Identifiera dataavvikelser (förhandsversion) för datauppsättningar
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Lär dig hur du övervakar dataavvikelser och anger aviseringar när driften är hög.
Med Azure Machine Learning-datauppsättningsövervakare (förhandsversion) kan du:
- Analysera avvikelser i dina data för att förstå hur de ändras över tid.
- Övervaka modelldata för skillnader mellan tränings- och serveringsdatauppsättningar. Börja med att samla in modelldata från distribuerade modeller.
- Övervaka nya data för skillnader mellan en baslinje- och måldatauppsättning.
- Profilera funktioner i data för att spåra hur statistiska egenskaper ändras över tid.
- Konfigurera aviseringar om dataavvikelser för tidiga varningar om potentiella problem.
- Skapa en ny datamängdsversion när du bedömer att data har drivit för mycket.
En Azure Machine Learning-datauppsättning används för att skapa övervakaren. Datauppsättningen måste innehålla en tidsstämpelkolumn.
Du kan visa mått för dataavvikelser med Python SDK eller i Azure Machine Learning-studio. Andra mått och insikter är tillgängliga via resursen Azure Application Insights som är associerad med Azure Machine Learning-arbetsytan.
Viktigt
Identifiering av dataavvikelser för datauppsättningar finns för närvarande i offentlig förhandsversion. Förhandsversionen tillhandahålls utan serviceavtal och rekommenderas inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Förutsättningar
Om du vill skapa och arbeta med datauppsättningsövervakare behöver du:
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning idag.
- En Azure Machine Learning-arbetsyta.
- Azure Machine Learning SDK för Python installerat, som innehåller paketet azureml-datasets.
- Strukturerade data (tabell) med en tidsstämpel som anges i filsökvägen, filnamnet eller kolumnen i data.
Vad är dataavvikelse?
Dataavvikelser är en av de främsta orsakerna till att modellprecisionen försämras med tiden. För maskininlärningsmodeller är dataavvikelsen den förändring av modellindata som leder till försämrad modellprestanda. Genom att övervaka dataavvikelser kan du identifiera dessa modellprestandaproblem.
Orsaker till dataavvikelser är:
- Uppströms processändringar, till exempel en sensor som byts ut som ändrar måttenheterna från tum till centimeter.
- Problem med datakvalitet, till exempel att en trasig sensor alltid läser 0.
- Naturliga avvikelser i data, till exempel att medeltemperaturen ändras med årstiderna.
- Ändring i förhållande mellan funktioner eller kovariansväxling.
Azure Machine Learning förenklar avvikelseidentifieringen genom att beräkna ett enda mått som abstraherar komplexiteten hos de datauppsättningar som jämförs. Dessa datauppsättningar kan ha hundratals funktioner och tiotusentals rader. När avvikelsen har identifierats ökar du detaljnivån för vilka funktioner som orsakar avvikelsen. Sedan inspekterar du mått på funktionsnivå för att felsöka och isolera rotorsaken till avvikelsen.
Den här metoden gör det enkelt att övervaka data i stället för traditionella regelbaserade tekniker. Regelbaserade tekniker, till exempel tillåtna dataintervall eller tillåtna unika värden, kan vara tidskrävande och felbenägna.
I Azure Machine Learning använder du datauppsättningsövervakare för att identifiera och varna för dataavvikelser.
Datauppsättningsövervakare
Med en datamängdsövervakare kan du:
- Identifiera och varna för dataavvikelser på nya data i en datauppsättning.
- Analysera historiska data för avvikelse.
- Profilera nya data över tid.
Algoritmen för dataavvikelser ger ett övergripande mått på ändringar i data och anger vilka funktioner som är ansvariga för vidare undersökning. Datamängdsövervakare genererar ett antal andra mått genom att profilera nya data i datauppsättningen timeseries .
Anpassade aviseringar kan konfigureras för alla mått som genereras av övervakaren via Azure Application Insights. Datauppsättningsövervakare kan användas för att snabbt fånga upp dataproblem och minska tiden för att felsöka problemet genom att identifiera troliga orsaker.
Konceptuellt finns det tre primära scenarier för att konfigurera datauppsättningsövervakare i Azure Machine Learning.
| Scenario | Beskrivning |
|---|---|
| Övervaka en modells betjänande data för avvikelse från träningsdata | Resultat från det här scenariot kan tolkas som övervakning av en proxy för modellens noggrannhet, eftersom modellprecisionen försämras när betjänande data avviker från träningsdata. |
| Övervaka en tidsseriedatauppsättning för avvikelse från en tidigare tidsperiod. | Det här scenariot är mer allmänt och kan användas för att övervaka datauppsättningar som ingår uppströms eller nedströms i modellbyggandet. Måldatauppsättningen måste ha en tidsstämpelkolumn. Baslinjedatauppsättningen kan vara valfri tabelldatauppsättning som har gemensamma funktioner med måldatauppsättningen. |
| Utföra analys på tidigare data. | Det här scenariot kan användas för att förstå historiska data och fatta beslut i inställningarna för datauppsättningsövervakare. |
Övervakare av datauppsättningar beror på följande Azure-tjänster.
| Azure-tjänst | Beskrivning |
|---|---|
| Datamängd | Drift använder Machine Learning-datauppsättningar för att hämta träningsdata och jämföra data för modellträning. Genereringsprofil för data används för att generera några av de rapporterade måtten, till exempel min, max, distinkta värden, distinkta värden. |
| Azureml-pipeline och beräkning | Avvikelseberäkningsjobbet finns i azureml-pipelinen. Jobbet utlöses på begäran eller enligt schema för att köras på en beräkning som konfigurerats vid skapandetiden för driftövervakaren. |
| Application Insights | Drift genererar mått till Application Insights som hör till maskininlärningsarbetsytan. |
| Azure Blob Storage | Drift genererar mått i json-format till Azure Blob Storage. |
Baslinje- och måldatauppsättningar
Du övervakar Azure Machine Learning-datauppsättningar för dataavvikelser. När du skapar en datauppsättningsövervakare refererar du till följande:
- Baslinjedatauppsättning – vanligtvis träningsdatauppsättningen för en modell.
- Måldatauppsättningen – vanligtvis modellindata – jämförs med din baslinjedatauppsättning över tid. Den här jämförelsen innebär att måldatauppsättningen måste ha en angiven tidsstämpelkolumn.
Övervakaren jämför baslinje- och måldatauppsättningarna.
