Självstudie: Träna och distribuera en bildklassificeringsmodell med ett exempel Jupyter Notebook
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här självstudien ska du träna en maskininlärningsmodell på fjärranslutna beräkningsresurser. Du använder arbetsflödet för träning och distribution för Azure Machine Learning i en Python-Jupyter Notebook. Du kan sedan använda anteckningsboken som en mall för att träna din egen maskininlärningsmodell med egna data.
Den här självstudien tränar en enkel logistisk regression med hjälp av MNIST-datauppsättningen och scikit-learn med Azure Machine Learning. MNIST är en populär datauppsättning som består av 70 000 gråskalebilder. Varje bild är en handskriven siffra på 28 × 28 pixlar, som representerar ett tal från noll till nio. Målet är att skapa en klassificerare för flera klasser som identifierar siffran som en viss bild representerar.
Läs hur du vidtar följande åtgärder:
- Ladda ned en datauppsättning och titta på data.
- Träna en bildklassificeringsmodell och loggmått med hjälp av MLflow.
- Distribuera modellen för att göra realtidsinferens.
Förutsättningar
- Slutför snabbstarten: Kom igång med Azure Machine Learning för att:
- Skapa en arbetsyta.
- Skapa en molnbaserad beräkningsinstans som ska användas för din utvecklingsmiljö.
Köra en notebook-fil från din arbetsyta
Azure Machine Learning innehåller en molnserver för notebook-filer på arbetsytan för en installationsfri och förkonfigurerad upplevelse. Använd din egen miljö om du föredrar att ha kontroll över din miljö, dina paket och beroenden.
Klona en anteckningsboksmapp
Du slutför följande experimentkonfiguration och kör stegen i Azure Machine Learning-studio. Det här konsoliderade gränssnittet innehåller maskininlärningsverktyg för att utföra datavetenskapsscenarier för datavetenskapsutövare på alla kunskapsnivåer.
Logga in på Azure Machine Learning-studio.
Välj din prenumeration och arbetsytan som du skapade.
Välj Notebooks till vänster.
Längst upp väljer du fliken Exempel .
Öppna mappen SDK v1 .
Välj knappen ... till höger om självstudiemappen och välj sedan Klona.
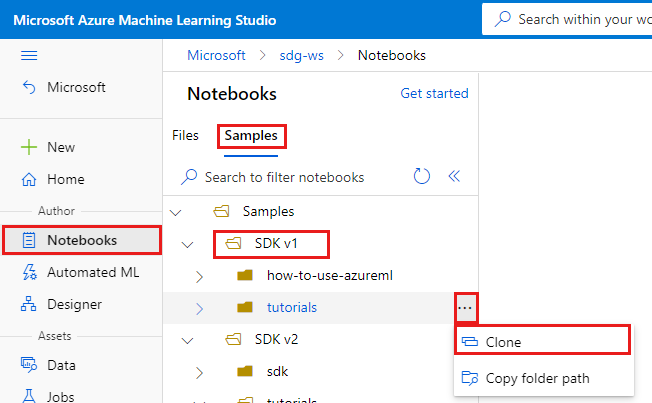
En lista med mappar visar varje användare som kommer åt arbetsytan. Välj din mapp för att klona mappen tutorials där.
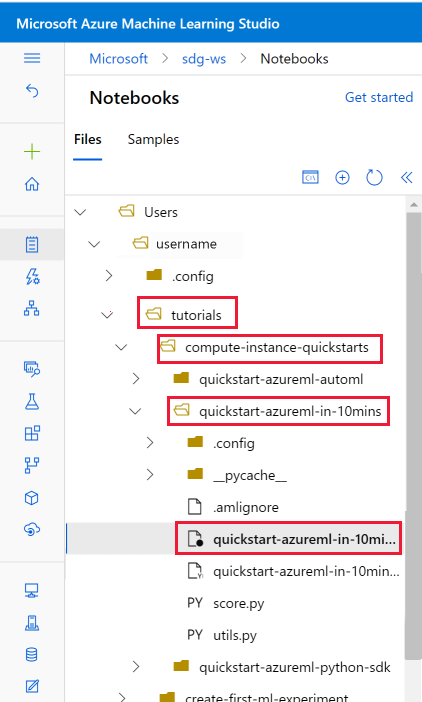
Öppna den klonade anteckningsboken
Öppna självstudiemappen som klonades i avsnittet Användarfiler .
