Köra batchförutsägelser med Hjälp av Azure Mašinsko učenje Designer
I den här artikeln får du lära dig hur du använder designern för att skapa en pipeline för batchförutsägelse. Med batchförutsägelse kan du kontinuerligt poängsätta stora datamängder på begäran med hjälp av en webbtjänst som kan utlösas från alla HTTP-bibliotek.
I den här instruktionen lär du dig att utföra följande uppgifter:
- Skapa och publicera en pipeline för batchinferens
- Använda en pipelineslutpunkt
- Hantera slutpunktsversioner
Mer information om hur du konfigurerar batchbedömningstjänster med hjälp av SDK finns i den medföljande självstudien om batchbedömning av pipeline.
Förutsättningar
Detta förutsätter att du redan har en träningspipeline. För en guidad introduktion till designern, slutför du del ett av designguiden.
Viktigt!
Om du inte ser grafiska element som nämns i det här dokumentet, till exempel knappar i studio eller designer, kanske du inte har rätt behörighetsnivå för arbetsytan. Kontakta azure-prenumerationsadministratören för att kontrollera att du har beviljats rätt åtkomstnivå. Mer information finns i Hantera användare och roller.
Skapa en pipeline för batchinferens
Din träningspipeline måste köras minst en gång för att kunna skapa en slutsatsdragningspipeline.
Gå till fliken Designer på arbetsytan.
Välj den träningspipeline som tränar den modell som du vill använda för att göra förutsägelser.
Skicka pipelinen.
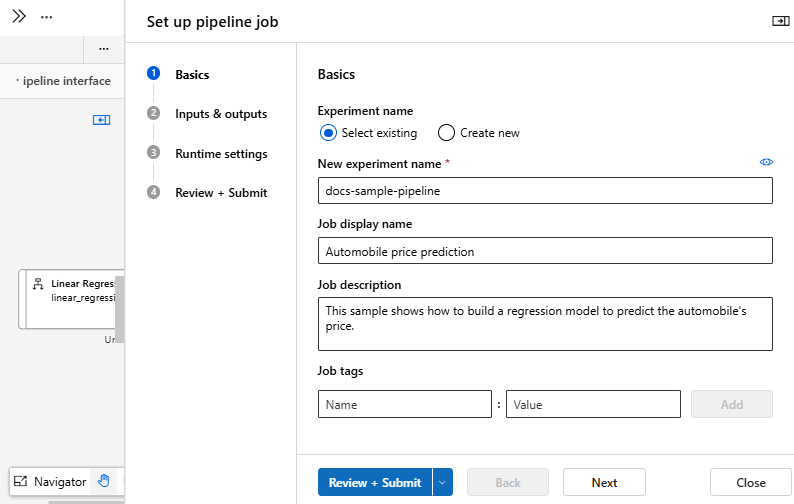

Du ser en överföringslista till vänster om arbetsytan. Du kan välja jobbinformationslänken för att gå till jobbinformationssidan, och när träningspipelinejobbet har slutförts kan du skapa en pipeline för batchinferens.

På sidan med jobbinformation, ovanför arbetsytan, väljer du listrutan Skapa slutsatsdragningspipeline. Välj Batch-slutsatsdragningspipeline.
Kommentar
För närvarande fungerar en pipeline för automatisk generering av slutsatsdragning endast för träningspipeline som skapats enbart av de inbyggda designerkomponenterna.
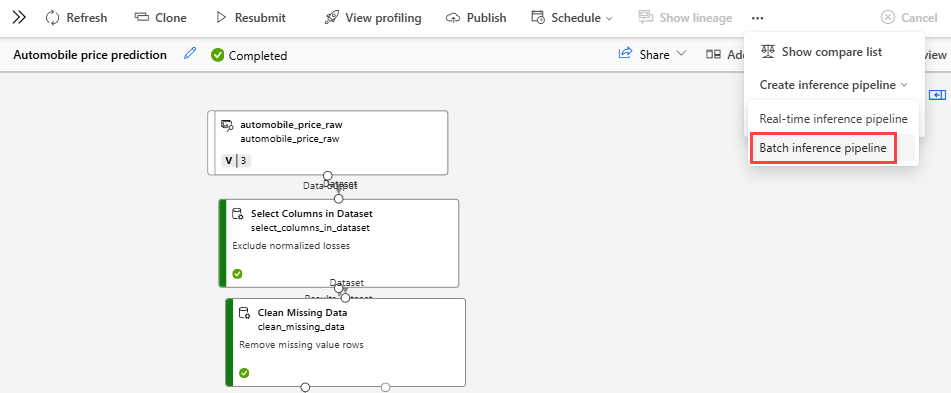
Det skapar ett pipelineutkast för batchinferens åt dig. Pipelineutkastet för batchinferens använder den tränade modellen som MD-nod och transformering som TD-nod från träningspipelinejobbet.
