I den här artikeln får du lära dig hur du använder Open Neural Network Exchange (ONNX) för att göra förutsägelser om modeller för visuellt innehåll som genererats från automatiserad maskininlärning (AutoML) i Azure Machine Learning.
Om du vill använda ONNX för förutsägelser måste du:
Ladda ned ONNX-modellfiler från en AutoML-träningskörning.
Förstå indata och utdata för en ONNX-modell.
Förbearbeta dina data så att de är i det format som krävs för indatabilder.
Utföra slutsatsdragning med ONNX Runtime för Python.
Visualisera förutsägelser för objektidentifiering och instanssegmenteringsuppgifter.
ONNX är en öppen standard för maskininlärning och djupinlärningsmodeller. Det möjliggör modellimport och export (samverkan) i de populära AI-ramverken. Mer information finns i ONNX GitHub-projektet.
ONNX Runtime är ett projekt med öppen källkod som stöder plattformsoberoende slutsatsdragning. ONNX Runtime tillhandahåller API:er för olika programmeringsspråk (inklusive Python, C++, C#, C, Java och JavaScript). Du kan använda dessa API:er för att utföra slutsatsdragning på indatabilder. När du har den modell som har exporterats till ONNX-format kan du använda dessa API:er på valfritt programmeringsspråk som ditt projekt behöver.
I den här guiden får du lära dig hur du använder Python-API:er för ONNX Runtime för att göra förutsägelser på bilder för populära visionsuppgifter. Du kan använda dessa ONNX-exporterade modeller på flera språk.
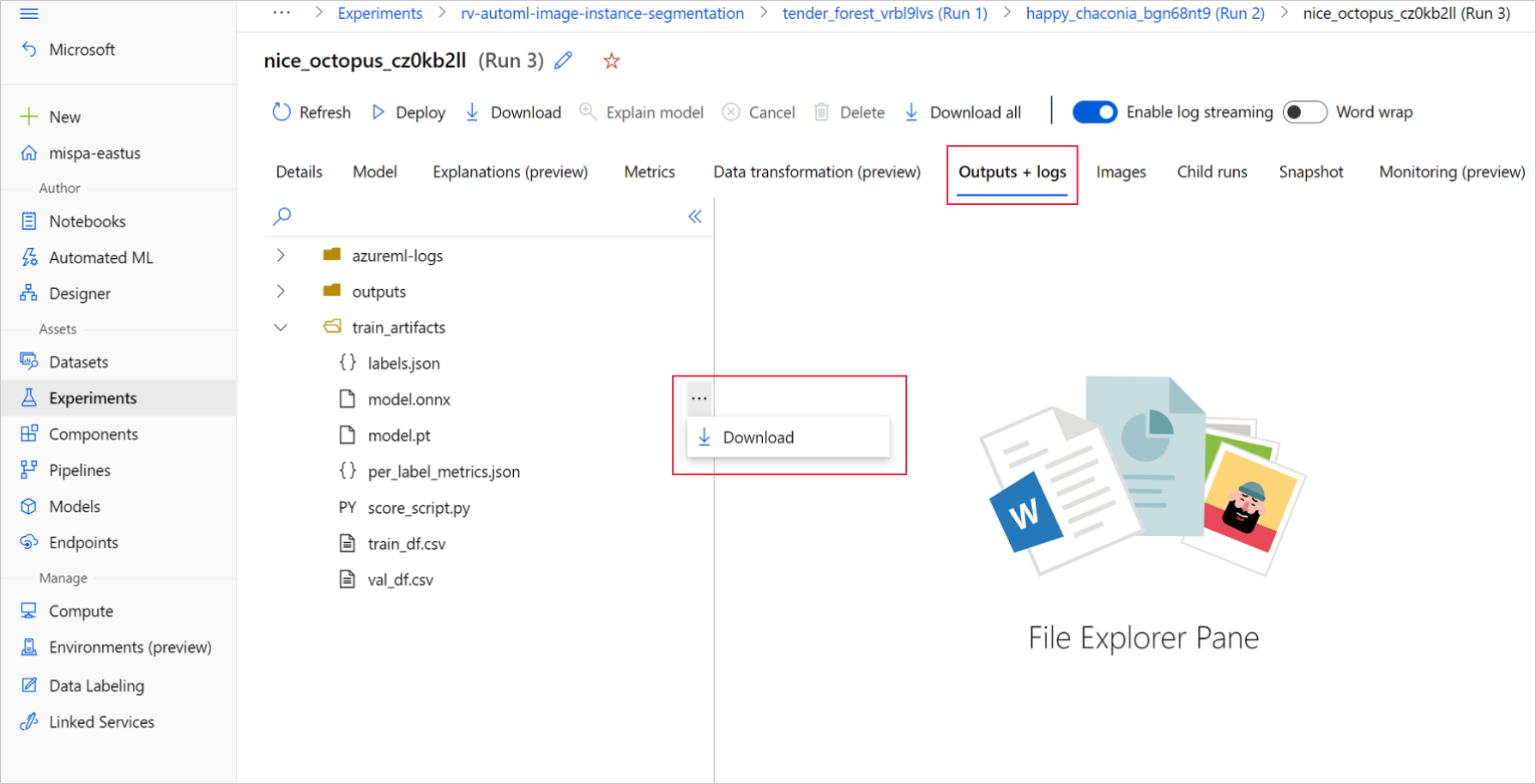
Du kan ladda ned ONNX-modellfiler från AutoML-körningar med hjälp av Azure Machine Learning-studio UI eller Azure Machine Learning Python SDK. Vi rekommenderar att du laddar ned via SDK:t med experimentnamnet och det överordnade körnings-ID:t.
