Utlösa Machine Learning-pipelines
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du programmatiskt schemalägger en pipeline som ska köras i Azure. Du kan skapa ett schema baserat på förfluten tid eller filsystemändringar. Tidsbaserade scheman kan användas för att ta hand om rutinuppgifter, till exempel övervakning av dataavvikelser. Ändringsbaserade scheman kan användas för att reagera på oregelbundna eller oförutsägbara ändringar, till exempel nya data som laddas upp eller gamla data som redigeras. När du har lärt dig hur du skapar scheman får du lära dig hur du hämtar och inaktiverar dem. Slutligen får du lära dig hur du använder andra Azure-tjänster, Azure Logic App och Azure Data Factory, för att köra pipelines. En Azure Logic App möjliggör mer komplex utlösande logik eller beteende. Med Azure Data Factory-pipelines kan du anropa en maskininlärningspipeline som en del av en större dataorkestreringspipeline.
Förutsättningar
En Azure-prenumeration. Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto.
En Python-miljö där Azure Mašinsko učenje SDK för Python installeras. Mer information finns i Skapa och hantera återanvändbara miljöer för träning och distribution med Azure Mašinsko učenje.
En Mašinsko učenje arbetsyta med en publicerad pipeline. Du kan använda den som är inbyggd i Skapa och köra maskininlärningspipelines med Azure Mašinsko učenje SDK.
Utlösa pipelines med Azure Mašinsko učenje SDK för Python
För att schemalägga en pipeline behöver du en referens till din arbetsyta, identifieraren för den publicerade pipelinen och namnet på experimentet där du vill skapa schemat. Du kan hämta dessa värden med följande kod:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Skapa en tidsplan
Om du vill köra en pipeline regelbundet skapar du ett schema. En Schedule associerar en pipeline, ett experiment och en utlösare. Utlösaren kan antingen vara enScheduleRecurrence som beskriver väntetiden mellan jobb eller en Datastore-sökväg som anger en katalog för att hålla utkik efter ändringar. I båda fallen behöver du pipelineidentifieraren och namnet på experimentet där schemat ska skapas.
Längst upp i Python-filen importerar du klasserna Schedule och ScheduleRecurrence :
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Skapa ett tidsbaserat schema
Konstruktorn ScheduleRecurrence har ett obligatoriskt frequency argument som måste vara en av följande strängar: "Minute", "Hour", "Day", "Week" eller "Month". Det kräver också ett heltalsargument interval som anger hur många av frequency enheterna som ska förflutit mellan schemastarterna. Med valfria argument kan du vara mer specifik om starttider, enligt beskrivningen i dokumentationen om ScheduleRecurrence SDK.
Skapa en Schedule som börjar ett jobb var 15:e minut:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Skapa ett ändringsbaserat schema
Pipelines som utlöses av filändringar kan vara effektivare än tidsbaserade scheman. När du vill göra något innan en fil ändras, eller när en ny fil läggs till i en datakatalog, kan du förbearbeta filen. Du kan övervaka ändringar i ett datalager eller ändringar i en specifik katalog i datalagringen. Om du övervakar en specifik katalog utlöser ändringar i underkataloger i katalogen inte ett jobb.
Kommentar
Ändringsbaserade scheman stöder endast övervakning av Azure Blob Storage.
Om du vill skapa en filreaktiv Schedulemåste du ange parametern datastore i anropet till Schedule.create. Om du vill övervaka en mapp anger du path_on_datastore argumentet.
Med polling_interval argumentet kan du i minuter ange hur ofta datalagringen ska kontrolleras efter ändringar.
Om pipelinen har konstruerats med en DataPath PipelineParameter kan du ange variabeln till namnet på den ändrade filen genom att ange data_path_parameter_name argumentet.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Valfria argument när du skapar ett schema
Förutom argumenten som beskrevs tidigare kan du ange status argumentet till för "Disabled" att skapa ett inaktivt schema. Slutligen continue_on_step_failure kan du skicka ett booleskt värde som åsidosätter pipelinens standardbeteende för fel.