Välj filen quickstart-azureml-in-10mins.ipynb från mappen tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins .
Installera paket
När beräkningsinstansen körs och kerneln visas lägger du till en ny kodcell för att installera paket som behövs för den här självstudien.
Lägg till en kodcell överst i anteckningsboken.
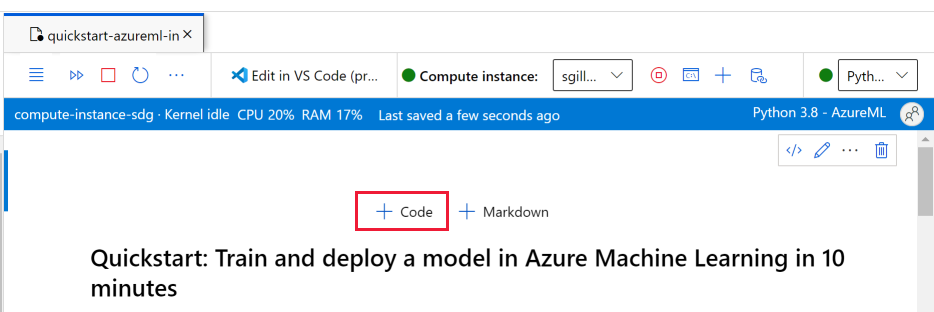
Lägg till följande i cellen och kör sedan cellen, antingen med verktyget Kör eller med hjälp av Skift+Retur.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Du kan se några installationsvarningar. Dessa kan ignoreras på ett säkert sätt.
Köra anteckningsboken
Den här självstudien och tillhörande utils.py-fil finns också på GitHub om du vill använda den i din egen lokala miljö. Om du inte använder beräkningsinstansen lägger du till %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib i installationen ovan.
Viktigt
Resten av den här artikeln innehåller samma innehåll som du ser i anteckningsboken.
Växla till Jupyter Notebook nu om du vill köra koden medan du läser vidare. Om du vill köra en enda kodcell i en notebook-fil klickar du på kodcellen och trycker på Skift+Retur. Du kan också köra hela anteckningsboken genom att välja Kör alla från det översta verktygsfältet.
Importera data
Innan du tränar en modell måste du förstå de data du använder för att träna den. I det här avsnittet lär du dig att:
- Ladda ned MNIST-datauppsättningen
- Visa några exempelbilder
Du använder Azure Open Datasets för att hämta MNIST-rådatafilerna. Azure Open Datasets är utvalda offentliga datauppsättningar som du kan använda för att lägga till scenariospecifika funktioner i maskininlärningslösningar för bättre modeller. Varje datauppsättning har i det här fallet en motsvarande klass MNIST för att hämta data på olika sätt.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Ta en titt på data
Läs in de komprimerade filerna i numpy-matriser. Använd därefter matplotlib till att rita 30 slumpmässiga bilder från datauppsättningen med sina etiketter ovanför dem.
Observera att det här steget kräver en load_data-funktion som ingår i utils.py-filen. Den här filen placeras i samma mapp som den här anteckningsboken. Funktionen load_data parsar enkelt de komprimerade filerna till numpy-matriser.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Koden ovan visar en slumpmässig uppsättning bilder med deras etiketter, ungefär så här:

Träna modell- och loggmått med MLflow
Du tränar modellen med hjälp av koden nedan. Observera att du använder automatisk MLflow-loggning för att spåra mått och loggmodellartefakter.
