Så här distribuerar du cohere-kommandomodeller med Azure Mašinsko učenje studio
Cohere erbjuder två kommandomodeller i Azure Mašinsko učenje studio. Dessa modeller är tillgängliga som serverlösa API:er med tokenbaserad betalning per användning.
- Cohere Command R
- Cohere Command R+
Du kan bläddra i cohere-serien med modeller i modellkatalogen genom att filtrera på cohere-samlingen.
Modeller
I den här artikeln får du lära dig hur du använder Azure Mašinsko učenje studio för att distribuera cohere-kommandomodellerna som ett serverlöst API med betala per användning-fakturering.
Cohere Command R
Kommando R är en mycket högpresterande generativ stor språkmodell, optimerad för en mängd olika användningsfall, inklusive resonemang, sammanfattning och frågesvar.
Modellarkitektur: Det här är en autoregressiv språkmodell som använder en optimerad transformeringsarkitektur. Efter förträning använder den här modellen övervakad finjustering (SFT) och inställningsträning för att anpassa modellbeteendet till mänskliga preferenser för hjälp och säkerhet.
Språk som omfattas: Modellen är optimerad för att fungera bra på följande språk: engelska, franska, spanska, italienska, tyska, brasilianska portugisiska, japanska, koreanska, förenklad kinesiska och arabiska.
Förträningsdata omfattade dessutom följande 13 språk: ryska, polska, turkiska, vietnamesiska, nederländska, tjeckiska, indonesiska, ukrainska, rumänska, grekiska, hindi, hebreiska, persiska.
Kontextlängd: Kommando R stöder en kontextlängd på 128 K.
Indata: Modellerar endast indatatext.
Utdata: Modeller genererar endast text.
Cohere Command R+
Kommando R+ är en mycket högpresterande generativ stor språkmodell, optimerad för en mängd olika användningsfall, inklusive resonemang, sammanfattning och frågesvar.
Modellarkitektur: Det här är en autoregressiv språkmodell som använder en optimerad transformeringsarkitektur. Efter förträning använder den här modellen övervakad finjustering (SFT) och inställningsträning för att anpassa modellbeteendet till mänskliga preferenser för hjälp och säkerhet.
Språk som omfattas: Modellen är optimerad för att fungera bra på följande språk: engelska, franska, spanska, italienska, tyska, brasilianska portugisiska, japanska, koreanska, förenklad kinesiska och arabiska.
Förträningsdata omfattade dessutom följande 13 språk: ryska, polska, turkiska, vietnamesiska, nederländska, tjeckiska, indonesiska, ukrainska, rumänska, grekiska, hindi, hebreiska, persiska.
Kontextlängd: Kommando R+ stöder en kontextlängd på 128 K.
Indata: Modellerar endast indatatext.
Utdata: Modeller genererar endast text.
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Distribuera som ett serverlöst API
Vissa modeller i modellkatalogen kan distribueras som ett serverlöst API med betala per användning-fakturering. Den här distributionsmetoden är ett sätt att använda modeller som ett API utan att vara värd för dem i din prenumeration, samtidigt som företagssäkerhets- och efterlevnadsorganisationerna behöver det. Det här distributionsalternativet kräver inte kvot från din prenumeration.
De tidigare nämnda Cohere-modellerna kan distribueras som ett serverlöst API med betala per användning och erbjuds av Cohere via Microsoft Azure Marketplace. Cohere kan ändra eller uppdatera användningsvillkoren och prissättningen för den här modellen.
Förutsättningar
En Azure-prenumeration med en giltig betalningsmetod. Kostnadsfria azure-prenumerationer eller utvärderingsprenumerationer fungerar inte. Om du inte har en Azure-prenumeration skapar du ett betalt Azure-konto för att börja.
