Publicera och spåra maskininlärningspipelines
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Den här artikeln visar hur du delar en maskininlärningspipeline med dina kollegor eller kunder.
Maskininlärningspipelines är återanvändbara arbetsflöden för maskininlärningsuppgifter. En fördel med pipelines är ökat samarbete. Du kan också versionspipelines så att kunderna kan använda den aktuella modellen medan du arbetar med en ny version.
Förutsättningar
Skapa en Azure Mašinsko učenje-arbetsyta för att lagra alla dina pipelineresurser
Konfigurera utvecklingsmiljön för att installera Azure Mašinsko učenje SDK eller använd en Azure Mašinsko učenje-beräkningsinstans med SDK:t redan installerat
Skapa och kör en maskininlärningspipeline, till exempel genom att följa Självstudie: Skapa en Azure-Mašinsko učenje pipeline för batchbedömning. Andra alternativ finns i Skapa och köra maskininlärningspipelines med Azure Mašinsko učenje SDK
Publicera en pipeline
När du har en pipeline igång kan du publicera en pipeline så att den körs med olika indata. För att REST-slutpunkten för en redan publicerad pipeline ska acceptera parametrar måste du konfigurera din pipeline så att den använder PipelineParameter objekt för de argument som varierar.
Om du vill skapa en pipelineparameter använder du ett PipelineParameter-objekt med ett standardvärde.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Lägg till det här
PipelineParameterobjektet som en parameter i något av stegen i pipelinen enligt följande:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publicera den här pipelinen som accepterar en parameter när den anropas.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")När du har publicerat din pipeline kan du kontrollera den i användargränssnittet. Pipeline-ID är det unika som identifierats för den publicerade pipelinen.


Köra en publicerad pipeline
Alla publicerade pipelines har en REST-slutpunkt. Med pipelineslutpunkten kan du utlösa en körning av pipelinen från alla externa system, inklusive icke-Python-klienter. Den här slutpunkten möjliggör "hanterad repeterbarhet" i scenarier för batchbedömning och omträning.
Viktigt!
Om du använder rollbaserad åtkomstkontroll i Azure (Azure RBAC) för att hantera åtkomst till din pipeline anger du behörigheterna för pipelinescenariot (träning eller bedömning).
Om du vill anropa körningen av den föregående pipelinen behöver du en Microsoft Entra-autentiseringshuvudtoken. Hämtar en sådan token beskrivs i klassreferensen för AzureCliAuthentication och i notebook-filen Autentisering i Azure Mašinsko učenje.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Argumentet json till POST-begäran måste för ParameterAssignments nyckeln innehålla en ordlista som innehåller pipelineparametrarna och deras värden. Dessutom json kan argumentet innehålla följande nycklar:
| Nyckel | beskrivning |
|---|---|
ExperimentName |
Namnet på experimentet som är associerat med den här slutpunkten |
Description |
Frihandstext som beskriver slutpunkten |
Tags |
Nyckel/värde-par i frihandsformat som kan användas för att märka och kommentera begäranden |
DataSetDefinitionValueAssignments |
Ordlista som används för att ändra datauppsättningar utan omträning (se diskussionen nedan) |
DataPathAssignments |
Ordlista som används för att ändra datavägar utan omträning (se diskussionen nedan) |
Köra en publicerad pipeline med C#
Följande kod visar hur du anropar en pipeline asynkront från C#. Det partiella kodfragmentet visar bara anropsstrukturen och ingår inte i ett Microsoft-exempel. Den visar inte fullständiga klasser eller felhantering.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Köra en publicerad pipeline med Java
Följande kod visar ett anrop till en pipeline som kräver autentisering (se Konfigurera autentisering för Azure Mašinsko učenje resurser och arbetsflöden). Om din pipeline distribueras offentligt behöver du inte de anrop som skapar authKey. Det partiella kodfragmentet visar inte Java-klass och undantagshanteringsplate. Koden används Optional.flatMap för sammanlänkning av funktioner som kan returnera en tom Optional. Användningen av flatMap förkortar och förtydligar koden, men observera att getRequestBody() sväljer undantag.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Ändra datauppsättningar och datavägar utan omträning
Du kanske vill träna och dra slutsatser om olika datauppsättningar och datavägar. Du kanske till exempel vill träna på en mindre datamängd men dra slutsatser om den fullständiga datamängden. Du växlar datauppsättningar med DataSetDefinitionValueAssignments nyckeln i begärans json argument. Du växlar datasökvägar med DataPathAssignments. Tekniken för båda är liknande:
I ditt pipelinedefinitionsskript skapar du en
PipelineParameterför datauppsättningen. Skapa enDatasetConsumptionConfigellerDataPathfrånPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)I ML-skriptet får du åtkomst till den dynamiskt angivna datamängden med hjälp av
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Observera att ML-skriptet kommer åt det angivna värdet för
DatasetConsumptionConfig(tabular_dataset) och inte värdet förPipelineParameter(tabular_ds_param).I skriptet för pipelinedefinition anger du
DatasetConsumptionConfigsom parameter tillPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Om du vill växla datauppsättningar dynamiskt i ditt slutsatsdragnings-REST-anrop använder du
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Notebook-filerna Showcasing Dataset och PipelineParameter och Showcasing DataPath och PipelineParameter har fullständiga exempel på den här tekniken.
