Självstudie: Använda designern för att distribuera en maskininlärningsmodell
I del ett av den här självstudien tränade du en linjär regressionsmodell som förutsäger bilpriser. I den andra delen använder du Azure Mašinsko učenje-designern för att distribuera modellen så att andra kan använda den.
Kommentar
Designern stöder två typer av komponenter: klassiska fördefinierade komponenter (v1) och anpassade komponenter (v2). Dessa två typer av komponenter är INTE kompatibla.
Klassiska fördefinierade komponenter tillhandahåller fördefinierade komponenter främst för databearbetning och traditionella maskininlärningsuppgifter som regression och klassificering. Den här typen av komponent stöds fortfarande, men inga nya komponenter läggs till.
Med anpassade komponenter kan du omsluta din egen kod som en komponent. De stöder delning av komponenter mellan arbetsytor och sömlös redigering i gränssnitten Mašinsko učenje Studio, CLI v2 och SDK v2.
För nya projekt rekommenderar vi att du använder anpassade komponenter som är kompatibla med Azure Mašinsko učenje v2 och fortsätter att ta emot nya uppdateringar.
Den här artikeln gäller för klassiska fördefinierade komponenter och är inte kompatibel med CLI v2 och SDK v2.
I den här kursen får du:
- Skapa en pipeline för slutsatsdragning i realtid.
- Skapa ett slutsatsdragningskluster.
- Distribuera realtidsslutpunkten.
- Testa realtidsslutpunkten.
Förutsättningar
Slutför del ett av självstudien för att lära dig hur du tränar och poängsätt en maskininlärningsmodell i designern.
Viktigt!
Om du inte ser grafiska element som nämns i det här dokumentet, till exempel knappar i studio eller designer, kanske du inte har rätt behörighetsnivå för arbetsytan. Kontakta azure-prenumerationsadministratören för att kontrollera att du har beviljats rätt åtkomstnivå. Mer information finns i Hantera användare och roller.
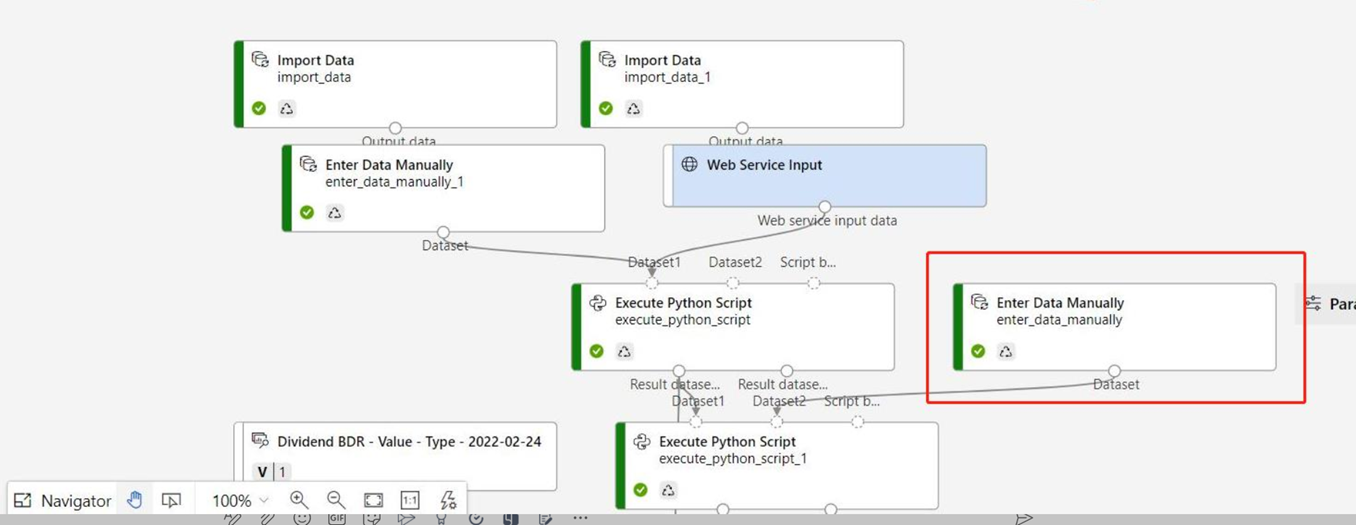
Skapa en pipeline för slutsatsdragning i realtid
Om du vill distribuera din pipeline måste du först konvertera träningspipelinen till en pipeline för slutsatsdragning i realtid. Den här processen tar bort träningskomponenter och lägger till webbtjänstindata och -utdata för att hantera begäranden.
Kommentar
Funktionen Skapa slutsatsdragningspipeline stöder träningspipelines som bara innehåller de inbyggda komponenterna i designern och som har en komponent som Train Model som matar ut den tränade modellen.
Skapa en pipeline för slutsatsdragning i realtid
Välj Pipelines på sidonavigeringspanelen och öppna sedan det pipelinejobb som du skapade. På detaljsidan, ovanför pipelinearbetsytan, väljer du ellipserna ... och väljer sedan Skapa slutsatsdragningspipeline> för realtidsinferens.
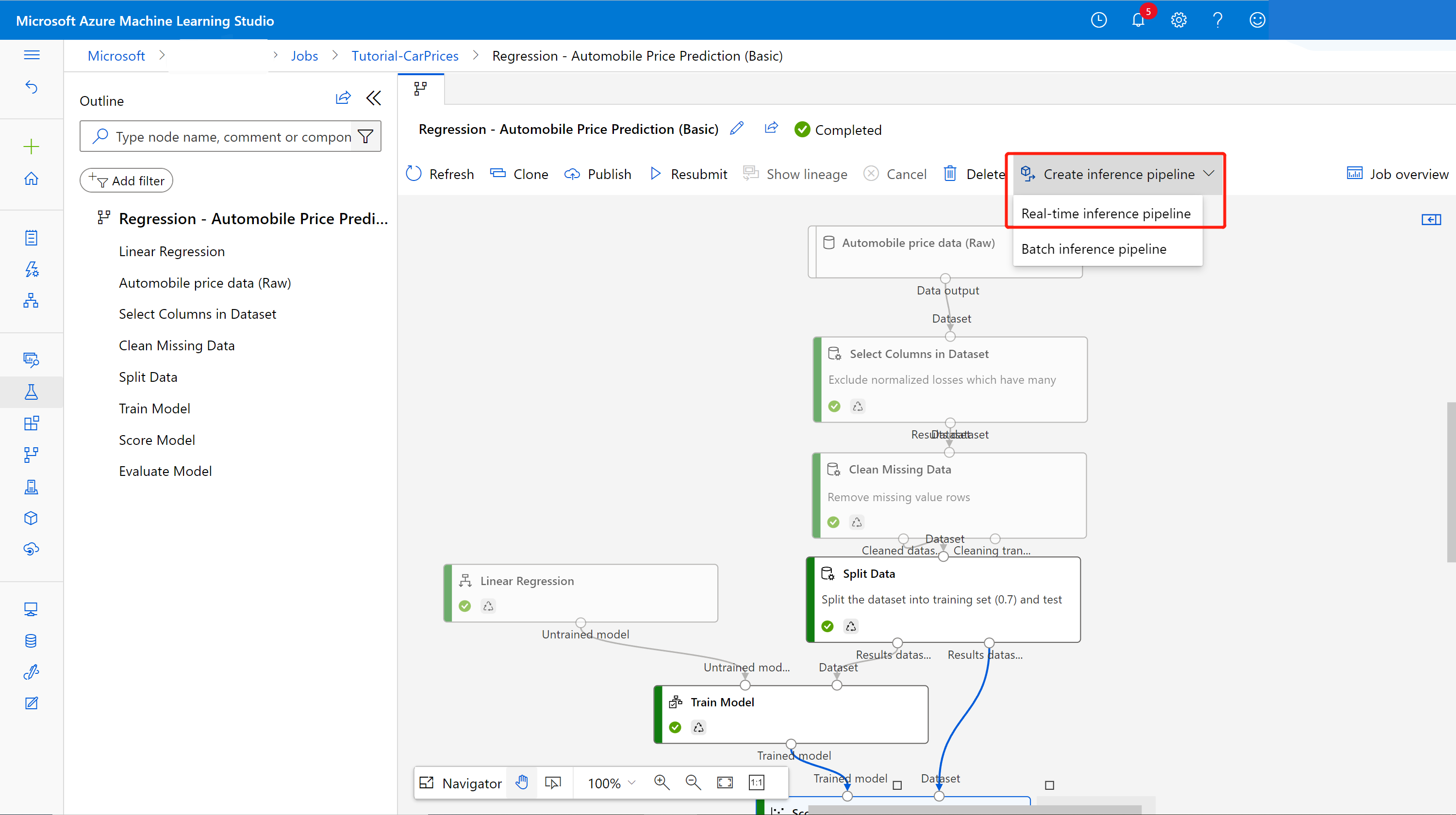
Din nya pipeline ser nu ut så här:
När du väljer Skapa slutsatsdragningspipeline händer flera saker:
- Den tränade modellen lagras som en datamängdskomponent i komponentpaletten. Du hittar den under Mina datauppsättningar.
