Spåra ML-modeller med MLflow och Azure Mašinsko učenje
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du aktiverar MLflow Tracking för att ansluta Azure Mašinsko učenje som serverdel för dina MLflow-experiment.
MLflow är ett bibliotek med öppen källkod för att hantera livscykeln för dina maskininlärningsexperiment. MLflow Tracking är en komponent i MLflow som loggar och spårar dina träningskörningsmått och modellartefakter, oavsett experimentets miljö – lokalt på datorn, på ett fjärrberäkningsmål, en virtuell dator eller ett Azure Databricks-kluster.
Se MLflow och Azure Mašinsko učenje för alla MLflow- och Azure-Mašinsko učenje funktioner som stöds, inklusive stöd för MLflow-projekt (förhandsversion) och modelldistribution.
Dricks
Om du vill spåra experiment som körs på Azure Databricks eller Azure Synapse Analytics kan du läsa de dedikerade artiklarna Spåra Azure Databricks ML-experiment med MLflow och Azure Mašinsko učenje eller Spåra ML-experiment för Azure Synapse Analytics med MLflow och Azure Mašinsko učenje.
Kommentar
Informationen i det här dokumentet är främst avsedd för dataforskare och utvecklare som vill övervaka modellträningsprocessen. Om du är administratör och är intresserad av att övervaka resursanvändning och händelser från Azure Mašinsko učenje, till exempel kvoter, slutförda träningsjobb eller slutförda modelldistributioner, kan du läsa Övervaka Azure Mašinsko učenje.
Förutsättningar
Installera paketet
mlflow.- Du kan använda MLflow Skinny som är ett enkelt MLflow-paket utan SQL-lagring, server, användargränssnitt eller datavetenskapsberoenden. Detta rekommenderas för användare som främst behöver spårnings- och loggningsfunktionerna utan att importera hela paketet med MLflow-funktioner, inklusive distributioner.
Installera paketet
azureml-mlflow.Installera och konfigurera Azure Mašinsko učenje CLI (v1) och se till att du installerar ml-tillägget.
Viktigt!
Några av Azure CLI-kommandona i den här artikeln använder
azure-cli-mltillägget , eller v1, för Azure Mašinsko učenje. Stödet för v1-tillägget upphör den 30 september 2025. Du kommer att kunna installera och använda v1-tillägget fram till det datumet.Vi rekommenderar att du övergår till
mltillägget , eller v2, före den 30 september 2025. Mer information om v2-tillägget finns i Azure ML CLI-tillägget och Python SDK v2.Installera och konfigurera Azure Mašinsko učenje SDK för Python.
Spåra körningar från din lokala dator eller fjärrberäkning
Med hjälp av MLflow med Azure Mašinsko učenje kan du lagra loggade mått och artefakter som kördes på din lokala dator på din Azure Mašinsko učenje-arbetsyta.
Konfigurera spårningsmiljö
För att spåra en körning som inte körs på Azure Mašinsko učenje beräkning (från och med nu kallas "lokal beräkning") måste du peka din lokala beräkning till Azure Mašinsko učenje MLflow Tracking URI.
Kommentar
När du kör på Azure Compute (Azure Notebooks, Jupyter Notebooks som finns på Azure Compute Instances eller Compute Clusters) behöver du inte konfigurera spårnings-URI:n. Den konfigureras automatiskt åt dig.
GÄLLER FÖR: Python SDK azureml v1
Du kan hämta Azure Mašinsko učenje MLflow-spårnings-URI:n med hjälp av Azure Mašinsko učenje SDK v1 för Python. Kontrollera att biblioteket azureml-sdk är installerat i klustret som du använder. Följande exempel hämtar den unika MLFLow-spårnings-URI som är associerad med din arbetsyta. Sedan pekar metoden set_tracking_uri() MLflow-spårnings-URI:n till den URI:n.
Använd konfigurationsfilen för arbetsytan:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Dricks
Du kan ladda ned arbetsytans konfigurationsfil genom att:
- Gå till Azure Mašinsko učenje Studio
- Klicka på det överordnade högra hörnet på sidan –> Ladda ned konfigurationsfilen.