Azure Machine Learning Studio
På Azure Machine Learning-studio går du till experimentet med hjälp av hyperlänken till experimentet som genereras i träningsanteckningsboken eller genom att välja experimentnamnet på fliken Experiment under Tillgångar. Välj sedan den bästa underordnade körningen.
Inom den bästa underordnade körningen går du till Utdata + loggar>train_artifacts. Använd knappen Ladda ned för att manuellt ladda ned följande filer:
labels.json: Fil som innehåller alla klasser eller etiketter i träningsdatauppsättningen.
model.onnx: Modell i ONNX-format.
Spara de nedladdade modellfilerna i en katalog. I exemplet i den här artikeln används katalogen ./automl_models .
Python-SDK för Azure Machine Learning
Med SDK:t kan du välja den bästa underordnade körningen (efter primärt mått) med experimentnamnet och det överordnade körnings-ID:t. Sedan kan du ladda ned filerna labels.json och model.onnx .
Följande kod returnerar den bästa underordnade körningen baserat på relevant primärt mått.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Ladda ned filen labels.json , som innehåller alla klasser och etiketter i träningsdatauppsättningen.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
Vid batchinferens för objektidentifiering och instanssegmentering med hjälp av ONNX-modeller läser du avsnittet om modellgenerering för batchbedömning.
Modellgenerering för batchbedömning
Som standard stöder AutoML för bilder batchbedömning för klassificering. Men ONNX-modeller för objektidentifiering och instanssegmentering stöder inte batchinferens. Vid batchinferens för objektidentifiering och instanssegmentering använder du följande procedur för att generera en ONNX-modell för den batchstorlek som krävs. Modeller som genereras för en viss batchstorlek fungerar inte för andra batchstorlekar.
Ladda ned conda-miljöfilen och skapa ett miljöobjekt som ska användas med kommandojobbet.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Information om hur du hämtar de argumentvärden som behövs för att skapa batchbedömningsmodellen finns i bedömningsskripten som genereras under utdatamappen för AutoML-träningskörningarna. Använd hyperparametervärdena som är tillgängliga i variabeln för modellinställningar i bedömningsfilen för bästa underordnade körning.
För bildklassificering i flera klasser stöder den genererade ONNX-modellen för bästa underordnade körning batchbedömning som standard. Därför behövs inga modellspecifika argument för den här aktivitetstypen och du kan gå vidare till avsnittet Läs in etiketter och ONNX-modellfiler .
För bildklassificering med flera etiketter stöder den genererade ONNX-modellen för bästa underordnade körning batchbedömning som standard. Därför behövs inga modellspecifika argument för den här aktivitetstypen och du kan gå vidare till avsnittet Läs in etiketter och ONNX-modellfiler .
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Ladda ned och behåll ONNX_batch_model_generator_automl_for_images.py filen i den aktuella katalogen för att skicka skriptet. Använd följande kommandojobb för att skicka skriptet ONNX_batch_model_generator_automl_for_images.py som är tillgängligt på GitHub-lagringsplatsen azureml-examples för att generera en ONNX-modell med en specifik batchstorlek. I följande kod används den tränade modellmiljön för att skicka det här skriptet för att generera och spara ONNX-modellen i utdatakatalogen.
För bildklassificering i flera klasser stöder den genererade ONNX-modellen för bästa underordnade körning batchbedömning som standard. Därför behövs inga modellspecifika argument för den här aktivitetstypen och du kan gå vidare till avsnittet Läs in etiketter och ONNX-modellfiler .