Du kommer att använda LogisticRegression-klassificeraren från SciKit Learn-ramverket för att klassificera data.
Anteckning
Modellträningen tar cirka 2 minuter att slutföra.**
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Visa experiment
I den vänstra menyn i Azure Machine Learning-studio väljer du Jobb och sedan ditt jobb (azure-ml-in10-mins-tutorial). Ett jobb är en gruppering av många körningar från ett angivet skript eller kodavsnitt. Flera jobb kan grupperas tillsammans som ett experiment.
Information för körningen lagras under det jobbet. Om namnet inte finns när du skickar ett jobb visas olika flikar som innehåller mått, loggar, förklaringar osv. om du väljer din körning.
Versionskontroll dina modeller med modellregistret
Du kan använda modellregistrering för att lagra och versionshantera dina modeller på din arbetsyta. Registrerade modeller identifieras med namn och version. Varje gång du registrerar en modell med ett namn som redan finns ökar versionsnumret. Koden nedan registrerar och versioner av modellen som du tränade ovan. När du har kört kodcellen nedan kan du se modellen i registret genom att välja Modeller på den vänstra menyn i Azure Machine Learning-studio.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Distribuera modellen för slutsatsdragning i realtid
I det här avsnittet får du lära dig hur du distribuerar en modell så att ett program kan använda (slutsatsdragning) modellen via REST.
Skapa distributionskonfiguration
Kodcellen hämtar en kuraterad miljö som anger alla beroenden som krävs för att vara värd för modellen (till exempel paketen som scikit-learn). Dessutom skapar du en distributionskonfiguration som anger hur mycket beräkning som krävs för att vara värd för modellen. I det här fallet har beräkningen 1CPU och 1 GB minne.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-0.24.1-ubuntu18.04-py37-cpu-inference",
version=1
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Distribuera modell
Nästa kodcell distribuerar modellen till Azure Container Instance.
Anteckning
Distributionen tar cirka 3 minuter att slutföra.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Bedömningsskriptfilen som refereras i koden ovan finns i samma mapp som den här notebook-filen och har två funktioner:
- En
initfunktion som körs en gång när tjänsten startar – i den här funktionen hämtar du normalt modellen från registret och anger globala variabler - En
run(data)funktion som körs varje gång ett anrop görs till tjänsten. I den här funktionen formaterar du normalt indata, kör en förutsägelse och matar ut det förväntade resultatet.
Visa slutpunkt
När modellen har distribuerats kan du visa slutpunkten genom att gå till Slutpunkter på den vänstra menyn i Azure Machine Learning-studio. Du kommer att kunna se tillståndet för slutpunkten (felfri/inte felfri), loggar och använda (hur program kan använda modellen).
Testa modelltjänsten
Du kan testa modellen genom att skicka en RÅ HTTP-begäran för att testa webbtjänsten.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Rensa resurser
Om du inte kommer att fortsätta att använda den här modellen tar du bort modelltjänsten med hjälp av:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Om du vill kontrollera kostnaden ytterligare stoppar du beräkningsinstansen genom att välja knappen "Stoppa beräkning" bredvid listrutan Beräkning . Starta sedan beräkningsinstansen igen nästa gång du behöver den.
Ta bort allt
Använd de här stegen för att ta bort din Azure Machine Learning-arbetsyta och alla beräkningsresurser.
Viktigt
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du skapade tar du bort dem så att du inte debiteras några avgifter:
I Azure-portalen väljer du Resursgrupper längst till vänster.
Välj resursgruppen som du skapade från listan.
Välj Ta bort resursgrupp.