En Azure Machine Learning-arbetsyta. Om du inte har dessa använder du stegen i artikeln Snabbstart: Skapa arbetsyteresurser för att skapa dem. Det serverlösa API-modelldistributionserbjudandet för Cohere Command är endast tillgängligt med arbetsytor som skapats i dessa regioner:
- East US
- USA, östra 2
- USA, norra centrala
- USA, södra centrala
- USA, västra
- USA, västra 3
- Sverige, centrala
En lista över regioner som är tillgängliga för var och en av modellerna som stöder serverlösa API-slutpunktsdistributioner finns i Regiontillgänglighet för modeller i serverlösa API-slutpunkter.
Rollbaserade åtkomstkontroller i Azure (Azure RBAC) används för att bevilja åtkomst till åtgärder. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen Azure AI Developer i resursgruppen.
Mer information om behörigheter finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta.
Skapa en ny distribution
Så här skapar du en distribution:
Gå till Azure Mašinsko učenje Studio.
Välj den arbetsyta där du vill distribuera dina modeller. Om du vill använda det serverlösa API-distributionserbjudandet måste din arbetsyta tillhöra regionen EastUS2 eller Sverige, centrala.
Välj den modell som du vill distribuera från modellkatalogen.
Du kan också initiera distributionen genom att gå till din arbetsyta och välja Slutpunkter>Serverlösa slutpunkter>Skapa.
