Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Managed Instance för Apache Cassandra tillhandahåller automatiserade distributions- och skalningsåtgärder för hanterade Apache Cassandra-datacenter med öppen källkod. Den här funktionen påskyndar hybridscenarier och hjälper till att minska pågående underhåll.
Den här snabbstarten visar hur du använder Azure-portalen för att skapa ett fullständigt hanterat Apache Spark-kluster i det virtuella nätverket i Azure för den hanterade instansen av Apache Cassandra-klustret. Du skapar Spark-klustret i Azure Databricks. Senare kan du skapa eller koppla notebook-filer till klustret, läsa data från olika datakällor och analysera insikter.
Du kan också lära dig mer med detaljerade anvisningar om hur du distribuerar Azure Databricks i ditt virtuella Azure-nätverk (virtuell nätverksinmatning).
Förutsättningar
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Skapa ett Azure Databricks-kluster
Följ de här stegen för att skapa ett Azure Databricks-kluster i ett virtuellt nätverk som har Azure Managed Instance för Apache Cassandra:
Logga in på Azure-portalen.
Leta reda på Resursgrupper i den vänstra rutan. Gå till resursgruppen som innehåller det virtuella nätverk där den hanterade instansen distribueras.
Öppna resursen Virtuellt nätverk och anteckna adressutrymmet.
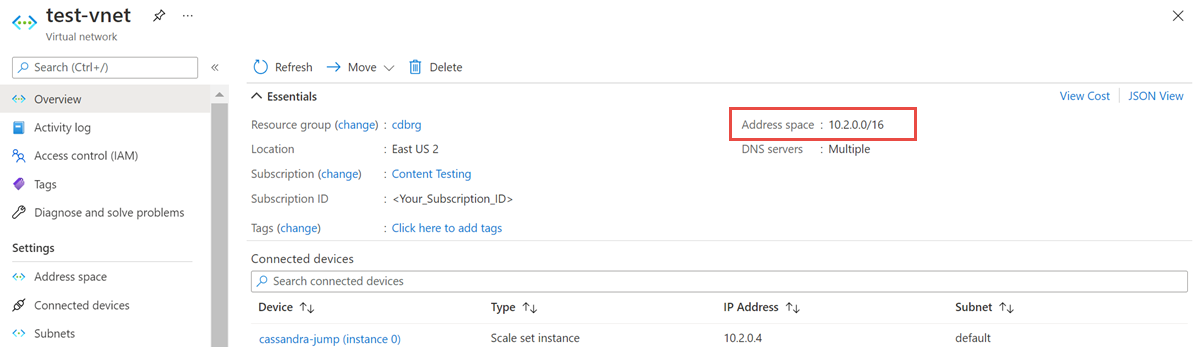
I resursgruppen väljer du Lägg till och söker efter Azure Databricks i sökfältet.
Välj Skapa för att skapa ett Azure Databricks-konto.
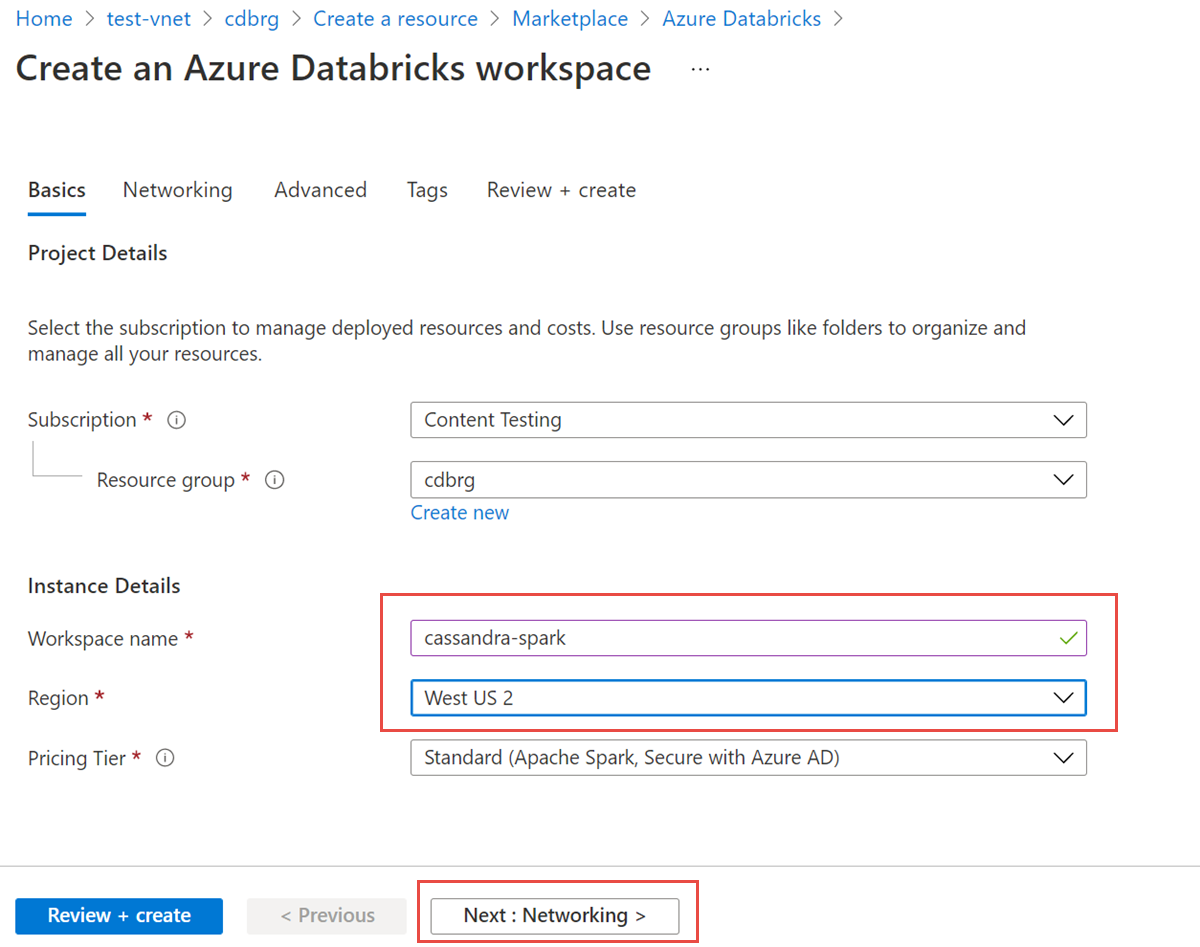
Ange följande värden:
- Namn på arbetsyta: Ange ett namn för din Azure Databricks-arbetsyta.
- Region: Välj samma region som det virtuella nätverket.
- Prisnivå: Välj Standard, Premium eller Utvärderingsversion. Mer information om dessa nivåer finns på prissättningssidan för Azure Databricks.
Välj fliken Nätverk och ange följande information:
- Distribuera Azure Databricks-arbetsytan i ditt virtuella nätverk (VNet): Välj Ja.
- Virtuellt nätverk: I listrutan väljer du det virtuella nätverk där den hanterade instansen finns.
- Namn på offentligt undernät: Ange ett namn för det offentliga undernätet.
- CIDR-intervall för offentligt undernät: Ange ett IP-intervall för det offentliga undernätet.
- Privat undernätsnamn: Ange ett namn för det privata undernätet.
- CIDR-intervall för privat undernät: Ange ett IP-intervall för det privata undernätet.
Se till att du väljer högre intervall för att undvika intervallkollisioner. Om det behövs använder du en visuell undernätskalkylator för att dela upp intervallen.
