Köra Python-maskininlärningsskript i Machine Learning Studio (klassisk)
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Python är ett värdefullt verktyg i verktygslådan för många dataexperter. Den används i varje steg i typiska arbetsflöden för maskininlärning, inklusive datautforskning, extrahering av funktioner, modellträning och validering samt distribution.
Den här artikeln beskriver hur du kan använda modulen Kör Python-skript för att använda Python-kod i dina Machine Learning Studio-experiment (klassiska) och webbtjänster.
Använda modulen Execute Python Script (Kör Python-skript)
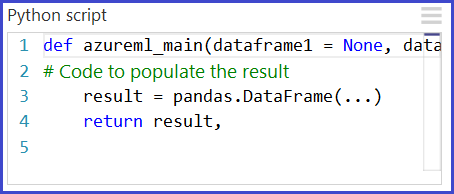
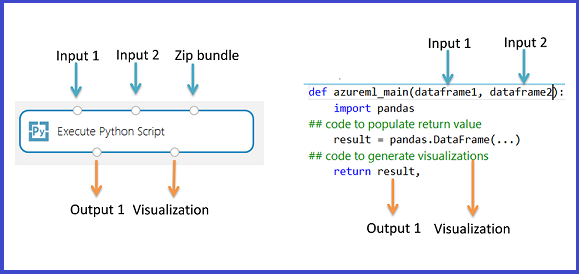
Det primära gränssnittet till Python i Studio (klassisk) är via modulen Kör Python-skript . Den accepterar upp till tre indata och ger upp till två utdata, ungefär som modulen Execute R Script (Kör R-skript). Python-kod anges i parameterrutan via en särskilt namngiven startpunktsfunktion med namnet azureml_main.
Indataparametrar
Indata till Python-modulen exponeras som Pandas DataFrames. Funktionen azureml_main accepterar upp till två valfria Pandas DataFrames som parametrar.
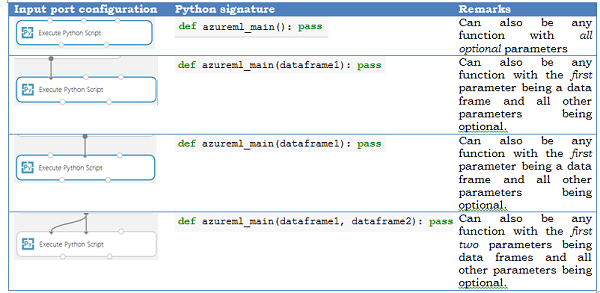
Mappningen mellan indataportar och funktionsparametrar är positionell:
- Den första anslutna indataporten mappas till den första parametern i funktionen.
- Den andra indatan (om den är ansluten) mappas till den andra parametern i funktionen.
- Den tredje indata används för att importera ytterligare Python-moduler.
Mer detaljerad semantik för hur indataportarna mappas till parametrar för azureml_main funktionen visas nedan.
Returvärden för utdata
Funktionen azureml_main måste returnera en enda Pandas DataFrame paketerad i en Python-sekvens , till exempel en tuppel, lista eller NumPy-matris. Det första elementet i den här sekvensen returneras till modulens första utdataport. Den andra utdataporten för modulen används för visualiseringar och kräver inget returvärde. Det här schemat visas nedan.
Översättning av in- och utdatatyper
Studio-datauppsättningar är inte samma som Panda DataFrames. Därför konverteras indatauppsättningar i Studio (klassisk) till Pandas DataFrame och utdatadataramar konverteras tillbaka till Studio-datauppsättningar (klassiska). Under den här konverteringsprocessen utförs även följande översättningar:
| Python-datatyp | Översättningsprocedur för Studio |
|---|---|
| Strängar och numeriska värden | Översatt som är |
| Pandas "NA" | Översatt som "Värde saknas" |
| Indexvektorer | Stöds inte* |
| Kolumnnamn som inte är strängar | Anropa str kolumnnamn |
| Duplicera kolumnnamn | Lägg till numeriskt suffix: (1), (2), (3) och så vidare. |
*Alla indataramar i Python-funktionen har alltid ett 64-bitars numeriskt index från 0 till antalet rader minus 1
Importera befintliga Python-skriptmoduler
Serverdelen som används för att köra Python baseras på Anaconda, en allmänt använd vetenskaplig Python-distribution. Det levereras med nästan 200 av de vanligaste Python-paketen som används i datacentrerade arbetsbelastningar. Studio (klassisk) stöder för närvarande inte användning av pakethanteringssystem som Pip eller Conda för att installera och hantera externa bibliotek. Om du upptäcker behovet av att lägga till ytterligare bibliotek använder du följande scenario som en guide.