Visa dina schemalagda pipelines
Gå till Azure Mašinsko učenje i webbläsaren. I avsnittet Slutpunkter i navigeringspanelen väljer du Pipeline-slutpunkter. Detta tar dig till en lista över pipelines som publicerats på arbetsytan.
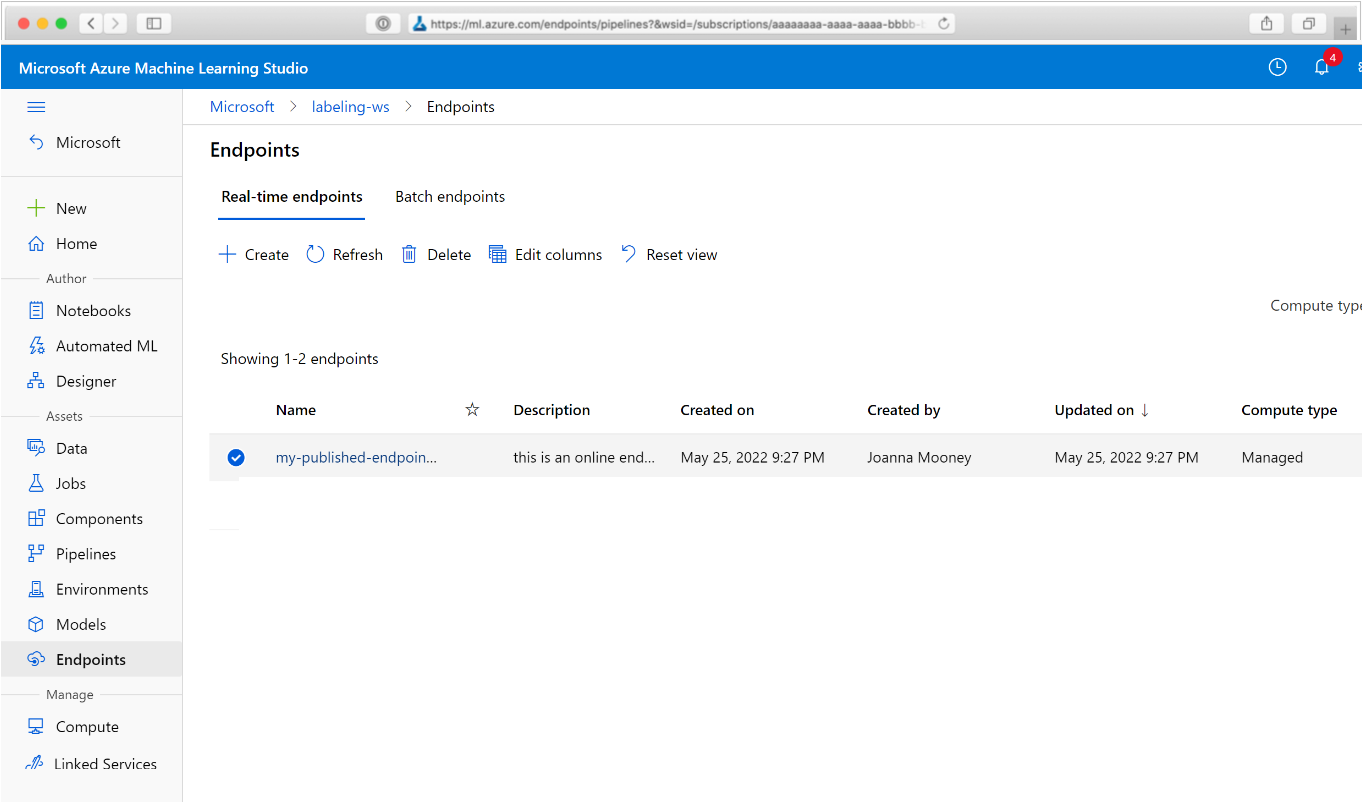
På den här sidan kan du se sammanfattningsinformation om alla pipelines på arbetsytan: namn, beskrivningar, status och så vidare. Öka detaljnivån genom att klicka i pipelinen. På den resulterande sidan finns mer information om din pipeline och du kan öka detaljnivån i enskilda jobb.