- Träningskomponenter som Train Model och Split Data tas bort.
- Den sparade tränade modellen läggs tillbaka till i pipelinen.
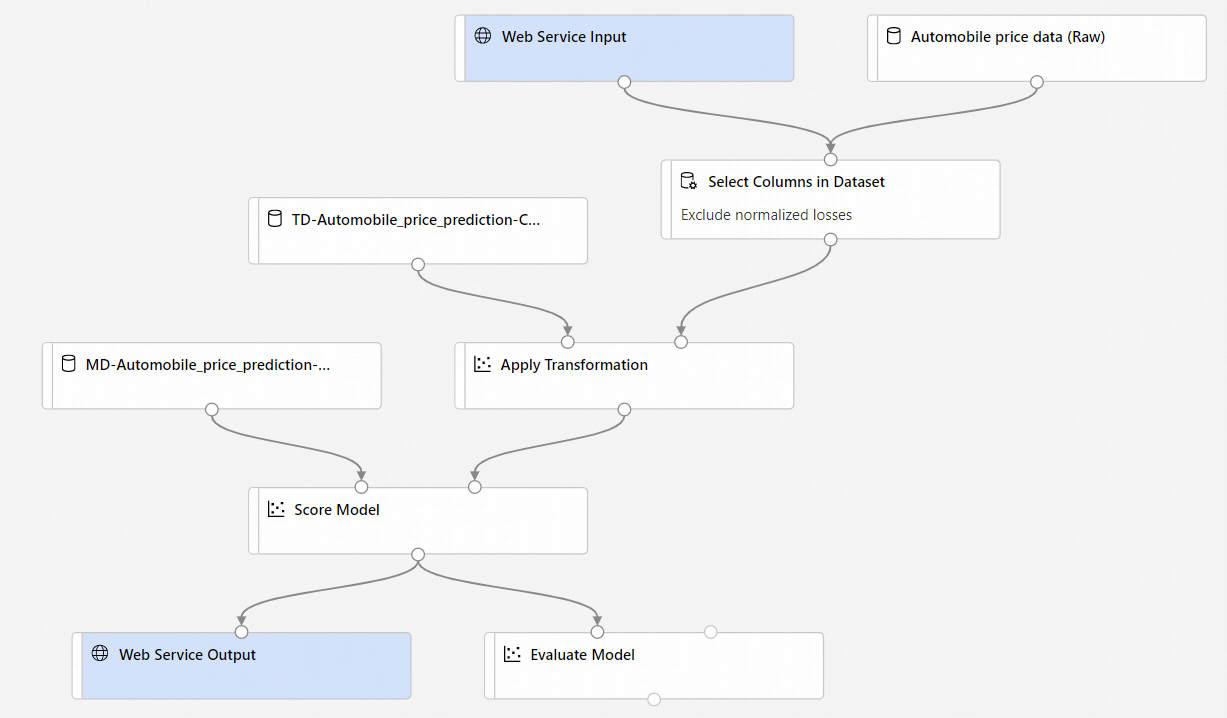
- Komponenter för webbtjänstindata och webbtjänstutdata läggs till. Dessa komponenter visar var användardata kommer in i pipelinen och var data returneras.
Kommentar
Webbtjänstindata förväntar sig som standard samma dataschema som komponentens utdata som ansluter till samma underordnade port. I det här exemplet ansluter webbtjänstindata och bilprisdata (Raw) till samma underordnade komponent, så Webbtjänstindata förväntar sig att samma dataschema som Automobile price data (Raw) och målvariabelkolumnen
priceingår i schemat. Men när du bedömer data känner du inte till målvariabelvärdena. I så fall kan du ta bort målvariabelkolumnen i slutsatsdragningspipelinen med hjälp av komponenten Välj kolumner i datauppsättning . Kontrollera att utdata från Select Columns in Dataset removing target variable column (Välj kolumner i datauppsättningen ) som tar bort målvariabelkolumnen är anslutna till samma port som utdata från komponenten Webbtjänstindata .Välj Konfigurera och skicka och använd samma beräkningsmål och experiment som du använde i del ett.
Om det här är det första jobbet kan det ta upp till 20 minuter innan pipelinen är klar. Standardinställningarna för beräkning har en minsta nodstorlek på 0, vilket innebär att designern måste allokera resurser när den är inaktiv. Upprepade pipelinejobb tar mindre tid eftersom beräkningsresurserna redan har allokerats. Dessutom använder designern cachelagrade resultat för varje komponent för att ytterligare förbättra effektiviteten.
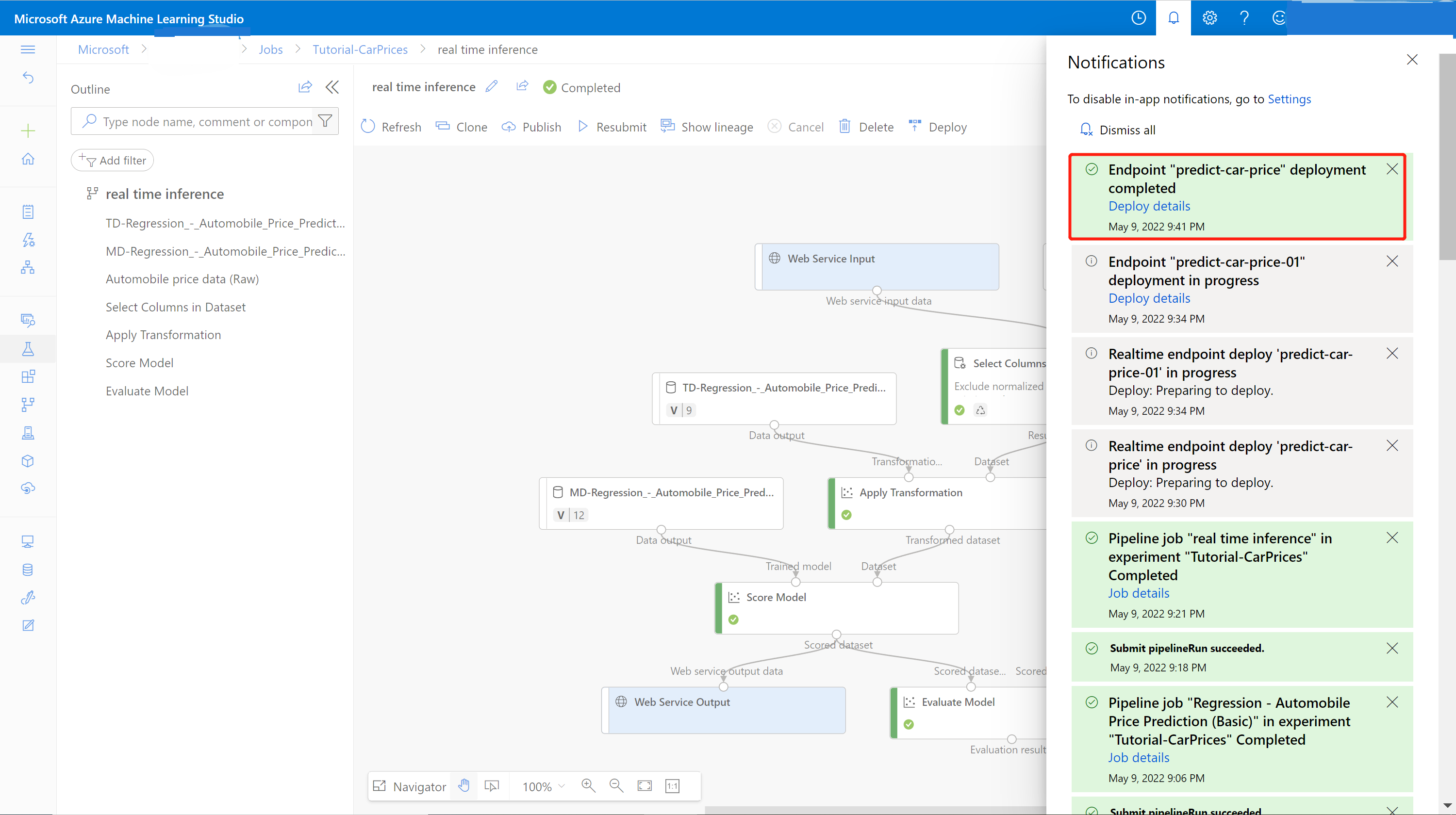
Gå till information om pipelinejobbet för realtidsslutledning genom att välja Jobbinformation i det vänstra fönstret.
