Konfigurera AutoML för att träna modeller för visuellt innehåll med Python (v1)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Viktigt!
Några av Azure CLI-kommandona i den här artikeln använder azure-cli-mltillägget , eller v1, för Azure Machine Learning. Stödet för v1-tillägget upphör den 30 september 2025. Du kommer att kunna installera och använda v1-tillägget fram till det datumet.
Vi rekommenderar att du övergår till mltillägget , eller v2, före den 30 september 2025. Mer information om v2-tillägget finns i Azure ML CLI-tillägget och Python SDK v2.
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
I den här artikeln får du lära dig hur du tränar modeller för visuellt innehåll på bilddata med automatiserad ML i Azure Machine Learning Python SDK.
AutoML har stöd för modellträning för uppgifter med datorseende som bildklassificering, objektidentifiering och instanssegmentering. Du kan för närvarande redigera AutoML-modeller för uppgifter med datorseende via Azure Machine Learning Python SDK. Resulterande experimentkörningar, modeller och utdata är tillgängliga från Azure Machine Learning-studio användargränssnittet. Läs mer om automatiserad ml för uppgifter om visuellt innehåll på bilddata.
Kommentar
Automatiserad ML för uppgifter med visuellt innehåll är endast tillgängligt via Azure Machine Learning Python SDK.
Förutsättningar
En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
Azure Machine Learning Python SDK installerat. Om du vill installera SDK:et kan du antingen
Skapa en beräkningsinstans som automatiskt installerar SDK och är förkonfigurerad för ML-arbetsflöden. Mer information finns i Skapa och hantera en Azure Machine Learning-beräkningsinstans.
automlInstallera paketet själv, vilket inkluderar standardinstallationen av SDK: et.
Kommentar
Endast Python 3.7 och 3.8 är kompatibla med automatiserat ML-stöd för uppgifter med visuellt innehåll.
Välj aktivitetstyp
Automatiserad ML för avbildningar stöder följande uppgiftstyper:
| Uppgiftstyp | AutoMLImage-konfigurationssyntax |
|---|---|
| bildklassificering | ImageTask.IMAGE_CLASSIFICATION |
| multietikett för bildklassificering | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| identifiering av bildobjekt | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentering av bildinstans | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Den här aktivitetstypen är en obligatorisk parameter och skickas med parametern task AutoMLImageConfigi .
Till exempel:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Tränings- och valideringsdata
För att generera modeller för visuellt innehåll måste du ta med märkta bilddata som indata för modellträning i form av en Azure Machine Learning TabularDataset. Du kan antingen använda en TabularDataset som du har exporterat från ett dataetikettprojekt eller skapa en ny TabularDataset med dina märkta träningsdata.
Om dina träningsdata har ett annat format (t.ex. pascal VOC eller COCO) kan du använda hjälpskripten som ingår i exempelanteckningsböckerna för att konvertera data till JSONL. Läs mer om hur du förbereder data för uppgifter med visuellt innehåll med automatiserad ML.
Varning
Skapande av TabularDatasets från data i JSONL-format stöds endast med hjälp av SDK för den här funktionen. Det går inte att skapa datamängden via användargränssnittet just nu. Från och med nu känner användargränssnittet inte igen StreamInfo-datatypen, som är den datatyp som används för bild-URL:er i JSONL-format.
Kommentar
Träningsdatauppsättningen måste ha minst 10 bilder för att kunna skicka en AutoML-körning.
JSONL-schemaexempel
Strukturen för TabularDataset beror på vilken uppgift som finns. För aktivitetstyper för visuellt innehåll består den av följande fält:
| Fält | beskrivning |
|---|---|
image_url |
Innehåller filepath som ett StreamInfo-objekt |
image_details |
Informationen om bildmetadata består av höjd, bredd och format. Det här fältet är valfritt och kan därför inte finnas. |
label |
En json-representation av bildetiketten baserat på aktivitetstypen. |
Följande är en JSONL-exempelfil för bildklassificering:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Följande kod är en JSONL-exempelfil för objektidentifiering:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Använda data
När dina data är i JSONL-format kan du skapa en TabularDataset med följande kod:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Automatiserad ML medför inga begränsningar för tränings- eller valideringsdatastorleken för uppgifter med visuellt innehåll. Maximal datamängdsstorlek begränsas endast av lagringslagret bakom datamängden (dvs. bloblager). Det finns inget minsta antal bilder eller etiketter. Vi rekommenderar dock att du börjar med minst 10–15 exempel per etikett för att säkerställa att utdatamodellen är tillräckligt tränad. Ju högre det totala antalet etiketter/klasser, desto fler exempel behöver du per etikett.