Inaktivera pipelinen
Om du har en Pipeline som har publicerats, men inte schemalagts, kan du inaktivera den med:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Om pipelinen är schemalagd måste du avbryta schemat först. Hämta schemats identifierare från portalen eller genom att köra:
ss = Schedule.list(ws)
for s in ss:
print(s)
När du har inaktiverat schedule_id kör du:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Om du sedan kör Schedule.list(ws) igen bör du få en tom lista.
Använda Azure Logic Apps för komplexa utlösare
Mer komplexa utlösarregler eller beteenden kan skapas med hjälp av en Azure Logic App.
Om du vill använda en Azure Logic App för att utlösa en Mašinsko učenje pipeline behöver du REST-slutpunkten för en publicerad Mašinsko učenje pipeline. Skapa och publicera din pipeline. Leta sedan reda på REST-slutpunkten för din PublishedPipeline med hjälp av pipeline-ID:t:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Skapa en logikapp i Azure
Skapa nu en Azure Logic App-instans . När logikappen har etablerats använder du de här stegen för att konfigurera en utlösare för din pipeline:
Skapa en systemtilldelad hanterad identitet för att ge appen åtkomst till din Azure Mašinsko učenje-arbetsyta.
Gå till vyn Logikappdesigner och välj mallen Tom logikapp.
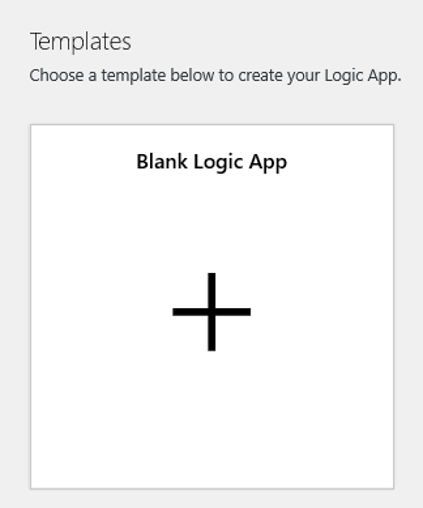
Sök efter blob i designern. Välj utlösaren När en blob läggs till eller ändras (endast egenskaper) och lägg till den här utlösaren i logikappen.
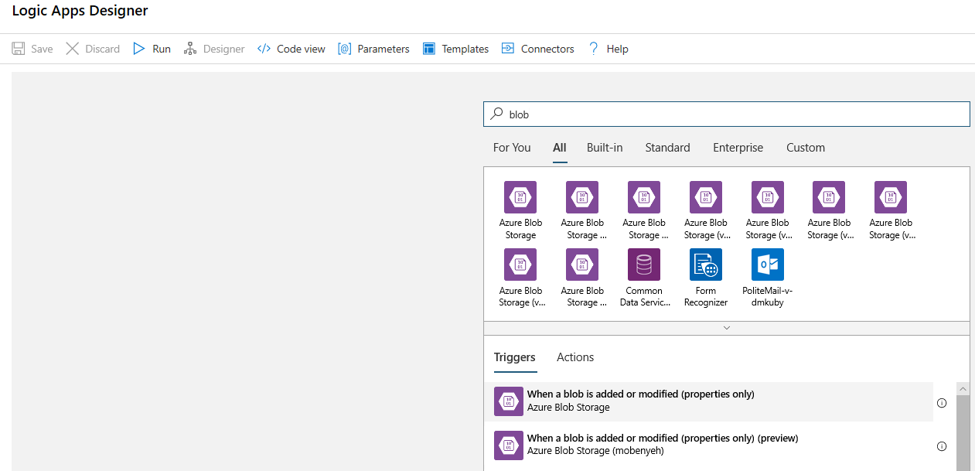
Fyll i anslutningsinformationen för det Blob Storage-konto som du vill övervaka för blobtillägg eller ändringar. Välj den container som ska övervakas.
