Skapa ditt första datavetenskapsexperiment i Machine Learning Studio (klassisk)
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
I den här artikeln skapar du ett maskininlärningsexperiment i Machine Learning Studio (klassisk) som förutsäger priset på en bil baserat på olika variabler som märke och tekniska specifikationer.
Om maskininlärning är nytt för dig är videoserien Datavetenskap för nybörjare en bra introduktion som med enkelt språk förklarar vad maskininlärning är.
Den här snabbstarten följer standardarbetsflödet för ett experiment:
- Skapa en modell
- Träna modellen
- Poängsätta och testa modellen
Hämta data
Det första du behöver för maskininlärning är data. Det finns flera exempeldatauppsättningar som ingår i Studio (klassisk) som du kan använda, eller så kan du importera data från många källor. I det här exemplet kommer vi att använda exempeluppsättningen Automobile price data (Raw), som ingår i arbetsytan. Den här datauppsättningen innehåller poster för ett antal olika bilar, inklusive uppgifter om modell, tekniska specifikationer och pris.
Tips
En arbetskopia av följande experiment finns i Azure AI-galleriet. Gå till Ditt första datavetenskapsexperiment – Förutsägelse av bilpriser och klicka på Öppna i Studio för att ladda ned en kopia av experimentet till din Machine Learning Studio-arbetsyta (klassisk).
Så här gör du för att få datauppsättningen till experimentet.
Skapa ett nytt experiment genom att klicka på +NYTT längst ned i Fönstret Machine Learning Studio (klassisk). Välj Experiment>Tomt experiment.
Experimentet får ett standardnamn som visas överst i arbetsytan. Markera texten och byt namn på den till ett mer beskrivande namn, exempelvis Förutsägelse av bilpriser. Namnet behöver inte vara unikt.
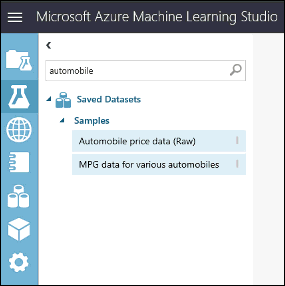
Till vänster om arbetsytan för experimentet finns en palett med datauppsättningar och moduler. Skriv automobile i sökrutan överst på den här paletten för att leta upp datauppsättningen Automobile price data (Raw). Dra datauppsättningen till experimentarbetsytan.
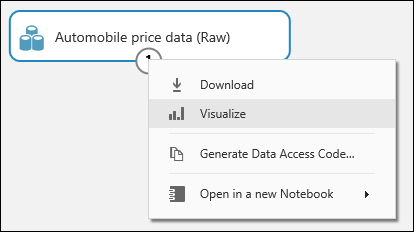
Om du vill se hur den här informationen ser ut klickar du på utdataporten längst ned i datamängden för bilar och väljer Visualisera.
Tips
Datauppsättningar och moduler har ingångs- och utgångsportar som representeras av små cirklar – ingångsportar högst upp och utgångsportar längst ned. Om du vill skapa ett flöde av data via ditt experiment ansluter du en utgångsport från en modul till en port på en annan. Du kan när som helst klicka på en datauppsättnings eller moduls utgångsport för att se hur dina data ser ut vid den tidpunkten i dataflödet.
I den här datamängden representerar varje rad en bil, och de variabler som är associerade med varje bil visas som kolumner. Vi förutsäger priset i kolumnen längst till höger (kolumn 26, ”price” (pris)) med hjälp av variablerna för en specifik bil.
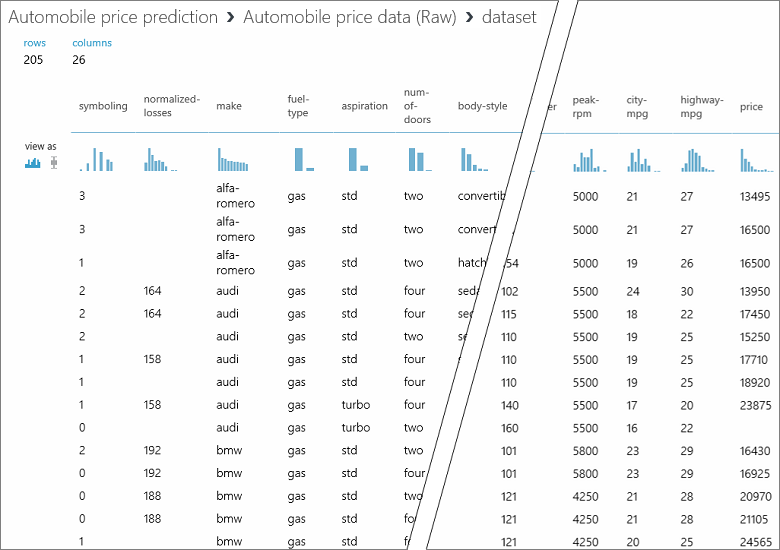
Stäng visualiseringsfönstret genom att klicka på ”x” i det övre högra hörnet.