Träningsdata krävs och skickas med hjälp av parametern training_data . Du kan också ange en annan TabularDataset som en valideringsdatauppsättning som ska användas för din modell med parametern validation_data autoMLImageConfig. Om ingen valideringsdatauppsättning har angetts används 20 % av dina träningsdata som standard för validering, såvida du inte skickar validation_size argument med ett annat värde.
Till exempel:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Beräkning för att köra experiment
Ange ett beräkningsmål för automatiserad ML för att genomföra modellträning. Automatiserade ML-modeller för uppgifter med visuellt innehåll kräver GPU-SKU:er och stöd för NC- och ND-familjer. Vi rekommenderar NCsv3-serien (med v100 GPU:er) för snabbare träning. Ett beräkningsmål med en vm-SKU för flera GPU:er utnyttjar flera GPU:er för att också påskynda träningen. När du konfigurerar ett beräkningsmål med flera noder kan du dessutom utföra snabbare modellträning genom parallellitet när du justerar hyperparametrar för din modell.
Kommentar
Om du använder en beräkningsinstans som beräkningsmål kontrollerar du att flera AutoML-jobb inte körs samtidigt. Kontrollera också att är max_concurrent_iterations inställt på 1 i experimentresurserna.
Beräkningsmålet är en obligatorisk parameter och skickas in med parametern compute_target AutoMLImageConfigför . Till exempel:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Konfigurera modellalgoritmer och hyperparametrar
Med stöd för uppgifter för visuellt innehåll kan du styra modellalgoritmen och sopa hyperparametrar. Dessa modellalgoritmer och hyperparametrar skickas som parameterutrymme för svepet.
Modellalgoritmen krävs och skickas via model_name parameter. Du kan antingen ange en enskild model_name eller välja mellan flera.
Modellalgoritmer som stöds
I följande tabell sammanfattas de modeller som stöds för varje uppgift för visuellt innehåll.
| Uppgift | Modellalgoritmer | Strängliteral syntaxdefault_model* anges med * |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) |
MobileNet: Lättviktade modeller för mobila program ResNet: Residualnätverk ResNeSt: Dela upp uppmärksamhetsnätverk SE-ResNeXt50: Squeeze-and-Excitation-nätverk ViT: Vision transformeringsnätverk |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (liten) vitb16r224* (bas) vitl16r224 (stor) |
| Objektidentifiering | YOLOv5: Objektidentifieringsmodell i ett steg Snabbare RCNN ResNet FPN: Tvåstegsobjektidentifieringsmodeller RetinaNet ResNet FPN: åtgärda obalans i klassen med brännpunktsförlust Obs! Se model_size hyperparameter för YOLOv5-modellstorlekar. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Instanssegmentering | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Förutom att styra modellalgoritmen kan du även justera hyperparametrar som används för modellträning. Många av de hyperparametrar som exponeras är modellagnostiska, men det finns instanser där hyperparametrar är aktivitetsspecifika eller modellspecifika. Läs mer om tillgängliga hyperparametrar för dessa instanser.
Dataförstoring
I allmänhet kan prestanda för djupinlärningsmodeller ofta förbättras med mer data. Dataförstoring är en praktisk teknik för att förstärka datastorleken och variabiliteten för en datauppsättning som hjälper till att förhindra överanpassning och förbättra modellens generaliseringsförmåga för osedda data. Automatiserad ML tillämpar olika dataförstoringstekniker baserat på uppgiften visuellt innehåll innan indatabilder matas in till modellen. För närvarande finns det ingen exponerad hyperparameter för att kontrollera dataförstoringar.
