Tillförlitlighet i Azure Traffic Manager
Den här artikeln innehåller specifika tillförlitlighetsrekommendationer för Azure Traffic Manager samt haveriberedskap mellan regioner och stöd för affärskontinuitet för Azure Traffic Manager.
En mer detaljerad översikt över tillförlitlighetsprinciper i Azure finns i Azures tillförlitlighet.
Tillförlitlighetsrekommendationer
Det här avsnittet innehåller rekommendationer för att uppnå återhämtning och tillgänglighet. Varje rekommendation ingår i någon av två kategorier:
Hälsoobjekt omfattar områden som konfigurationsobjekt och rätt funktion för de huvudkomponenter som utgör din Azure-arbetsbelastning, till exempel Konfigurationsinställningar för Azure-resurser, beroenden för andra tjänster och så vidare.
Riskobjekt omfattar områden som tillgänglighets- och återställningskrav, testning, övervakning, distribution och andra objekt som, om de lämnas olösta, ökar risken för problem i miljön.
Prioritetsmatris för tillförlitlighetsrekommendationer
Varje rekommendation markeras i enlighet med följande prioritetsmatris:
| Bild | Prioritet | beskrivning |
|---|---|---|
| Högt | Omedelbar korrigering krävs. | |
| Medium | Åtgärda inom 3–6 månader. | |
| Låg | Måste granskas. |
Sammanfattning av tillförlitlighetsrekommendationer
Tillgänglighet
 Traffic Manager-övervakningsstatus bör vara online
Traffic Manager-övervakningsstatus bör vara online
Övervakningsstatus bör vara online för att tillhandahålla redundans för programarbetsbelastningen. Om hälsotillståndet för Traffic Manager visar statusen Degraderad kan statusen för en eller flera slutpunkter också försämras.
Mer information om slutpunktsövervakning i Traffic Manager finns i Traffic Manager-slutpunktsövervakning.
Information om hur du felsöker ett degraderat tillstånd i Azure Traffic Manager finns i Felsöka degraderat tillstånd i Azure Traffic Manager.
Traffic Manager-profiler bör ha mer än en slutpunkt
När du konfigurerar Azure Traffic Manager bör du etablera minst två slutpunkter för att redundansväxla arbetsbelastningen till en annan instans.
Mer information om Traffic Manager-slutpunktstyper finns i Traffic Manager-slutpunkter.
Systemeffektivitet
 TTL-värdet för användarprofiler bör vara inom 60 sekunder
TTL-värdet för användarprofiler bör vara inom 60 sekunder
Time to Live (TTL) påverkar hur snabbt en klient får ett svar när den skickar en begäran till Azure Traffic Manager. När TTL-värdet minskas dirigeras klienten till en fungerande slutpunkt snabbare vid redundans. Konfigurera din TTL till 60 sekunder för att dirigera trafik till en felfri slutpunkt så snabbt som möjligt.
Mer information om hur du konfigurerar DNS TTL finns i Konfigurera DNS-tid till live.
Haveriberedskap
Konfigurera minst en slutpunkt i en annan region
Profiler bör ha fler än en slutpunkt för att säkerställa tillgängligheten om en av slutpunkterna inte kan användas. Slutpunkterna bör dessutom ligga i olika regioner.
Mer information om Traffic Manager-slutpunktstyper finns i Traffic Manager-slutpunkter.
Se till att slutpunkten är konfigurerad för "(All World)" för geografiska profiler
Vid geografisk routning dirigeras trafiken till slutpunkter baserat på redan angivna regioner. Om en region inte fungerar finns ingen fördefinierad redundans. Om du har en slutpunkt där den regionala grupperingen är konfigurerad till "Alla (världen)" för geografiska profiler undviker du svart trafikskydd och garanterar att tjänsten förblir tillgänglig.
Information om hur du lägger till och konfigurerar en slutpunkt finns i Lägga till, inaktivera, aktivera, ta bort eller flytta slutpunkter.
Haveriberedskap och affärskontinuitet mellan regioner
Haveriberedskap handlar om att återställa från händelser med hög påverkan, till exempel naturkatastrofer eller misslyckade distributioner som resulterar i driftstopp och dataförlust. Oavsett orsak är den bästa lösningen för en katastrof en väldefinierad och testad DR-plan och en programdesign som aktivt stöder DR. Innan du börjar fundera på att skapa en haveriberedskapsplan kan du läsa Rekommendationer för att utforma en strategi för haveriberedskap.