Förbereda data
En datauppsättning kräver vanligtvis viss bearbetning i förväg innan den kan analyseras. Du kanske har lagt märke till värdena som saknas i kolumnerna på olika rader. Dessa värden som saknas måste rensas bort så att modellen kan analysera informationen korrekt. Vi tar bort alla rader som har saknade värden. Dessutom har kolumnen normalized-losses många värden som saknas, så vi ska utesluta kolumnen från modellen helt och hållet.
Tips
Du måste rensa värden som saknas i indata för att kunna använda de flesta moduler.
Först lägger vi till en modul som tar bort kolumnen normalized-losses helt. Sedan lägger vi till en till modul som tar bort rader där data saknas.
Skriv välj kolumner i sökrutan överst på modulpaletten för att leta upp modulen Välj kolumner i datamängd. Dra den sedan till experimentarbetsytan. Den här modulen gör att vi kan välja vilka kolumner med data som vi vill ta med eller utelämna i modellen.
Anslut utdataporten för datauppsättningen Automobile price data (Raw) till indataporten för Välj kolumner i datauppsättningen.
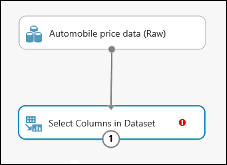
Klicka på modulen Välj kolumner i datauppsättning och klicka på Starta kolumnväljaren i rutan Egenskaper.
Klicka på Med regler till vänster.
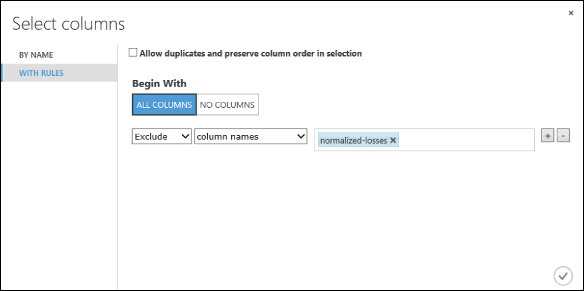
Under Börjar med klickar du på Alla kolumner. De här reglerna instruerar Välj kolumner i datamängd att gå igenom alla kolumner (förutom dem som vi ska utesluta).
I listrutorna väljer du Exkludera och kolumnnamn och klickar sedan i textrutan. En lista med kolumner visas. Välj normalized-losses så läggs den till i textrutan.
Stäng kolumnväljaren genom att klicka på bockmarkeringen (OK) längst ned till höger.
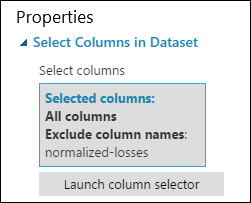
Egenskapsrutan för Välj kolumner i datauppsättning anger nu att alla kolumner i datauppsättningen tas med utom normalized-losses.
Tips
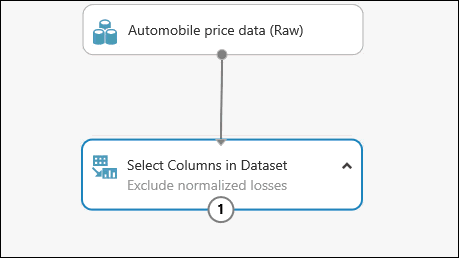
Du kan lägga till en kommentar till en modul genom att dubbelklicka på modulen och skriva text. På så sätt kan du snabbt se vad modulen gör i experimentet. I vårt exempel dubbelklickar du på modulen Välj kolumner i datauppsättning och skriver kommentaren ”Exkludera normaliserade förluster”.
