Felsöka pipelines för maskininlärning
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du felsöker när du får fel när du kör en maskininlärningspipeline i Azure Mašinsko učenje SDK och Azure Mašinsko učenje designer.
Felsökningstips
Följande tabell innehåller vanliga problem under pipelineutvecklingen, med möjliga lösningar.
| Problem | Möjlig lösning |
|---|---|
Det gick inte att skicka data till PipelineData katalog |
Se till att du har skapat en katalog i skriptet som motsvarar var din pipeline förväntar sig stegutdata. I de flesta fall definierar ett indataargument utdatakatalogen och sedan skapar du katalogen explicit. Använd os.makedirs(args.output_dir, exist_ok=True) för att skapa utdatakatalogen. Se självstudien för att få ett exempel på bedömningsskript som visar det här designmönstret. |
| Beroendebuggar | Om du ser beroendefel i fjärrpipelinen som inte inträffade när du testade lokalt kontrollerar du att dina fjärrmiljöberoenden och -versioner matchar dem i testmiljön. (Se Miljöskapande, cachelagring och återanvändning |
| Tvetydiga fel med beräkningsmål | Försök att ta bort och återskapa beräkningsmål. Det går snabbt att återskapa beräkningsmål och det kan lösa vissa tillfälliga problem. |
| Pipeline återanvänder inte steg | Återanvändning av steg är aktiverat som standard, men se till att du inte har inaktiverat det i ett pipelinesteg. Om återanvändning är inaktiverat anges parametern allow_reuse i steget till False. |
| Pipeline körs igen i onödan | För att säkerställa att stegen bara körs igen när underliggande data eller skript ändras frikopplar du källkodskatalogerna för varje steg. Om du använder samma källkatalog för flera steg kan det uppstå onödiga körningar. Använd parametern source_directory i ett pipelinestegobjekt för att peka på din isolerade katalog för det steget och se till att du inte använder samma source_directory sökväg för flera steg. |
| Steg som saktar ned över träningsepoker eller annat loopbeteende | Prova med att växla alla filskrivningar, inklusive loggning, as_mount() till as_upload(). Monteringsläget använder ett virtualiserat fjärrfilsystem och laddar upp hela filen varje gång något läggs till i den. |
| Det tar lång tid att starta beräkningsmålet | Docker-avbildningar för beräkningsmål läses in från Azure Container Registry (ACR). Som standard skapar Azure Mašinsko učenje en ACR som använder den grundläggande tjänstnivån. Om du ändrar ACR för din arbetsyta till standard- eller premiumnivån kan det minska tidsåtgången för att skapa och läsa in avbildningar. Mer information finns i Azure Container Registry-tjänstnivåer (ACR). |
Autentiseringsfel
Om du utför en hanteringsåtgärd på ett beräkningsmål från ett fjärrjobb får du något av följande fel:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Du får till exempel ett fel om du försöker skapa eller koppla ett beräkningsmål från en ML-pipeline som skickas för fjärrkörning.