Ett vanligt användningsfall är att införliva befintliga Python-skript i Studio-experiment (klassiska). Modulen Execute Python Script (Kör Python-skript) accepterar en zip-fil som innehåller Python-moduler på den tredje indataporten. Filen packas upp av körningsramverket vid körning och innehållet läggs till i bibliotekssökvägen för Python-tolken. Startpunktsfunktionen azureml_main kan sedan importera dessa moduler direkt.
Anta till exempel att filen Hello.py innehåller en enkel "Hello, World"-funktion.
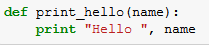
Sedan skapar vi en fil Hello.zip som innehåller Hello.py:

Ladda upp zip-filen som en datauppsättning till Studio (klassisk). Skapa och kör sedan ett experiment som använder Python-koden i Hello.zip-filen genom att koppla den till den tredje indataporten för modulen Kör Python-skript enligt följande bild.
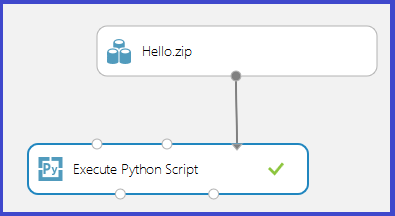
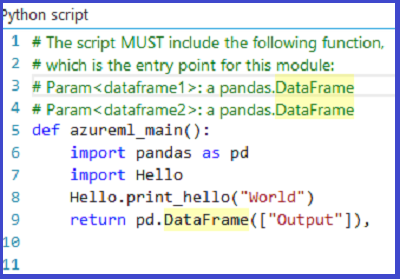
Modulens utdata visar att zip-filen har packats upp och att funktionen print_hello har körts.

Åtkomst till Azure Storage-blobar
Du kan komma åt data som lagras i ett Azure Blob Storage konto med hjälp av följande steg:
- Ladda ned Azure Blob Storage-paketet för Python lokalt.
- Ladda upp zip-filen till din Studio-arbetsyta (klassisk) som en datauppsättning.
- Skapa ditt BlobService-objekt med
protocol='http'
from azure.storage.blob import BlockBlobService
# Create the BlockBlockService that is used to call the Blob service for the storage account
block_blob_service = BlockBlobService(account_name='account_name', account_key='account_key', protocol='http')