| Uppgift | Datauppsättning som påverkas | Dataförstoringsteknik(er) tillämpas |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) | Träning Validering och test |
Slumpmässig storleksändring och beskärning, vågrät flip, färg jitter (ljusstyrka, kontrast, mättnad och nyans), normalisering med hjälp av kanalmässigt ImageNets medelvärde och standardavvikelse Ändra storlek, centrera beskärning, normalisering |
| Objektidentifiering, instanssegmentering | Träning Validering och test |
Slumpmässig beskärning runt avgränsningsrutor, expandera, vågrät flip, normalisering, ändra storlek Normalisering, ändra storlek |
| Objektidentifiering med yolov5 | Träning Validering och test |
Mosaik, slumpmässig affin (rotation, översättning, skala, sk shear), vågrät vänd Storleksändring för brevlåda |
Konfigurera dina experimentinställningar
Innan du gör ett stort svep för att söka efter de optimala modellerna och hyperparametrar rekommenderar vi att du provar standardvärdena för att få en första baslinje. Sedan kan du utforska flera hyperparametrar för samma modell innan du sveper över flera modeller och deras parametrar. På så sätt kan du använda en mer iterativ metod, eftersom med flera modeller och flera hyperparametrar för var och en växer sökutrymmet exponentiellt och du behöver fler iterationer för att hitta optimala konfigurationer.
Om du vill använda standardvärdena för hyperparameter för en viss algoritm (till exempel yolov5) kan du ange konfigurationen för autoML-avbildningen så här:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
När du har skapat en baslinjemodell kanske du vill optimera modellprestanda för att svepa över modellalgoritmen och hyperparameterutrymmet. Du kan använda följande exempelkonfiguration för att svepa över hyperparametrar för varje algoritm och välja mellan olika värden för learning_rate, optimerare, lr_scheduler osv. för att generera en modell med det optimala primära måttet. Om hyperparametervärden inte anges används standardvärdena för den angivna algoritmen.
Primärt mått
Det primära mått som används för modelloptimering och justering av hyperparametrar beror på aktivitetstypen. Det finns för närvarande inte stöd för att använda andra primära måttvärden.
accuracyför IMAGE_CLASSIFICATIONiouför IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionför IMAGE_OBJECT_DETECTIONmean_average_precisionför IMAGE_INSTANCE_SEGMENTATION
Experimentbudget
Du kan också ange den maximala tidsbudgeten för AutoML Vision-experimentet med – experiment_timeout_hours hur lång tid det tar timmar innan experimentet avslutas. Om ingen anges är standardtidsgränsen för experiment sju dagar (högst 60 dagar).
Svepande hyperparametrar för din modell
När modeller för visuellt innehåll tränas beror modellprestandan mycket på de värden för hyperparameter som valts. Ofta kanske du vill justera hyperparametrar för att få optimala prestanda. Med stöd för uppgifter för visuellt innehåll i automatiserad ML kan du sopa hyperparametrar för att hitta de optimala inställningarna för din modell. Den här funktionen använder funktionerna för hyperparameterjustering i Azure Machine Learning. Lär dig hur du finjusterar hyperparametrar.
Definiera parameterns sökutrymme
Du kan definiera modellalgoritmerna och hyperparametrar som ska sopa i parameterutrymmet.
- Se Konfigurera modellalgoritmer och hyperparametrar för listan över modellalgoritmer som stöds för varje aktivitetstyp.
- Se Hyperparametrar för hyperparametrar för dataseendeuppgifter för varje aktivitetstyp för visuellt innehåll.
- Se information om distributioner som stöds för diskreta och kontinuerliga hyperparametrar.
Provtagningsmetoder för svepet
När du sveper hyperparametrar måste du ange den samplingsmetod som ska användas för att svepa över det definierade parameterutrymmet. För närvarande stöds följande samplingsmetoder med parametern hyperparameter_sampling :
Kommentar
För närvarande stöder endast slumpmässig sampling och rutnätssampling villkorsstyrda hyperparameterutrymmen.
Principer för tidig uppsägning
Du kan automatiskt avsluta dåligt presterande körningar med en princip för tidig avslutning. Tidig avslutning förbättrar beräkningseffektiviteten och sparar beräkningsresurser som annars skulle ha spenderats på mindre lovande konfigurationer. Automatiserad ML för avbildningar stöder följande principer för tidig avslutning med hjälp av parametern early_termination_policy . Om ingen avslutningsprincip har angetts körs alla konfigurationer för att slutföras.
Läs mer om hur du konfigurerar principen för tidig avslutning för hyperparametersvepningen.