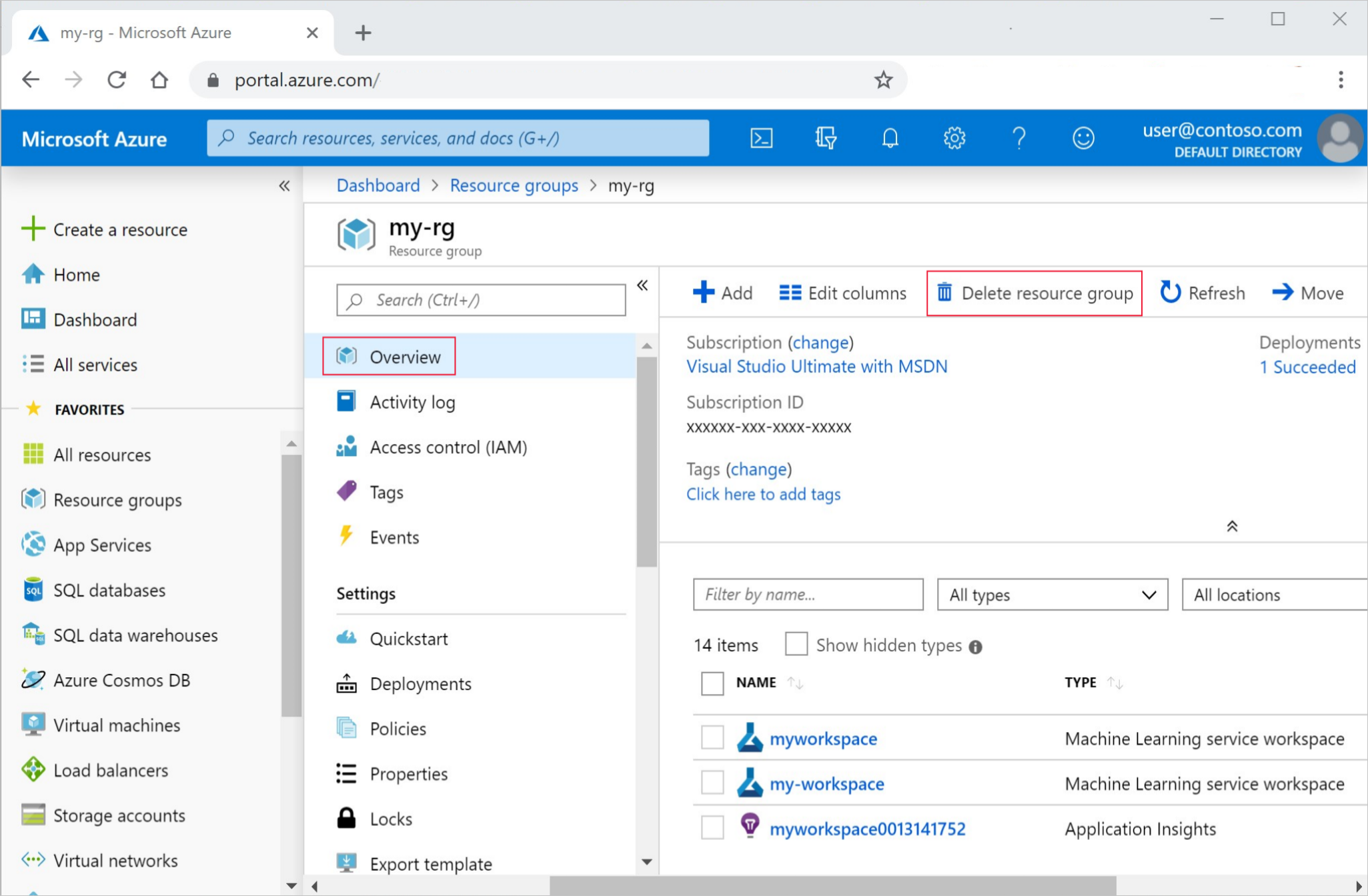
Ange resursgruppsnamnet. Välj sedan Ta bort.
Nästa steg
- Lär dig mer om alla distributionsalternativ för Azure Machine Learning.
- Lär dig hur du autentiserar till den distribuerade modellen.
- Göra förutsägelser kring stora mängder data asynkront.
- Övervaka dina Azure Machine Learning-modeller med Application Insights.