Felsökning ParallelRunStep
Skriptet för en ParallelRunStep måste innehålla två funktioner:
init(): Använd den här funktionen för eventuella kostsamma eller vanliga förberedelser för senare slutsatsdragning. Använd den till exempel för att läsa in modellen i ett globalt objekt. Den här funktionen anropas bara en gång i början av processen.run(mini_batch): Funktionen körs för varjemini_batchinstans.mini_batch:ParallelRunStepanropar körningsmetoden och skickar antingen en lista eller pandasDataFramesom ett argument till metoden. Varje post i mini_batch är en filsökväg om indata är enFileDataseteller en PandasDataFrameom indata är enTabularDataset.response: run()-metoden ska returnera en PandasDataFrameeller en matris. För append_row output_action läggs dessa returnerade element till i den gemensamma utdatafilen. För summary_only ignoreras innehållet i elementen. För alla utdataåtgärder anger varje returnerat utdataelement en lyckad körning av indataelementet i minibatchen för indata. Se till att tillräckligt med data ingår i körningsresultatet för att mappa indata för att köra utdataresultatet. Körningsutdata skrivs i utdatafilen och garanteras inte vara i ordning. Du bör använda en nyckel i utdata för att mappa den till indata.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Om du har en annan fil eller mapp i samma katalog som ditt slutsatsdragningsskript kan du referera till den genom att hitta den aktuella arbetskatalogen.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parametrar för ParallelRunConfig
ParallelRunConfigär den viktigaste konfigurationen för ParallelRunStep instansen i Azure Mašinsko učenje pipeline. Du använder det för att omsluta skriptet och konfigurera nödvändiga parametrar, inklusive alla följande poster:
entry_script: Ett användarskript som en lokal filsökväg som körs parallellt på flera noder. Omsource_directoryfinns använder du en relativ sökväg. Annars använder du alla sökvägar som är tillgängliga på datorn.mini_batch_size: Storleken på mini-batchen som skickas till ett endarun()anrop. (valfritt; standardvärdet är10filer förFileDatasetoch1MBförTabularDataset.)- För
FileDatasetär det antalet filer med ett minsta värde på1. Du kan kombinera flera filer i en mini-batch. - För
TabularDatasetär det storleken på data. Exempelvärden är1024,1024KB,10MBoch1GB. Det rekommenderade värdet är1MB. Mini-batchen frånTabularDatasetkommer aldrig att korsa filgränserna. Om du till exempel har .csv filer med olika storlekar är den minsta filen 100 KB och den största är 10 MB. Om du angermini_batch_size = 1MBbehandlas filer med en storlek som är mindre än 1 MB som en mini-batch. Filer med en storlek som är större än 1 MB delas upp i flera mini-batchar.
- För
error_threshold: Antalet postfel förTabularDatasetoch filfel förFileDatasetsom ska ignoreras under bearbetningen. Om felantalet för hela indata överskrider det här värdet avbryts jobbet. Tröskelvärdet för fel gäller för hela indata och inte för enskilda minibatch som skickas tillrun()metoden. Intervallet är[-1, int.max]. Delen-1anger att alla fel ignoreras under bearbetningen.output_action: Ett av följande värden anger hur utdata organiseras:summary_only: Användarskriptet lagrar utdata.ParallelRunStepanvänder endast utdata för beräkningen av feltröskeln.append_row: För alla indata skapas endast en fil i utdatamappen för att lägga till alla utdata avgränsade med rad.
append_row_file_name: Om du vill anpassa utdatafilens namn för append_row output_action (valfritt, ärparallel_run_step.txtstandardvärdet ).source_directory: Sökvägar till mappar som innehåller alla filer som ska köras på beräkningsmålet (valfritt).compute_target: EndastAmlComputestöds.node_count: Antalet beräkningsnoder som ska användas för att köra användarskriptet.process_count_per_node: Antalet processer per nod. Bästa praxis är att ange till antalet GPU eller PROCESSOR en nod har (valfritt; standardvärdet är1).environment: Python-miljödefinitionen. Du kan konfigurera den så att den använder en befintlig Python-miljö eller för att konfigurera en tillfällig miljö. Definitionen ansvarar också för att ange nödvändiga programberoenden (valfritt).logging_level: Log verbosity. Värden i ökande verbositet är:WARNING,INFOochDEBUG. (valfritt; standardvärdet ärINFO)run_invocation_timeout: Tidsgränsenrun()för metodens anrop i sekunder. (valfritt; standardvärdet är60)run_max_try: Maximalt antalrun()försök för en mini-batch. Arun()misslyckas om ett undantag utlöses eller inget returneras närrun_invocation_timeouthar nåtts (valfritt; standardvärdet är3).
Du kan ange mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeoutoch run_max_try som PipelineParameter, så att du kan finjustera parametervärdena när du skicka en pipelinekörning igen. I det här exemplet använder PipelineParameter du för mini_batch_size och Process_count_per_node och ändrar dessa värden när du lägger till en körning igen senare.