- Spara filen
config.jsoni samma katalog som du arbetar med.
Använd prenumerations-ID, resursgruppsnamn och arbetsytenamn:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Ange experimentnamn
Alla MLflow-körningar loggas till det aktiva experimentet. Som standard loggas körningar till ett experiment med namnet Default som skapas automatiskt åt dig. För att konfigurera experimentet som du vill arbeta med använder du MLflow-kommandot mlflow.set_experiment().
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Dricks
När du skickar jobb med Azure Mašinsko učenje SDK kan du ange experimentnamnet med hjälp av egenskapen experiment_name när du skickar det. Du behöver inte konfigurera det i träningsskriptet.
Starta träningskörning
När du har angett MLflow-experimentnamnet kan du starta träningskörningen med start_run(). Använd log_metric() sedan för att aktivera MLflow-loggnings-API:et och börja logga dina träningskörningsmått.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Mer information om hur du loggar mått, parametrar och artefakter i en körning med MLflow-vyn Så här loggar och visar du mått.
Spåra körningar som körs på Azure Mašinsko učenje
GÄLLER FÖR: Python SDK azureml v1
Med fjärrkörningar (jobb) kan du träna dina modeller på ett mer robust och repetitivt sätt. De kan också använda mer kraftfulla beräkningar, till exempel Mašinsko učenje Compute-kluster. Mer information om olika beräkningsalternativ finns i Använda beräkningsmål för modellträning .
När du skickar körningar konfigurerar Azure Mašinsko učenje automatiskt MLflow så att det fungerar med arbetsytan som körningen körs i. Det innebär att du inte behöver konfigurera URI:n för MLflow-spårning. Dessutom namnges experiment automatiskt baserat på information om experimentöverföringen.
Viktigt!
När du skickar träningsjobb till Azure Mašinsko učenje behöver du inte konfigurera URI:n för MLflow-spårning på din träningslogik eftersom den redan har konfigurerats åt dig. Du behöver inte heller konfigurera experimentnamnet i träningsrutinen.
Skapa en träningsrutin
Först bör du skapa en src underkatalog och skapa en fil med träningskoden i en train.py fil i underkatalogen src . All träningskod kommer att gå till underkatalogen src , inklusive train.py.
Träningskoden hämtas från det här MLflow-exemplet i Azure Mašinsko učenje exempellagringsplats.
Kopiera den här koden till filen:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Konfigurera experimentet
Du måste använda Python för att skicka experimentet till Azure Mašinsko učenje. Konfigurera din beräknings- och träningskörningsmiljö med Environment klassen i en notebook- eller Python-fil.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
ScriptRunConfig Skapa sedan med fjärrberäkningen som beräkningsmål.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Med den här konfigurationen Experiment.submit() för beräknings- och träningskörningar använder du metoden för att skicka en körning. Den här metoden anger automatiskt MLflow-spårnings-URI:n och dirigerar loggningen från MLflow till din arbetsyta.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Visa mått och artefakter på din arbetsyta
Mått och artefakter från MLflow-loggning spåras på din arbetsyta. Om du vill visa dem när som helst går du till din arbetsyta och hittar experimentet efter namn på din arbetsyta i Azure Mašinsko učenje studio. Eller kör koden nedan.
Hämta körningsmått med MLflow get_run().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Om du vill visa artefakterna för en körning kan du använda MlFlowClient.list_artifacts()
client.list_artifacts(run_id)
Om du vill ladda ned en artefakt till den aktuella katalogen kan du använda MLFlowClient.download_artifacts()
client.download_artifacts(run_id, "helloworld.txt", ".")
Mer information om hur du hämtar information från experiment och körs i Azure Mašinsko učenje med MLflow-vyn Hantera experiment och körningar med MLflow.