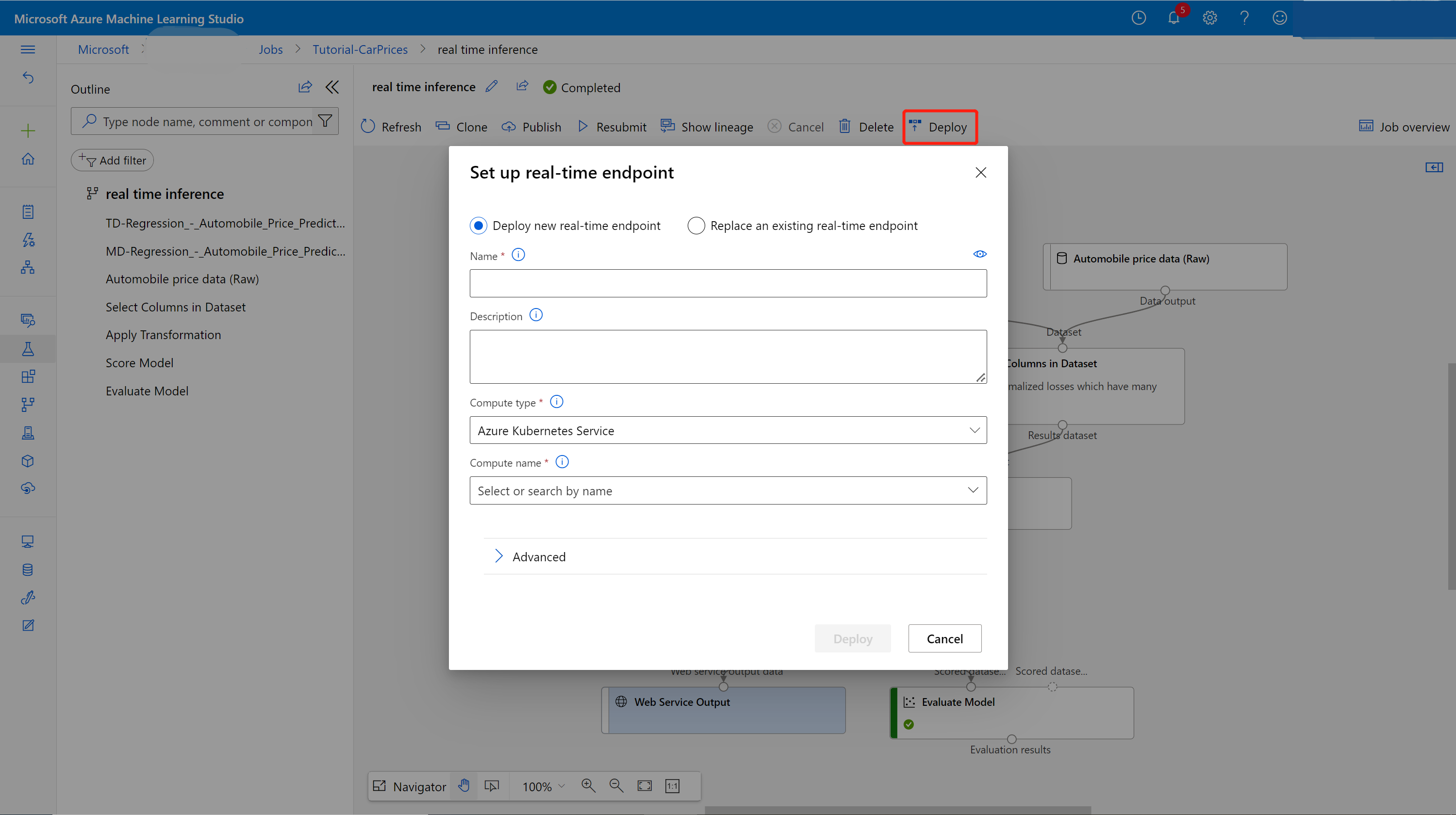
Välj Distribuera på sidan med jobbinformation.


Skapa ett slutsatsdragningskluster
I dialogrutan som visas kan du välja från alla befintliga AKS-kluster (Azure Kubernetes Service) som du vill distribuera din modell till. Om du inte har något AKS-kluster använder du följande steg för att skapa ett.
Gå till sidan Beräkning genom att välja Beräkning i dialogrutan.
I navigeringsfliksområdet väljer du Kubernetes Clusters>+ New.
I fönstret slutsatsdragningskluster konfigurerar du en ny Kubernetes-tjänst.
Ange aks-compute som beräkningsnamn.
Välj en närliggande region som är tillgänglig för regionen.
Välj Skapa.
Kommentar
Det tar ungefär 15 minuter att skapa en ny AKS-tjänst. Du kan kontrollera etableringstillståndet på sidan Slutsatsdragningskluster .
Distribuera realtidsslutpunkten
När AKS-tjänsten har slutfört etableringen återgår du till pipelinen för slutsatsdragning i realtid för att slutföra distributionen.
Välj Distribuera ovanför arbetsytan.
Välj Distribuera ny realtidsslutpunkt.
Välj det AKS-kluster som du skapade.