När det gäller dr använder Microsoft modellen för delat ansvar. I en modell med delat ansvar ser Microsoft till att baslinjeinfrastrukturen och plattformstjänsterna är tillgängliga. Samtidigt replikerar många Azure-tjänster inte automatiskt data eller återgår från en misslyckad region för att korsreparera till en annan aktiverad region. För dessa tjänster ansvarar du för att konfigurera en haveriberedskapsplan som fungerar för din arbetsbelastning. De flesta tjänster som körs på PaaS-erbjudanden (Plattform som en tjänst) i Azure ger funktioner och vägledning för att stödja DR och du kan använda tjänstspecifika funktioner för att stödja snabb återställning för att utveckla din DR-plan.
Azure Traffic Manager är en DNS-baserad lastbalanserare för trafik som gör att du kan distribuera trafik till dina offentliga program i globala Azure-regioner. Traffic Manager ger även dina offentliga slutpunkter hög tillgänglighet och snabb svarstid.
Traffic Manager använder DNS för att dirigera klientbegäranden till lämplig tjänstslutpunkt baserat på en trafikroutningsmetod. Traffic Manager tillhandahåller även hälsoövervakning för varje slutpunkt. Slutpunkten kan vara valfri Internetuppkopplad tjänst som finns i eller utanför Azure. Traffic Manager tillhandahåller en uppsättning trafikdirigeringsmetoder och alternativ för slutpunktsövervakning som passar olika programbehov och modeller för automatisk redundansväxling. Traffic Manager har bra återhämtningsförmåga i händelse av fel, inklusive fel som påverkar en hel Azure-region.
Haveriberedskap i geografi för flera regioner
DNS är en av de mest effektiva mekanismerna för att omdirigera nätverkstrafik. DNS är effektivt eftersom DNS ofta är globalt och externt till datacentret. DNS är också isolerat från eventuella fel på regional nivå eller tillgänglighetsnivå (AZ).
Det finns två tekniska aspekter för att konfigurera arkitekturen för haveriberedskap:
Använda en distributionsmekanism för att replikera instanser, data och konfigurationer mellan primära miljöer och väntelägesmiljöer. Den här typen av haveriberedskap kan utföras internt viaAzure Site Recovery, se Dokumentation om Azure Site Recovery via Microsoft Azure-partnerenheter/-tjänster som Veritas eller NetApp.
Utveckla en lösning för att omdirigera nätverks-/webbtrafik från den primära platsen till väntelägesplatsen. Den här typen av haveriberedskap kan uppnås via Azure DNS, Azure Traffic Manager (DNS) eller globala lastbalanserare från tredje part.
Den här artikeln fokuserar specifikt på planering av haveriberedskap i Azure Traffic Manager.
Identifiering, avisering och hantering av avbrott
Under en katastrof avsöks den primära slutpunkten och statusen ändras till degraderad och haveriberedskapsplatsen förblir Online. Som standard skickar Traffic Manager all trafik till den primära slutpunkten (högsta prioritet). Om den primära slutpunkten verkar degraderad dirigerar Traffic Manager trafiken till den andra slutpunkten så länge den förblir felfri. Man kan konfigurera fler slutpunkter i Traffic Manager som kan fungera som extra redundansslutpunkter, eller som lastbalanserare som delar belastningen mellan slutpunkter.
Konfigurera haveriberedskap och avbrottsidentifiering
När du har komplexa arkitekturer och flera uppsättningar resurser som kan utföra samma funktion kan du konfigurera Azure Traffic Manager (baserat på DNS) för att kontrollera hälsotillståndet för dina resurser och dirigera trafiken från den icke-felfria resursen till den felfria resursen.
I följande exempel har både den primära regionen och den sekundära regionen en fullständig distribution. Den här distributionen omfattar molntjänsterna och en synkroniserad databas.