Resurser för svepet
Du kan styra de resurser som spenderas på hyperparametersvepningen iterations genom att ange och max_concurrent_iterations för svepet.
| Parameter | Detalj |
|---|---|
iterations |
Obligatorisk parameter för maximalt antal konfigurationer som ska rensas. Måste vara ett heltal mellan 1 och 1000. När du bara utforskar standardhyperparametrar för en viss modellalgoritm anger du den här parametern till 1. |
max_concurrent_iterations |
Maximalt antal körningar som kan köras samtidigt. Om det inte anges startas alla körningar parallellt. Om det anges måste det vara ett heltal mellan 1 och 100. Obs! Antalet samtidiga körningar är gated på de resurser som är tillgängliga i det angivna beräkningsmålet. Kontrollera att beräkningsmålet har tillgängliga resurser för önskad samtidighet. |
Kommentar
Ett fullständigt exempel på svepkonfiguration finns i den här självstudien.
Argument
Du kan skicka fasta inställningar eller parametrar som inte ändras under parameterutrymmessvepningen som argument. Argument skickas i namn/värde-par och namnet måste föregås av ett dubbelt bindestreck.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Inkrementell träning (valfritt)
När träningskörningen är klar kan du träna modellen ytterligare genom att läsa in den tränade modellkontrollpunkten. Du kan antingen använda samma datauppsättning eller en annan för inkrementell träning.
Det finns två tillgängliga alternativ för inkrementell träning. Du kan:
- Skicka det körnings-ID som du vill läsa in kontrollpunkten från.
- Skicka kontrollpunkterna via en FileDataset.
Skicka kontrollpunkten via körnings-ID
Om du vill hitta körnings-ID:t från den önskade modellen kan du använda följande kod.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Om du vill skicka en kontrollpunkt via körnings-ID:t måste du använda parametern checkpoint_run_id .
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Skicka kontrollpunkten via FileDataset
Om du vill skicka en kontrollpunkt via en FileDataset måste du använda parametrarna checkpoint_dataset_id och checkpoint_filename .
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Skicka körningen
När du har ditt AutoMLImageConfig objekt klart kan du skicka experimentet.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Utdata och utvärderingsmått
De automatiserade ML-träningskörningarna genererar utdatamodellfiler, utvärderingsmått, loggar och distributionsartefakter som bedömningsfilen och miljöfilen som kan visas från fliken utdata och loggar och mått i de underordnade körningarna.
Dricks
Kontrollera hur du navigerar till jobbresultatet från avsnittet Visa körningsresultat .
Definitioner och exempel på prestandadiagram och mått som tillhandahålls för varje körning finns i Utvärdera automatiserade maskininlärningsexperimentresultat
Registrera och distribuera modell
När körningen är klar kan du registrera den modell som skapades från den bästa körningen (konfiguration som resulterade i det bästa primära måttet)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
När du har registrerat den modell som du vill använda kan du distribuera den som en webbtjänst på Azure Container Instances (ACI) eller Azure Kubernetes Service (AKS). ACI är det perfekta alternativet för att testa distributioner, medan AKS passar bättre för storskalig produktionsanvändning.
Det här exemplet distribuerar modellen som en webbtjänst i AKS. Om du vill distribuera i AKS skapar du först ett AKS-beräkningskluster eller använder ett befintligt AKS-kluster. Du kan använda GPU- eller CPU VM-SKU:er för distributionsklustret.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Därefter kan du definiera inferenskonfigurationen som beskriver hur du konfigurerar webbtjänsten som innehåller din modell. Du kan använda bedömningsskriptet och miljön från träningskörningen i din slutsatsdragningskonfiguration.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Du kan sedan distribuera modellen som en AKS-webbtjänst.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Du kan också distribuera modellen från Azure Machine Learning-studio användargränssnittet. Gå till den modell som du vill distribuera på fliken Modeller i den automatiserade ML-körningen och välj Distribuera.