För bildklassificering med flera etiketter stöder den genererade ONNX-modellen för bästa underordnade körning batchbedömning som standard. Därför behövs inga modellspecifika argument för den här aktivitetstypen och du kan gå vidare till avsnittet Läs in etiketter och ONNX-modellfiler .
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
När batchmodellen har genererats kan du antingen ladda ned den från utdata+loggar>manuellt via användargränssnittet eller använda följande metod:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Vi tränade modellerna för alla visionsuppgifter med sina respektive datauppsättningar för att demonstrera ONNX-modellinferens.
Läs in etiketterna och ONNX-modellfilerna
Följande kodfragment läser in labels.json, där klassnamn sorteras. Om ONNX-modellen förutsäger ett etikett-ID som 2 motsvarar det etikettnamnet som anges i det tredje indexet i filen labels.json .
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Hämta förväntad information om indata och utdata för en ONNX-modell
När du har modellen är det viktigt att känna till viss modellspecifik och uppgiftsspecifik information. Den här informationen omfattar antalet indata och antalet utdata, förväntad indataform eller format för förbearbetning av bilden och utdataform så att du känner till modellspecifika eller uppgiftsspecifika utdata.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Förväntade in- och utdataformat för ONNX-modellen
Varje ONNX-modell har en fördefinierad uppsättning indata- och utdataformat.
Det här exemplet använder modellen som tränats på datauppsättningen fridgeObjects med 134 bilder och 4 klasser/etiketter för att förklara ONNX-modellinferens. Mer information om hur du tränar en bildklassificeringsuppgift finns i notebook-filen för bildklassificering i flera klasser.
Indataformat
Indata är en förbearbetad avbildning.
Indatanamn
Indataform
Input type
beskrivning
input1
(batch_size, num_channels, height, width)
ndarray(float)
Indata är en förbearbetad bild med formen (1, 3, 224, 224) för en batchstorlek på 1 och en höjd och bredd på 224. Dessa siffror motsvarar de värden som används för crop_size i träningsexemplet.
Utdataformat
Utdata är en matris med logits för alla klasser/etiketter.
Utdatanamn
Utdataform
Utdatatyp
beskrivning
output1
(batch_size, num_classes)
ndarray(float)
Modellen returnerar logits (utan softmax). För batchstorlek 1 och 4-klasser returneras (1, 4)till exempel .
I det här exemplet används modellen som tränats på datauppsättningen för kyl med flera etiketterObjects med 128 bilder och 4 klasser/etiketter för att förklara ONNX-modellinferens. Mer information om modellträning för bildklassificering med flera etiketter finns i notebook-filen för bildklassificering med flera etiketter.
Indataformat
Indata är en förbearbetad avbildning.
Indatanamn
Indataform
Input type
beskrivning
input1
(batch_size, num_channels, height, width)
ndarray(float)
Indata är en förbearbetad bild med formen (1, 3, 224, 224) för en batchstorlek på 1 och en höjd och bredd på 224. Dessa siffror motsvarar de värden som används för crop_size i träningsexemplet.
Utdataformat
Utdata är en matris med logits för alla klasser/etiketter.
Utdatanamn
Utdataform
Utdatatyp
beskrivning
output1
(batch_size, num_classes)
ndarray(float)
Modellen returnerar logits (utan sigmoid). För batchstorlek 1 och 4-klasser returneras (1, 4)till exempel .
I det här objektidentifieringsexemplet används modellen som tränats på datamängden fridgeObjects detection med 128 bilder och 4 klasser/etiketter för att förklara INFERENS för ONNX-modellen. Det här exemplet tränar Snabbare R-CNN-modeller för att demonstrera slutsatsdragningssteg. Mer information om hur du tränar objektidentifieringsmodeller finns i notebook-filen för objektidentifiering.
Indataformat
Indata är en förbearbetad avbildning.
Indatanamn
Indataform
Input type
beskrivning
Indata
(batch_size, num_channels, height, width)
ndarray(float)
Indata är en förbearbetad bild med formen (1, 3, 600, 800) för en batchstorlek på 1 och en höjd på 600 och en bredd på 800.
Utdataformat
Utdata är en tupplar av output_names och förutsägelser. Här och output_namespredictions finns listor med längd 3*batch_size vardera. För Snabbare R-CNN-ordning av utdata är rutor, etiketter och poäng, medan retinanet-utdata är rutor, poäng, etiketter.
Utdatanamn
Utdataform
Utdatatyp
beskrivning
output_names
(3*batch_size)
Lista över nycklar
För en batchstorlek på 2 är output_names['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Lista över ndarray(float)
För en batchstorlek på 2 tar predictions formen [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Här motsvarar värden vid varje index samma index i output_names.