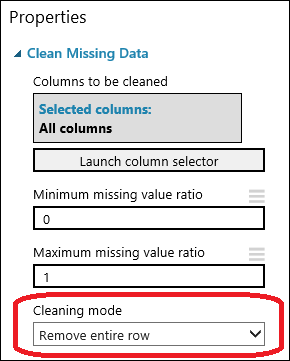
Dra modulen Rensa data som saknas till experimentarbetsytan och anslut den till modulen Välj kolumner i datauppsättning. I fönstret Egenskaper väljer du Ta bort hela raden under Rensningsläge. De här alternativen instruerar modulen Rensa data som saknas att rensa data genom att ta bort rader som har saknade värden. Dubbelklicka på modulen och skriv kommentaren ”Ta bort rader med värden som saknas”.
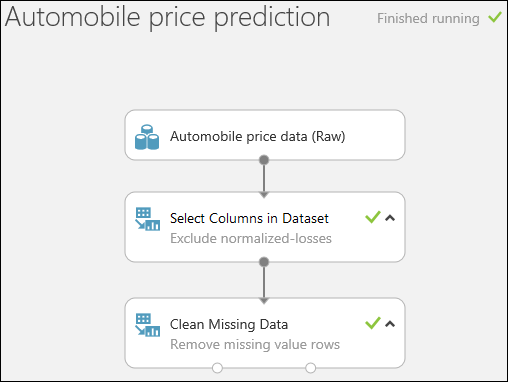
Kör försöket genom att klicka på KÖR längst ned på sidan.
När experimentet är klart visas alla moduler med en grön bockmarkering som bekräftar att de har slutförts. Notera också statusen Har slutförts i det övre högra hörnet.
Tips
Varför kör vi experimentet nu? När experimentet körs överförs kolumndefinitionerna för våra data från datauppsättningen genom modulen Välj kolumner i datauppsättning och genom modulen Rensa data som saknas. Detta innebär att alla moduler som vi ansluter till Rensa data som saknas får samma information.
Nu har vi rena data. Om du vill visa den rensade datauppsättningen klickar du på den vänstra indataporten för modulen Rensa data som saknas och väljer Visualisera. Observera att kolumnen normalized-losses inte längre ingår och att det inte finns några värden som saknas.
Nu när vi har rensat bort data kan vi ange vilka funktioner som vi vill använda i förutsägelsemodellen.
Definiera funktioner
I maskininlärning är funktioner enskilda mätbara egenskaper för något du är intresserad av. I vår datauppsättning representerar varje rad en bil och varje kolumn är en funktion i den bilen.
Det krävs en del experimenterande och kunskap om det problem som ska lösas för att hitta en bra uppsättning funktioner för att skapa en förutsägelsemodell. Vissa funktioner är bättre för att förutsäga målet än andra. Vissa funktioner har en stark korrelation med andra funktioner och kan tas bort. Till exempel är city-mpg och highway-mpg nära relaterade så att vi kan behålla en och ta bort den andra utan att förutsägelsen påverkas avsevärt.
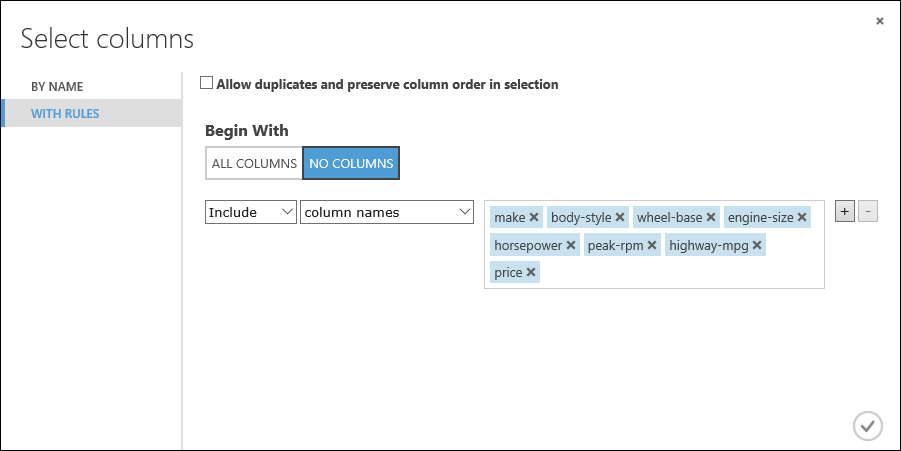
Vi ska skapa en modell som använder en delmängd av funktionerna i vår datauppsättning. Du kan komma tillbaka senare och välja andra funktioner, köra experimentet igen och se om du får bättre resultat. Men om du vill starta ska du prova följande funktioner:
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Dra en till modul av typen Välj kolumner i datauppsättning till experimentarbetsytan. Anslut den vänstra utdataporten för modulen Rensa data som saknas till indataporten för modulen Välj kolumner i datauppsättning.