Du kan också ändra det här utkastet till slutsatsdragningspipeline för att bättre hantera dina indata för batchinferens.



Lägga till en pipelineparameter
Om du vill skapa förutsägelser för nya data kan du antingen manuellt ansluta en annan datauppsättning i den här pipelineutkastvyn eller skapa en parameter för din datauppsättning. Med parametrar kan du ändra beteendet för batch-inferensprocessen vid körning.
I det här avsnittet skapar du en datamängdsparameter för att ange en annan datauppsättning att göra förutsägelser om.
Välj datamängdskomponenten.
Ett fönster visas till höger om arbetsytan. Längst ned i fönstret väljer du Ange som pipelineparameter.
Ange ett namn för parametern eller acceptera standardvärdet.

Skicka batchens slutsatsdragningspipeline och gå till sidan med jobbinformation genom att välja jobblänken i den vänstra rutan.

Publicera batchinferenspipelinen
Nu är du redo att distribuera slutsatsdragningspipelinen. Detta distribuerar pipelinen och gör den tillgänglig för andra att använda.
Välj sedan knappen Publicera.
I dialogrutan som visas expanderar du listrutan för PipelineEndpoint och väljer Ny PipelineEndpoint.
Ange ett slutpunktsnamn och en valfri beskrivning.
Längst ned i dialogrutan kan du se parametern som du konfigurerade med ett standardvärde för det datamängds-ID som användes under träningen.
Välj Publicera.

Använda en slutpunkt
Nu har du en publicerad pipeline med en datamängdsparameter. Pipelinen använder den tränade modellen som skapades i träningspipelinen för att poängsätta den datauppsättning som du anger som en parameter.
Skicka ett pipelinejobb
I det här avsnittet konfigurerar du ett manuellt pipelinejobb och ändrar pipelineparametern för att poängsätta nya data.
När distributionen är klar går du till avsnittet Slutpunkter .
Välj Pipelineslutpunkter.
Välj namnet på slutpunkten som du skapade.
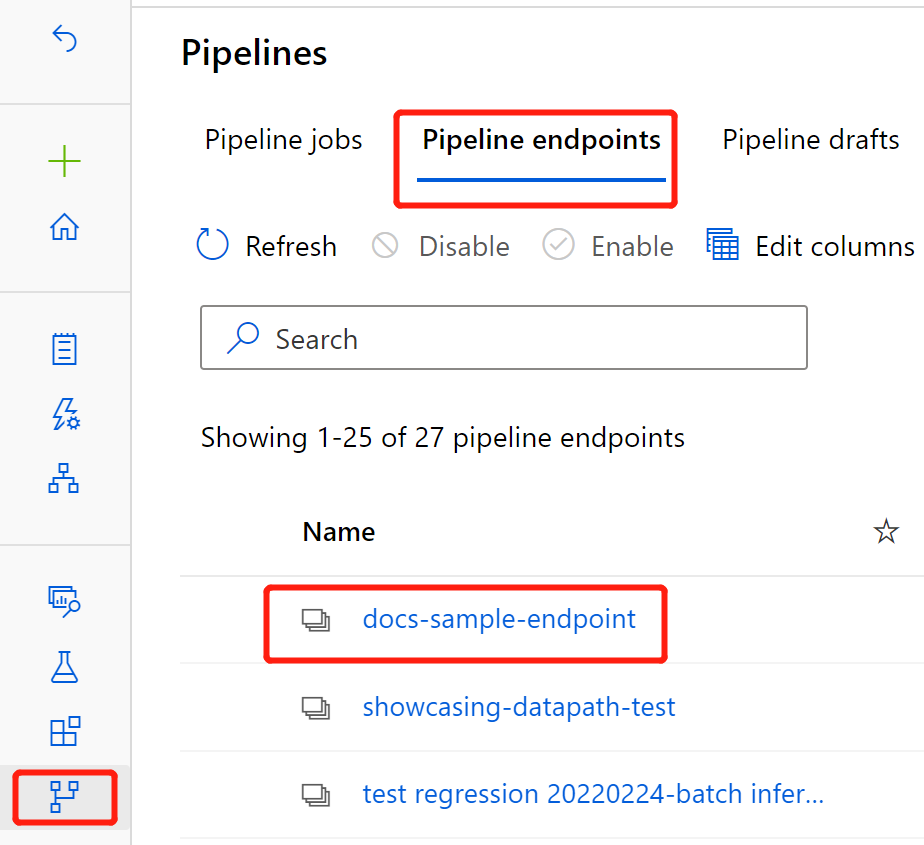
Välj Publicerade pipelines.