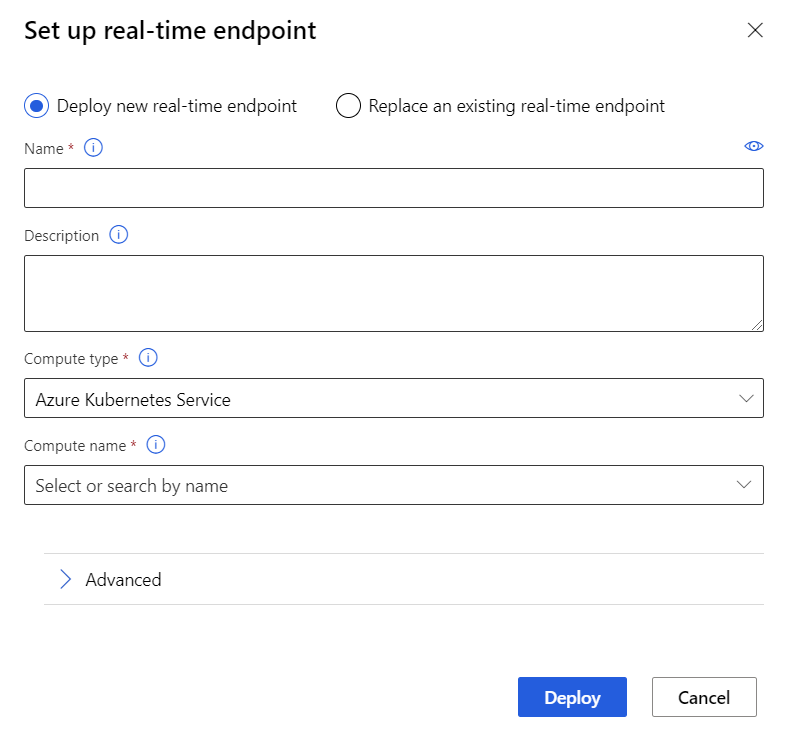
Du kan också ändra inställningen Avancerat för realtidsslutpunkten.
Avancerad inställning beskrivning Aktivera Application Insights-diagnostik och datainsamling Gör att Azure Application Insights kan samla in data från de distribuerade slutpunkterna.
Som standard: false.Tidsgräns för bedömning En timeout i millisekunder för att framtvinga för bedömningsanrop till webbtjänsten.
Som standard: 60000.Automatisk skalning aktiverat Tillåter automatisk skalning för webbtjänsten.
Som standard: true.Minsta repliker Det minsta antalet containrar som ska användas vid automatisk skalning av den här webbtjänsten.
Som standard: 1.Maximalt antal repliker Det maximala antalet containrar som ska användas vid automatisk skalning av den här webbtjänsten.
Som standard: 10.Målanvändning Den målanvändning (i procent) som autoskalningen ska försöka underhålla för den här webbtjänsten.
Som standard: 70.Uppdateringsperiod Hur ofta (i sekunder) autoskalningstjänsten försöker skala den här webbtjänsten.
Som standard: 1.Processorreservkapacitet Antalet CPU-kärnor som ska allokeras för den här webbtjänsten.
Som standard: 0.1.Minnesreservkapacitet Mängden minne (i GB) som ska allokeras för den här webbtjänsten.
Som standard: 0,5.Välj distribuera.
Ett meddelande från meddelandecentret visas när distributionen har slutförts. Det kan ta några minuter.

Dricks
Du kan också distribuera till Azure Container Instance om du väljer Azure Container Instance for Compute-typ i inställningsrutan för slutpunkt i realtid. Azure Container Instance används för testning eller utveckling. Använd Azure Container Instance för lågskalig CPU-baserad arbetsbelastning som kräver mindre än 48 GB RAM-minne.
Testa realtidsslutpunkten
När distributionen är klar kan du visa slutpunkten i realtid genom att gå till sidan Slutpunkter .
På sidan Slutpunkter väljer du den slutpunkt som du distribuerade.
På fliken Information kan du se mer information, till exempel REST-URI, Swagger-definition, status och taggar.
På fliken Förbruka hittar du exempel på förbrukningskod, säkerhetsnycklar och anger autentiseringsmetoder.
På fliken Distributionsloggar hittar du detaljerade distributionsloggar för din realtidsslutpunkt.
Om du vill testa slutpunkten går du till fliken Test . Härifrån kan du ange testdata och välja Testa verifiera slutpunktens utdata.
Uppdatera realtidsslutpunkten
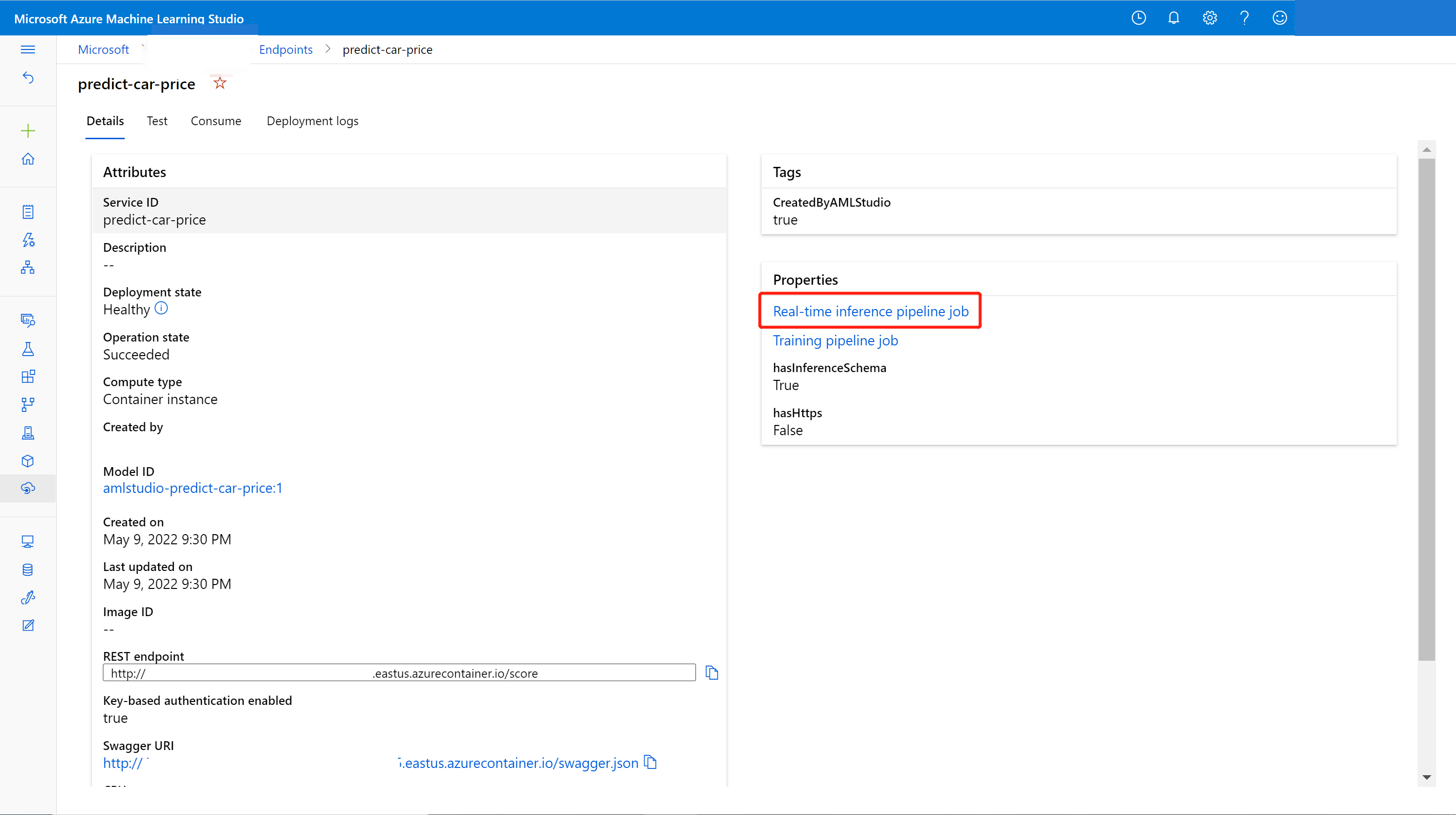
Du kan uppdatera onlineslutpunkten med en ny modell som tränats i designern. På informationssidan för onlineslutpunkten hittar du ditt tidigare pipelinejobb för träning och härledningspipelinesjobb.
Du kan hitta och ändra ditt utkast för träningspipeline på designerns startsida.