I följande tabell beskrivs rutor, etiketter och poäng som returneras för varje exempel i batchen med bilder.
Name
Form
Typ
Beskrivning
Lådor
(n_boxes, 4), där varje ruta har x_min, y_min, x_max, y_max
ndarray(float)
Modellen returnerar n-rutor med koordinaterna överst till vänster och längst ned till höger.
Etiketter
(n_boxes)
ndarray(float)
Etikett eller klass-ID för ett objekt i varje ruta.
Noter
(n_boxes)
ndarray(float)
Konfidenspoäng för ett objekt i varje ruta.
I det här objektidentifieringsexemplet används modellen som tränats på datamängden fridgeObjects detection med 128 bilder och 4 klasser/etiketter för att förklara INFERENS för ONNX-modellen. Det här exemplet tränar YOLO-modeller för att demonstrera slutsatsdragningssteg. Mer information om hur du tränar objektidentifieringsmodeller finns i notebook-filen för objektidentifiering.
Indataformat
Indata är en förbearbetad bild med formen (1, 3, 640, 640) för en batchstorlek på 1 och en höjd och bredd på 640. Dessa siffror motsvarar de värden som används i träningsexemplet.
Indatanamn
Indataform
Input type
beskrivning
Indata
(batch_size, num_channels, height, width)
ndarray(float)
Indata är en förbearbetad bild med formen (1, 3, 640, 640) för en batchstorlek på 1 och en höjd på 640 och bredden 640.
Utdataformat
ONNX-modellförutsägelser innehåller flera utdata. De första utdata behövs för att utföra nonmax-undertryckning för identifieringar. För enkel användning visar automatiserad ML utdataformatet efter NMS-efterbearbetningssteget. Utdata efter NMS är en lista över rutor, etiketter och poäng för varje exempel i batchen.
Utdatanamn
Utdataform
Utdatatyp
beskrivning
Output
(batch_size)
Lista över ndarray(float)
Modellen returnerar lådidentifieringar för varje exempel i batchen
Varje cell i listan anger rutasidentifieringar av ett exempel med formen (n_boxes, 6), där varje ruta har x_min, y_min, x_max, y_max, confidence_score, class_id.
I det här instanssegmenteringsexemplet använder du R-CNN-modellen Mask som har tränats på datauppsättningen fridgeObjects med 128 bilder och 4 klasser/etiketter för att förklara ONNX-modellinferens. Mer information om träning av instanssegmenteringsmodellen finns i notebook-filen för instanssegmentering.
Viktigt!
Endast Maskera R-CNN stöds för instanssegmenteringsuppgifter. Indata- och utdataformaten baseras endast på Maskera R-CNN.
Indataformat
Indata är en förbearbetad avbildning. ONNX-modellen för Mask R-CNN har exporterats för att fungera med bilder av olika former. Vi rekommenderar att du ändrar storlek på dem till en fast storlek som är konsekvent med bildstorlekar för träning, för bättre prestanda.
Indatanamn
Indataform
Input type
beskrivning
Indata
(batch_size, num_channels, height, width)
ndarray(float)
Indata är en förbearbetad bild med en form (1, 3, input_image_height, input_image_width) för en batchstorlek på 1 och en höjd och bredd som liknar en indatabild.
Utdataformat
Utdata är en tupplar av output_names och förutsägelser. Här och output_namespredictions är listor med längd 4*batch_size vardera.
Utdatanamn
Utdataform
Utdatatyp
beskrivning
output_names
(4*batch_size)
Lista över nycklar
För en batchstorlek på 2 är output_names['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Lista över ndarray(float)
För en batchstorlek på 2 tar predictions formen [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Här motsvarar värden vid varje index samma index i output_names.
Name
Form
Typ
Beskrivning
Lådor
(n_boxes, 4), där varje ruta har x_min, y_min, x_max, y_max
ndarray(float)
Modellen returnerar n-rutor med koordinaterna överst till vänster och längst ned till höger.
Etiketter
(n_boxes)
ndarray(float)
Etikett eller klass-ID för ett objekt i varje ruta.
Noter
(n_boxes)
ndarray(float)
Konfidenspoäng för ett objekt i varje ruta.
Masker
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Masker (polygoner) för identifierade objekt med formhöjd och bredd för en indatabild.
Utför följande förbearbetningssteg för ONNX-modellinferensen:
Konvertera bilden till RGB.
Ändra storlek på avbildningen till valid_resize_size och valid_resize_size värden som motsvarar de värden som används i omvandlingen av valideringsdatauppsättningen under träningen. Standardvärdet för valid_resize_size är 256.