Den här skärmen visar alla publicerade pipelines som publicerats under den här slutpunkten.
Välj den pipeline som du publicerade.
På sidan med pipelineinformation visas en detaljerad jobbhistorik och niska veze information för din pipeline.
Välj Skicka för att skapa en manuell körning av pipelinen.
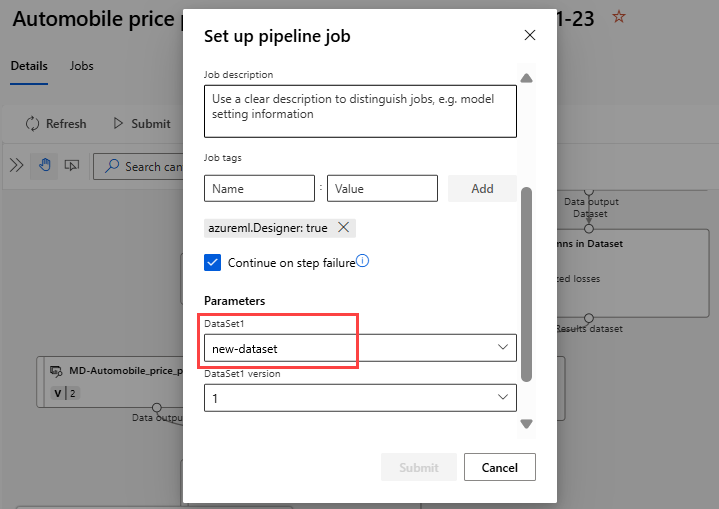
Ändra parametern så att den använder en annan datauppsättning.
Välj Skicka för att köra pipelinen.

Använda REST-slutpunkten
Du hittar information om hur du använder pipelineslutpunkter och publicerad pipeline i avsnittet Slutpunkter .
Du hittar REST-slutpunkten för en pipelineslutpunkt i jobböversiktspanelen. Genom att anropa slutpunkten använder du den publicerade standardpipelinen.
Du kan också använda en publicerad pipeline på sidan Publicerade pipelines . Välj en publicerad pipeline så hittar du REST-slutpunkten för den i översiktspanelen För publicerad pipeline till höger om diagrammet.
Om du vill göra ett REST-anrop behöver du ett autentiseringshuvud av typen OAuth 2.0-ägartyp. Mer information om hur du konfigurerar autentisering till din arbetsyta och gör ett parametriserat REST-anrop finns i följande självstudieavsnitt .
Versionsslutpunkter
Designern tilldelar en version till varje efterföljande pipeline som du publicerar till en slutpunkt. Du kan ange den pipelineversion som du vill köra som en parameter i REST-anropet. Om du inte anger något versionsnummer använder designern standardpipelinen.
När du publicerar en pipeline kan du välja att göra den till den nya standardpipelinen för slutpunkten.
