Distribuera maskininlärningsmodeller till Azure
GÄLLER FÖR: Azure CLI ml-tillägg v1Python SDK azureml v1
Azure CLI ml-tillägg v1Python SDK azureml v1
Lär dig hur du distribuerar din maskininlärnings- eller djupinlärningsmodell som en webbtjänst i Azure-molnet.
Anteckning
Azure Machine Learning-slutpunkter (v2) ger en förbättrad och enklare distributionsupplevelse. Slutpunkter stöder både realtids- och batchinferensscenarier. Slutpunkter tillhandahåller ett enhetligt gränssnitt för att anropa och hantera modelldistributioner mellan beräkningstyper. Se Vad är Azure Machine Learning-slutpunkter?.
Arbetsflöde för att distribuera en modell
Arbetsflödet är ungefär likadant var du än distribuerar din modell:
- Registrera modellen.
- Förbered ett postskript.
- Förbered en slutsatsdragningskonfiguration.
- Distribuera modellen lokalt för att säkerställa att allt fungerar.
- Välj ett beräkningsmål.
- Distribuera modellen till molnet.
- Testa den resulterande webbtjänsten.
Mer information om begreppen i arbetsflödet för distribution av maskininlärning finns i Hantera, distribuera och övervaka modeller med Azure Machine Learning.
Förutsättningar
GÄLLER FÖR:Azure CLI ml-tillägg v1
Viktigt
Azure CLI-kommandona i den här artikeln kräverazure-cli-mltillägget , eller v1, för Azure Machine Learning. Stödet för v1-tillägget upphör den 30 september 2025. Du kommer att kunna installera och använda v1-tillägget fram till det datumet.
Vi rekommenderar att du övergår till mltillägget , eller v2, före den 30 september 2025. Mer information om v2-tillägget finns i Azure ML CLI-tillägget och Python SDK v2.
- En Azure Machine Learning-arbetsyta. Mer information finns i Skapa arbetsyteresurser.
- En modell. Exemplen i den här artikeln använder en förtränad modell.
- En dator som kan köra Docker, till exempel en beräkningsinstans.
Anslut till arbetsytan
GÄLLER FÖR:Azure CLI ml-tillägg v1
Om du vill se de arbetsytor som du har åtkomst till använder du följande kommandon:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registrera modellen
En vanlig situation för en distribuerad maskininlärningstjänst är att du behöver följande komponenter:
- Resurser som representerar den specifika modell som du vill distribuera (till exempel en pytorchmodellfil).
- Kod som du kommer att köra i tjänsten som kör modellen på en viss indata.
Med Azure Machine Learning kan du dela upp distributionen i två separata komponenter, så att du kan behålla samma kod, men bara uppdatera modellen. Vi definierar den mekanism som du laddar upp en modell med separat från din kod som "registrera modellen".
När du registrerar en modell laddar vi upp modellen till molnet (i din arbetsytas standardlagringskonto) och monterar den sedan på samma beräkning som där webbtjänsten körs.
Följande exempel visar hur du registrerar en modell.
Viktigt
Du bör endast använda modeller som du har skapat eller som du har hämtat från en betrodd källa. Du bör behandla serialiserade modeller som kod eftersom säkerhetsrisker har identifierats i ett antal populära format. Dessutom kan modeller avsiktligt tränas för att ge vinklade eller felaktiga utdata.
GÄLLER FÖR:Azure CLI ml-tillägg v1
Följande kommandon laddar ned en modell och registrerar den sedan med din Azure Machine Learning-arbetsyta:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Ange -p sökvägen till en mapp eller en fil som du vill registrera.
Mer information om az ml model registerfinns i referensdokumentationen.
Registrera en modell från ett Azure Machine Learning-träningsjobb
Om du behöver registrera en modell som skapades tidigare via ett Azure Machine Learning-träningsjobb kan du ange experimentet, körningen och sökvägen till modellen:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Parametern --asset-path refererar till modellens molnplats. I det här exemplet används sökvägen till en enda fil. Om du vill inkludera flera filer i modellregistreringen anger du --asset-path sökvägen till en mapp som innehåller filerna.
Mer information om az ml model registerfinns i referensdokumentationen.
Anteckning
Du kan också registrera en modell från en lokal fil via arbetsytegränssnittsportalen.
För närvarande finns det två alternativ för att ladda upp en lokal modellfil i användargränssnittet:
- Från lokala filer, som registrerar en v2-modell.