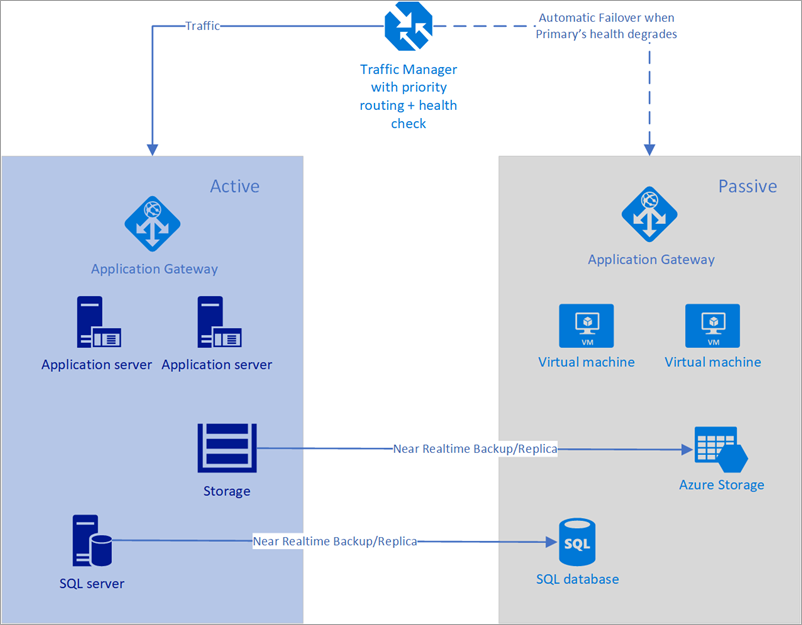
Bild – Automatisk redundans med Azure Traffic Manager
Det är dock bara den primära regionen som aktivt hanterar nätverksbegäranden från användarna. Den sekundära regionen blir endast aktiv när den primära regionen upplever ett avbrott i tjänsten. I så fall dirigeras alla nya nätverksbegäranden till den sekundära regionen. Eftersom säkerhetskopieringen av databasen är nästan omedelbar, både lastbalanserarna har IP-adresser som kan hälsokontrolleras och instanserna alltid är igång, ger den här topologin ett alternativ för att gå in för en låg RTO och redundans utan manuella åtgärder. Den sekundära redundansregionen måste vara redo att aktiveras direkt efter fel i den primära regionen.
Det här scenariot är perfekt för användning av Azure Traffic Manager som har inbyggda avsökningar för olika typer av hälsokontroller, inklusive http/https och TCP. Azure Traffic Manager har också en regelmotor som kan konfigureras för redundansväxling när ett fel inträffar enligt beskrivningen nedan. Nu ska vi överväga följande lösning med Hjälp av Traffic Manager:
- Kunden har den region nr 1-slutpunkt som kallas prod.contoso.com med en statisk IP-adress som 100.168.124.44 och en region #2-slutpunkt som kallas dr.contoso.com med en statisk IP-adress som 100.168.124.43.
- Var och en av dessa miljöer frontas via en offentlig egenskap som en lastbalanserare. Lastbalanseraren kan konfigureras för att ha en DNS-baserad slutpunkt eller ett fullständigt domännamn (FQDN) enligt ovan.
- Alla instanser i region 2 är i nära realtidsreplikering med region 1. Dessutom är datorbilderna uppdaterade och alla programvaru-/konfigurationsdata korrigeras och är i linje med Region 1.
- Automatisk skalning förkonfigureras i förväg.
Så här konfigurerar du redundansväxlingen med Azure Traffic Manager:
Skapa en ny Azure Traffic Manager-profil Skapa en ny Azure Traffic Manager-profil med namnet contoso123 och välj routningsmetoden som Prioritet. Om du har en befintlig resursgrupp som du vill associera med kan du välja en befintlig resursgrupp, annars kan du skapa en ny resursgrupp.
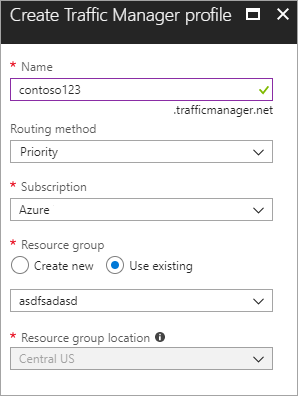
Bild – Skapa en Traffic Manager-profil
Skapa slutpunkter i Traffic Manager-profilen
I det här steget skapar du slutpunkter som pekar på produktions- och haveriberedskapsplatserna. Här väljer du Typ som en extern slutpunkt, men om resursen finns i Azure kan du också välja Azure-slutpunkt . Om du väljer Azure-slutpunkt väljer du en målresurs som antingen är en App Service eller en offentlig IP-adress som allokeras av Azure. Prioriteten anges som 1 eftersom det är den primära tjänsten för region 1. På samma sätt skapar du även slutpunkten för haveriberedskap i Traffic Manager.