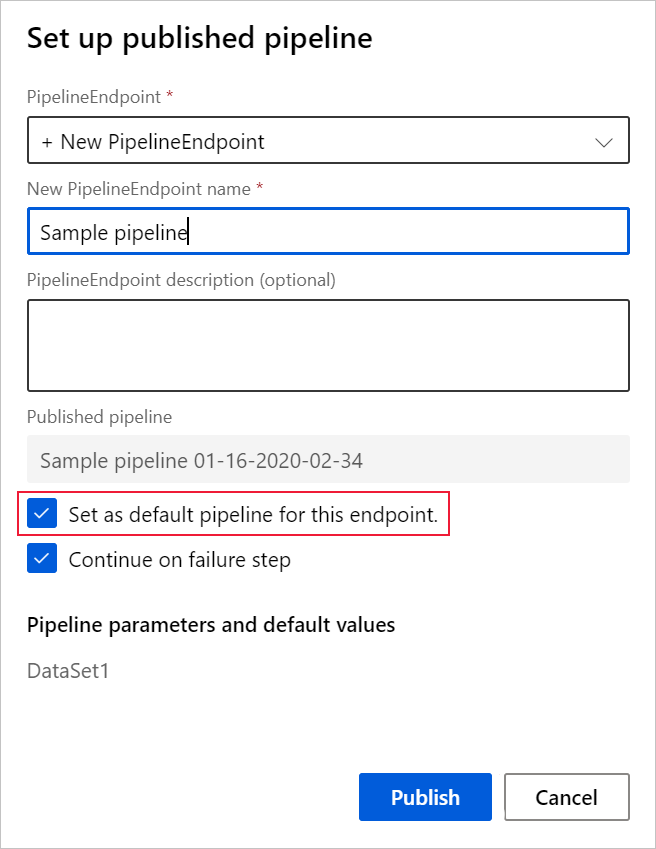
Du kan också ange en ny standardpipeline på fliken Publicerade pipelines i slutpunkten.
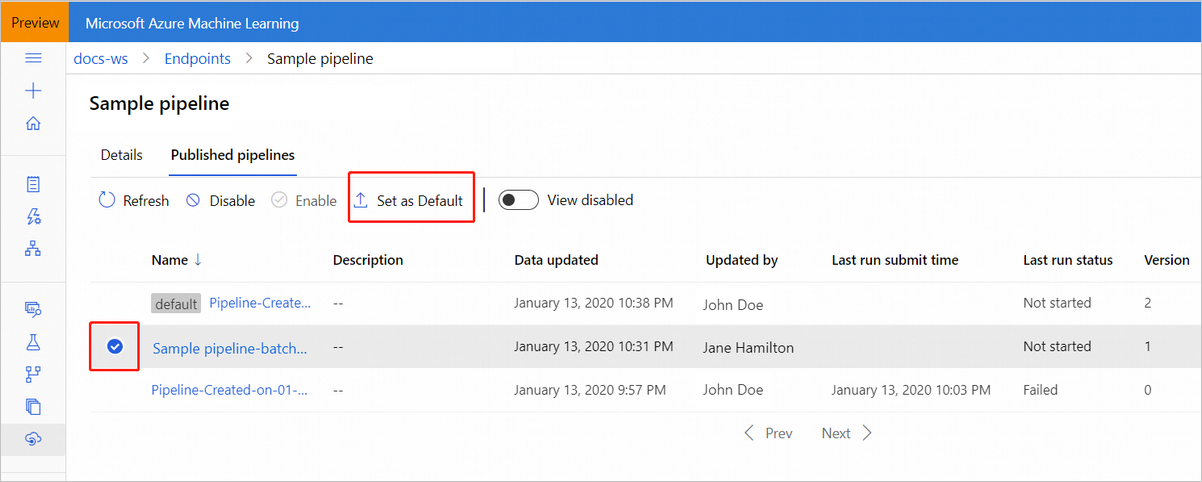
Uppdatera pipelineslutpunkten
Om du gör några ändringar i träningspipelinen kanske du vill uppdatera den nyligen tränade modellen till pipelineslutpunkten.
När din ändrade träningspipeline har slutförts går du till sidan med jobbinformation.