Skapa måldatauppsättning
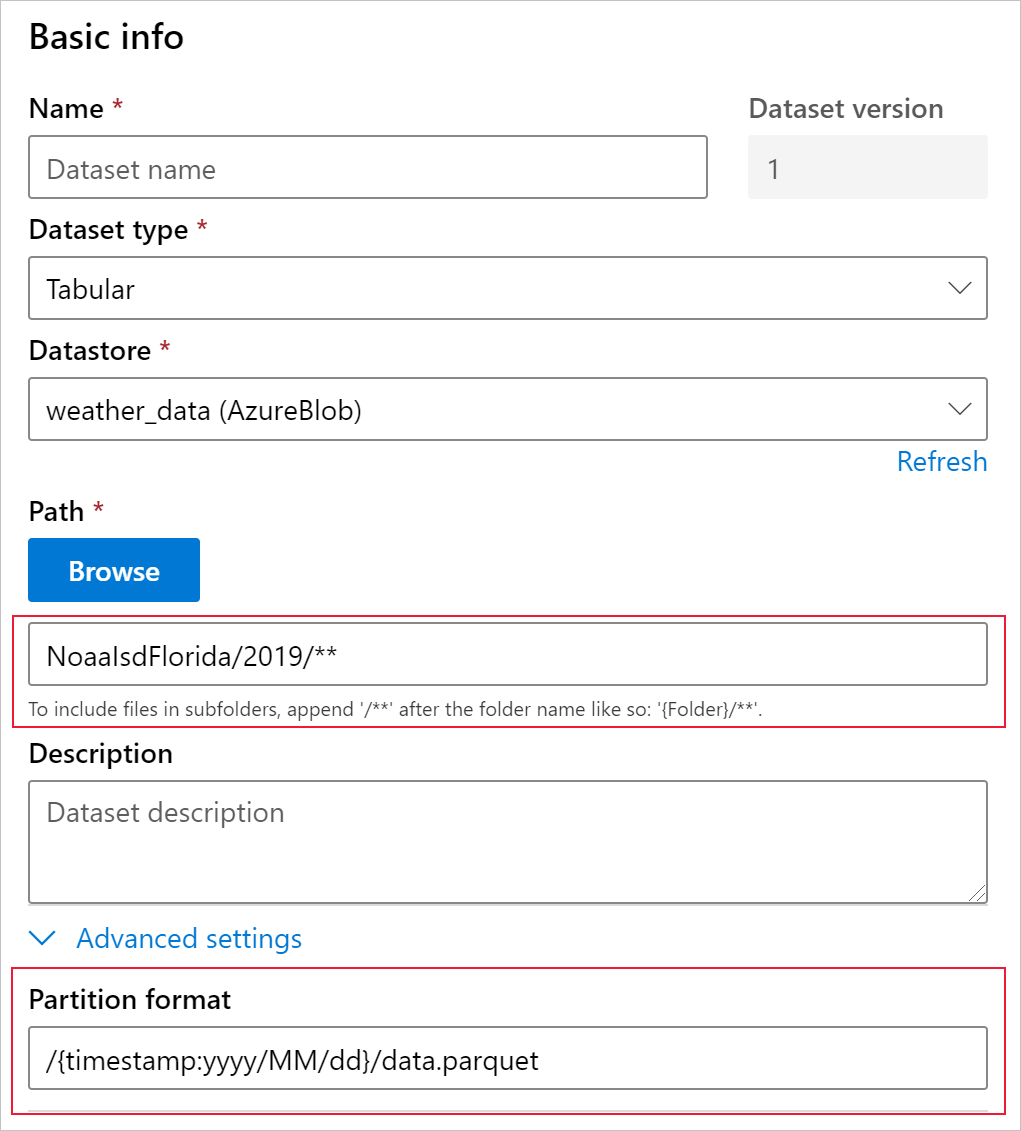
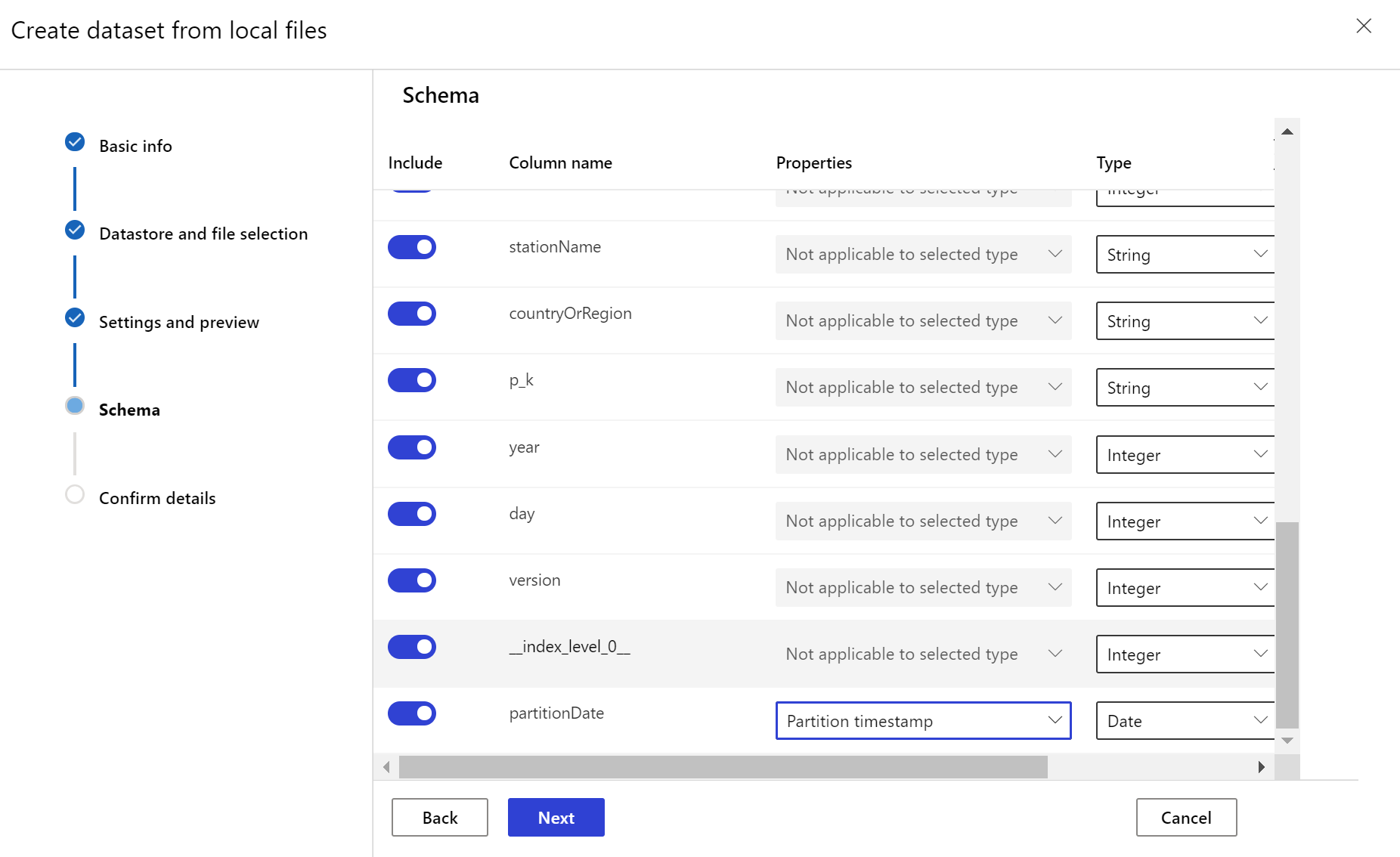
Måldatauppsättningen behöver egenskapen timeseries som angetts på den genom att ange tidsstämpelkolumnen antingen från en kolumn i data eller en virtuell kolumn som härletts från filernas sökvägsmönster. Skapa datauppsättningen med en tidsstämpel via Python SDK eller Azure Machine Learning-studio. En kolumn som representerar en "tidsstämpel" måste anges för att lägga timeseries till egenskap i datauppsättningen. Om dina data är partitionerade i mappstrukturen med tidsinformation, till exempel {åå/MM/dd}, skapar du en virtuell kolumn via sökvägsmönsterinställningen och anger den som "partitionstidsstämpel" för att aktivera api-funktioner för tidsserier.