På modellens översiktssida i modellkatalogen väljer du Distribuera.
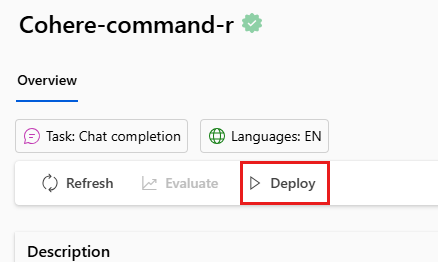
I distributionsguiden väljer du länken till Azure Marketplace-villkor för att lära dig mer om användningsvillkoren.
Du kan också välja fliken Information om Marketplace-erbjudande för att lära dig mer om priser för den valda modellen.
Om det här är första gången du distribuerar modellen på arbetsytan måste du prenumerera på din arbetsyta för modellens specifika erbjudande. Det här steget kräver att ditt konto har behörigheter för Azure AI Developer-rollen för resursgruppen enligt kraven. Varje arbetsyta har en egen prenumeration på det specifika Azure Marketplace-erbjudandet, vilket gör att du kan styra och övervaka utgifter. Välj Prenumerera och Distribuera. För närvarande kan du bara ha en distribution för varje modell på en arbetsyta.
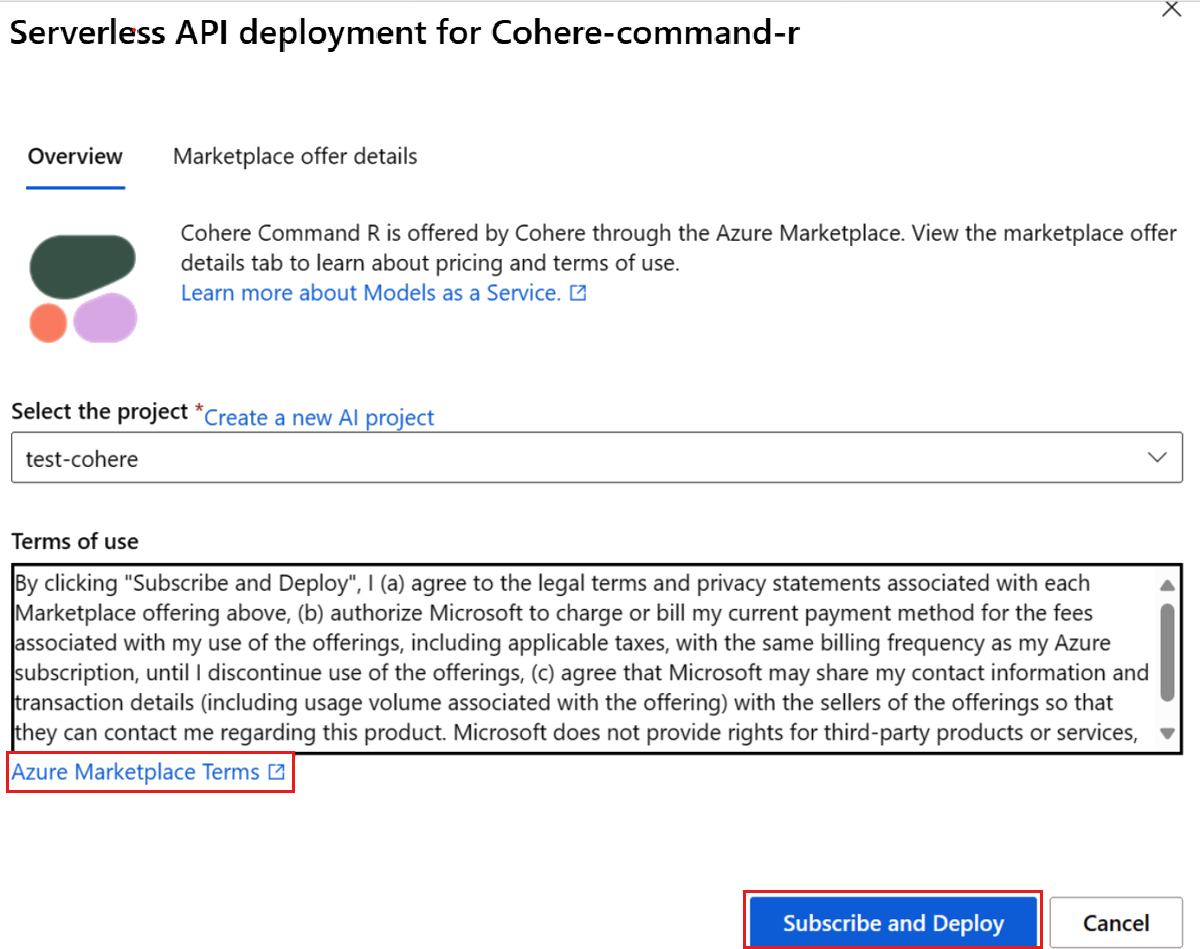
När du prenumererar på arbetsytan för det specifika Azure Marketplace-erbjudandet behöver efterföljande distributioner av samma erbjudande på samma arbetsyta inte prenumerera igen. Om det här scenariot gäller för dig finns det alternativet Fortsätt att distribuera för att välja.
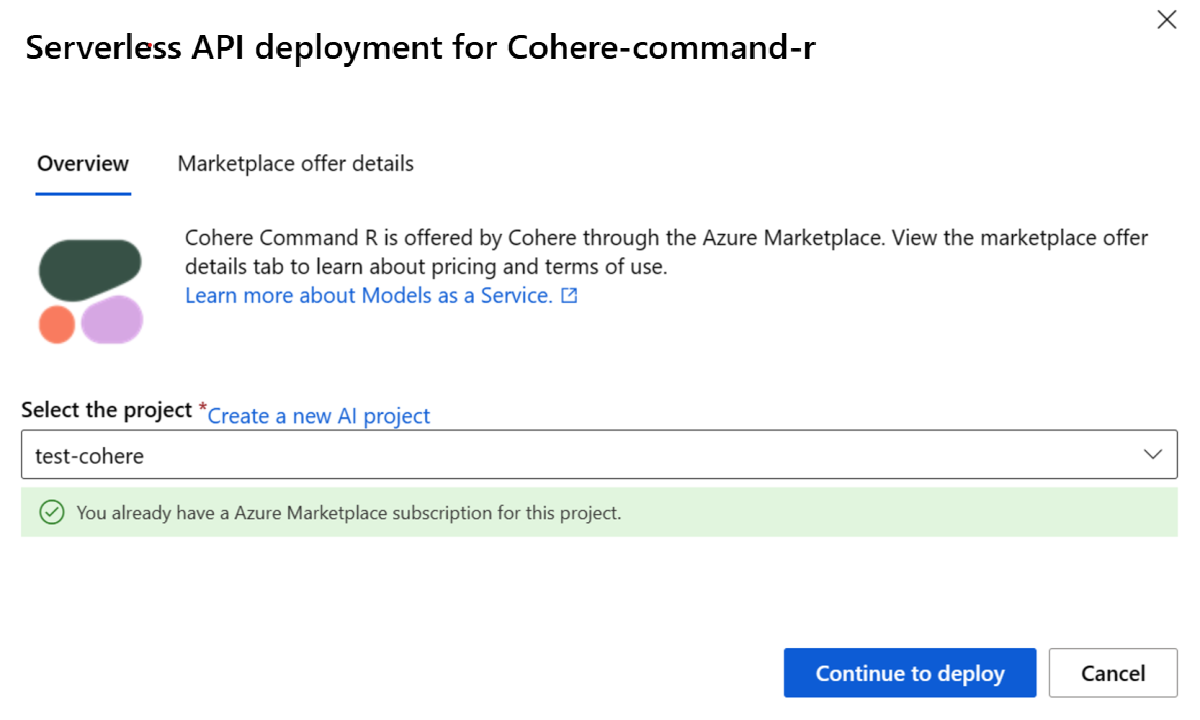
Ge distributionen ett namn. Det här namnet blir en del av URL:en för distributions-API:et. Den här URL:en måste vara unik i varje Azure-region.