Dubbelklicka på modulen och skriv ”Välj funktioner för förutsägelse”.
Klicka på Starta kolumnväljaren i fönstret Egenskaper.
Klicka på Med regler.
Under Börjar med klickar du på Inga kolumner. I filterraden väljer du Inkludera och kolumnnamn och markerar listan över kolumnnamn i textrutan. Det här filtret instruerar modulen att bara ta med de kolumner (funktioner) som vi anger.
Klicka på bockmarkeringen (OK).
Den här modulen skapar en filtrerad datamängd som enbart innehåller de funktioner vi vill skicka till den inlärningsalgoritm som vi använder i nästa steg. Du kan komma tillbaka senare och försöka igen med andra funktioner.
Välja och tillämpa en algoritm
Nu när våra data är klara är det dags att gå vidare och träna och testa vår förutsägelsemodell. Vi ska använda våra data för att träna modellen och sedan testa den för att se hur väl den kan förutsäga priser.
Klassificering och regression är två typer av övervakade Machine Learning-algoritmer. Klassificering förutsäger ett svar från en definierad uppsättning kategorier, till exempel en färg (röd, blå eller grön). Regression används för att förutsäga ett tal.
Eftersom vi vill förutsäga pris, vilket är ett tal, använder vi en regressionsalgoritm. I det här exemplet använder vi en linjär regressionsmodell.
Vi tränar modellen genom att ge den en uppsättning data som innehåller priset. Modellen söker efter data och letar efter samband mellan en bils funktioner och dess pris. Därefter testar vi modellen – den får en uppsättning funktioner för bilar vi känner till, så vi kan se hur nära modellen kommer att förutsäga det kända priset.
Vi använder våra data både för träning och testning av modellen genom att dela in data i separata tränings- och testningsdatauppsättningar.
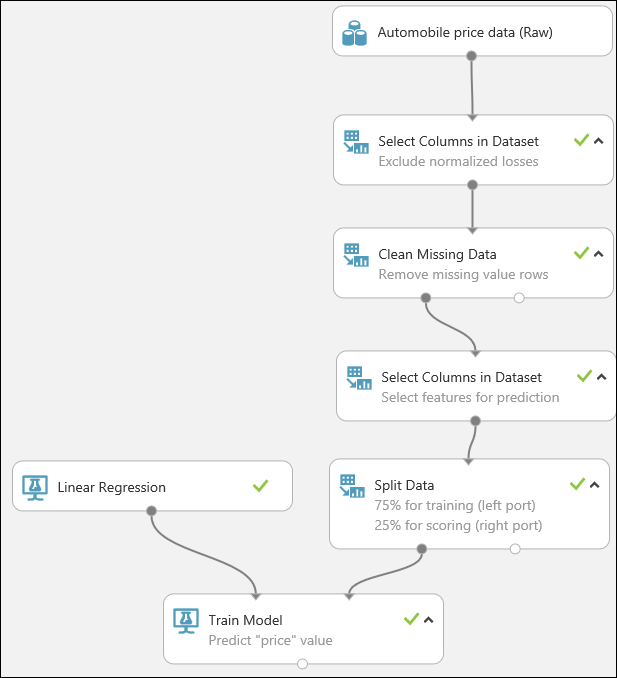
Markera och dra modulen Dela data till experimentarbetsytan och anslut den till den sista modulen av typen Välj kolumner i datauppsättning.
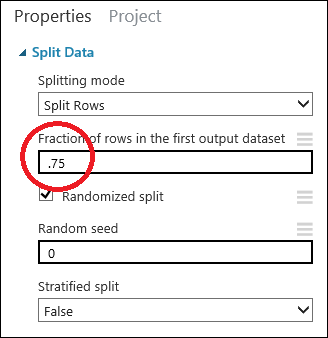
Klicka på modulen Dela data för att välja den. Leta upp Del av rader i den första utdatauppsättningen (i fönstret Egenskaper på höger sida i arbetsytan) och ange 0,75. På så sätt kan vi använda 75 procent av våra data för att träna modellen, och lämna 25 procent för testning.
Tips
Genom att ändra parametern Slumptal kan du generera olika slumpmässiga prov för träning och testning. Den här parametern styr den pseudoslumpmässiga talgeneratorns startvärden (seeding).
