Självstudie: Träna din första maskininlärningsmodell (SDK v1, del 2 av 3)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Den här självstudien visar hur du tränar en maskininlärningsmodell i Azure Machine Learning. Den här självstudien är del 2 i en självstudieserie i två delar.
I del 1: Kör "Hello world!" i serien lärde du dig hur du använder ett kontrollskript för att köra ett jobb i molnet.
I den här självstudien tar du nästa steg genom att skicka ett skript som tränar en maskininlärningsmodell. Det här exemplet hjälper dig att förstå hur Azure Machine Learning underlättar konsekvent beteende mellan lokal felsökning och fjärrkörningar.
I den här kursen får du:
- Skapa ett träningsskript.
- Använd Conda för att definiera en Azure Machine Learning-miljö.
- Skapa ett kontrollskript.
- Förstå Azure Machine Learning-klasser (
Environment,Run,Metrics). - Skicka in och kör ditt träningsskript.
- Visa dina kodutdata i molnet.
- Logga mått till Azure Machine Learning.
- Visa dina mått i molnet.
Förutsättningar
- Slutförande av del 1 i serien.
Skapa träningsskript
Först definierar du arkitekturen för neurala nätverk i en model.py fil. All träningskod hamnar i underkatalogen src , inklusive model.py.
Träningskoden hämtas från det här introduktionsexemplet från PyTorch. Azure Machine Learning-begreppen gäller för alla maskininlärningskoder, inte bara PyTorch.
Skapa en model.py fil i undermappen src . Kopiera den här koden till filen:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xI verktygsfältet väljer du Spara för att spara filen. Stäng fliken om du vill.
Definiera sedan träningsskriptet, även i undermappen src . Det här skriptet laddar ned CIFAR10 datauppsättningen med hjälp av PyTorch-API
torchvision.dataset:er, konfigurerar nätverket som definierats i model.py och tränar den för två epoker med hjälp av standard-SGD och korsentropiförlust.Skapa ett train.py skript i undermappen src :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Nu har du följande mappstruktur:
Testa lokalt
Välj Spara och kör skript i terminalen för att köra train.py skriptet direkt på beräkningsinstansen.
När skriptet är klart väljer du Uppdatera ovanför filmapparna. Du ser den nya datamappen get-started /data Expandera den här mappen för att visa nedladdade data.
Skapa en Python-miljö
Azure Machine Learning tillhandahåller konceptet med en miljö som representerar en reproducerbar, versionshanterad Python-miljö för att köra experiment. Det är enkelt att skapa en miljö från en lokal Conda- eller pip-miljö.
Först skapar du en fil med paketberoendena.
Skapa en ny fil i kom igång-mappen med namnet
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionI verktygsfältet väljer du Spara för att spara filen. Stäng fliken om du vill.
Skapa kontrollskriptet
Skillnaden mellan följande kontrollskript och det som du använde för att skicka "Hello world!" är att du lägger till ett par extra rader för att ange miljön.
Skapa en ny Python-fil i kom igång-mappen med namnet run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Dricks
Om du använde ett annat namn när du skapade beräkningsklustret måste du också justera namnet i koden compute_target='cpu-cluster' .
Förstå kodändringarna
env = ...
Refererar till beroendefilen som du skapade ovan.
config.run_config.environment = env
Lägger till miljön i ScriptRunConfig.
Skicka körningen till Azure Machine Learning
Välj Spara och kör skript i terminalen för att köra skriptet run-pytorch.py .
Du ser en länk i terminalfönstret som öppnas. Välj länken för att visa jobbet.
Kommentar
Du kan se några varningar som börjar med Fel vid inläsning av azureml_run_type_providers.... Du kan ignorera dessa varningar. Använd länken längst ned i dessa varningar för att visa dina utdata.
Visa utdata
- På sidan som öppnas ser du jobbstatusen. Första gången du kör det här skriptet skapar Azure Machine Learning en ny Docker-avbildning från PyTorch-miljön. Hela jobbet kan ta cirka 10 minuter att slutföra. Den här avbildningen återanvänds i framtida jobb för att få dem att köras mycket snabbare.
- Du kan se Visa Docker-byggloggar i Azure Machine Learning-studio. för att visa byggloggarna:
- Välj fliken Utdata + loggar.
- Välj mappen azureml-logs .
- Välj 20_image_build_log.txt.
- När jobbets status är Slutförd väljer du Utdata + loggar.
- Välj user_logs och sedan std_log.txt för att visa utdata för jobbet.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Om du ser ett fel Your total snapshot size exceeds the limitfinns datamappen i värdet source_directory som används i ScriptRunConfig.
Välj ... i slutet av mappen och välj sedan Flytta för att flytta data till mappen komma igång.
Loggträningsmått
Nu när du har en modellträning i Azure Machine Learning börjar du spåra några prestandamått.
Det aktuella träningsskriptet skriver ut mått till terminalen. Azure Machine Learning tillhandahåller en mekanism för loggning av mått med fler funktioner. Genom att lägga till några rader kod får du möjlighet att visualisera mått i studion och jämföra mått mellan flera jobb.
Ändra train.py för att inkludera loggning
Ändra ditt train.py skript så att det innehåller ytterligare två kodrader:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Spara den här filen och stäng sedan fliken om du vill.
Förstå de ytterligare två kodraderna
I train.py kommer du åt körningsobjektet från själva träningsskriptet med hjälp Run.get_context() av metoden och använder den för att logga mått:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Mått i Azure Machine Learning är:
- Ordnat efter experiment och körning, så det är enkelt att hålla reda på och jämföra mått.
- Utrustad med ett användargränssnitt så att du kan visualisera träningsprestanda i studion.
- Utformad för att skala, så du behåller dessa fördelar även när du kör hundratals experiment.
Uppdatera Conda-miljöfilen
Skriptet train.py tog just ett nytt beroende av azureml.core. Uppdatera pytorch-env.yml för att återspegla den här ändringen:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Se till att du sparar den här filen innan du skickar körningen.
Skicka körningen till Azure Machine Learning
Välj fliken för skriptet run-pytorch.py och välj sedan Spara och kör skriptet i terminalen för att köra run-pytorch.py skriptet igen. Se till att du sparar ändringarna till pytorch-env.yml först.
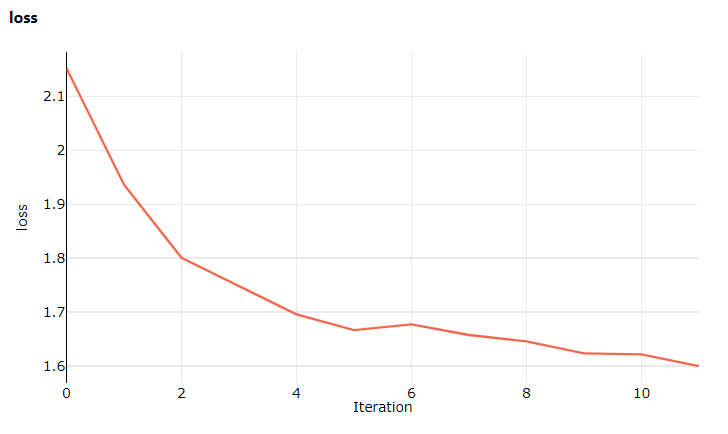
Den här gången när du besöker studion går du till fliken Mått där du nu kan se liveuppdateringar om modellträningsförlusten! Det kan ta 1 till 2 minuter innan träningen börjar.
Rensa resurser
Om du planerar att fortsätta nu till en annan självstudie eller starta egna träningsjobb går du vidare till Relaterade resurser.
Stoppa beräkningsinstans
Om du inte ska använda den nu stoppar du beräkningsinstansen:
- Välj Beräkning till vänster i studion.
- På de översta flikarna väljer du Beräkningsinstanser
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
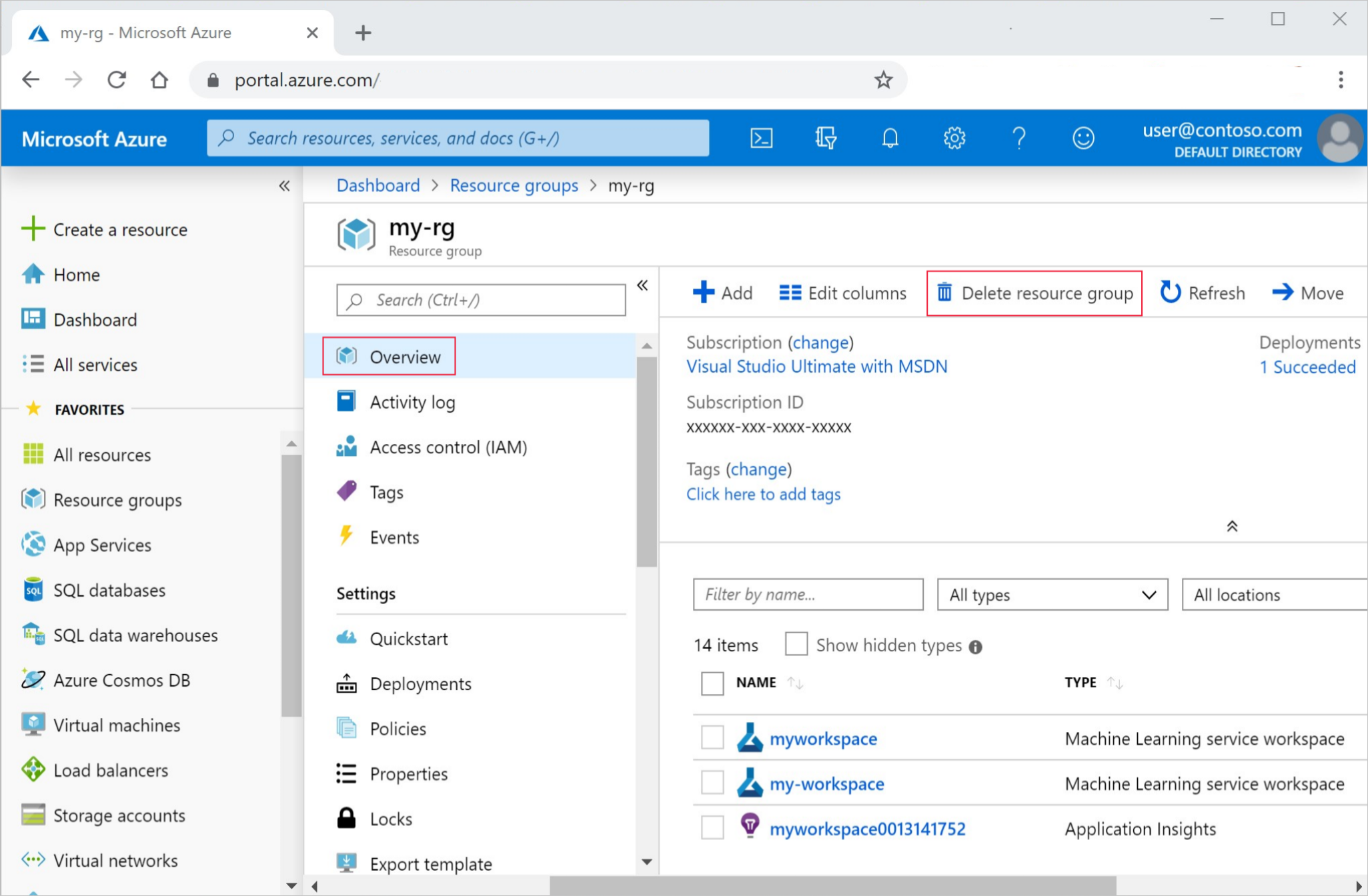
Ange resursgruppsnamnet. Välj sedan ta bort.
Du kan också behålla resursgruppen men ta bort en enstaka arbetsyta. Visa arbetsytans egenskaper och välj Ta bort.
Relaterade resurser
I den här sessionen uppgraderade du från ett grundläggande "Hello world!"-skript till ett mer realistiskt träningsskript som krävde att en specifik Python-miljö kördes. Du såg hur du använder utvalda Azure Machine Learning-miljöer. Slutligen såg du hur du i några rader med kod kan logga mått till Azure Machine Learning.
Det finns andra sätt att skapa Azure Machine Learning-miljöer, bland annat från en pip-requirements.txt-fil eller från en befintlig lokal Conda-miljö.