GÄLLER FÖR:Python SDK azureml v1
with_timestamp_columns() Klassmetoden Dataset definierar tidsstämpelkolumnen för datauppsättningen.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tips
Ett fullständigt exempel på hur du använder timeseries egenskapen för datauppsättningar finns i exempelanteckningsboken eller SDK-dokumentationen för datauppsättningar.
Skapa datauppsättningsövervakare
Skapa en datauppsättningsövervakare för att identifiera och varna för dataavvikelser på en ny datauppsättning. Använd antingen Python SDK eller Azure Machine Learning-studio.
GÄLLER FÖR:Python SDK azureml v1
Se Referensdokumentationen för Python SDK om dataavvikelse för fullständig information.
I följande exempel visas hur du skapar en datauppsättningsövervakare med hjälp av Python SDK
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Tips
Ett fullständigt exempel på hur du konfigurerar en timeseries datauppsättning och dataavvikelseidentifiering finns i vår exempelanteckningsbok.
Förstå dataavvikelseresultat
Det här avsnittet visar resultatet av övervakningen av en datauppsättning som finns på sidanDatamängdsdatauppsättningsövervakare / i Azure Studio. Du kan uppdatera inställningarna och analysera befintliga data under en viss tidsperiod på den här sidan.
Börja med insikter på den översta nivån om storleken på dataavvikelsen och en höjdpunkt på funktioner som ska undersökas ytterligare.
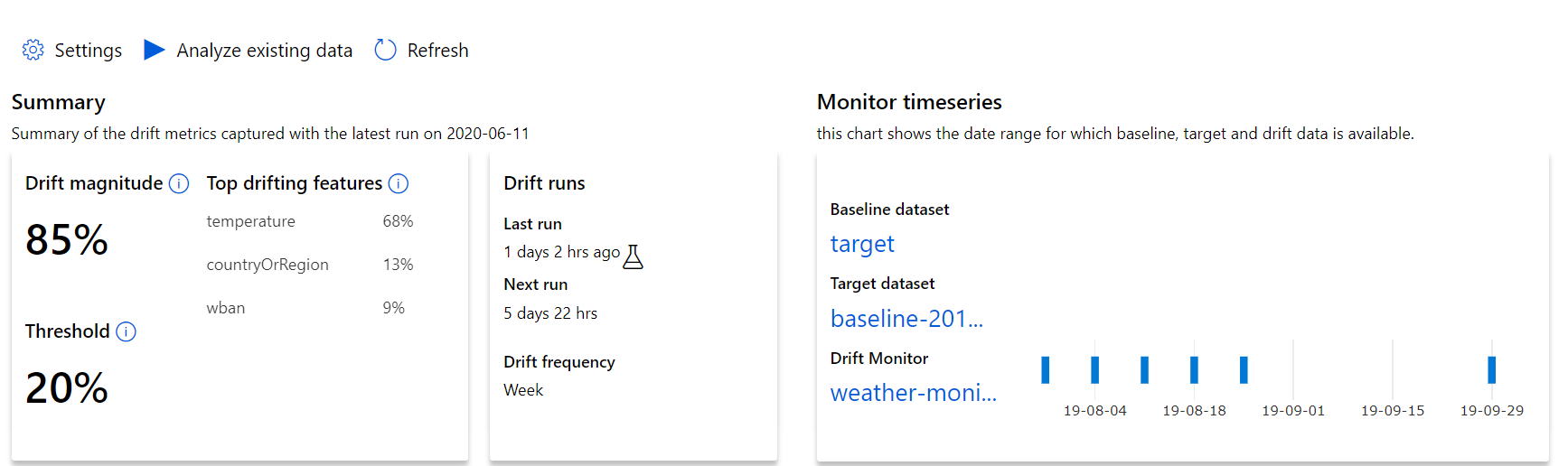
| Metric | Beskrivning |
|---|---|
| Storlek på dataavvikelse | En procentandel av avvikelsen mellan baslinjen och måldatauppsättningen över tid. Mellan 0 och 100 anger 0 identiska datamängder och 100 anger att Azure Machine Learning-dataavvikelsemodellen helt kan skilja de två datauppsättningarna åt. Brus i den exakta procentandelen som mäts förväntas på grund av maskininlärningstekniker som används för att generera den här storleken. |