Kör experimentet. När experimentet har körts överför modulerna Välj kolumner i datauppsättning och Dela data kolumndefinitionerna till de moduler som vi ska lägga till härnäst.
Välj inlärningsalgoritmen genom att expandera kategorin Machine Learning på modulpaletten till vänster om arbetsytan och expandera Initiera modell. Nu visas flera kategorier av moduler som kan användas för att initiera algoritmer för maskininlärning. I det här experimentet väljer du modulen Linjär regression under kategorin Regression och drar den till arbetsytan för experimentet. (Du kan också hitta modulen genom att skriva "linjär regression" i rutan Sök på paletten.)
Leta upp och dra modulen Träna modell till arbetsytan för experimentet. Anslut utdataporten för modulen Linjär regression till den vänstra indataporten för modulen Träna modell och anslut träningsresultatet (vänster port) för modulen Dela data till den högra indatasporten för modulen Träna modell.
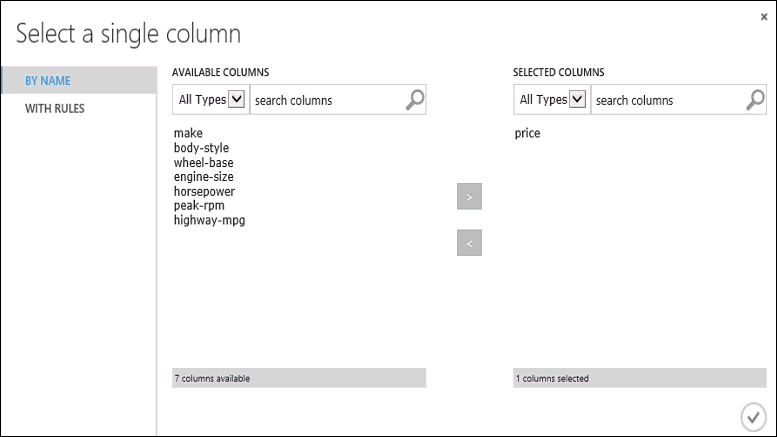
Klicka på modulen Träna modell, klicka på Starta kolumnväljaren i rutan Egenskaper och välj kolumnen price. Pris är det värde som vår modell ska förutsäga.
Du väljer priskolumnen i kolumnväljaren genom att dra den från listan över tillgängliga kolumner till listan över markerade kolumner.
Kör experimentet.
Nu har vi en tränad regressionsmodell som kan användas för att poängsätta nya bildata för att göra prisförutsägelser.
Förutsäga nya bilpriser
Nu när vi har tränat modellen med 75 procent av våra data kan vi använda den för att bedöma de övriga 25 procenten av dessa data och se hur bra vår modell fungerar.
Leta upp och dra modulen Poängsätta modell till arbetsytan för experimentet. Anslut utdataporten för modulen Träna modell till den vänstra indataporten för Poängsätta modell. Anslut utdataporten för testning (den högra porten) för modulen Dela data till den högra indataporten för Poängsätta modell.
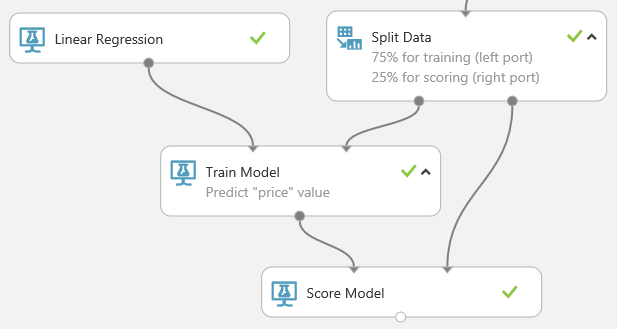
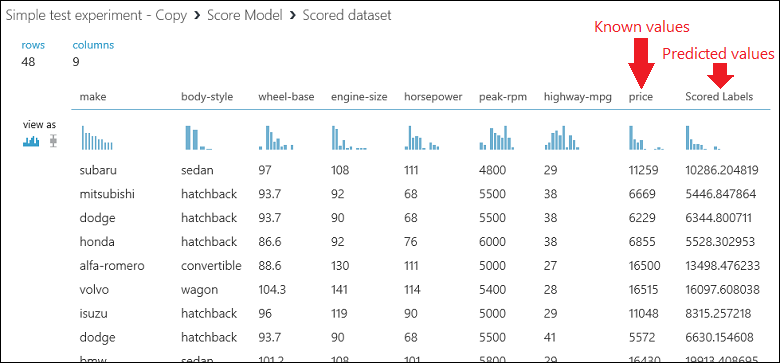
Kör experimentet och visa utdata från modulen Poängsätta modell genom att klicka på utdataporten för Poängsätta modell och välja Visualisera. Utdata innehåller de förväntade värdena för pris och de kända värdena från testdata.