Högerklicka på komponenten Träna modell och välj Registrera data
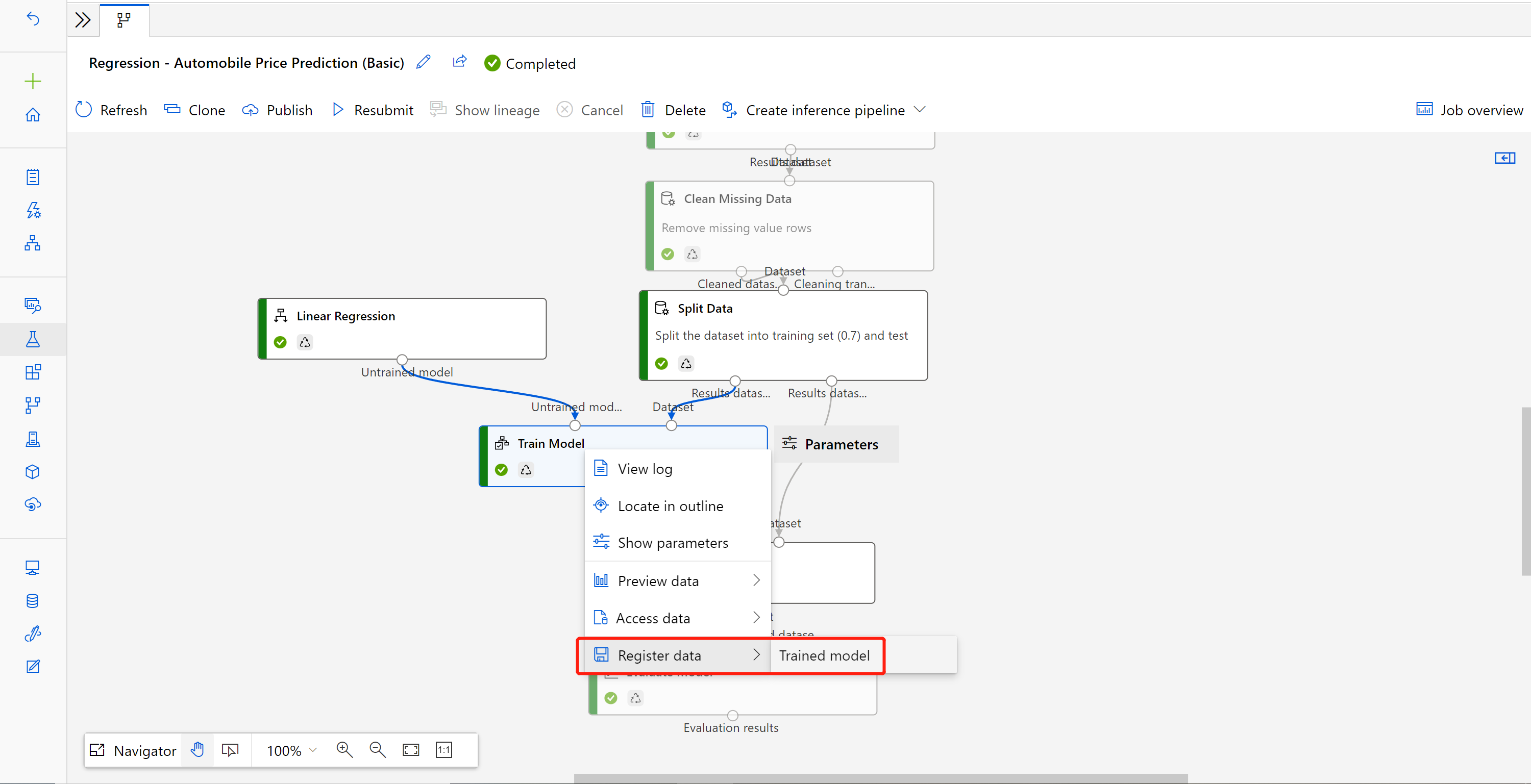
Indatanamn och välj Filtyp .