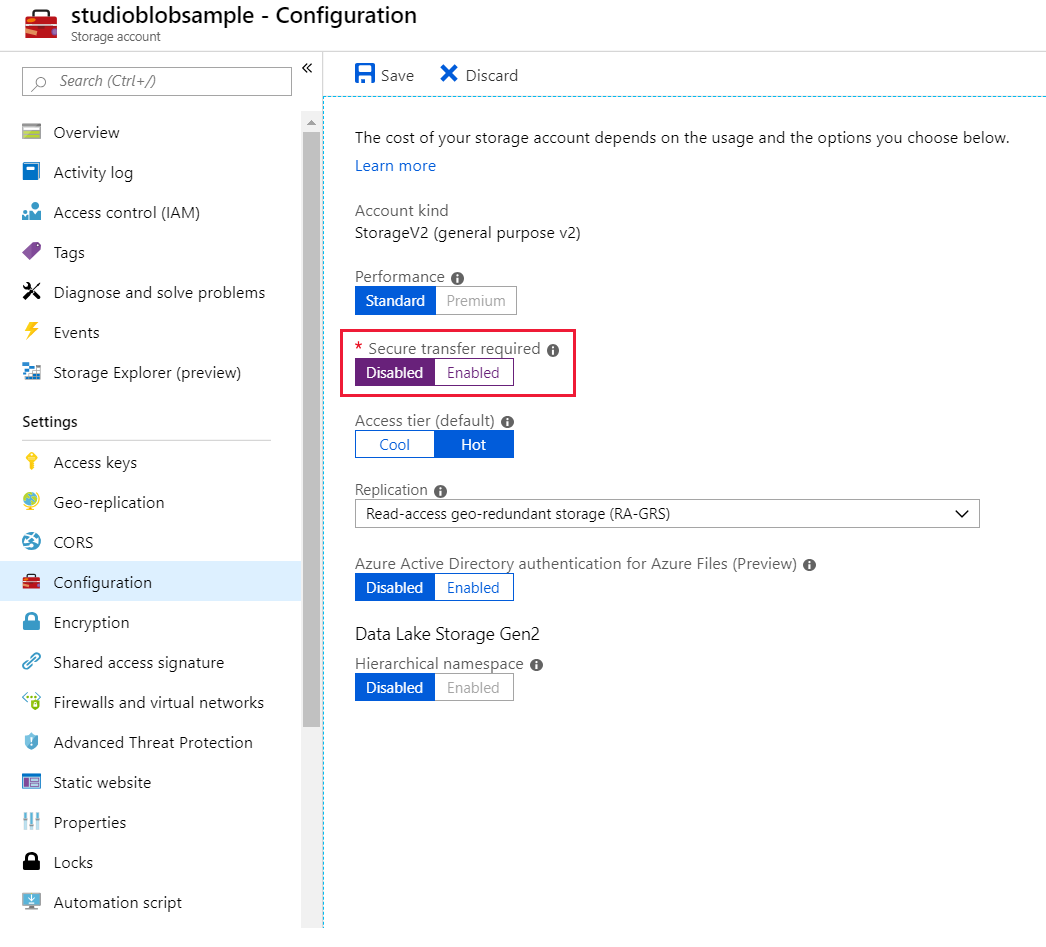
- Inaktivera säker överföring som krävs på inställningsfliken För lagringskonfiguration
Operationalisera Python-skript
Alla Execute Python Script-moduler som används i ett bedömningsexperiment anropas när de publiceras som en webbtjänst. Bilden nedan visar till exempel ett bedömningsexperiment som innehåller koden för att utvärdera ett enda Python-uttryck.
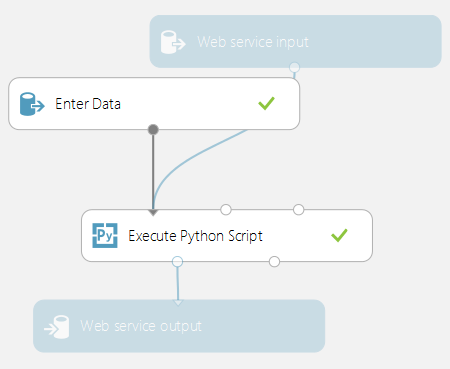
En webbtjänst som skapats från det här experimentet skulle vidta följande åtgärder:
- Ta ett Python-uttryck som indata (som en sträng)
- Skicka Python-uttrycket till Python-tolken
- Returnerar en tabell som innehåller både uttrycket och det utvärderade resultatet.
Arbeta med visualiseringar
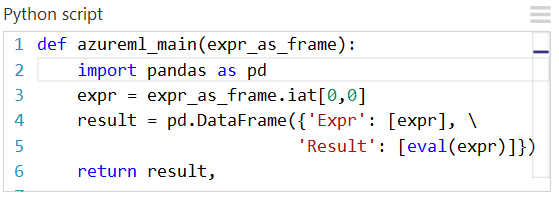
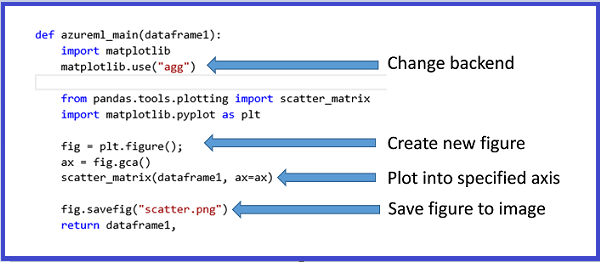
Diagram som skapats med MatplotLib kan returneras av Kör Python-skript. Diagram omdirigeras dock inte automatiskt till bilder som de är när du använder R. Så användaren måste uttryckligen spara alla diagram i PNG-filer.
Om du vill generera avbildningar från MatplotLib måste du utföra följande steg:
- Växla serverdelen till "AGG" från den Qt-baserade standardåtergivningen.
- Skapa ett nytt figurobjekt.
- Hämta axeln och generera alla diagram i den.
- Spara bilden i en PNG-fil.
Den här processen illustreras i följande bilder som skapar en punktdiagrammatris med hjälp av funktionen scatter_matrix i Pandas.