Jämför och fråga
Jämför och fråga alla MLflow-körningar i din Azure Mašinsko učenje-arbetsyta med följande kod. Läs mer om hur du kör frågor mot körningar med MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Automatisk loggning
Med Azure Mašinsko učenje och MLFlow kan användarna logga mått, modellparametrar och modellartefakter automatiskt när de tränar en modell. En mängd populära maskininlärningsbibliotek stöds.
Om du vill aktivera automatisk loggning infogar du följande kod före träningskoden:
mlflow.autolog()
Läs mer om automatisk loggning med MLflow.
Hantera modeller
Registrera och spåra dina modeller med Azure Mašinsko učenje-modellregistret, som stöder MLflow-modellregistret. Azure Mašinsko učenje-modeller är anpassade till MLflow-modellschemat, vilket gör det enkelt att exportera och importera dessa modeller i olika arbetsflöden. MLflow-relaterade metadata, till exempel körnings-ID, spåras också med den registrerade modellen för spårning. Användare kan skicka träningskörningar, registrera och distribuera modeller som skapats från MLflow-körningar.
Om du vill distribuera och registrera din produktionsklara modell i ett steg kan du läsa Distribuera och registrera MLflow-modeller.
Om du vill registrera och visa en modell från en körning använder du följande steg:
När en körning är klar anropar du
register_model()metoden.# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Visa den registrerade modellen på din arbetsyta med Azure Mašinsko učenje studio.
I följande exempel har den registrerade modellen
my-modelMLflow-spårningsmetadata taggade.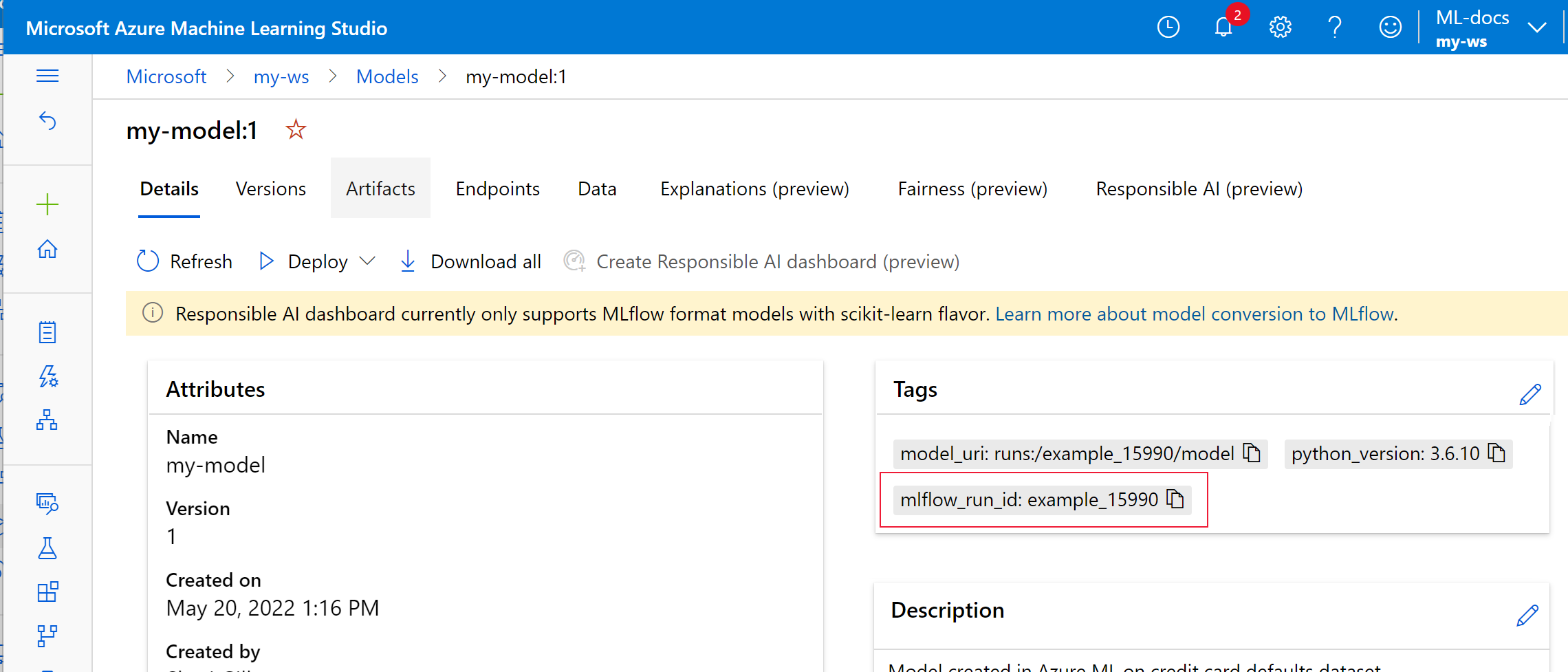
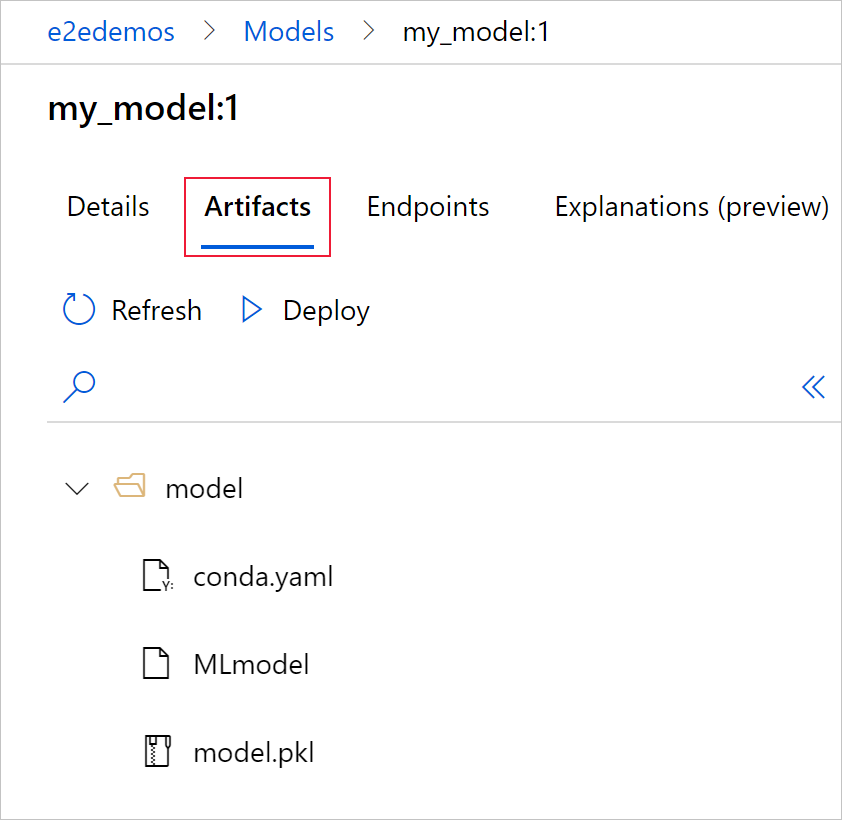
Välj fliken Artefakter för att se alla modellfiler som överensstämmer med MLflow-modellschemat (conda.yaml, MLmodel, model.pkl).