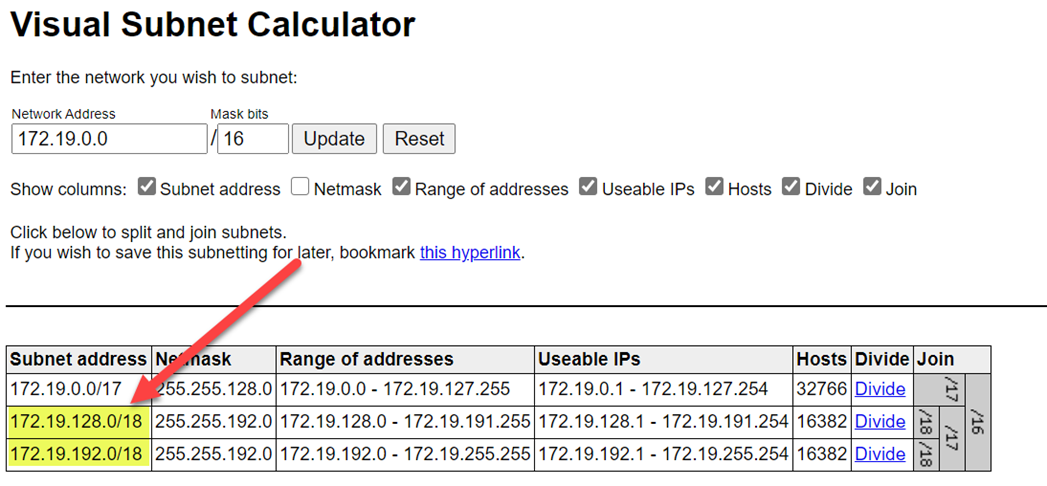
Följande skärmbild visar exempelinformation i nätverksfönstret.
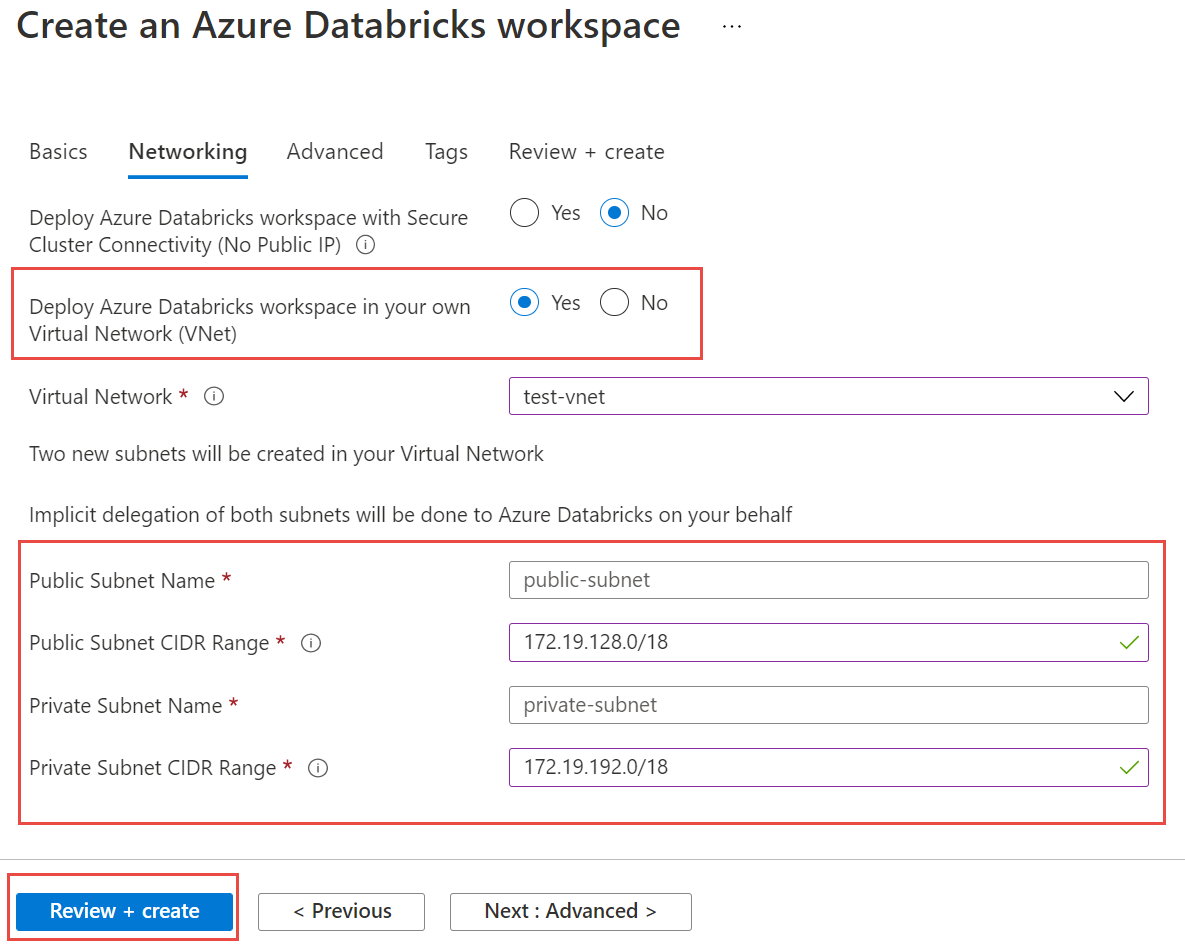
Välj Granska + skapa och välj sedan Skapa för att distribuera arbetsytan.