Eller så kan du öppna länken för träningspipelinejobbet och sedan klona den till ett nytt pipelineutkast för att fortsätta redigera.
När du har skickat den ändrade träningspipelinen går du till sidan med jobbinformation.
När jobbet är klart högerklickar du på Träna modell och väljer Registrera data.
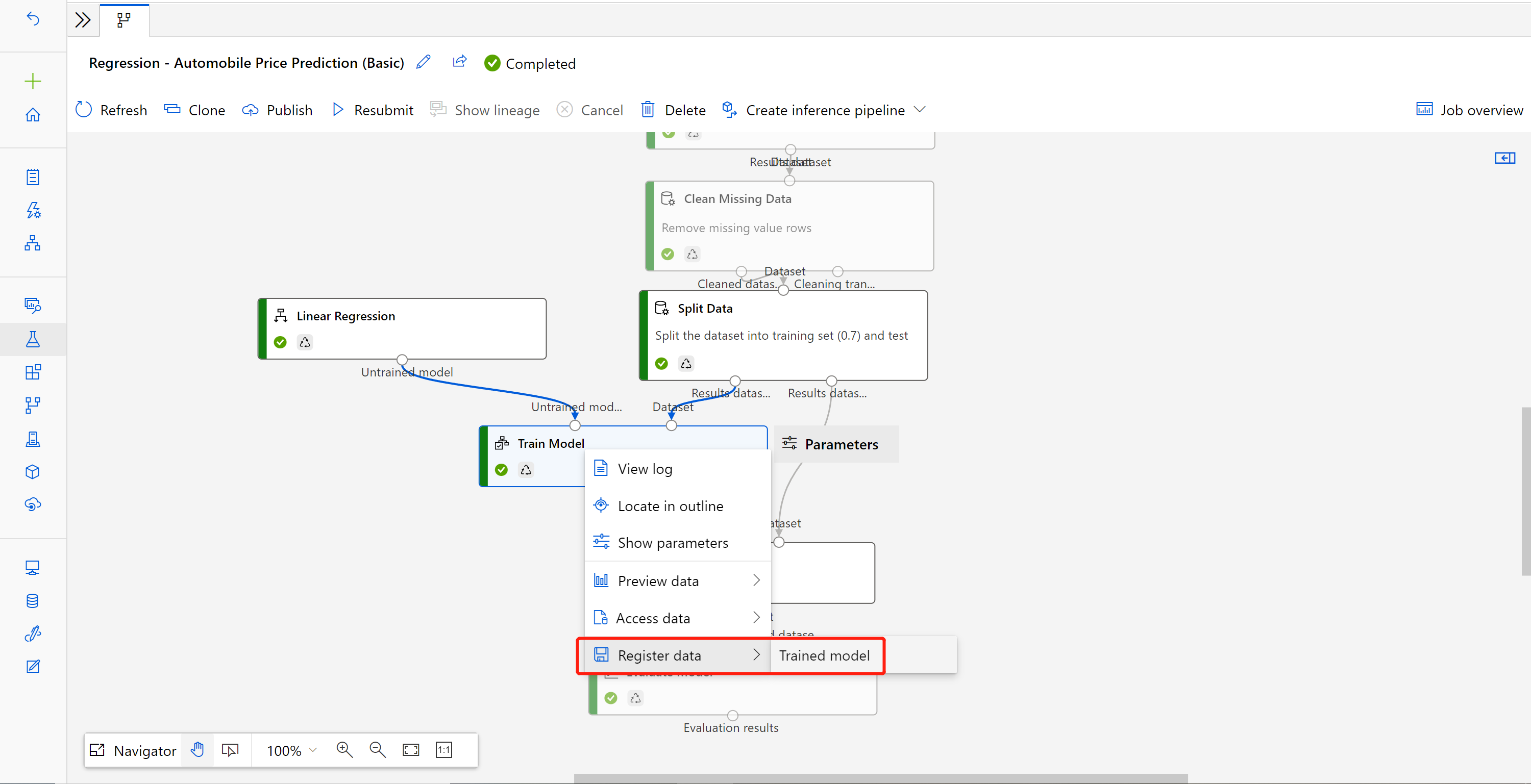
Indatanamn och välj Filtyp .
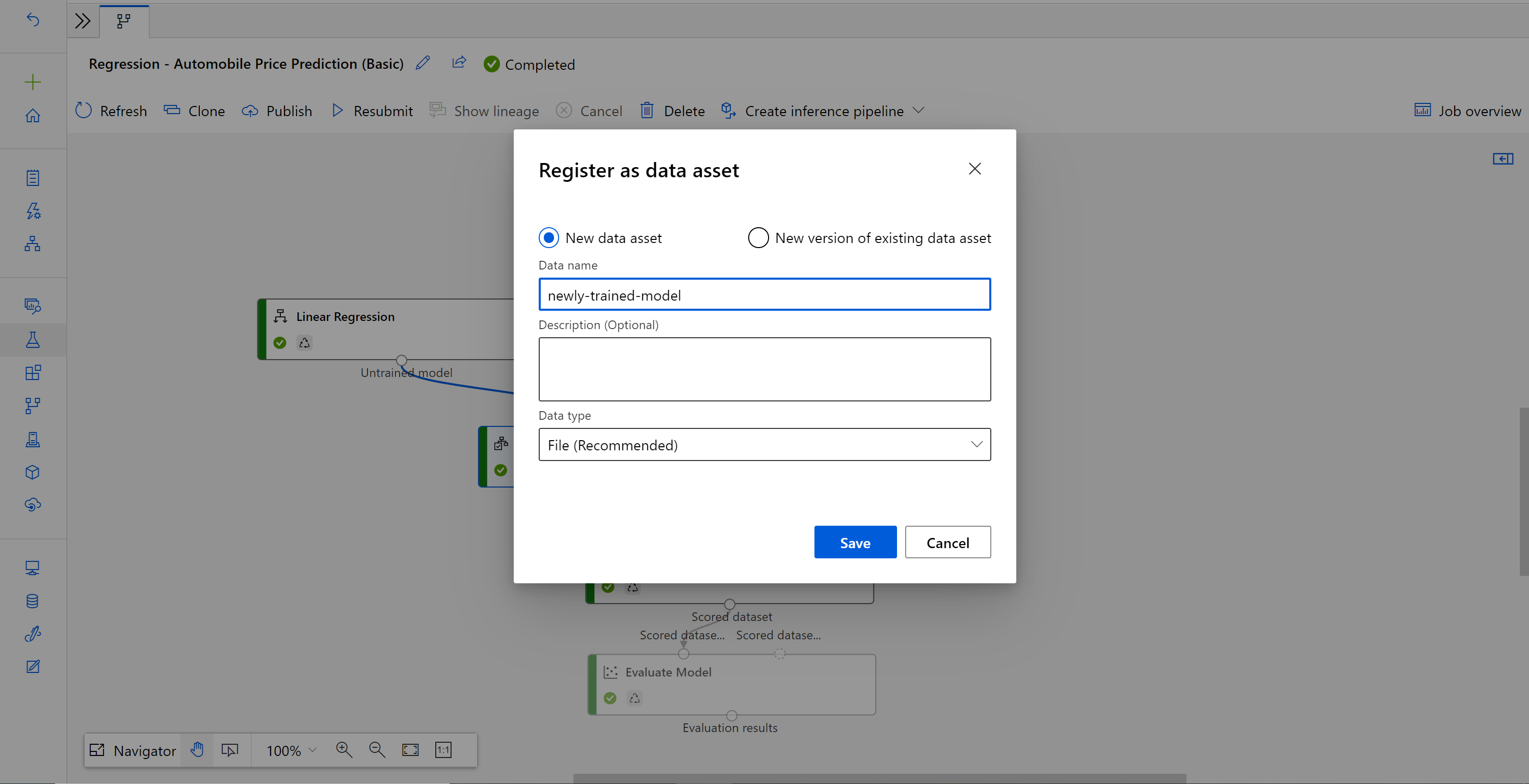
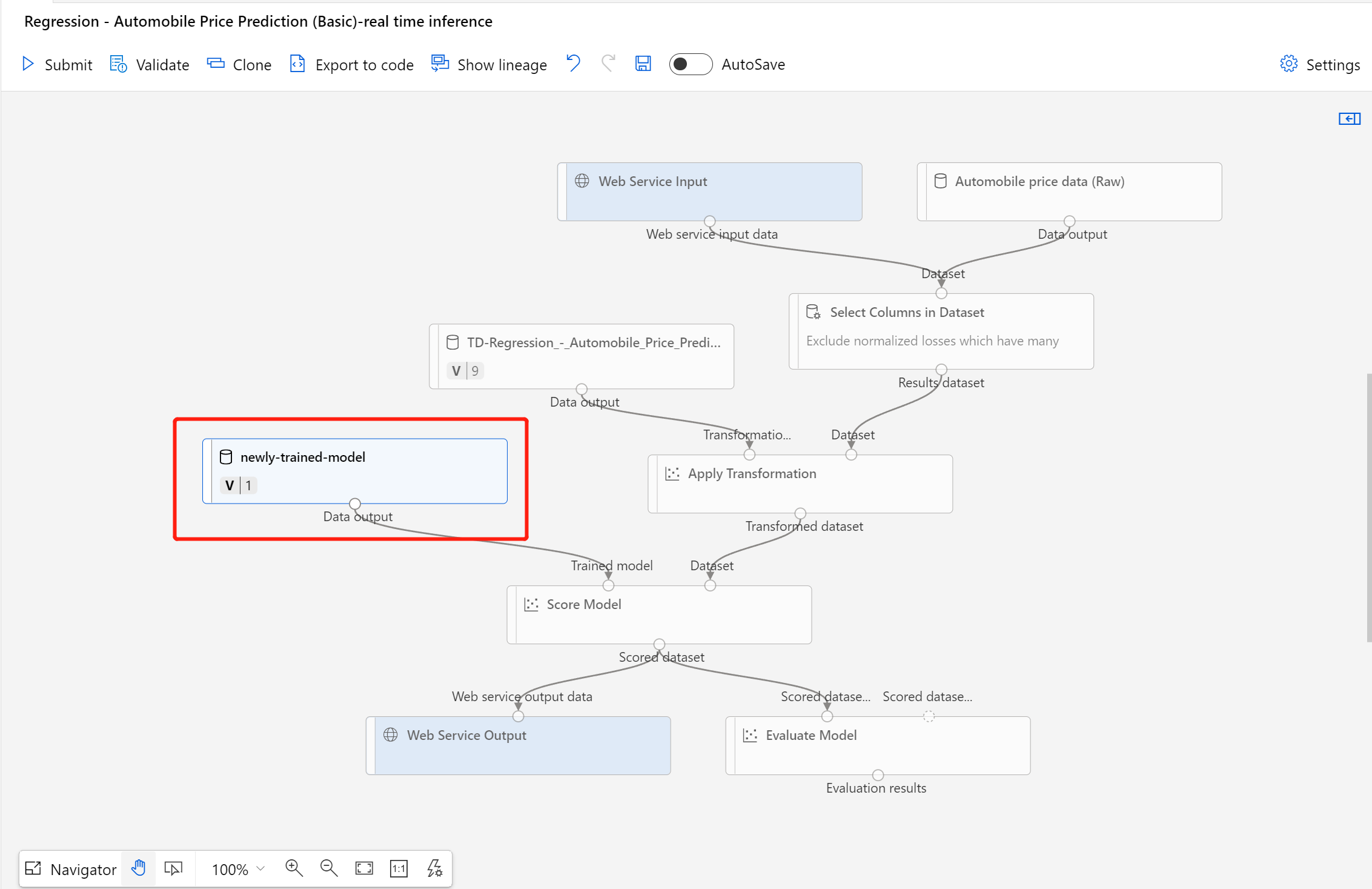
När datauppsättningen har registrerats öppnar du ditt utkast till slutsatsdragningspipeline eller klonar det tidigare