Välj intervall och frekvens för att söka efter uppdateringar som fungerar åt dig.
Kommentar
Den här utlösaren övervakar den valda containern men övervakar inte undermappar.
Lägg till en HTTP-åtgärd som körs när en ny eller modifierad blob identifieras. Välj + Nytt steg och sök sedan efter och välj HTTP-åtgärden.
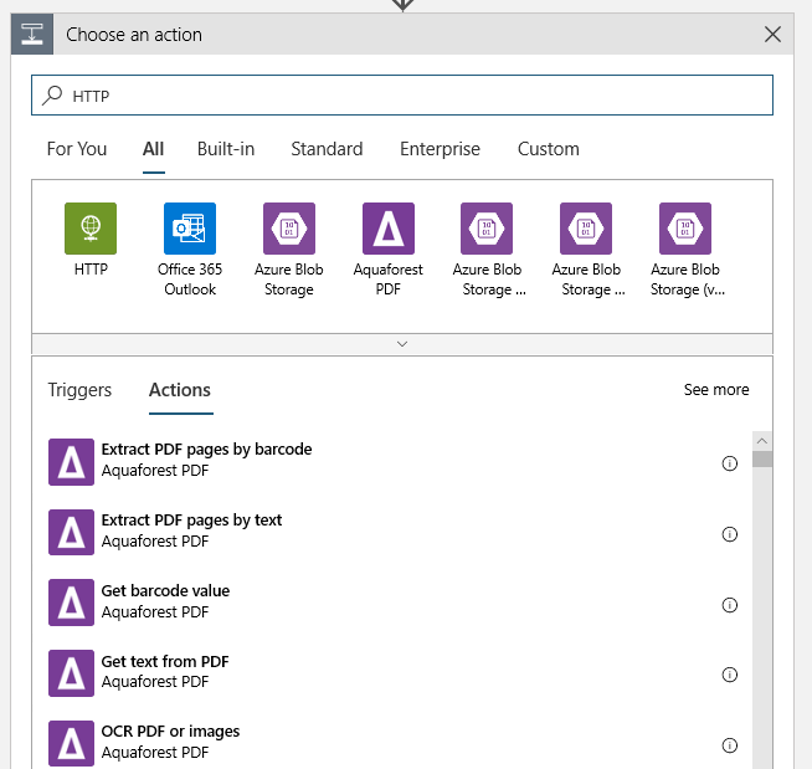
Använd följande inställningar för att konfigurera åtgärden:
| Inställning | Värde |
|---|---|
| HTTP-åtgärd | POST |
| URI | slutpunkten till den publicerade pipelinen som du hittade som en förutsättning |