Parametrar för att skapa ParallelRunStep
Skapa ParallelRunStep med hjälp av skriptet, miljökonfigurationen och parametrarna. Ange det beräkningsmål som du redan har kopplat till din arbetsyta som mål för körningen för ditt slutsatsdragningsskript. Använd ParallelRunStep för att skapa steget för batchinferenspipeline, som tar alla följande parametrar:
name: Namnet på steget med följande namngivningsbegränsningar: unikt, 3–32 tecken och regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: EttParallelRunConfigobjekt enligt definitionen tidigare.inputs: En eller flera azure-Mašinsko učenje datauppsättningar som ska partitioneras för parallell bearbetning.side_inputs: En eller flera referensdata eller datauppsättningar som används som sidoindata utan att behöva partitioneras.output: EttOutputFileDatasetConfigobjekt som motsvarar utdatakatalogen.arguments: En lista med argument som skickas till användarskriptet. Använd unknown_args för att hämta dem i ditt postskript (valfritt).allow_reuse: Om steget ska återanvända tidigare resultat när det körs med samma inställningar/indata. Om den här parametern ärFalsegenereras en ny körning för det här steget under pipelinekörningen. (valfritt; standardvärdet ärTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Felsökningstekniker
Det finns tre huvudsakliga tekniker för felsökning av pipelines:
- Felsöka enskilda pipelinesteg på din lokala dator
- Använda loggning och Application Insights för att isolera och diagnostisera orsaken till problemet
- Koppla en fjärrfelsökare till en pipeline som körs i Azure
Felsöka skript lokalt
Ett av de vanligaste felen i en pipeline är att domänskriptet inte körs som avsett eller innehåller körningsfel i fjärrberäkningskontexten som är svåra att felsöka.
Själva pipelines kan inte köras lokalt. Men om du kör skripten isolerat på den lokala datorn kan du felsöka snabbare eftersom du inte behöver vänta på beräknings- och miljögenereringsprocessen. Vissa utvecklingsarbete krävs för att göra detta:
- Om dina data finns i ett molndatalager måste du ladda ned data och göra dem tillgängliga för skriptet. Att använda ett litet exempel på dina data är ett bra sätt att minska körningen och snabbt få feedback om skriptbeteende
- Om du försöker simulera ett mellanliggande pipelinesteg kan du behöva skapa de objekttyper som det specifika skriptet förväntar sig manuellt från föregående steg
- Du måste definiera din egen miljö och replikera de beroenden som definierats i fjärrberäkningsmiljön
När du har en skriptkonfiguration som ska köras i din lokala miljö är det enklare att felsöka uppgifter som:
- Ansluta en anpassad felsökningskonfiguration
- Pausa körning och inspektera objekttillstånd
- Fånga typ eller logiska fel som inte exponeras förrän körningen
Dricks
När du kan kontrollera att skriptet körs som förväntat körs ett bra nästa steg i skriptet i en pipeline i ett steg innan du försöker köra det i en pipeline med flera steg.
Konfigurera, skriva till och granska pipelineloggar
Att testa skript lokalt är ett bra sätt att felsöka större kodfragment och komplex logik innan du börjar skapa en pipeline. Vid något tillfälle måste du felsöka skript under själva pipelinekörningen, särskilt när du diagnostiserar beteendet som inträffar under interaktionen mellan pipelinestegen. Vi rekommenderar frisinnad användning av print() instruktioner i dina stegskript så att du kan se objekttillstånd och förväntade värden under fjärrkörning, ungefär som när du felsöker JavaScript-kod.
Loggningsalternativ och beteende
Följande tabell innehåller information om olika felsökningsalternativ för pipelines. Det är inte en fullständig lista, eftersom det finns andra alternativ förutom bara Azure Mašinsko učenje och Python som visas här.
| Bibliotek | Typ | Exempel | Mål | Resurser |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metric | run.log(name, val) |
Azure Machine Learning-portalens användargränssnitt | Så här spårar du experiment Klassen azureml.core.Run |
| Python-utskrift/-loggning | Loggas | print(val)logging.info(message) |
Drivrutinsloggar, Azure Machine Learning Designer | Så här spårar du experiment Python-loggning |
Exempel på loggningsalternativ
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Azure Machine Learning Designer
För pipelines som skapats i designern kan du hitta filen 70_driver_log antingen på redigeringssidan eller på informationssidan för pipelinekörning.