pipelinejobbet för slutsatsdragning till ett nytt utkast. I utkastet till slutsatsdragningspipelinen ersätter du den tidigare tränade modellen som visas som MD-XXXX-nod som är ansluten till komponenten Poängsätta modell med den nyligen registrerade datamängden.
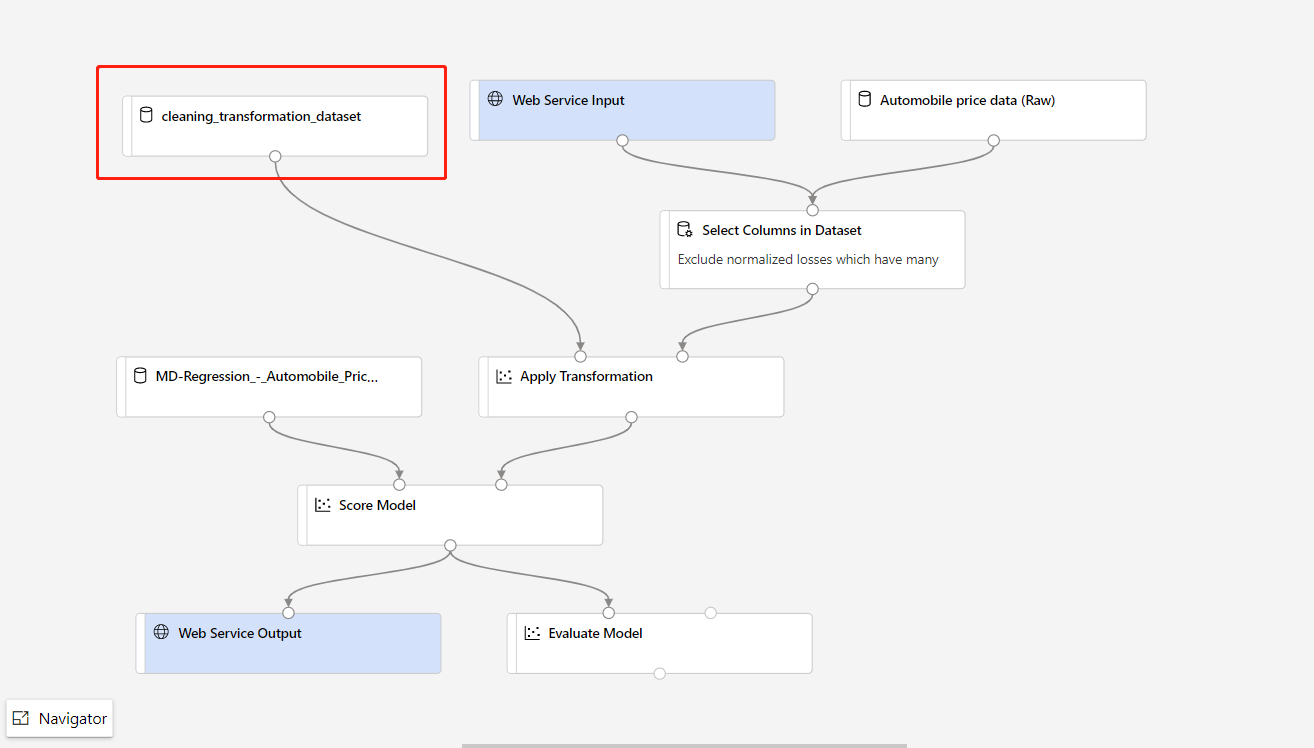
Om du behöver uppdatera dataförbearbetningsdelen i din träningspipeline och vill uppdatera den till slutsatsdragningspipelinen liknar bearbetningen stegen ovan.
Du behöver bara registrera transformeringsutdata för transformeringskomponenten som datauppsättning.