| Autentiseringsläge | Hanterad identitet |
Konfigurera schemat för att ange värdet för alla DataPath PipelineParameters som du kan ha:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Använd den
DataStoreNamedu har lagt till på din arbetsyta som en förutsättning.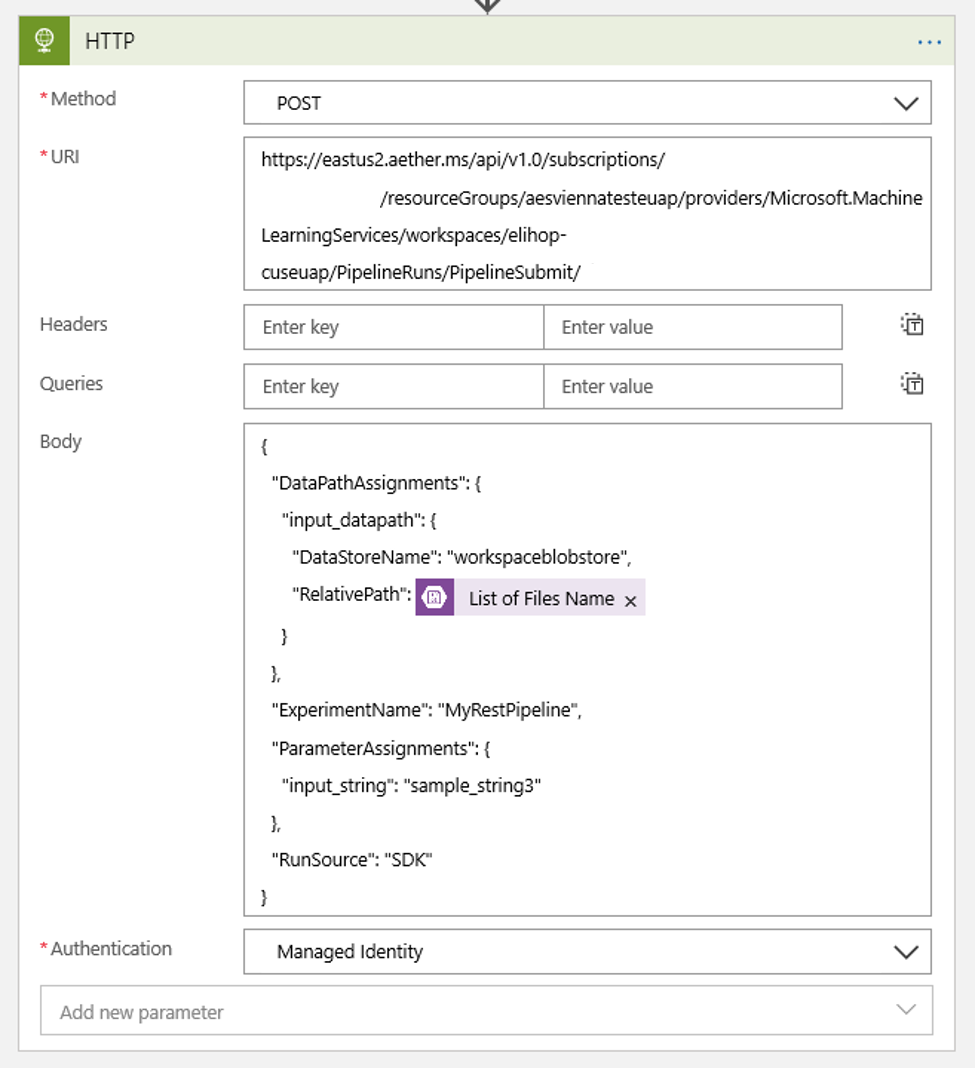
Välj Spara och ditt schema är nu klart.
Viktigt!
Om du använder rollbaserad åtkomstkontroll i Azure (Azure RBAC) för att hantera åtkomst till din pipeline anger du behörigheterna för pipelinescenariot (träning eller bedömning).