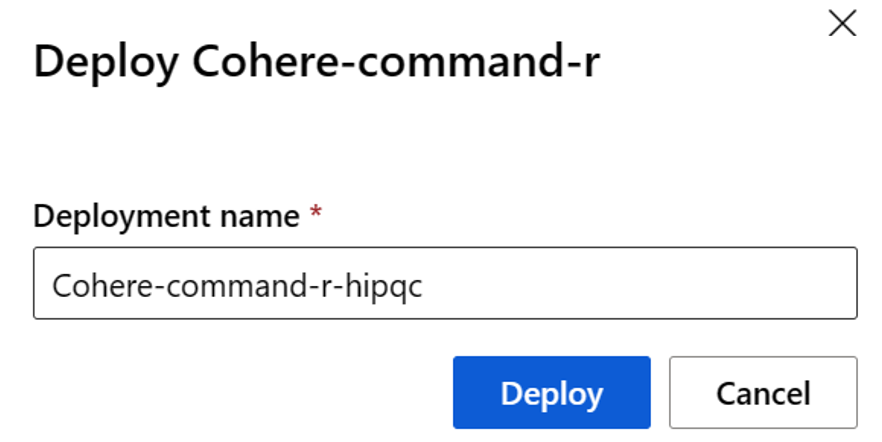
Välj distribuera. Vänta tills distributionen är klar och du omdirigeras till sidan serverlösa slutpunkter.
Välj slutpunkten för att öppna sidan Information.
Välj fliken Test för att börja interagera med modellen.
Du kan alltid hitta slutpunktens information, URL och åtkomstnycklar genom att navigera till Serverlösa slutpunkter för arbetsyteslutpunkter>>.
Anteckna mål-URL:en och den hemliga nyckeln. Mer information om hur du använder API:erna finns i referensavsnittet.




Mer information om fakturering för modeller som distribueras med betala per användning finns i Kostnads- och kvotöverväganden för cohere-modeller som distribueras som en tjänst.
Använda Cohere-modellerna som en tjänst
De tidigare nämnda Cohere-modellerna kan användas med hjälp av chatt-API:et.
- På arbetsytan väljer du Slutpunkter>Serverlösa slutpunkter.
- Leta upp och välj den distribution som du skapade.
- Kopiera mål-URL:en och nyckeltokensvärden.
- Cohere exponerar två vägar för slutsatsdragning med modellerna Command R och Command R+. Api:et för Azure AI-modellinferens på vägen
/chat/completionsoch det interna cohere-API:et.
Mer information om hur du använder API:erna finns i referensavsnittet.
Referens för cohere-modeller som distribuerats som ett serverlöst API
Cohere Command R- och Command R+-modeller accepterar både Azure AI Model Inference API på vägen /chat/completions och det interna Cohere Chat-API :et på /v1/chat.