Öppna arbetsytan efter att arbetsytan har skapats.
Du omdirigeras till Azure Databricks-portalen. I portalen väljer du Nytt kluster.
I fönstret Nytt kluster accepterar du standardvärden för alla andra fält än följande fält:
- Klusternamn: Ange ett namn för klustret.
- Databricks Runtime-version: Vi rekommenderar att du väljer Azure Databricks runtime version 7.5 eller senare för Stöd för Spark 3.x.

Expandera Avancerade alternativ och lägg till följande konfiguration. Se till att ersätta nod-IP-adresser och autentiseringsuppgifter.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueLägg till Apache Spark Cassandra Connector-biblioteket i klustret för att ansluta till både interna slutpunkter och Azure Cosmos DB Cassandra-slutpunkter. I klustret väljer du Bibliotek>Installera ny>Maven och lägger sedan till
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0i fältet Maven-koordinater .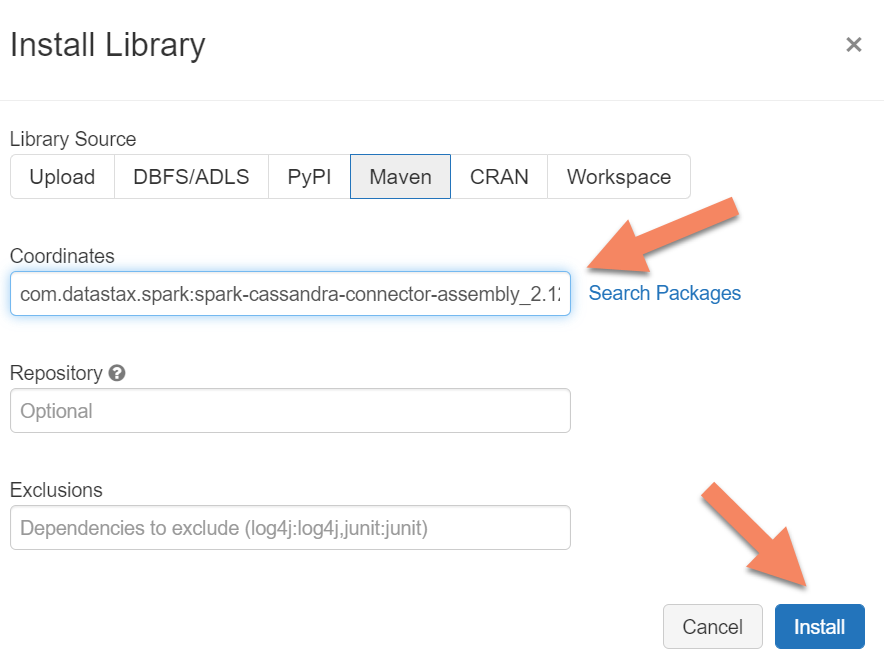
Välj Installera.
Rensa resurser
Om du inte kommer att fortsätta att använda det här hanterade instansklustret följer du de här stegen för att ta bort det:
- Välj Resursgrupper på den vänstra menyn på Azure-portalen.
- I listan väljer du den resursgrupp som du skapade för den här snabbstarten.
- I fönstret Översikt över resursgrupp väljer du Ta bort resursgrupp.
- I nästa fönster anger du namnet på resursgruppen som ska tas bort och väljer sedan Ta bort.
Nästa steg
I den här snabbstarten har du lärt dig hur du skapar ett fullständigt hanterat Apache Spark-kluster i det virtuella nätverket i ditt Azure Managed Instance för Apache Cassandra-kluster. Lär dig sedan hur du hanterar kluster- och datacenterresurserna.