Aktivera loggning för realtidsslutpunkter
För att kunna felsöka och felsöka realtidsslutpunkter i designern måste du aktivera Application Insight-loggning med hjälp av SDK:t. Med loggning kan du felsöka och felsöka problem med modelldistribution och användning. Mer information finns i Loggning för distribuerade modeller.
Hämta loggar från redigeringssidan
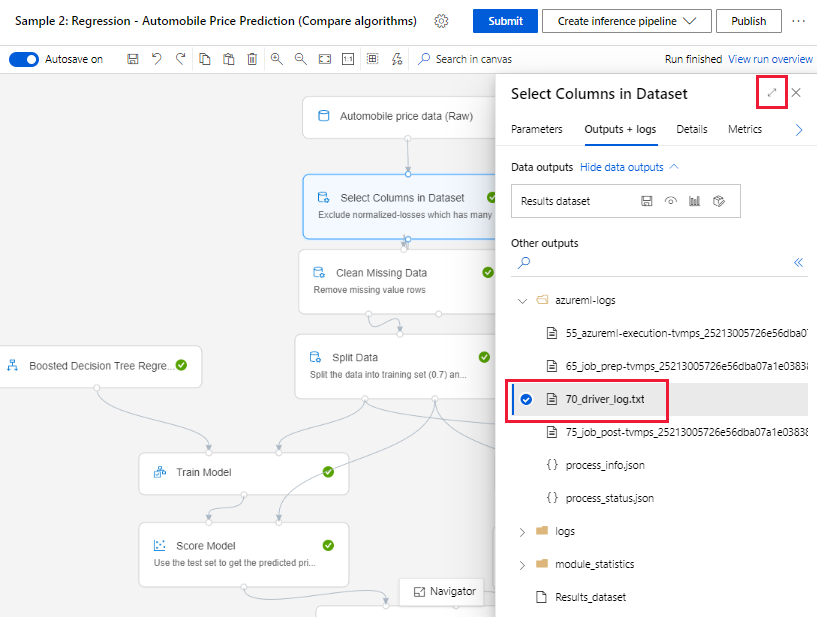
När du skickar en pipelinekörning och stannar kvar på redigeringssidan kan du hitta loggfilerna som genereras för varje komponent när varje komponent är klar.
Välj en komponent som har körts på redigeringsarbetsytan.
I komponentens högra fönster går du till fliken Utdata + loggar .
Expandera den högra rutan och välj 70_driver_log.txt för att visa filen i webbläsaren. Du kan också ladda ned loggar lokalt.
Hämta loggar från pipelinekörningar
Du kan också hitta loggfilerna för specifika körningar på informationssidan för pipelinekörning, som finns i avsnittet Pipelines eller Experiment i studion.
Välj en pipelinekörning som skapats i designern.