API:et för Azure AI-modellslutsatsdragning
Schemat API för Azure AI Model Inference finns i artikeln referens för Chattslutföranden och en OpenAPI-specifikation kan hämtas från själva slutpunkten.
Cohere Chat API
Följande innehåller information om Cohere Chat API.
Förfrågan
POST /v1/chat HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
schema för v1/chattbegäran
Cohere Command R och Command R+ accepterar följande parametrar för ett v1/chat svarsinferensanrop:
| Nyckel | Typ | Standardvärde | beskrivning |
|---|---|---|---|
message |
string |
Obligatoriskt | Textinmatning som modellen ska svara på. |
chat_history |
array of messages |
None |
En lista över tidigare meddelanden mellan användaren och modellen, avsedd att ge modellen konversationskontext för att svara på användarens meddelande. |
documents |
array |
None |
En lista över relevanta dokument som modellen kan citera för att generera ett mer korrekt svar. Varje dokument är en strängsträngsordlista. Nycklar och värden från varje dokument serialiseras till en sträng och skickas till modellen. Den resulterande generationen innehåller citat som refererar till några av dessa dokument. Vissa föreslagna nycklar är "text", "författare" och "date". För bättre generationskvalitet behåller du det totala antalet ord för strängarna i ordlistan till under 300 ord. Ett _excludes fält (matris med strängar) kan eventuellt anges för att utelämna vissa nyckel/värde-par från att visas för modellen. De utelämnade fälten visas fortfarande i källhänvisningsobjektet. Fältet "_excludes" skickas inte till modellen. Se guide för dokumentläge från Cohere-dokument. |
search_queries_only |
boolean |
false |
När trueinnehåller svaret bara en lista över genererade sökfrågor, men ingen sökning sker, och inget svar från modellen till användaren genereras message . |
stream |
boolean |
false |
När trueär svaret en JSON-ström av händelser. Den sista händelsen innehåller det fullständiga svaret och har en event_type av "stream-end". Direktuppspelning är fördelaktigt för användargränssnitt som återger innehållet i svaret bit för bit när det genereras. |
max_tokens |
integer |
Ingen | Det maximala antalet token som modellen genererar som en del av svaret. Obs! Om du anger ett lågt värde kan det leda till ofullständiga generationer. Om det inte anges genererar tokens till slutet av sekvensen. |
temperature |
float |
0.3 |
Använd ett lägre värde för att minska slumpmässigheten i svaret. Slumpmässighet kan maximeras ytterligare genom att öka värdet för parametern p . Minsta värde är 0 och max 2. |
p |
float |
0.75 |
Använd ett lägre värde för att ignorera mindre sannolika alternativ. Ange till 0 eller 1.0 för att inaktivera. Om både p och k är aktiverade agerar p efter k. min-värdet 0,01, maxvärdet 0,99. |
k |
float |
0 |
Ange antalet tokenval som modellen använder för att generera nästa token. Om både p och k är aktiverade agerar p efter k. Minsta värde är 0, maxvärdet är 500. |
prompt_truncation |
enum string |
OFF |
AUTO_PRESERVE_ORDERAccepterar , AUTO, OFF. Avgör hur prompten skapas. Med prompt_truncation inställt på AUTO_PRESERVE_ORDER, släpps vissa element från chat_history och documents för att skapa en uppmaning som passar inom modellens kontextlängdsgräns. Under den här processen bevaras ordningen på dokumenten och chatthistoriken. Med prompt_truncation värdet "OFF" släpps inga element. |
stop_sequences |
array of strings |
None |
Den genererade texten klipps ut i slutet av den tidigaste förekomsten av en stoppsekvens. Sekvensen ingår i texten. |
frequency_penalty |
float |
0 |
Används för att minska repetitiviteten hos genererade token. Ju högre värde, desto starkare tillämpas en straffavgift för tidigare närvarande token, proportionellt mot hur många gånger de redan har dykt upp i prompten eller föregående generation. Minsta värde på 0,0, maxvärdet 1,0. |
presence_penalty |
float |
0 |