| De främsta driftfunktionerna | Visar de funktioner från datauppsättningen som har drivit mest och därför bidrar mest till måttet Drift Magnitude. På grund av samvariatväxling behöver den underliggande fördelningen av en funktion inte nödvändigtvis ändras för att ha relativt hög funktionsvikt. |
| Tröskelvärde | Dataavvikelse utöver det angivna tröskelvärdet utlöser aviseringar. Detta kan konfigureras i övervakningsinställningarna. |
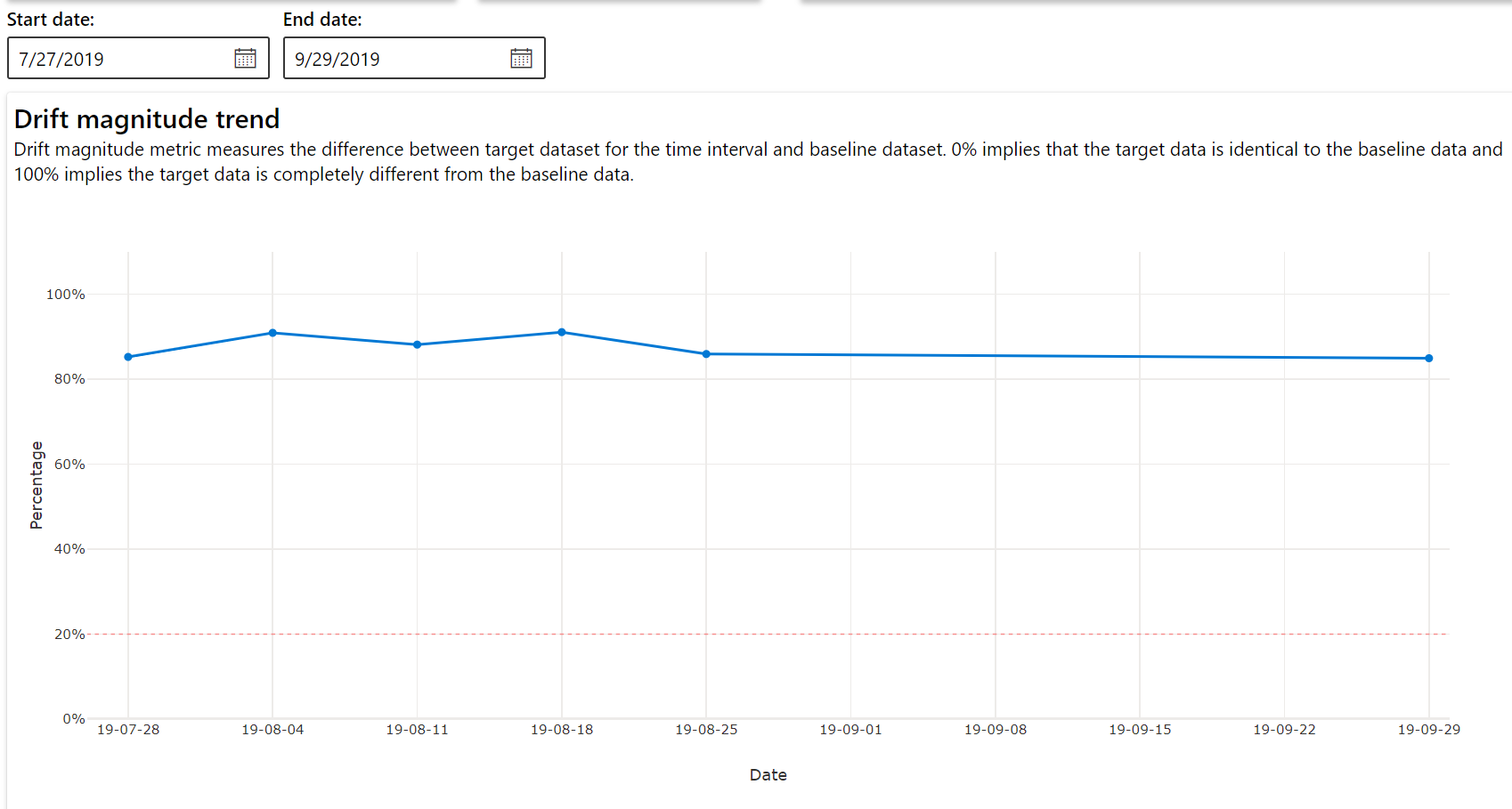
Trend för driftshärd
Se hur datauppsättningen skiljer sig från måldatauppsättningen under den angivna tidsperioden. Ju närmare 100 %, desto mer skiljer sig de två datauppsättningarna åt.
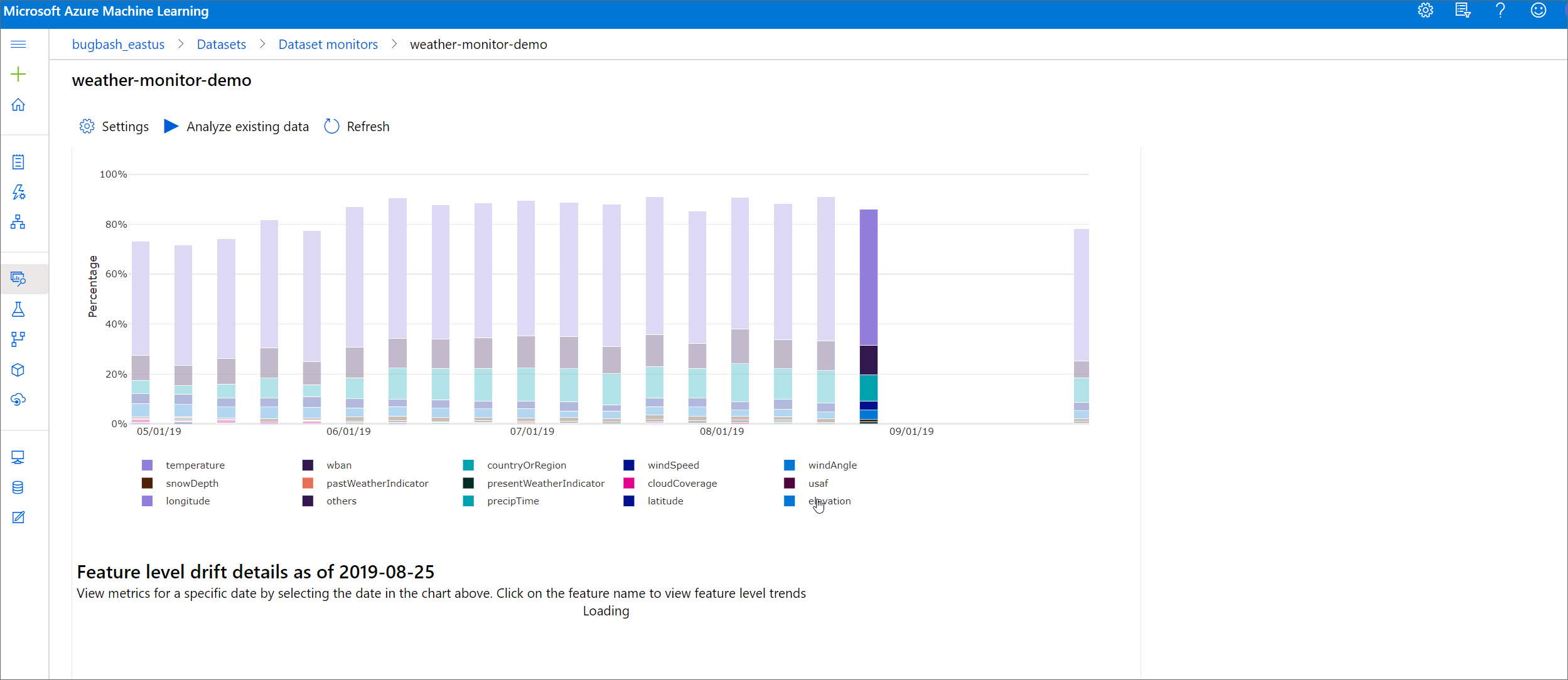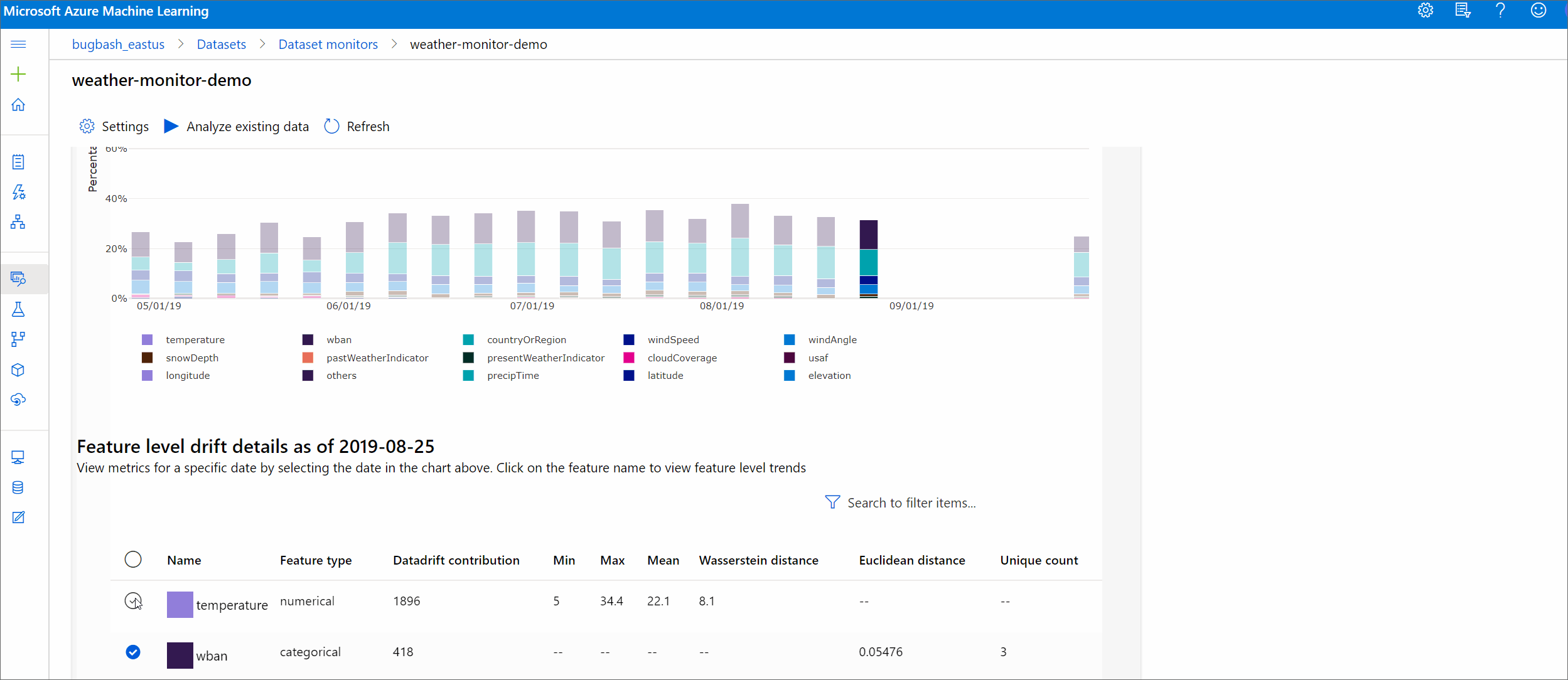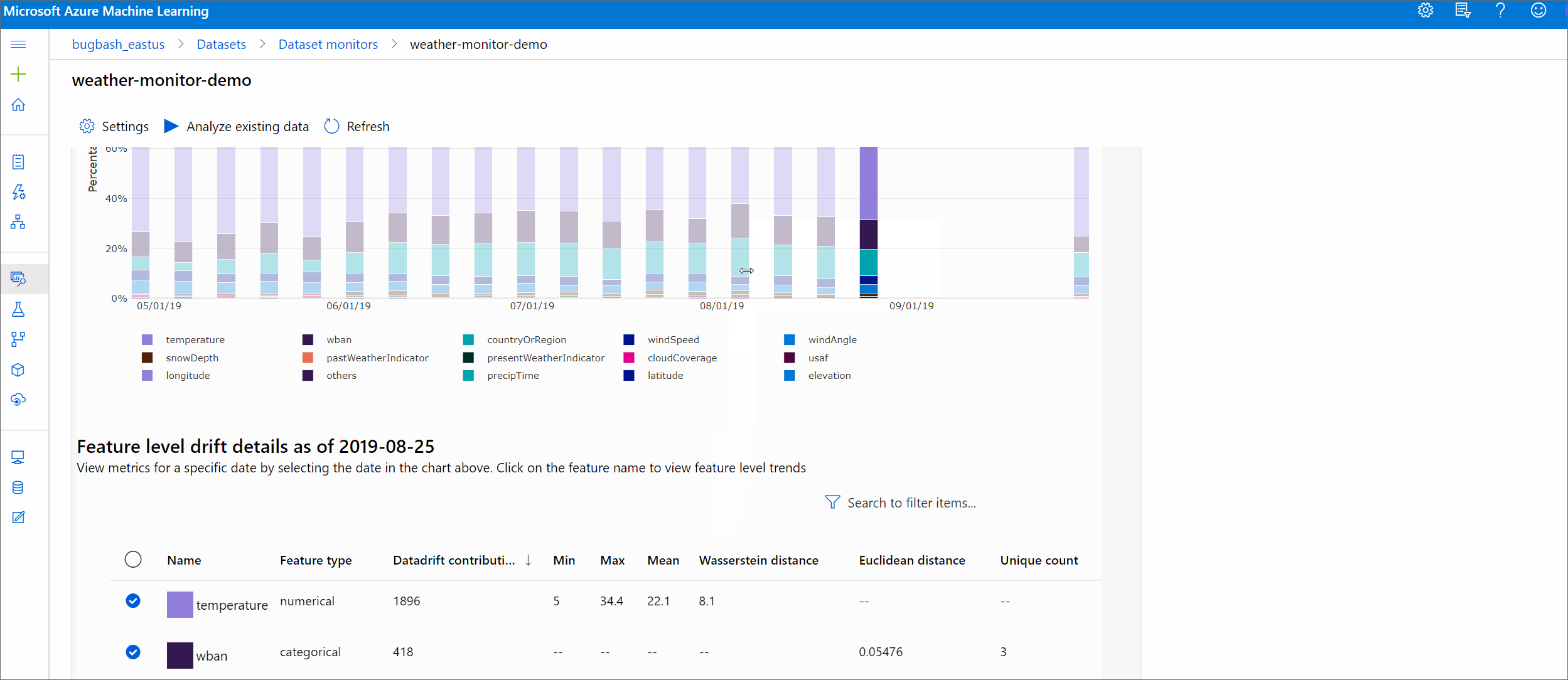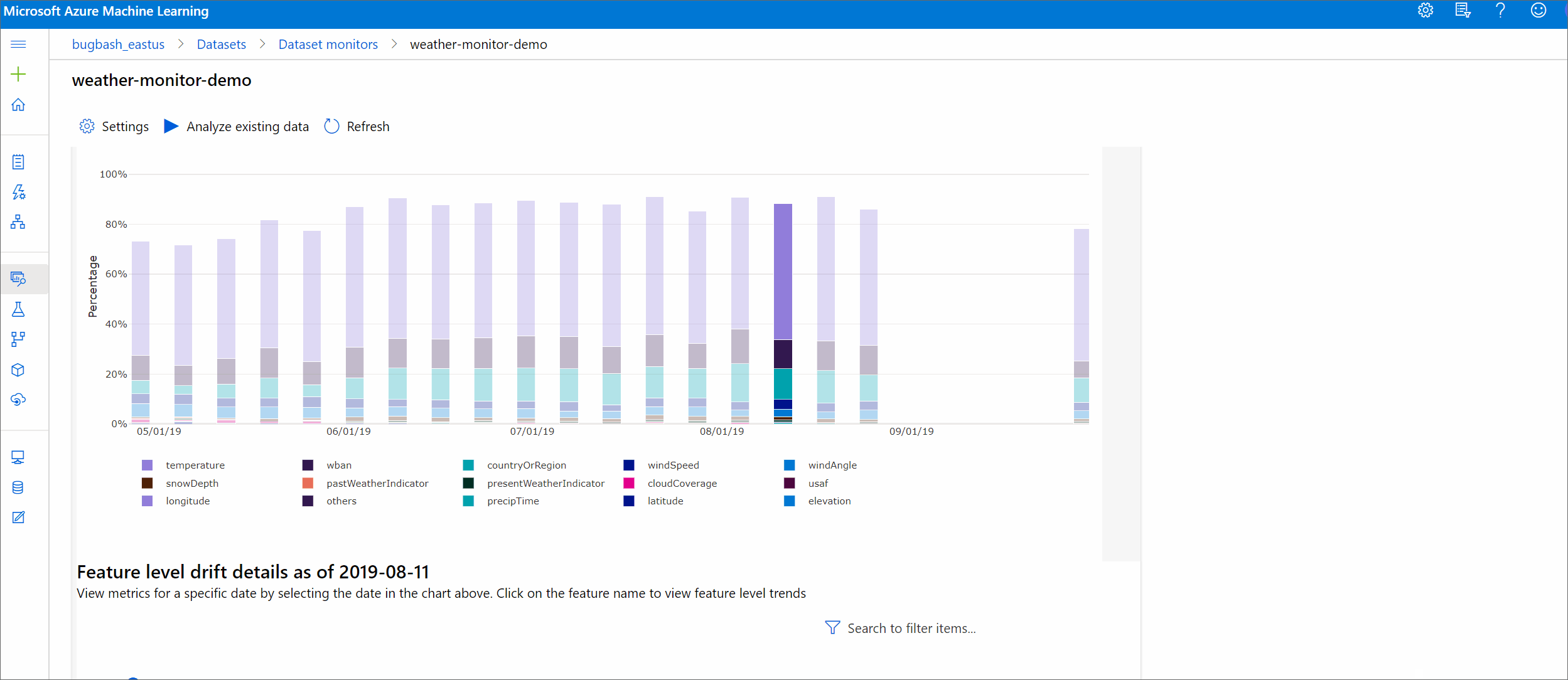
Driftsstorlek efter funktioner
Det här avsnittet innehåller insikter på funktionsnivå om ändringen av den valda funktionens distribution samt annan statistik över tid.
Måldatauppsättningen profileras också över tid. Det statistiska avståndet mellan baslinjefördelningen för varje funktion jämförs med måldatauppsättningens över tid. Konceptuellt liknar detta dataavvikelsens storlek. Det här statistiska avståndet gäller dock för en enskild funktion snarare än för alla funktioner. Min, max och medelvärde är också tillgängliga.
I Azure Machine Learning-studio klickar du på ett fält i diagrammet för att se information på funktionsnivå för det datumet. Som standard visas baslinjedatauppsättningens distribution och det senaste jobbets distribution av samma funktion.
Dessa mått kan också hämtas i Python SDK via get_metrics() metoden för ett DataDriftDetector -objekt.
Funktionsinformation
Rulla slutligen ned för att visa information om varje enskild funktion. Använd listrutorna ovanför diagrammet för att välja funktionen och välj dessutom det mått som du vill visa.
Måtten i diagrammet beror på typen av funktion.