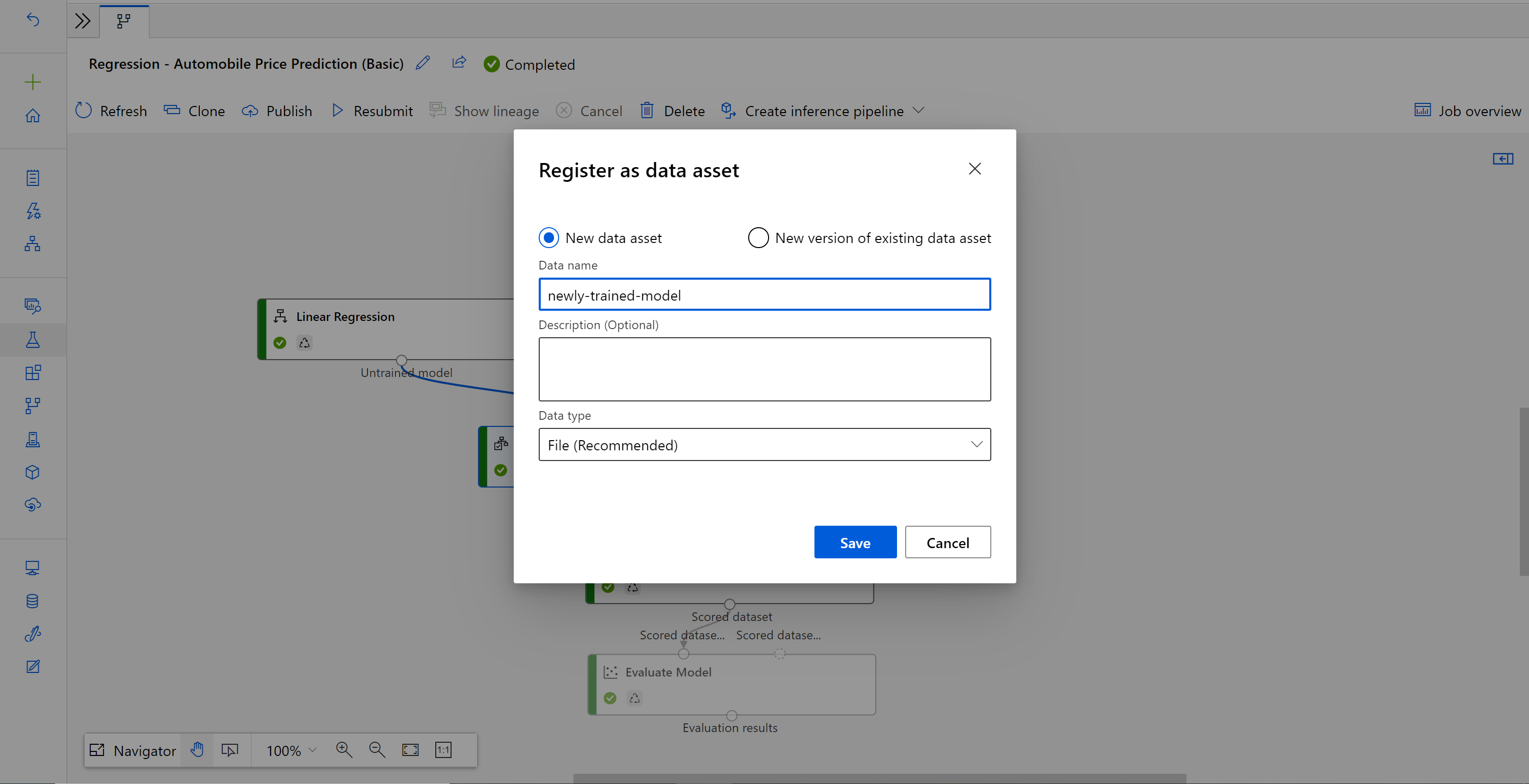
Leta reda på det tidigare pipelineutkastet för batchinferens, eller så kan du bara klona den publicerade pipelinen till ett nytt utkast.
Ersätt MD-noden i utkast till slutsatsdragningspipeline med registrerade data i steget ovan.