Används för att minska repetitiviteten hos genererade token. frequency_penaltyLiknar , förutom att den här påföljden tillämpas lika på alla token som redan har dykt upp, oavsett deras exakta frekvenser. Minsta värde på 0,0, maxvärdet 1,0. |
seed |
integer |
None |
Om det anges gör serverdelen ett bra försök att sampla token deterministiskt, så att upprepade begäranden med samma startvärde och parametrar ska returnera samma resultat. Determinism kan dock inte garanteras. |
return_prompt |
boolean |
false |
Returnerar den fullständiga prompten som skickades till modellen när true. |
tools |
array of objects |
None |
Fältet kan komma att ändras. En lista över tillgängliga verktyg (funktioner) som modellen kan föreslå att anropa innan du skapar ett textsvar. När tools skickas (utan tool_results) text fylls "" fältet i svaret och tool_calls fältet i svaret med en lista över verktygsanrop som måste göras. Om inga anrop behöver göras är matrisen tool_calls tom. |
tool_results |
array of objects |
None |
Fältet kan komma att ändras. En lista med resultat från att anropa verktyg som rekommenderas av modellen i föregående chattsväng. Resultaten används för att skapa ett textsvar och refereras i citationstecken. När du använder tool_resultstools , måste också skickas. Varje tool_result innehåller information om hur det anropades och en lista över utdata i form av ordlistor. Cohere unika detaljerade källhänvisningslogik kräver att utdata är en lista. Om utdata bara är ett objekt, till exempel , {"status": 200}omsluter du det fortfarande i en lista. |
Objektet chat_history kräver följande fält:
| Nyckel | Typ | Beskrivning |
|---|---|---|
role |
enum string |
Tar USER, SYSTEMeller CHATBOT. |
message |
string |
Textinnehåll i meddelandet. |
Objektet documents har följande valfria fält:
| Nyckel | Typ | Standardvärde | beskrivning |
|---|---|---|---|
id |
string |
None |
Kan anges för att identifiera dokumentet i citaten. Det här fältet skickas inte till modellen. |
_excludes |
array of strings |
None |
Du kan också ange att vissa nyckel/värde-par inte ska visas för modellen. De utelämnade fälten visas fortfarande i källhänvisningsobjektet. Fältet _excludes skickas inte till modellen. |
v1/chattsvarsschema
Svarsfälten är helt dokumenterade i Cohere:s chatt-API-referens. Svarsobjektet innehåller alltid:
| Nyckel | Typ | Beskrivning |
|---|---|---|
response_id |
string |
Unik identifierare för chattens slutförande. |
generation_id |
string |
Unik identifierare för chattens slutförande, som används med feedbackslutpunkten på Cohere-plattformen. |
text |
string |
Modellens svar på indata från chattmeddelanden. |
finish_reason |
enum string |
Varför generationen slutfördes. Kan vara något av följande värden: COMPLETE, ERROR, ERROR_TOXIC, ERROR_LIMITeller USER_CANCELMAX_TOKENS |
token_count |
integer |
Antal token som används. |
meta |
string |
API-användningsdata, inklusive aktuell version och fakturerbara token. |
Dokument
Om documents anges i begäran finns det två andra fält i svaret:
| Nyckel | Typ | Beskrivning |
|---|---|---|
documents |
array of objects |
Visar en lista över de dokument som angavs i svaret. |
citations |
array of objects |
Anger vilken del av svaret som hittades i ett visst dokument. |
citations är en matris med objekt med följande obligatoriska fält:
| Nyckel | Typ | Beskrivning |
|---|---|---|
start |
integer |
Indexet för text som källhänvisning börjar på och räknar från noll. Till exempel skulle en generation av Hello, world! med en källhänvisning på world ha ett startvärde på 7. Det beror på att citatet börjar vid w, vilket är det sjunde tecknet. |
end |
integer |
Indexet för text som källhänvisning slutar efter, räknar från noll. Till exempel skulle en generation av Hello, world! med en källhänvisning på world ha ett slutvärde på 11. Det beror på att citatet slutar efter d, vilket är det elfte tecknet. |
text |
string |
Texten i citatet. Till exempel skulle en generation av Hello, world! med en källhänvisning ha world ett textvärde på world. |
document_ids |
array of strings |