Numeriska funktioner
Metric Beskrivning Wassersteinavstånd Minsta mängd arbete för att omvandla baslinjedistributionen till målfördelningen. Medelvärde Genomsnittligt värde för funktionen. Minvärde Minsta värde för funktionen. Maxvärde Maximalt värde för funktionen. Kategoriska funktioner
Metric Beskrivning Euklidiskt avstånd Beräknas för kategoriska kolumner. Euklidiskt avstånd beräknas på två vektorer som genereras från empirisk fördelning av samma kategoriska kolumn från två datauppsättningar. 0 anger att det inte finns någon skillnad i de empiriska fördelningarna. Ju mer den avviker från 0, desto mer har den här kolumnen glidit. Trender kan observeras från ett tidsseriediagram för det här måttet och kan vara till hjälp när du ska upptäcka en drivande funktion. Unika värden Antal unika värden (kardinalitet) för funktionen.
I det här diagrammet väljer du ett enda datum för att jämföra funktionsfördelningen mellan målet och det här datumet för den visade funktionen. För numeriska funktioner visar detta två sannolikhetsfördelningar. Om funktionen är numerisk visas ett stapeldiagram.
Mått, aviseringar och händelser
Mått kan efterfrågas i resursen Azure Application Insights som är associerad med din maskininlärningsarbetsyta. Du har åtkomst till alla funktioner i Application Insights, inklusive konfiguration av anpassade aviseringsregler och åtgärdsgrupper för att utlösa en åtgärd, till exempel en Email/SMS/Push/Voice eller Azure Function. Mer information finns i den fullständiga Application Insights-dokumentationen.
Kom igång genom att gå till Azure Portal och välja arbetsytans översiktssida. Den associerade Application Insights-resursen finns längst till höger:
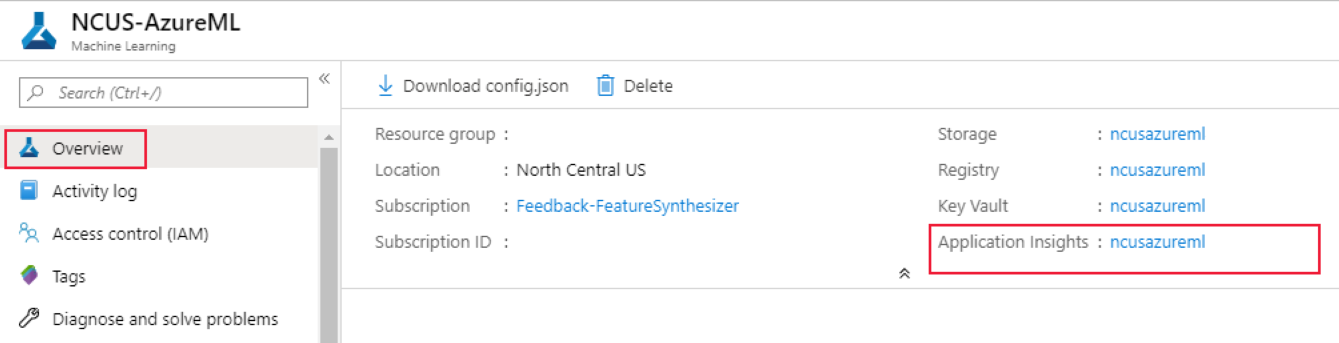
Välj Loggar (analys) under Övervakning i det vänstra fönstret:
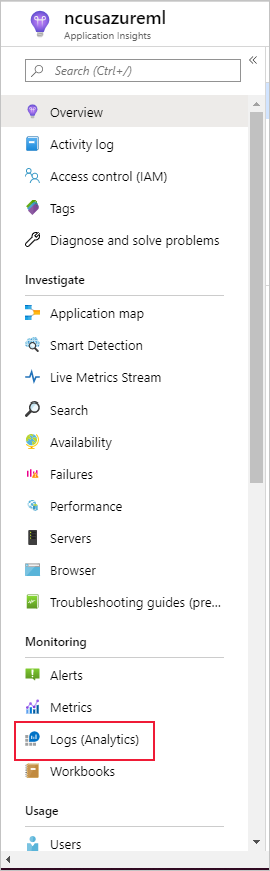
Datauppsättningens övervakningsmått lagras som customMetrics. Du kan skriva och köra en fråga när du har konfigurerat en datauppsättningsövervakare för att visa dem:
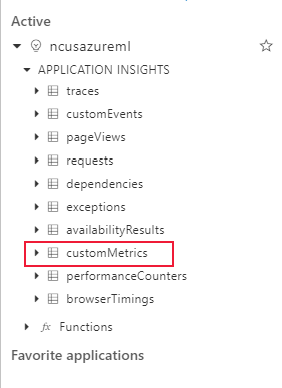
När du har identifierat mått för att konfigurera aviseringsregler skapar du en ny aviseringsregel:
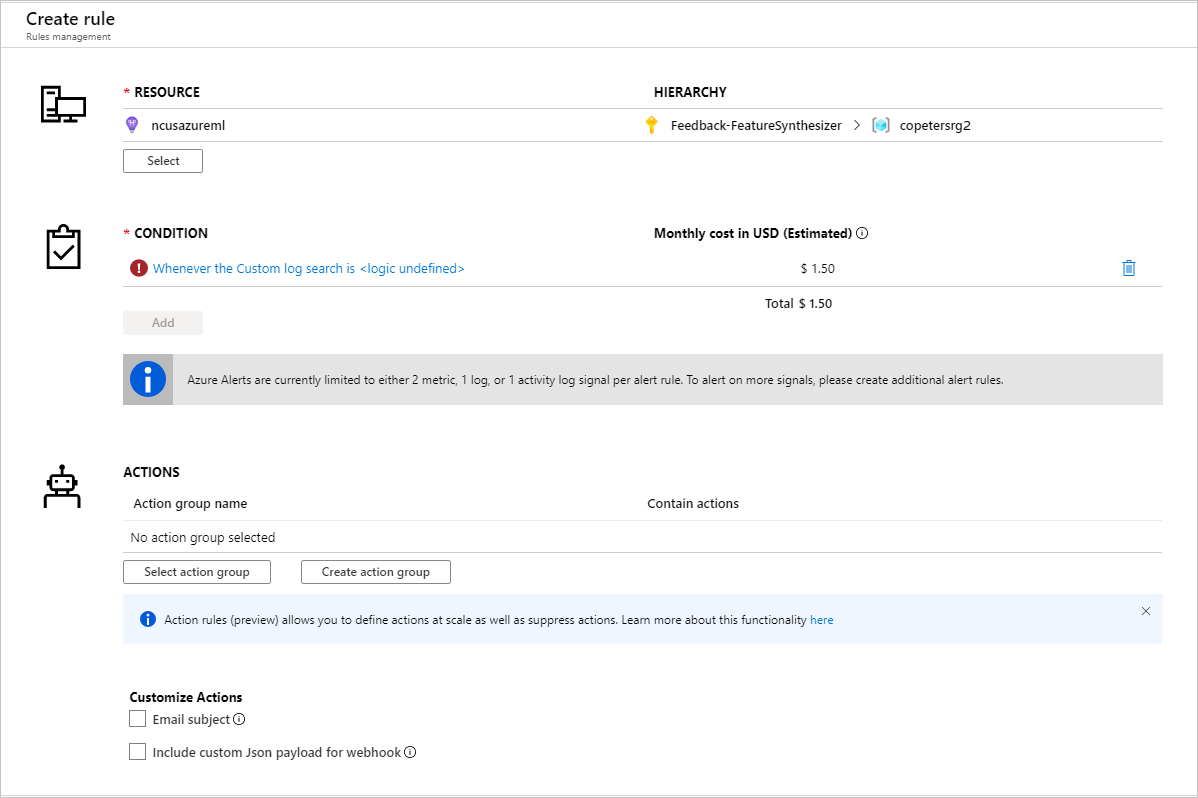
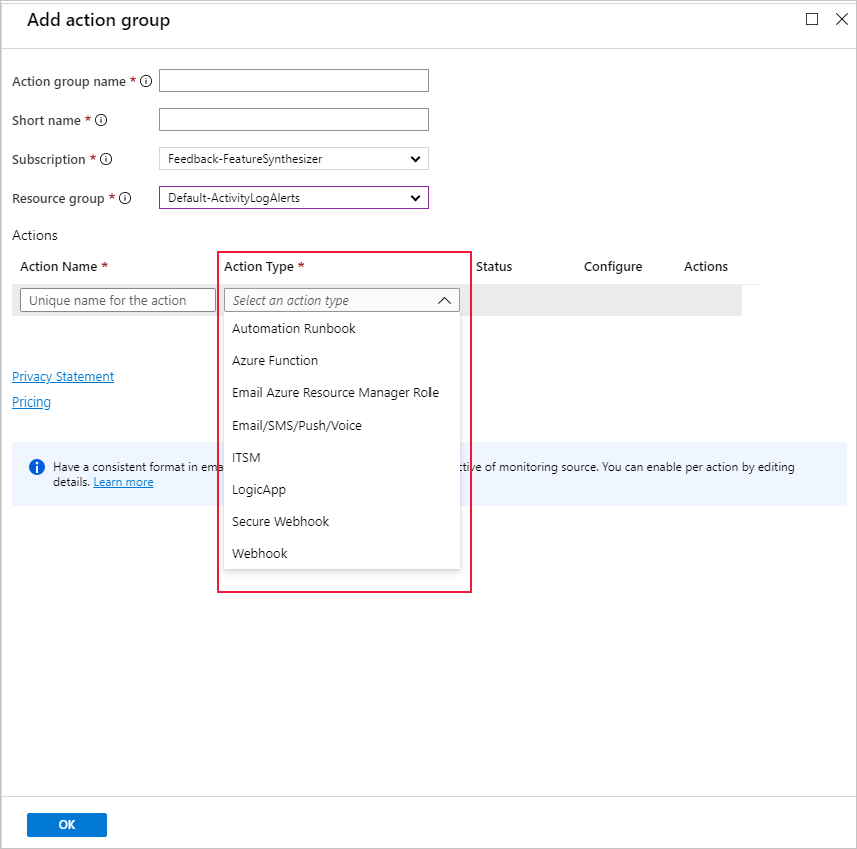
Du kan använda en befintlig åtgärdsgrupp eller skapa en ny för att definiera den åtgärd som ska vidtas när de angivna villkoren uppfylls:
Felsökning
Begränsningar och kända problem för övervakare av dataavvikelser:
Tidsintervallet vid analys av historiska data är begränsat till 31 intervall för övervakarens frekvensinställning.
Begränsning på 200 funktioner, såvida inte en funktionslista inte har angetts (alla funktioner som används).