- Från lokala filer (baserat på ramverk), som registrerar en v1-modell.
Observera att endast modeller som registrerats via ingångarna Från lokala filer (baserat på ramverk) (som kallas v1-modeller) kan distribueras som webbtjänster med hjälp av SDKv1/CLIv1.
Definiera ett dummy-postskript
Startskriptet tar emot data som skickas till en distribuerad webbtjänst och skickar dem vidare till modellen. Den returnerar sedan modellens svar till klienten. Skriptet är specifikt för din modell. Inmatningsskriptet måste förstå de data som modellen förväntar sig och returnerar.
De två saker som du behöver utföra i ditt inmatningsskript är:
- Läsa in din modell (med hjälp av en funktion som heter
init()) - Köra din modell på indata (med hjälp av en funktion som kallas
run())
För den första distributionen använder du ett dummy-inmatningsskript som skriver ut de data som den tar emot.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Spara den här filen i en katalog med echo_score.py namnet source_dir. Det här dummyskriptet returnerar de data som du skickar till den, så den använder inte modellen. Men det är användbart för att testa att bedömningsskriptet körs.
Definiera en slutsatsdragningskonfiguration
En slutsatsdragningskonfiguration beskriver dockercontainern och filerna som ska användas när webbtjänsten initieras. Alla filer i källkatalogen, inklusive underkataloger, kommer att zippas upp och laddas upp till molnet när du distribuerar webbtjänsten.
Härledningskonfigurationen nedan anger att maskininlärningsdistributionen ska använda filen echo_score.py i ./source_dir katalogen för att bearbeta inkommande begäranden och att den ska använda Docker-avbildningen med De Python-paket som anges i project_environment miljön.
Du kan använda valfri Azure Machine Learning-slutsatsdragning för organiserade miljöer som basavbildning för Docker när du skapar din projektmiljö. Vi installerar de nödvändiga beroendena ovanpå och lagrar den resulterande Docker-avbildningen på lagringsplatsen som är associerad med din arbetsyta.
Anteckning
Källkataloguppladdningen för Azure Machine Learning-inferens respekterar inte .gitignore eller .amlignore
GÄLLER FÖR:Azure CLI ml-tillägg v1
En minimal inferenskonfiguration kan skrivas som:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Spara filen med namnet dummyinferenceconfig.json.
I den här artikeln finns en mer ingående beskrivning av slutsatsdragningskonfigurationer.
Definiera en distributionskonfiguration
En distributionskonfiguration anger mängden minne och kärnor som din webbtjänst behöver för att kunna köras. Den innehåller också konfigurationsinformation om den underliggande webbtjänsten. Med en distributionskonfiguration kan du till exempel ange att tjänsten behöver 2 gigabyte minne, 2 CPU-kärnor, 1 GPU-kärna och att du vill aktivera autoskalning.
Vilka alternativ som är tillgängliga för en distributionskonfiguration varierar beroende på vilket beräkningsmål du väljer. I en lokal distribution kan du bara ange vilken port din webbtjänst ska hanteras på.
GÄLLER FÖR:Azure CLI ml-tillägg v1
Posterna i dokumentmappningen deploymentconfig.json till parametrarna för LocalWebservice.deploy_configuration. I följande tabell beskrivs mappningen mellan entiteterna i JSON-dokumentet och parametrarna för metoden:
| JSON-entitet | Metodparameter | Beskrivning |
|---|---|---|
computeType |
NA | Beräkningsmålet. För lokala mål måste värdet vara local. |
port |
port |
Den lokala porten som tjänstens HTTP-slutpunkt ska exponeras på. |
Denna JSON är ett exempel på distributionskonfiguration för användning med CLI:
{
"computeType": "local",
"port": 32267
}
Spara den här JSON-filen som en fil med namnet deploymentconfig.json.
Mer information finns i distributionsschemat.
Distribuera din maskininlärningsmodell
Nu är du redo att distribuera din modell.
GÄLLER FÖR:Azure CLI ml-tillägg v1
Ersätt bidaf_onnx:1 med namnet på din modell och dess versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Anropa din modell
Nu ska vi kontrollera att ekomodellen har distribuerats. Du bör kunna göra en enkel liveness-begäran, samt en bedömningsbegäran:
GÄLLER FÖR:Azure CLI ml-tillägg v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definiera ett inmatningsskript
Nu är det dags att faktiskt läsa in din modell. Ändra först inmatningsskriptet:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Spara den här filen som score.py inuti source_dir.