Identifierare för dokument som anges i det här avsnittet i det genererade svaret. |
Verktyg
Om tools anges och anropas av modellen finns det ett annat fält i svaret:
| Nyckel | Typ | Beskrivning |
|---|---|---|
tool_calls |
array of objects |
Innehåller de verktygsanrop som genereras av modellen. Använd den för att anropa dina verktyg. |
tool_calls är en matris med objekt med följande fält:
| Nyckel | Typ | Beskrivning |
|---|---|---|
name |
string |
Namnet på det verktyg som ska anropas. |
parameters |
object |
Namn och värde för de parametrar som ska användas när du anropar ett verktyg. |
Search_queries_only
Om search_queries_only=TRUE anges i begäran finns det två andra fält i svaret:
| Nyckel | Typ | Beskrivning |
|---|---|---|
is_search_required |
boolean |
Instruerar modellen att generera en sökfråga. |
search_queries |
array of objects |
Objekt som innehåller en lista över sökfrågor. |
search_queries är en matris med objekt med följande fält:
| Nyckel | Typ | Beskrivning |
|---|---|---|
text |
string |
Texten i sökfrågan. |
generation_id |
string |
Unik identifierare för den genererade sökfrågan. Användbart för att skicka feedback. |
Exempel
Chatt – slutföranden
Följande text är ett exempelbegäransanrop för att få chattavslut från cohere-kommandomodellen. Använd när du genererar ett chattavslut.
Begäran:
{
"chat_history": [
{"role":"USER", "message": "What is an interesting new role in AI if I don't have an ML background"},
{"role":"CHATBOT", "message": "You could explore being a prompt engineer!"}
],
"message": "What are some skills I should have"
}
Svar:
{
"response_id": "09613f65-c603-41e6-94b3-a7484571ac30",
"text": "Writing skills are very important for prompt engineering. Some other key skills are:\n- Creativity\n- Awareness of biases\n- Knowledge of how NLP models work\n- Debugging skills\n\nYou can also have some fun with it and try to create some interesting, innovative prompts to train an AI model that can then be used to create various applications.",
"generation_id": "6d31a57f-4d94-4b05-874d-36d0d78c9549",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 99,
"response_tokens": 70,
"total_tokens": 169,
"billed_tokens": 151
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 81,
"output_tokens": 70
}
}
}
Chatt – Grundad generation och RAG-funktioner
Kommando R och Kommando R+ tränas för RAG via en blandning av övervakad finjustering och finjustering av inställningar med hjälp av en specifik promptmall. Vi introducerar den promptmallen via parametern documents . Dokumentfragmenten ska vara segment i stället för långa dokument, vanligtvis cirka 100–400 ord per segment. Dokumentfragment består av nyckel/värde-par. Nycklarna ska vara korta beskrivande strängar. Värdena kan vara text eller halvstrukturerade.
Begäran:
{
"message": "Where do the tallest penguins live?",
"documents": [
{
"title": "Tall penguins",
"snippet": "Emperor penguins are the tallest."
},
{
"title": "Penguin habitats",
"snippet": "Emperor penguins only live in Antarctica."
}
]
}
Svar:
{
"response_id": "d7e72d2e-06c0-469f-8072-a3aa6bd2e3b2",
"text": "Emperor penguins are the tallest species of penguin and they live in Antarctica.",
"generation_id": "b5685d8d-00b4-48f1-b32f-baebabb563d8",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 615,
"response_tokens": 15,
"total_tokens": 630,
"billed_tokens": 22
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 7,
"output_tokens": 15
}
},
"citations": [
{
"start": 0,
"end": 16,
"text": "Emperor penguins",
"document_ids": [
"doc_0"
]
},
{
"start": 69,
"end": 80,
"text": "Antarctica.",
"document_ids": [
"doc_1"
]
}
],
"documents": [
{
"id": "doc_0",
"snippet": "Emperor penguins are the tallest.",
"title": "Tall penguins"
},
{
"id": "doc_1",
"snippet": "Emperor penguins only live in Antarctica.",
"title": "Penguin habitats"
}
]
}
Chatt – Verktygsanvändning
Om du anropar verktyg eller genererar ett svar baserat på verktygsresultat använder du följande parametrar.
