnotebook-filer
Notebook-filerna med prognosexempel innehåller detaljerade kodexempel för avancerad konfiguration av prognostisering, inklusive:
- funktionalisering och identifiering av helgdagar
- korsvalidering för rullande ursprung
- konfigurerbara förskjutningar
- aggregeringsfunktioner för rullande fönster
Nästa steg
- Läs mer om hur du distribuerar en AutoML-modell till en onlineslutpunkt.
- Lär dig mer om tolkning: modellförklaringar i automatiserad maskininlärning (förhandsversion).
- Lär dig mer om hur AutoML bygger prognosmodeller.