Anropa pipelines för maskininlärning från Azure Data Factory-pipelines
I en Azure Data Factory-pipeline kör aktiviteten Mašinsko učenje Execute Pipeline en Azure Mašinsko učenje pipeline. Du hittar den här aktiviteten på datafabrikens redigeringssida under kategorin Mašinsko učenje:
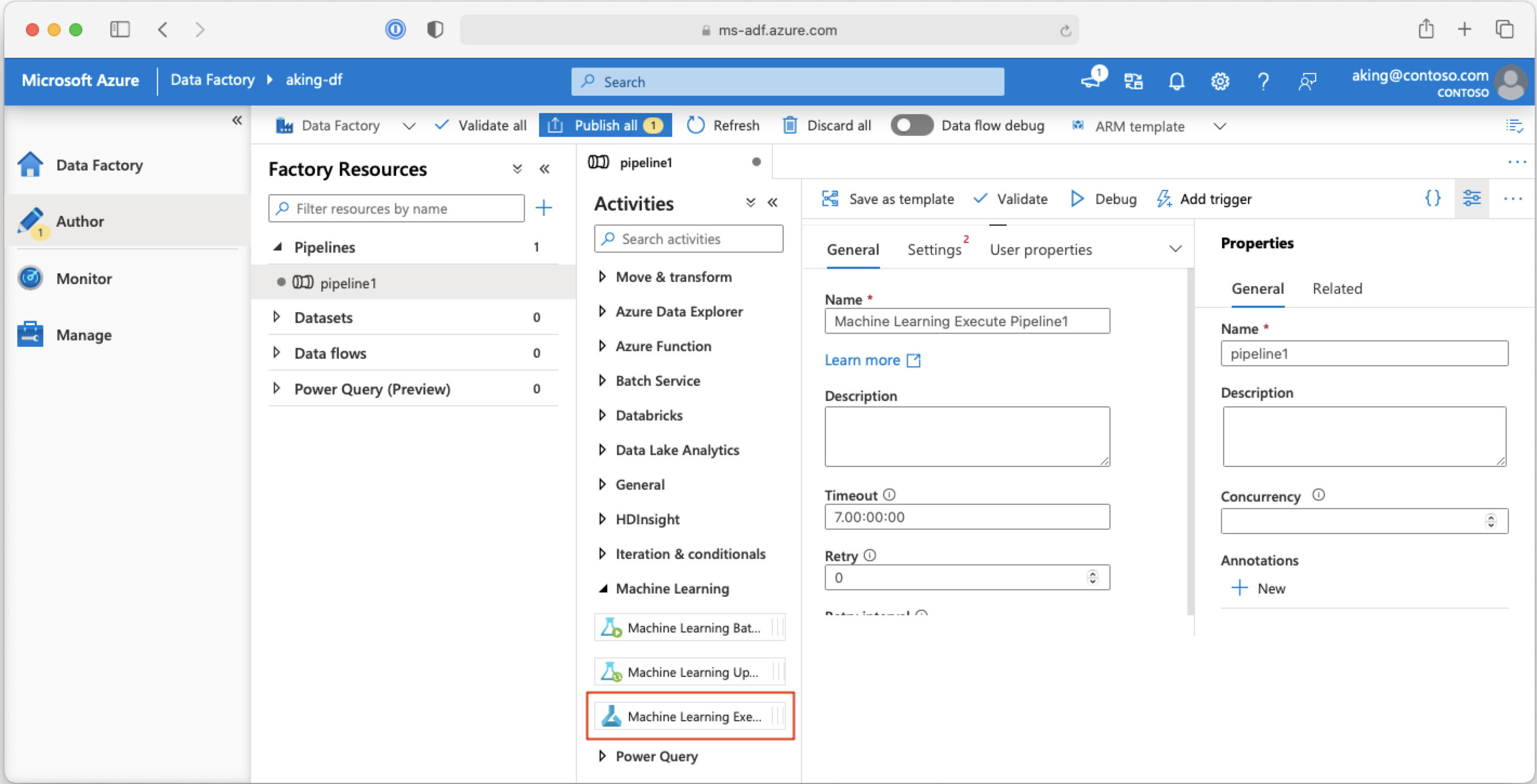
Nästa steg
I den här artikeln använde du Azure Mašinsko učenje SDK för Python för att schemalägga en pipeline på två olika sätt. Ett schema upprepas baserat på förfluten klocktid. De andra schemajobben om en fil ändras på en angiven Datastore eller i en katalog i det arkivet. Du såg hur du använder portalen för att undersöka pipelinen och enskilda jobb. Du har lärt dig hur du inaktiverar ett schema så att pipelinen slutar köras. Slutligen skapade du en Azure Logic App för att utlösa en pipeline.
Mer information finns i:
- Läs mer om pipelines
- Läs mer om att utforska Azure Mašinsko učenje med Jupyter
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för