Begäran:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Svar:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
När du har kört funktionen och tagit emot verktygsutdata kan du skicka tillbaka dem till modellen för att generera ett svar för användaren.
Begäran:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Svar:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
Chatt – Sökfrågor
Om du skapar en RAG-agent kan du också använda Cohere's Chat API för att hämta sökfrågor från Kommandot. Ange search_queries_only=TRUE i din begäran.
Begäran:
{
"message": "Which lego set has the greatest number of pieces?",
"search_queries_only": true
}
Svar:
{
"response_id": "5e795fe5-24b7-47b4-a8bc-b58a68c7c676",
"text": "",
"finish_reason": "COMPLETE",
"meta": {
"api_version": {
"version": "1"
}
},
"is_search_required": true,
"search_queries": [
{
"text": "lego set with most pieces",
"generation_id": "a086696b-ad8e-4d15-92e2-1c57a3526e1c"
}
]
}
Ytterligare slutsatsdragningsexempel
| Paket | Exempelnotebook |
|---|---|
| CLI med curl- och Python-webbbegäranden – Kommando R | command-r.ipynb |
| CLI med curl- och Python-webbbegäranden – Kommando R+ | command-r-plus.ipynb |
| OpenAI SDK (experimentell) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
Exempel på hämtning av utökad generation (RAG) och verktyg
| Beskrivning | Paket | Exempelnotebook |
|---|---|---|
| Skapa ett lokalt vektorindex för Facebook AI Similarity Search (FAISS) med hjälp av cohere-inbäddningar – Langchain | langchain, langchain_cohere |
cohere_faiss_langchain_embed.ipynb |
| Använd Cohere Command R/R+ för att besvara frågor från data i det lokala FAISS-vektorindexet – Langchain | langchain, langchain_cohere |
command_faiss_langchain.ipynb |
| Använd Cohere Command R/R+ för att besvara frågor från data i AI-sökvektorindex – Langchain | langchain, langchain_cohere |
cohere-aisearch-langchain-rag.ipynb |
| Använd Cohere Command R/R+ för att besvara frågor från data i AI-sökvektorindex – Cohere SDK | cohere, azure_search_documents |
cohere-aisearch-rag.ipynb |
| Kommando-R+-verktyg/funktionsanrop med LangChain | cohere, , langchainlangchain_cohere |
command_tools-langchain.ipynb |
Kostnad och kvoter
Kostnads- och kvotöverväganden för modeller som distribueras som en tjänst
Enhetliga modeller som distribueras som en tjänst erbjuds av Cohere via Azure Marketplace och integreras med Azure Machine Learning-studio för användning. Du hittar priser för Azure Marketplace när du distribuerar modellerna.
Varje gång en arbetsyta prenumererar på ett visst modellerbjudande från Azure Marketplace skapas en ny resurs för att spåra de kostnader som är kopplade till förbrukningen. Samma resurs används för att spåra kostnader som är associerade med slutsatsdragning. Flera mätare är dock tillgängliga för att spåra varje scenario oberoende av varandra.
Mer information om hur du spårar kostnader finns i Övervaka kostnader för modeller som erbjuds via Azure Marketplace.
Kvot hanteras per distribution. Varje distribution har en hastighetsgräns på 200 000 token per minut och 1 000 API-begäranden per minut. För närvarande begränsar vi dock en distribution per modell per arbetsyta. Kontakta Microsoft Azure Support om de aktuella hastighetsgränserna inte räcker för dina scenarier.
Innehållsfiltrering
Modeller som distribueras som en tjänst med betala per användning skyddas av Azure AI-innehållssäkerhet. Med Azure AI-innehållssäkerhet aktiverat passerar både prompten och slutförandet genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata. Läs mer om Azure AI Content Safety.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för