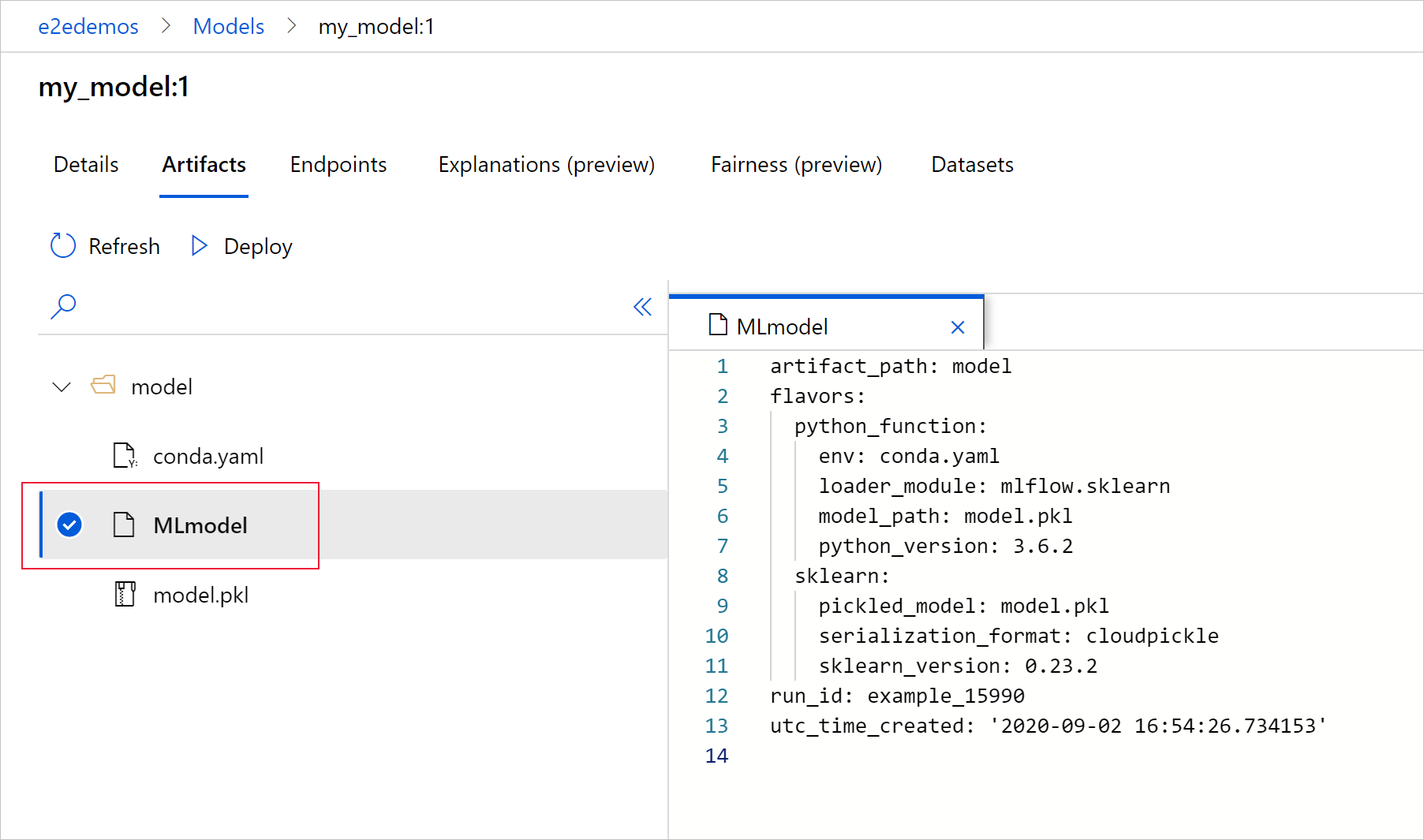
Välj MLmodel för att se MLmodel-filen som genereras av körningen.
Rensa resurser
Om du inte planerar att använda de loggade måtten och artefakterna på din arbetsyta är möjligheten att ta bort dem individuellt för närvarande inte tillgänglig. Ta i stället bort resursgruppen som innehåller lagringskontot och arbetsytan, så att du inte debiteras några avgifter:
I Azure-portalen väljer du Resursgrupper längst till vänster.
Välj den resursgrupp i listan som du har skapat.
Välj Ta bort resursgrupp.
Ange resursgruppsnamnet. Välj sedan ta bort.
Exempelnotebook-filer
MLflow med Azure Mašinsko učenje notebook-filer visar och utökar begrepp som presenteras i den här artikeln. Se även den communitydrivna lagringsplatsen AzureML-Examples.
Nästa steg
- Distribuera modeller med MLflow.
- Övervaka dina produktionsmodeller för dataavvikelse.
- Spåra Azure Databricks-körningar med MLflow.
- Hantera dina modeller.