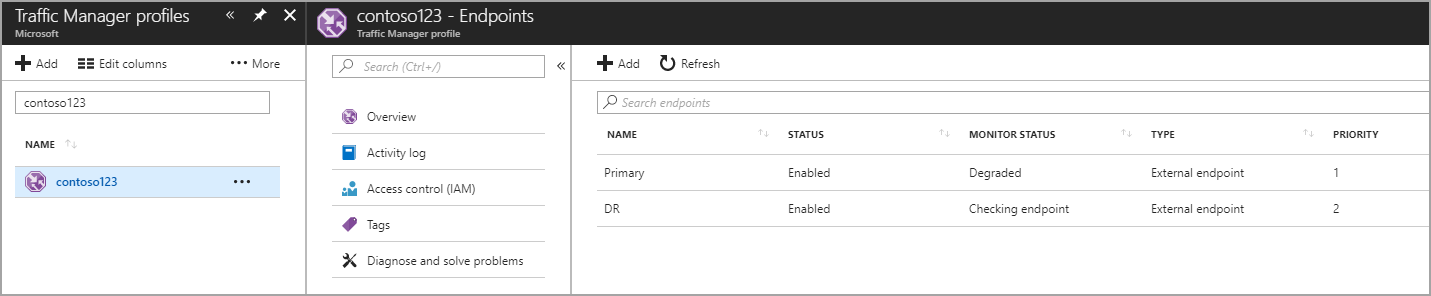
Bild – Skapa slutpunkter för haveriberedskap
Konfigurera konfiguration av hälsokontroll och redundans
I det här steget anger du DNS TTL till 10 sekunder, vilket respekteras av de flesta internetuppkopplade rekursiva matchare. Den här konfigurationen innebär att ingen DNS-matchare cachelagras i mer än 10 sekunder.
För inställningarna för slutpunktsövervakaren är sökvägen aktuell inställd på/eller rot, men du kan anpassa slutpunktsinställningarna för att utvärdera en sökväg, till exempel prod.contoso.com/index.
Exemplet nedan visar https som avsökningsprotokoll. Du kan dock även välja http eller tcp . Valet av protokoll beror på slutprogrammet. Avsökningsintervallet är inställt på 10 sekunder, vilket möjliggör snabb avsökning och återförsöket är inställt på 3. Därför redundansväxlar Traffic Manager till den andra slutpunkten om tre intervall i följd registrerar ett fel.
Följande formel definierar den totala tiden för en automatiserad redundansväxling:
Time for failover = TTL + Retry * Probing intervalOch i det här fallet är värdet 10 + 3 * 10 = 40 sekunder (max).
Om återförsöket är inställt på 1 och TTL är inställt på 10 sekunder, är tiden för redundansväxling 10 + 1 * 10 = 20 sekunder.
Ange återförsöket till ett värde som är större än 1 för att eliminera risken för redundans på grund av falska positiva identifieringar eller några mindre nätverksblips.
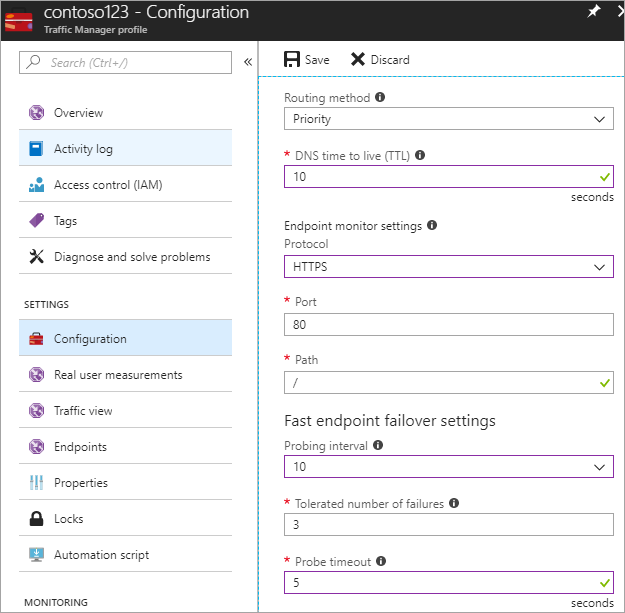
Bild – Konfigurera konfiguration av hälsokontroll och redundans
Nästa steg
Läs mer om Azure Traffic Manager.
Läs mer om Azure DNS.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för