Observera användningen av AZUREML_MODEL_DIR miljövariabeln för att hitta den registrerade modellen. Nu när du har lagt till några pip-paket.
GÄLLER FÖR:Azure CLI ml-tillägg v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Spara filen som inferenceconfig.json
Distribuera igen och anropa tjänsten
Distribuera tjänsten igen:
GÄLLER FÖR:Azure CLI ml-tillägg v1
Ersätt bidaf_onnx:1 med namnet på din modell och dess versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Se sedan till att du kan skicka en postbegäran till tjänsten:
GÄLLER FÖR:Azure CLI ml-tillägg v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Välj ett beräkningsmål
Beräkningsmålet som du använder som värd för din modell påverkar kostnaden och tillgängligheten för den distribuerade slutpunkten. Använd den här tabellen för att välja ett lämpligt beräkningsmål.
| Beräkningsmål | Används för | GPU-stöd | Beskrivning |
|---|---|---|---|
| Lokal webbtjänst | Testa/felsöka | Använd för begränsad testning och felsökning. Maskinvaruacceleration beror på användningen av bibliotek i det lokala systemet. | |
| Azure Machine Learning-slutpunkter (endast SDK/CLI v2) | Slutsatsdragning i realtid Batch-slutsatsdragning |
Ja | Fullständigt hanterade beräkningar för realtid (hanterade onlineslutpunkter) och batchbedömning (batchslutpunkter) på serverlös beräkning. |
| Azure Machine Learning Kubernetes | Slutsatsdragning i realtid Batch-slutsatsdragning |
Ja | Kör slutsatsdragning av arbetsbelastningar på lokala Kubernetes-kluster, i molnet och på gränsenheter. |
| Azure Container Instances (endast SDK/CLI v1) | Slutsatsdragning i realtid Rekommenderas endast i utvecklings-/testsyfte. |
Används för lågskalig CPU-baserade arbetsbelastningar som kräver mindre än 48 GB RAM-minne. Kräver inte att du hanterar ett kluster. Stöds i designern. |
Anteckning
När du väljer en kluster-SKU skalar du först upp och sedan ut. Börja med en dator som har 150 % av det RAM-minne som din modell kräver, profilera resultatet och hitta en dator som har den prestanda du behöver. När du har lärt dig det ökar du antalet datorer så att de passar ditt behov av samtidig slutsatsdragning.
Anteckning
Containerinstanser kräver SDK eller CLI v1 och är endast lämpliga för små modeller som är mindre än 1 GB.
Distribuera till molnet
När du har bekräftat att tjänsten fungerar lokalt och valt ett fjärrberäkningsmål är du redo att distribuera till molnet.
Ändra distributionskonfigurationen så att den motsvarar det beräkningsmål som du har valt, i det här fallet Azure Container Instances:
GÄLLER FÖR:Azure CLI ml-tillägg v1
Vilka alternativ som är tillgängliga för en distributionskonfiguration varierar beroende på vilket beräkningsmål du väljer.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Spara filen som re-deploymentconfig.json.
Mer information finns i den här referensen.
Distribuera tjänsten igen:
GÄLLER FÖR:Azure CLI ml-tillägg v1
Ersätt bidaf_onnx:1 med namnet på din modell och dess versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Om du vill visa tjänstloggarna använder du följande kommando:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Anropa fjärrwebbtjänsten
När du distribuerar via fjärranslutning kan nyckelautentisering vara aktiverat. Exemplet nedan visar hur du hämtar din tjänstnyckel med Python för att göra en slutsatsdragningsbegäran.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Se artikeln om klientprogram för att använda webbtjänster för fler exempelklienter på andra språk.