Skapa en versionsslutpunkt för pipeline
Du kan skapa en pipelineslutpunkt med flera publicerade pipelines bakom. Den här tekniken ger dig en fast REST-slutpunkt när du itererar på och uppdaterar dina ML-pipelines.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Skicka ett jobb till en pipelineslutpunkt
Du kan skicka ett jobb till standardversionen av en pipelineslutpunkt:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Du kan också skicka ett jobb till en viss version:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Samma sak kan åstadkommas med hjälp av REST-API:et:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Använda publicerade pipelines i studion
Du kan också köra en publicerad pipeline från studion:
Logga in på Azure Mašinsko učenje Studio.
Välj Slutpunkter till vänster.
Längst upp väljer du Pipeline-slutpunkter.
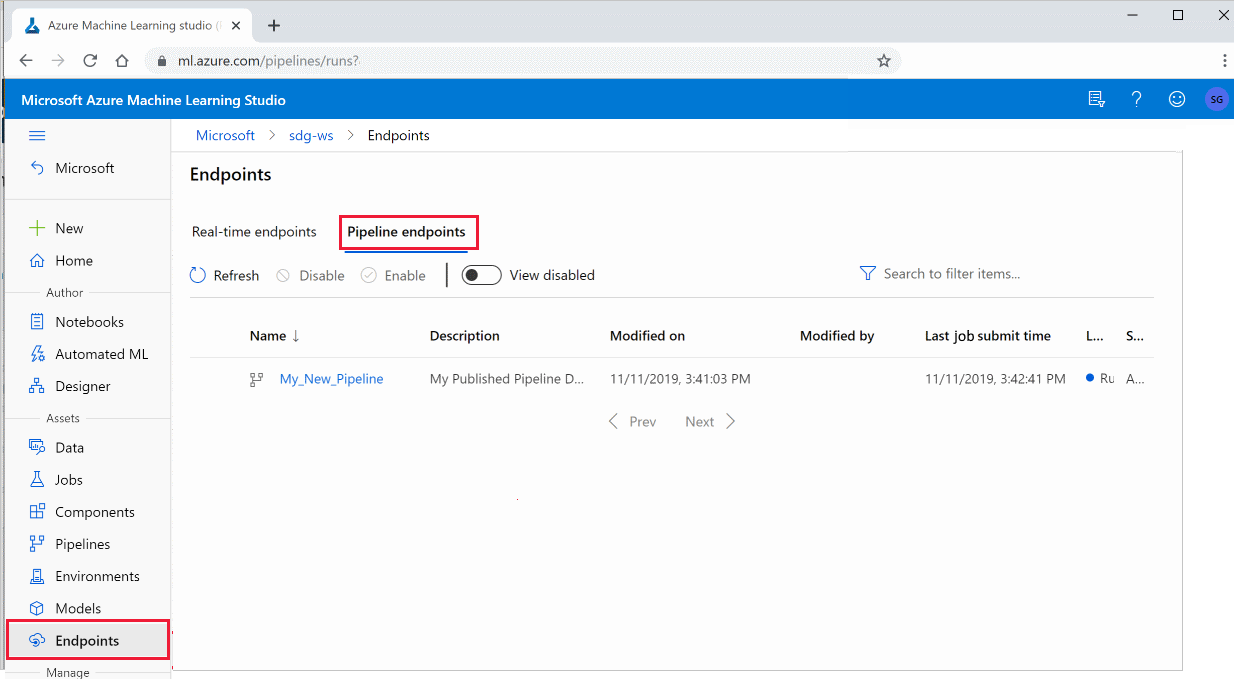
Välj en specifik pipeline för att köra, använda eller granska resultaten från tidigare körningar av pipelineslutpunkten.
Inaktivera en publicerad pipeline
Om du vill dölja en pipeline från listan över publicerade pipelines inaktiverar du den, antingen i studion eller från SDK:t:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Du kan aktivera den igen med p.enable(). Mer information finns i Klassreferens för PublishedPipeline .
Nästa steg
- Använd de här Jupyter-notebook-filerna på GitHub för att utforska maskininlärningspipelines ytterligare.
- Se SDK-referenshjälpen för paketet azureml-pipelines-core och paketet azureml-pipelines-steps .
- Se anvisningar för tips om felsökning och felsökning av pipelines.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för