Centrera beskära avbildningen till height_onnx_crop_size och width_onnx_crop_size. Det motsvarar valid_crop_size med standardvärdet 224.
Ändra HxWxC till CxHxW.
Konvertera till flyttaltyp.
Normalisera med ImageNets mean = [0.485, 0.456, 0.406] och .std = [0.229, 0.224, 0.225]
Om du väljer olika värden för hyperparametrarvalid_resize_size och valid_crop_size under träningen ska dessa värden användas.
Hämta den indataform som behövs för ONNX-modellen.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Med PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Utför följande förbearbetningssteg för ONNX-modellinferensen. De här stegen är desamma för bildklassificering i flera klasser.
Konvertera bilden till RGB.
Ändra storlek på avbildningen till valid_resize_size och valid_resize_size värden som motsvarar de värden som används i omvandlingen av valideringsdatauppsättningen under träningen. Standardvärdet för valid_resize_size är 256.
Centrera beskära avbildningen till height_onnx_crop_size och width_onnx_crop_size. Detta motsvarar valid_crop_size standardvärdet 224.
Ändra HxWxC till CxHxW.
Konvertera till flyttaltyp.
Normalisera med ImageNets mean = [0.485, 0.456, 0.406] och .std = [0.229, 0.224, 0.225]
Om du väljer olika värden för hyperparametrarvalid_resize_size och valid_crop_size under träningen ska dessa värden användas.
Hämta den indataform som behövs för ONNX-modellen.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Med PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
För objektidentifiering med arkitekturen Snabbare R-CNN följer du samma förbearbetningssteg som bildklassificering, förutom bildbeskärning. Du kan ändra storlek på bilden med höjd 600 och bredd 800. Du kan få den förväntade indatahöjden och bredden med följande kod.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
För objektidentifiering med YOLO-arkitekturen följer du samma förbearbetningssteg som bildklassificering, förutom bildbeskärning. Du kan ändra storlek på bilden med höjd 600 och bredd 800och hämta förväntad indatahöjd och bredd med följande kod.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Viktigt!
Endast Maskera R-CNN stöds för instanssegmenteringsuppgifter. Förbearbetningsstegen baseras endast på Maskera R-CNN.
Utför följande förbearbetningssteg för ONNX-modellinferensen:
Konvertera bilden till RGB.
Ändra storlek på bilden.
Ändra HxWxC till CxHxW.
Konvertera till flyttaltyp.
Normalisera med ImageNets mean = [0.485, 0.456, 0.406] och .std = [0.229, 0.224, 0.225]
För resize_height och resize_widthkan du också använda de värden som du använde under träningen, avgränsade med min_size och max_sizehyperparametrar för Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Slutsatsdragning med ONNX Runtime
Slutsatsdragningen med ONNX Runtime skiljer sig åt för varje uppgift för visuellt innehåll.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Instanssegmenteringsmodellen förutsäger rutor, etiketter, poäng och masker. ONNX matar ut en förutsagd mask per instans, tillsammans med motsvarande avgränsningsrutor och klassförtroendepoäng. Du kan behöva konvertera från binär mask till polygon om det behövs.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Använd softmax() över förutsagda värden för att få klassificeringsförtroendepoäng (sannolikheter) för varje klass. Sedan blir förutsägelsen den klass med högst sannolikhet.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Det här steget skiljer sig från klassificering med flera klasser. Du måste tillämpa sigmoid på logits (ONNX-utdata) för att få konfidenspoäng för bildklassificering med flera etiketter.
Utan PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Med PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
För klassificering med flera klasser och flera etiketter kan du följa samma steg som tidigare för alla modellarkitekturer som stöds i AutoML.
För objektidentifiering sker förutsägelser automatiskt på skalan height_onnx, width_onnx. Om du vill transformera koordinaterna för den förutsagda rutan till de ursprungliga dimensionerna kan du implementera följande beräkningar.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Ett annat alternativ är att använda följande kod för att skala boxdimensionerna så att de ligger inom intervallet [0, 1]. På så sätt kan lådkoordinaterna multipliceras med originalbildernas höjd och bredd med respektive koordinater (enligt beskrivningen i avsnittet visualisera förutsägelser) för att hämta rutor i ursprungliga bilddimensioner.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Följande kod skapar rutor, etiketter och poäng. Använd den här avgränsningsrutan för att utföra samma steg för efterbearbetning som du gjorde för R-CNN-modellen Snabbare.
Du kan antingen använda de steg som anges för Snabbare R-CNN (om det gäller maskera R-CNN har varje exempel fyra elementrutor, etiketter, poäng, masker) eller referera till avsnittet visualisera förutsägelser för instanssegmentering.
 Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)