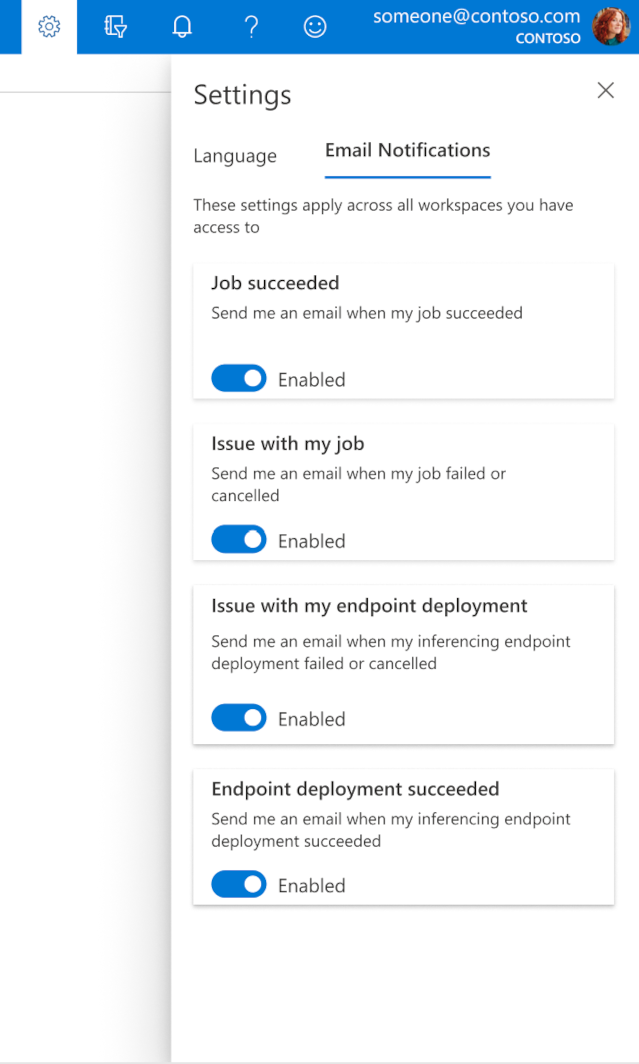
Så här konfigurerar du e-postmeddelanden i studio
Om du vill börja ta emot e-postmeddelanden när jobbet, onlineslutpunkten eller batchslutpunkten har slutförts eller om det finns ett problem (misslyckades, avbröts) använder du följande steg:
- I Azure ML Studio går du till inställningar genom att välja kugghjulsikonen.
- Välj fliken Email meddelanden.
- Växla om du vill aktivera eller inaktivera e-postaviseringar för en viss händelse.
Förstå tjänsttillstånd
Under modelldistributionen kan tjänsttillståndet ändras medan det distribueras fullständigt.
I följande tabell beskrivs de olika tjänsttillstånden:
| Webbtjänsttillstånd | Beskrivning | Slutligt tillstånd? |
|---|---|---|
| Övergång | Tjänsten håller på att distribueras. | Inga |
| Ohälsosamt | Tjänsten har distribuerats men kan för närvarande inte nås. | Inga |
| Ej schemalagt | Tjänsten kan inte distribueras just nu på grund av brist på resurser. | Inga |
| Misslyckad | Det gick inte att distribuera tjänsten på grund av ett fel eller en krasch. | Ja |
| Felfri | Tjänsten är felfri och slutpunkten är tillgänglig. | Ja |
Tips
När du distribuerar skapas och läses Docker-avbildningar för beräkningsmål in från Azure Container Registry (ACR). Som standard skapar Azure Machine Learning en ACR som använder den grundläggande tjänstnivån. Om du ändrar ACR för din arbetsyta till standard- eller premiumnivå kan det minska den tid det tar att skapa och distribuera avbildningar till dina beräkningsmål. Mer information finns i Azure Container Registry-tjänstnivåer (ACR).
Anteckning
Om du distribuerar en modell till Azure Kubernetes Service (AKS) rekommenderar vi att du aktiverar Azure Monitor för klustret. Detta hjälper dig att förstå övergripande klusterhälsa och resursanvändning. Följande resurser kan också vara användbara:
- Sök efter Resource Health-händelser som påverkar ditt AKS-kluster
- Azure Kubernetes Service-diagnostik
Om du försöker distribuera en modell till ett felaktigt eller överbelastat kluster är det väntat att det uppstår problem. Kontakta AKS-supporten om du behöver hjälp med att felsöka problem med AKS-kluster.
Ta bort resurser
GÄLLER FÖR:Azure CLI ml-tillägg v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Om du vill ta bort en distribuerad webbtjänst använder du az ml service delete <name of webservice>.
Om du vill ta bort en registrerad modell från din arbetsyta använder du az ml model delete <model id>
Läs mer om att ta bort en webbtjänst och ta bort en modell.
Nästa steg
- Felsöka en misslyckad distribution
- Uppdatera webbtjänst
- Distribution med ett klick för automatiserade ML-körningar i Azure Machine Learning-studio
- Använda TLS för att skydda en webbtjänst via Azure Machine Learning
- Övervaka dina Azure Machine Learning-modeller med Application Insights
- Skapa händelseaviseringar och utlösare för modelldistributioner