Slutligen testar vi resultatets kvalitet. Markera och dra modulen Utvärdera modell till experimentarbetsytan och anslut utdataporten för modulen Poängsätta modell till den vänstra indataporten för Utvärdera modell. Det slutliga experimentet bör se ut ungefär så här:
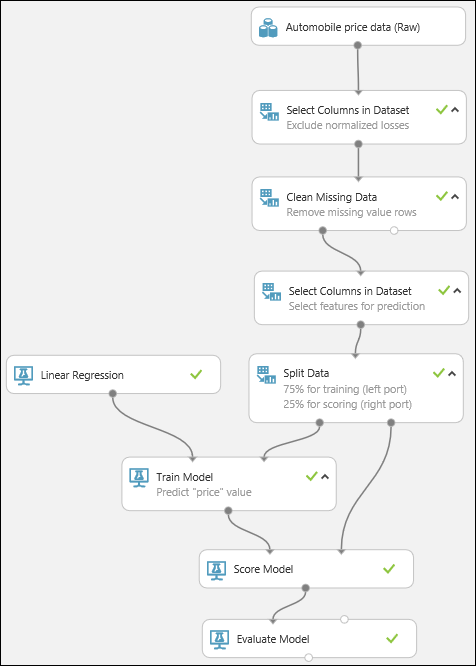
Kör experimentet.
Du visar utdata från modulen Utvärdera modell genom att klicka på utdataporten och sedan välja Visualisera.
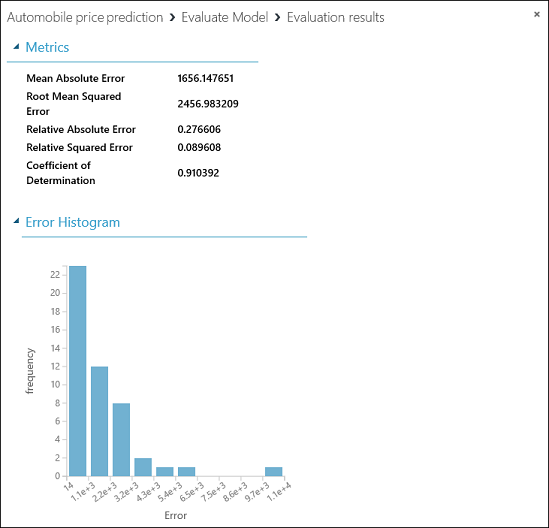
För vår modell visas följande statistik:
- Medelabsolutfel (MAE): Medelvärdet av absoluta fel (ett fel är skillnaden mellan det förväntade och faktiska värdet).
- Medelkvadratfel (RMSE): Kvadratroten av genomsnittet av kvadratfel i förutsägelser som görs mot testdatauppsättningen.
- Relativa absoluta fel: Medelvärdet av absoluta fel i förhållande till den absoluta skillnaden mellan faktiska värden och medelvärdet av alla faktiska värden.
- Relativa kvadratfel: Medelvärdet av kvadratfel i förhållande till kvadratskillnaden mellan faktiska värden och medelvärdet av alla faktiska värden.
- Bestämningskoefficient: Kallas också för R-kvadratvärdet och är ett statistiskt mått som anger hur väl en modell passar data.
För all felstatistik gäller att mindre är bättre. Ett mindre värde anger att förutsägelser bättre överensstämmer med de faktiska värdena. För bestämningskoefficient är förutsägelserna bättre ju närmare värdet är ett (1,0).
Rensa resurser
Om du inte behöver de resurser som du skapade i den här artikeln kan du ta bort dem så att du undviker eventuella kostnader. Det kan du lära dig i artikeln om att exportera och ta bort användardata i produkten.
Nästa steg
I den här snabbstarten skapade du ett enkelt experiment med hjälp av en exempeldatamängd. Fortsätt till självstudien om en förutsägande lösning för att utforska processen med att skapa och distribuera en modell i närmare detalj.