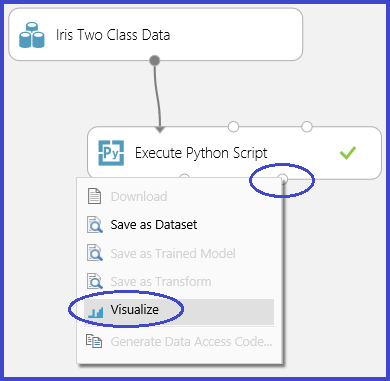
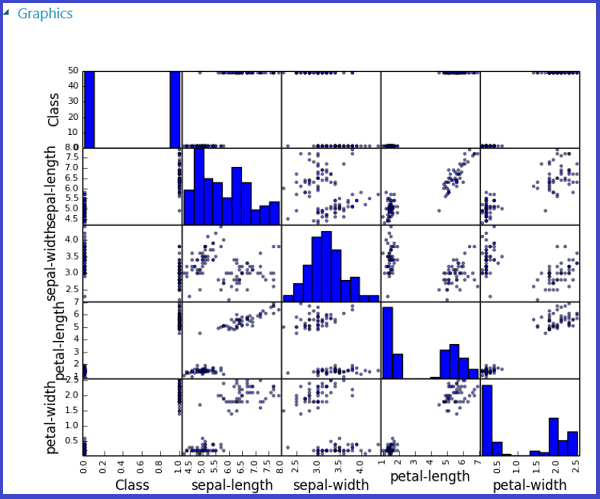
Det går att returnera flera siffror genom att spara dem i olika bilder. Studio (klassisk) runtime hämtar alla bilder och sammanfogar dem för visualisering.
Avancerade exempel
Anaconda-miljön som är installerad i Studio (klassisk) innehåller vanliga paket som NumPy, SciPy och Scikits-Learn. Dessa paket kan användas effektivt för databearbetning i en maskininlärningspipeline.
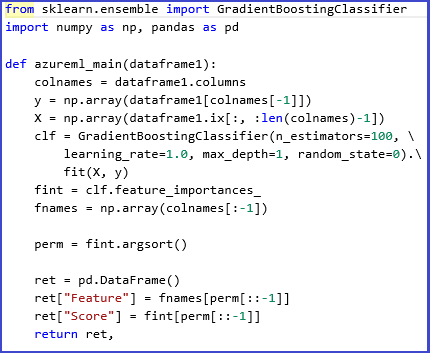
Följande experiment och skript illustrerar till exempel användningen av ensemble-elever i Scikits-Learn för att beräkna funktionsprioritetspoäng för en datauppsättning. Poängen kan användas för att utföra övervakat funktionsval innan de matas in i en annan modell.
Här är python-funktionen som används för att beräkna prioritetspoängen och sortera funktionerna baserat på poängen:
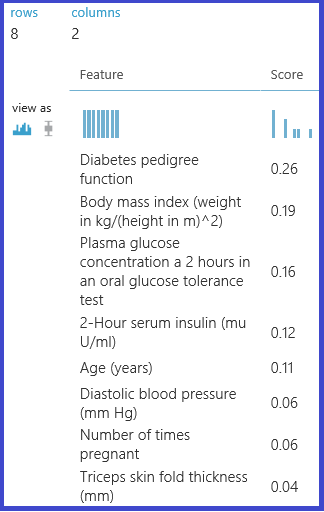
Följande experiment beräknar och returnerar sedan prioritetspoängen för funktioner i datauppsättningen "Pima Indian Diabetes" i Machine Learning Studio (klassisk):
Begränsningar
Modulen Kör Python-skript har för närvarande följande begränsningar:
Körning i begränsat läge
Python-körningen är för närvarande begränsat och tillåter inte åtkomst till nätverket eller det lokala filsystemet på ett beständigt sätt. Alla filer som sparas lokalt isoleras och tas bort när modulen är klar. Python-koden kan inte komma åt de flesta kataloger på den dator som den körs på, undantaget är den aktuella katalogen och dess underkataloger.
Brist på avancerat stöd för utveckling och felsökning
Python-modulen stöder för närvarande inte IDE-funktioner som intellisense och felsökning. Om modulen misslyckas vid körning är den fullständiga Python-stackspårningen också tillgänglig. Men den måste visas i utdataloggen för modulen. Vi rekommenderar för närvarande att du utvecklar och felsöker Python-skript i en miljö som IPython och sedan importerar koden till modulen.
Utdata för enkel dataram
Python-startpunkten får endast returnera en enda dataram som utdata. Det går för närvarande inte att returnera godtyckliga Python-objekt, till exempel tränade modeller direkt tillbaka till Studio-körningen (klassisk). Precis som Kör R-skript, som har samma begränsning, är det i många fall möjligt att lägga objekt i en bytematris och sedan returnera det i en dataram.
Det går inte att anpassa Python-installationen
För närvarande är det enda sättet att lägga till anpassade Python-moduler via zip-filmekanismen som beskrevs tidigare. Även om detta är möjligt för små moduler är det besvärligt för stora moduler (särskilt moduler med inbyggda DLL:er) eller ett stort antal moduler.
Nästa steg
Mer information finns i Python Developer Center.