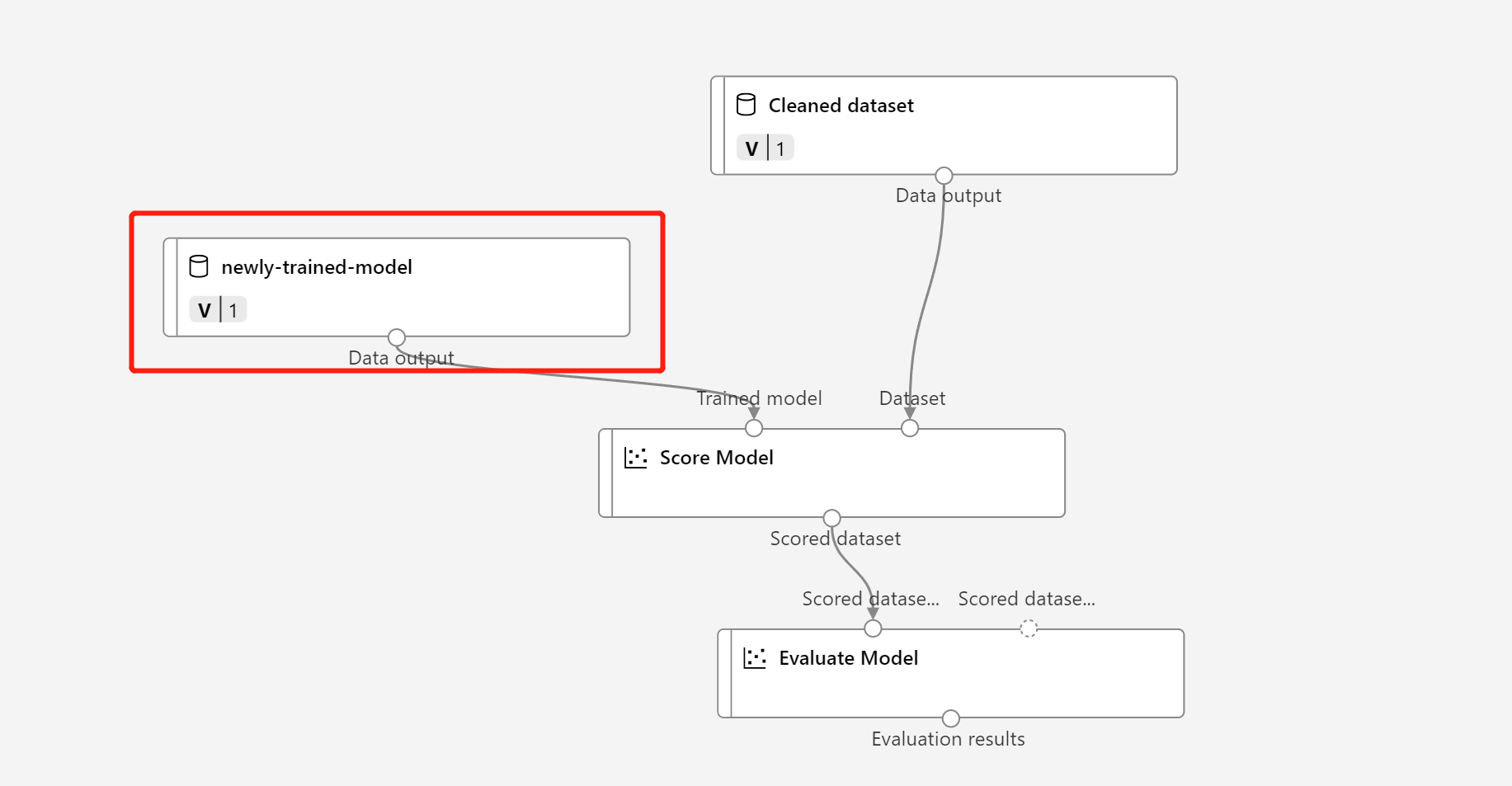
Uppdatering av datatransformeringsnodens TD – är samma som den tränade modellen.
Sedan kan du skicka in slutsatsdragningspipelinen med den uppdaterade modellen och omvandlingen och publicera igen.


Nästa steg
- Följ designguiden för att träna och distribuera en regressionsmodell.
- Information om hur du publicerar och kör en publicerad pipeline med hjälp av SDK v1 finns i artikeln Så här distribuerar du pipelines .