Beräkningsstorleken måste vara tillräckligt stor för att hantera data.
Se till att datauppsättningen har data inom start- och slutdatumet för ett visst övervakningsjobb.
Datauppsättningsövervakare fungerar bara på datauppsättningar som innehåller 50 rader eller mer.
Kolumner, eller funktioner, i datauppsättningen klassificeras som kategoriska eller numeriska baserat på villkoren i följande tabell. Om funktionen inte uppfyller dessa villkor, till exempel en kolumn av typen sträng med >100 unika värden, tas funktionen bort från vår dataavvikelsealgoritm, men är fortfarande profilerad.
Funktionstyp Datatyp Villkor Begränsningar Kategoriska sträng Antalet unika värden i funktionen är mindre än 100 och mindre än 5 % av antalet rader. Null behandlas som en egen kategori. Numeriska int, float Värdena i funktionen är av en numerisk datatyp och uppfyller inte villkoret för en kategorisk funktion. Funktionen har släppts om >15 % av värdena är null. När du har skapat en övervakare av dataavvikelser men inte kan se data på sidan Datamängdsövervakare i Azure Machine Learning-studio kan du prova följande.
- Kontrollera om du har valt rätt datumintervall överst på sidan.
- På fliken Datauppsättningsövervakare väljer du experimentlänken för att kontrollera jobbstatus. Den här länken finns längst till höger i tabellen.
- Om jobbet har slutförts kontrollerar du drivrutinsloggarna för att se hur många mått som har genererats eller om det finns några varningsmeddelanden. Hitta drivrutinsloggar på fliken Utdata + loggar när du har klickat på ett experiment.
Om SDK-funktionen
backfill()inte genererar förväntade utdata kan det bero på ett autentiseringsproblem. När du skapar beräkningen som ska skickas till den här funktionen ska du inte användaRun.get_context().experiment.workspace.compute_targets. Använd i stället ServicePrincipalAuthentication , till exempel följande, för att skapa den beräkning som du skickar till denbackfill()funktionen:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")Från modelldatainsamlaren kan det ta upp till (men vanligtvis mindre än) 10 minuter innan data tas emot i bloblagringskontot. I ett skript eller en notebook-fil väntar du 10 minuter för att se till att cellerna nedan körs.
import time time.sleep(600)
Nästa steg
- Gå till Azure Machine Learning-studio eller Python Notebook för att konfigurera en datauppsättningsövervakare.
- Se hur du konfigurerar dataavvikelser för modeller som distribueras till Azure Kubernetes Service.
- Konfigurera övervakare av datamängdsavvikelser med Azure Event Grid.