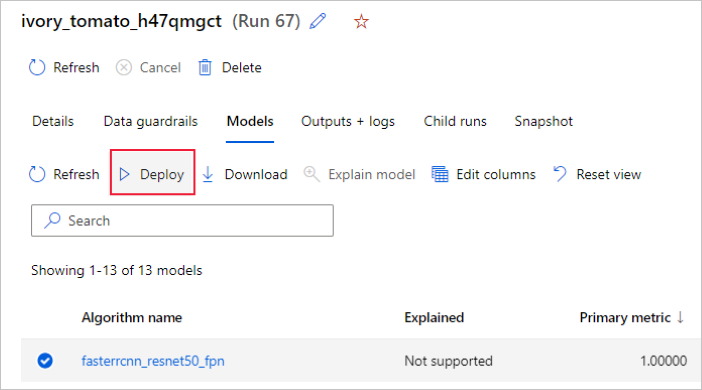
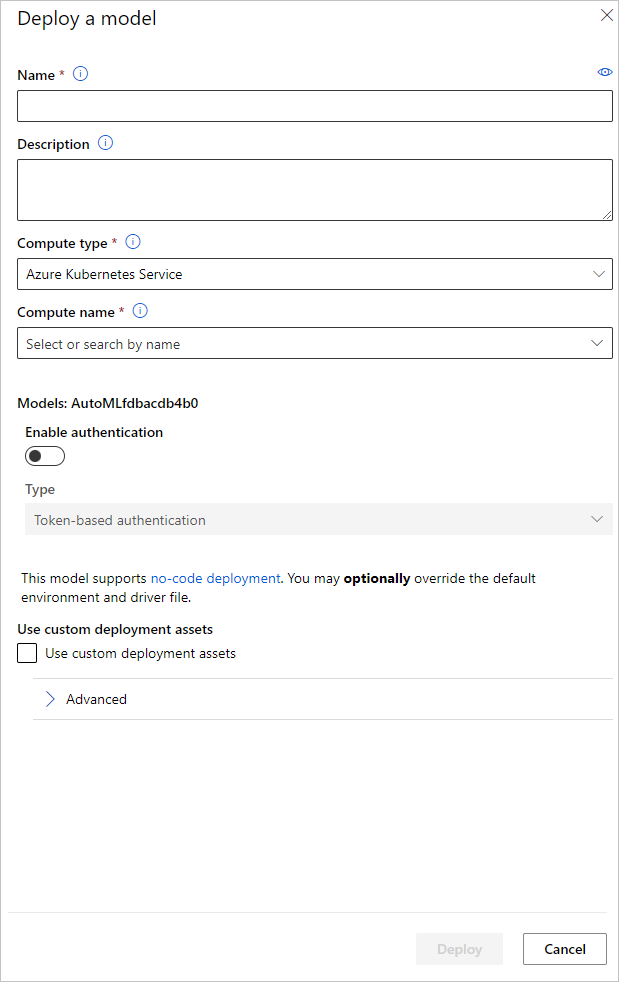
Du kan konfigurera namnet på modelldistributionens slutpunkt och det slutsatsdragningskluster som ska användas för modelldistributionen i fönstret Distribuera en modell .
Uppdatera inferenskonfiguration
I föregående steg laddade vi ned bedömningsfilen outputs/scoring_file_v_1_0_0.py från den bästa modellen till en lokal score.py fil och vi använde den för att skapa ett InferenceConfig objekt. Det här skriptet kan ändras för att ändra modellspecifika slutsatsdragningsinställningar om det behövs efter att det har laddats ned och innan du InferenceConfigskapar . Det här är till exempel kodavsnittet som initierar modellen i bedömningsfilen:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Var och en av uppgifterna (och vissa modeller) har en uppsättning parametrar i model_settings ordlistan. Som standard använder vi samma värden för de parametrar som användes under träningen och valideringen. Beroende på vilket beteende vi behöver när vi använder modellen för slutsatsdragning kan vi ändra dessa parametrar. Nedan hittar du en lista med parametrar för varje aktivitetstyp och modell.
| Uppgift | Parameternamn | Standardvärde |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) | valid_resize_sizevalid_crop_size |
256 224 |
| Objektidentifiering | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Objektidentifiering med hjälp av yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medel 0,1 0,5 |
| Instanssegmentering | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Falsk JPG |
En detaljerad beskrivning av uppgiftsspecifika hyperparametrar finns i Hyperparametrar för uppgifter för visuellt innehåll i automatiserad maskininlärning.
Om du vill använda tiling och vill styra plattsättningsbeteendet är följande parametrar tillgängliga: tile_grid_size, tile_overlap_ratio och tile_predictions_nms_thresh. Mer information om dessa parametrar finns i Träna en modell för identifiering av små objekt med AutoML.
Exempelnotebook-filer
Granska detaljerade kodexempel och användningsfall på GitHub-lagringsplatsen med automatiserade maskininlärningsexempel. Kontrollera mapparna med prefixet "image-" för exempel som är specifika för att skapa modeller för visuellt innehåll.