Ersätt sedan TD-komponenten manuellt i slutsatsdragningspipelinen med den registrerade datauppsättningen.
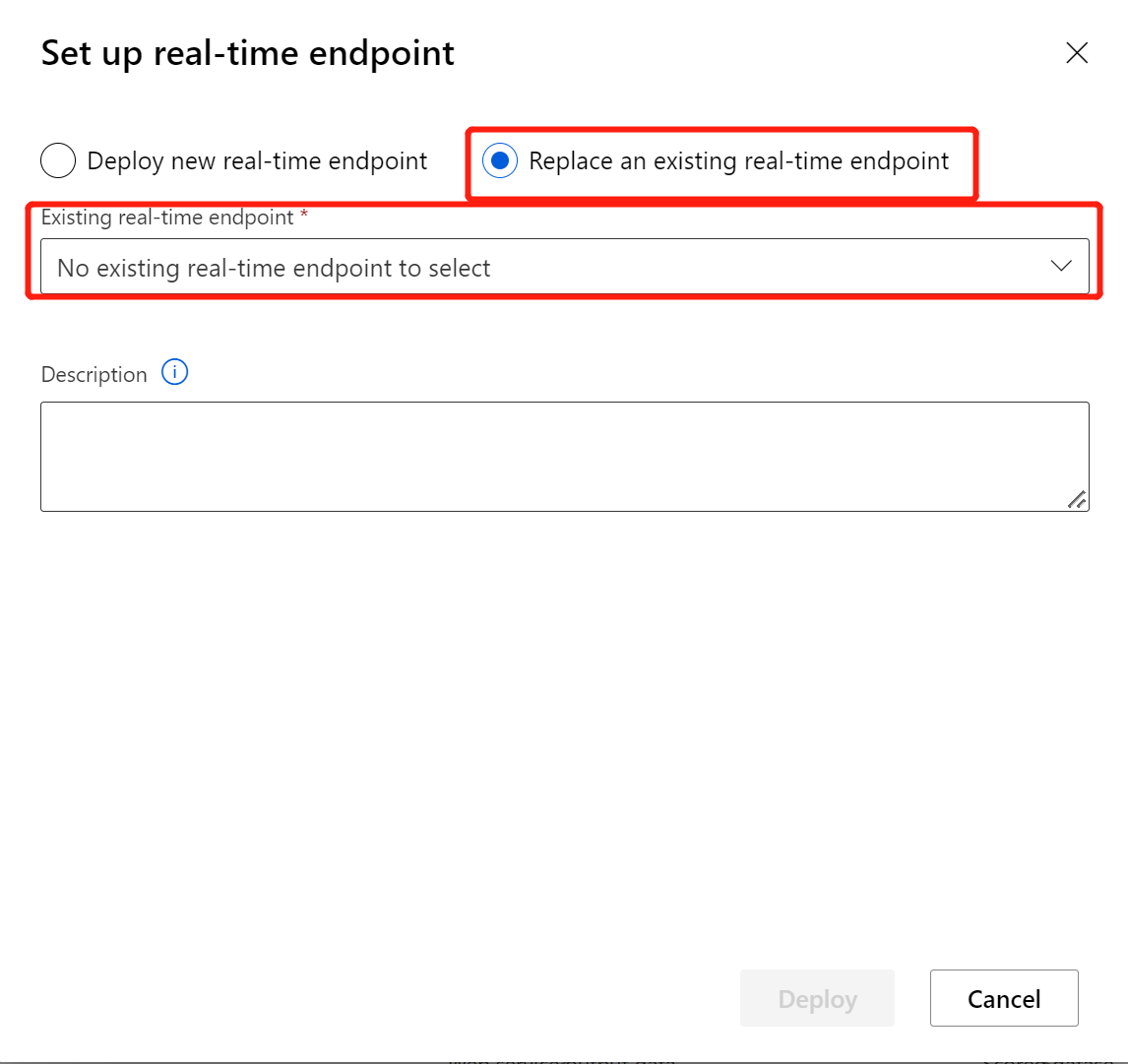
När du har modifierat din slutsatsdragningspipeline med den nyligen tränade modellen eller omvandlingen skickar du den. När jobbet har slutförts distribuerar du det till den befintliga onlineslutpunkten som distribuerades tidigare.




Begränsningar
På grund av åtkomstbegränsningar för datalager tas de bort automatiskt när de distribueras till realtidsslutpunkten om din slutsatsdragningspipeline innehåller komponenterna Importera data eller Exportera data .
Om du har datauppsättningar i pipelinen för slutsatsdragning i realtid och vill distribuera den till realtidsslutpunkten stöder det här flödet för närvarande endast datauppsättningar som registrerats från Blob-datalager . Om du vill använda datauppsättningar från andra typer av datalager kan du använda Välj kolumn för att ansluta till din första datauppsättning med inställningar för att välja alla kolumner, registrera utdata från Välj kolumn som fildatauppsättning och sedan ersätta den första datauppsättningen i pipelinen för slutsatsdragning i realtid med den nyligen registrerade datauppsättningen.
Om inferensdiagrammet innehåller komponenten Ange data manuellt som inte är ansluten till samma port som komponenten För webbtjänstindata , körs inte komponenten Ange data manuellt under HTTP-anropsbearbetningen. En lösning är att registrera utdata från komponenten Ange data manuellt som en datauppsättning. Ersätt sedan komponenten Ange data manuellt med den registrerade datauppsättningen i utkast till slutsatsdragningspipeline.

Rensa resurser
Viktigt!
Du kan använda de resurser som du skapade som förutsättningar för andra Azure-Mašinsko učenje självstudier och instruktionsartiklar.
Ta bort allt
Om du inte planerar att använda något som du har skapat tar du bort hela resursgruppen så att du inte debiteras några avgifter.
I Azure-portalen väljer du Resursgrupper till vänster i fönstret.
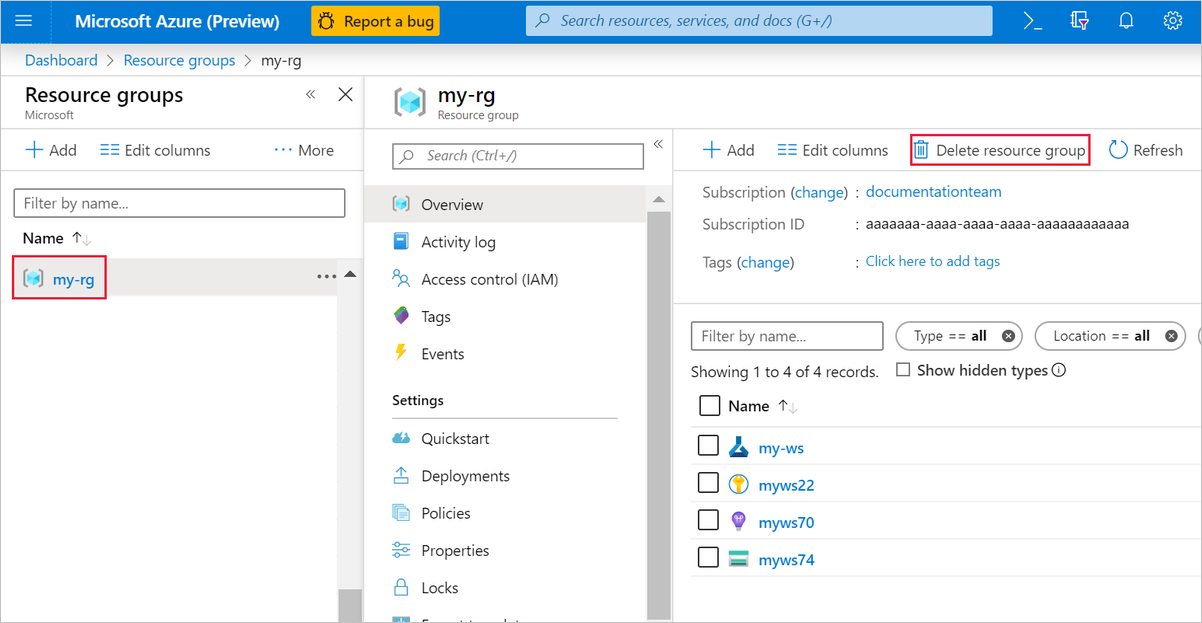
I listan väljer du den resursgrupp som du skapade.