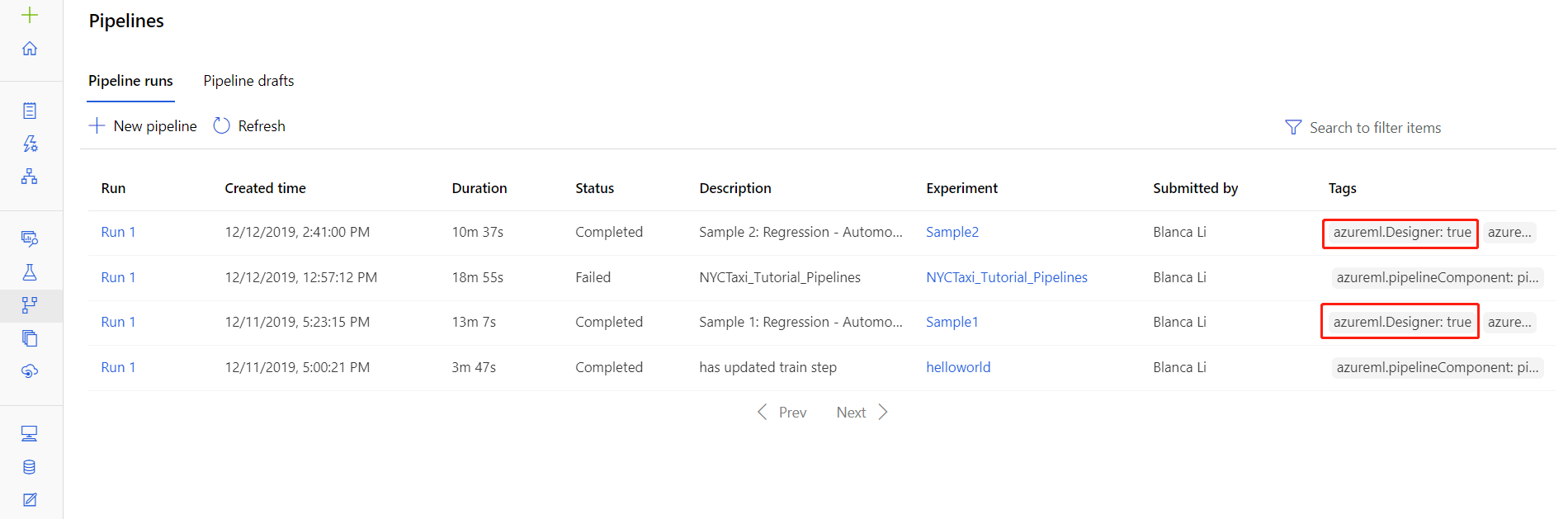
Välj en komponent i förhandsgranskningsfönstret.
I komponentens högra fönster går du till fliken Utdata + loggar .
Expandera det högra fönstret om du vill visa std_log.txt filen i webbläsaren eller välj filen för att ladda ned loggarna lokalt.
Viktigt!
Om du vill uppdatera en pipeline från informationssidan för pipelinekörningen måste du klona pipelinekörningen till ett nytt pipelineutkast. En pipelinekörning är en ögonblicksbild av pipelinen. Den liknar en loggfil och kan inte ändras.
Interaktiv felsökning med Visual Studio Code
I vissa fall kan du behöva felsöka Python-koden interaktivt i din ML-pipeline. Genom att använda Visual Studio Code (VS Code) och debugpy kan du ansluta till koden när den körs i träningsmiljön. Mer information finns i den här guiden för interaktiv felsökning i VS Code.
HyperdriveStep och AutoMLStep misslyckas med nätverksisolering
När du har använt HyperdriveStep och AutoMLStep kan du få ett fel när du försöker registrera modellen.
Du använder Azure Mašinsko učenje SDK v1.
Din Azure Mašinsko učenje-arbetsyta har konfigurerats för nätverksisolering (VNet).
Pipelinen försöker registrera modellen som genererades av föregående steg. I följande exempel är parametern
inputstill exempel saved_model från en HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Lösning
Viktigt!
Det här beteendet inträffar inte när du använder Azure Mašinsko učenje SDK v2.
Om du vill kringgå det här felet använder du klassen Kör för att hämta modellen som skapats från HyperdriveStep eller AutoMLStep. Följande är ett exempelskript som hämtar utdatamodellen från en HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Filen kan sedan användas från en PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Nästa steg
En fullständig självstudiekurs med hjälp av finns
ParallelRunStepi Självstudie: Skapa en Azure Mašinsko učenje pipeline för batchbedömning.Ett fullständigt exempel som visar automatiserad maskininlärning i ML-pipelines finns i Använda automatiserad ML i en Azure Mašinsko učenje-pipeline i Python.
Se SDK-referensen för hjälp med paketet azureml-pipelines-core och paketet azureml-pipelines-steps .
Se listan över designerfel och felkoder.