Välj Ta bort resursgrupp.
Om du tar bort resursgruppen tas även alla resurser som du skapade i designern bort.
Ta bort enskilda tillgångar
I designern där du skapade experimentet tar du bort enskilda tillgångar genom att välja dem och sedan välja knappen Ta bort .
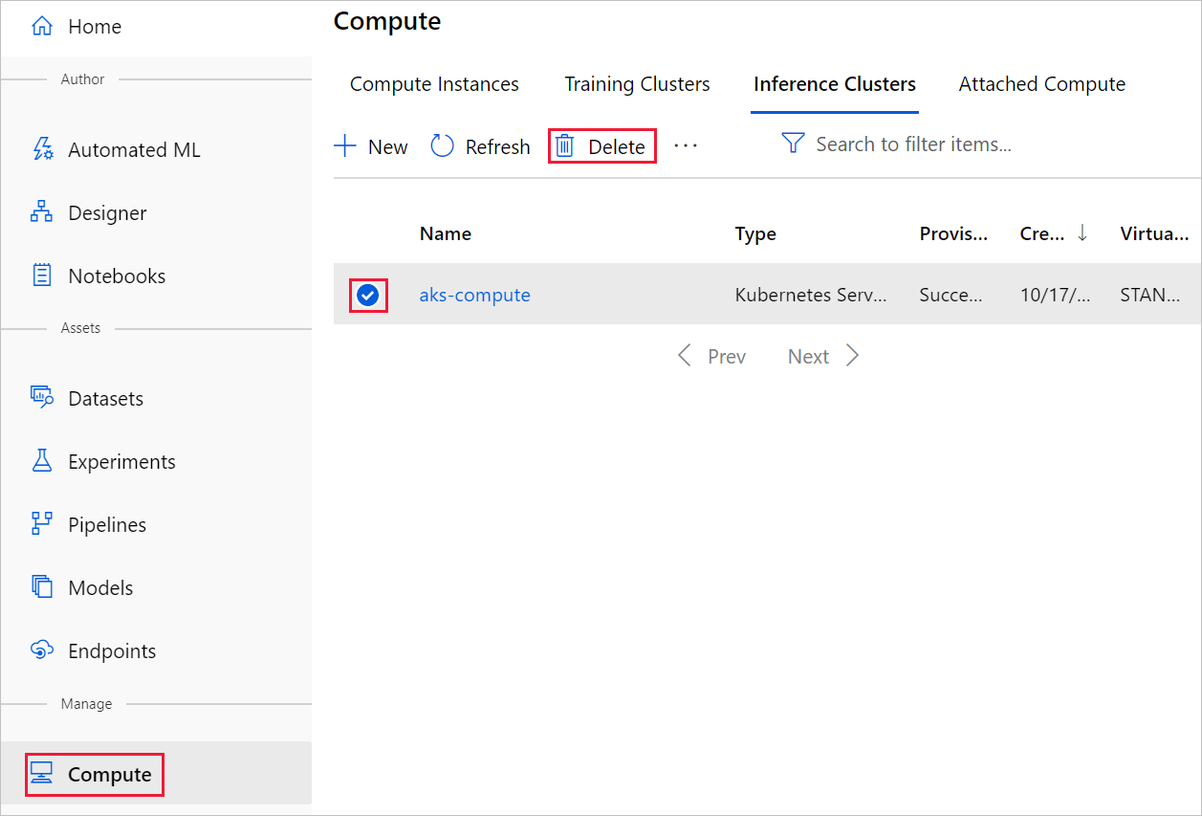
Beräkningsmålet som du skapade här skalar automatiskt till noll noder när det inte används. Den här åtgärden vidtas för att minimera avgifterna. Om du vill ta bort beräkningsmålet gör du följande:
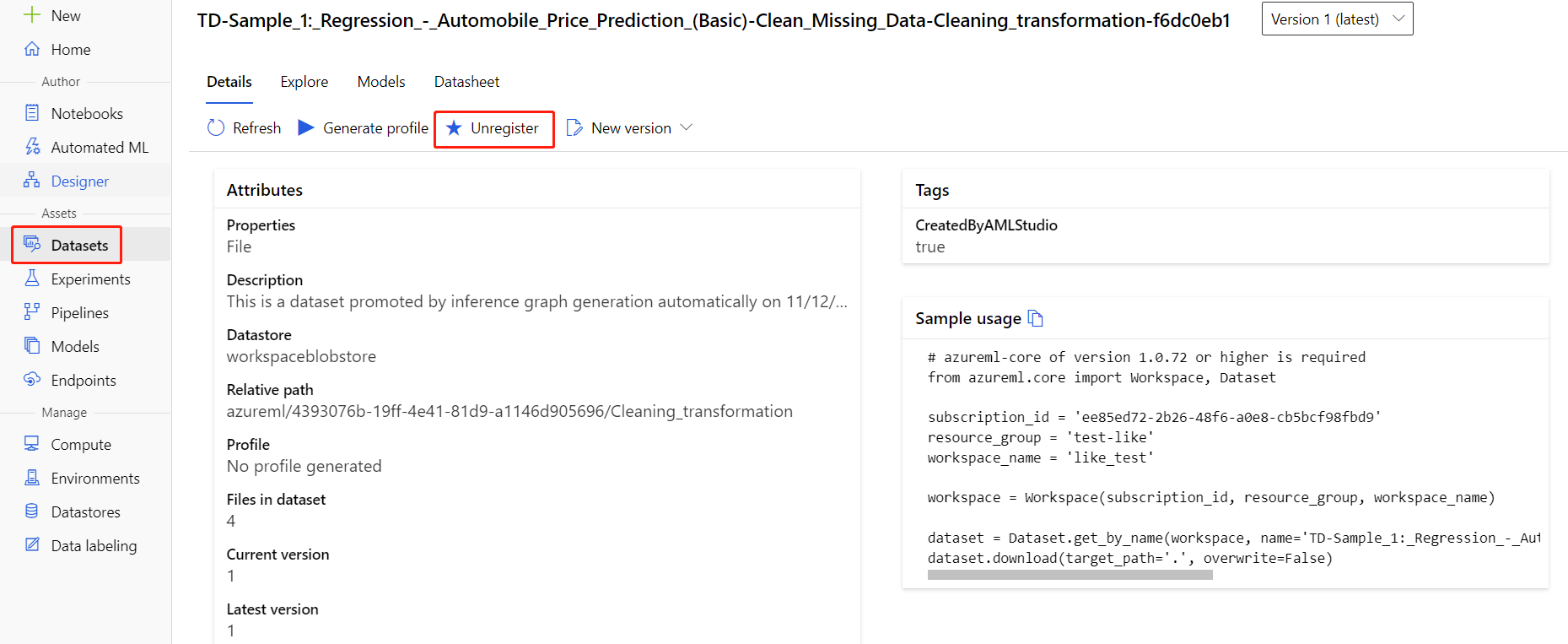
Du kan avregistrera datauppsättningar från din arbetsyta genom att välja varje datauppsättning och välja Avregistrera.
Om du vill ta bort en datauppsättning går du till lagringskontot med hjälp av Azure-portalen eller Azure Storage Explorer och tar bort dessa tillgångar manuellt.
Relaterat innehåll
I den här självstudien har du lärt dig hur du skapar, distribuerar och använder en maskininlärningsmodell i designern. Mer information om hur du kan använda designern finns i följande artiklar: