Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Affärskontinuitet i Azure Database for PostgreSQL refererar till de mekanismer, principer och procedurer som gör det möjligt för ditt företag att fortsätta sin verksamhet vid störningar, särskilt dess infrastruktur för databehandling. I de flesta fall hanterar Azure Database for PostgreSQL störande händelser som kan inträffa i molnmiljön och hålla dina program och affärsprocesser igång. Det finns dock vissa händelser som inte kan hanteras automatiskt, till exempel:
- Användaren tar av misstag bort eller uppdaterar en rad i en tabell.
- Jordbävning orsakar ett strömavbrott och inaktiverar tillfälligt en tillgänglighetszon eller en region.
- Databaskorrigering krävs för att åtgärda ett fel eller säkerhetsproblem.
Azure Database for PostgreSQL innehåller funktioner som skyddar data och minskar stilleståndstiden för dina verksamhetskritiska databaser under planerade och oplanerade driftstopp. Azure Database for PostgreSQL bygger på Azure-infrastrukturen som erbjuder robust återhämtning och tillgänglighet och har funktioner för affärskontinuitet som ger ett annat felskydd, åtgärdar krav på återställningstid och minskar exponeringen för dataförlust. När du utformar dina program bör du överväga stilleståndstidstoleransen – mål för återställningstid (RTO) och exponering för dataförlust – målet för återställningspunkten (RPO). Din affärskritiska databas kräver till exempel striktare drifttid än en testdatabas.
Tabellen nedan visar de funktioner som Azure Database for PostgreSQL erbjuder.
| Funktion | Beskrivning | Överväganden |
|---|---|---|
| Automatiska säkerhetskopieringar | En flexibel Azure Database for PostgreSQL-serverinstans utför automatiskt dagliga säkerhetskopieringar av dina databasfiler och säkerhetskopierar kontinuerligt transaktionsloggar. Säkerhetskopior kan behållas från 7 dagar upp till 35 dagar. Du kan återställa databasservern till valfri tidpunkt inom kvarhållningsperioden för säkerhetskopior. RTO är beroende av storleken på data för att återställa + tiden för att utföra loggåterställning. Det kan vara från några minuter upp till 12 timmar. Mer information finns i Begrepp – Säkerhetskopiering och återställning. | Säkerhetskopieringsdata finns kvar i regionen. |
| Zonredundant hög tillgänglighet | En flexibel Azure Database for PostgreSQL-serverinstans kan distribueras med konfiguration med zonredundant hög tillgänglighet (HA) där primära servrar och väntelägesservrar distribueras i två olika tillgänglighetszoner i en region. Den här HA-konfigurationen skyddar dina databaser från fel på zonnivå och hjälper även till med att minska programavbrott under planerade och oplanerade driftstopp. Data från den primära servern replikeras till väntelägesrepliken i synkront läge. I händelse av störningar på den primära servern redigeras servern automatiskt över till standby-repliken. RTO förväntas i de flesta fall vara mindre än 120-talet. RPO förväntas vara noll (ingen dataförlust). Mer information finns i [Begrepp – hög tillgänglighet]/azure/reliability/reliability-postgresql-flexible-server. | Stöds i generell användning och minnesoptimerade beräkningsnivåer. Endast tillgängligt i regioner där flera zoner är tillgängliga. |
| Hög tillgänglighet i samma zon | En flexibel Azure Database for PostgreSQL-serverinstans kan distribueras med hög tillgänglighetskonfiguration (HA) i samma zon, där primära och standby-servrar distribueras i samma tillgänglighetszon i en region. Den här HA-konfigurationen skyddar dina databaser från fel på nodnivå och hjälper även till med att minska programavbrott under planerade och oplanerade driftstopp. Data från den primära servern replikeras till väntelägesrepliken i synkront läge. I händelse av störningar på den primära servern redigeras servern automatiskt över till standby-repliken. RTO förväntas i de flesta fall vara mindre än 120-talet. RPO förväntas vara noll (ingen dataförlust). Mer information finns i [Begrepp – hög tillgänglighet]/azure/reliability/reliability-postgresql-flexible-server. | Stöds i generell användning och minnesoptimerade beräkningsnivåer. |
| Premium-hanterade diskar | Databasfiler lagras i en mycket hållbar och tillförlitlig premium-hanterad lagring. Detta ger dataredundans med tre kopior av repliker som lagras i en tillgänglighetszon med funktioner för automatisk dataåterställning. Mer information finns i dokumentationen om hanterade diskar. | Data som lagras i en tillgänglighetszon. |
| Zonredundant säkerhetskopiering | Säkerhetskopieringar av flexibel Azure Database for PostgreSQL-serverinstans lagras automatiskt och säkert i en zonredundant lagring i en region, om regionen stöder tillgänglighetszoner. Under ett fel på zonnivå där servern etableras, och om servern inte har konfigurerats med zonredundans, kan du fortfarande återställa databasen med hjälp av den senaste återställningspunkten i en annan zon. Mer information finns i Begrepp – Säkerhetskopiering och återställning. | Gäller endast i regioner där flera zoner är tillgängliga. |
| Geo-redundant säkerhetskopiering | Säkerhetskopior av Azure Database for PostgreSQL flexibel server kopieras till en fjärrregion. som hjälper till med haveriberedskap i händelse av att den primära serverregionen är nere. | Den här funktionen är för närvarande aktiverad i valda regioner. Det tar en längre RTO och ett högre RPO beroende på storleken på de data som ska återställas och hur mycket återställning som ska utföras. |
| Läs replik | Läsrepliker mellan regioner kan distribueras för att skydda dina databaser mot fel på regionnivå. Läsrepliker uppdateras asynkront med PostgreSQL:s fysiska replikeringsteknik och kan fördröja den primära replikeringen. Mer information finns i Begrepp – Läs repliker. | Stöds i generell användning och minnesoptimerade beräkningsnivåer. |
I följande tabell jämförs RTO och RPO i ett typiskt arbetsbelastningsscenario :
| Förmåga | Burstbar | Produktions-SKU (generell användning/minnesoptimerad) |
|---|---|---|
| Återställning till tidpunkt från säkerhetskopia | Alla återställningspunkter inom kvarhållningsperioden RTO – varierar RPO < 5 minuter |
Alla återställningspunkter inom kvarhållningsperioden RTO – varierar RPO < 5 minuter |
| Geo-återställning från geo-replikerade säkerhetskopior | RTO – varierar RPO < 1 timme |
RTO – varierar RPO < 1 timme |
| Skrivskyddade repliker | Ej tillämpligt | RTO – minuter* RPO – vanligtvis från 30 sekunder till 5 minuter* |
| Hög tillgänglighet | Ej tillämpligt | RTO < 120 sek RPO = 0 |
Planerade driftstopp
Nedan visas några scenarier för planerat underhåll. Dessa händelser medför vanligtvis upp till några minuters stilleståndstid och utan dataförlust.
| Scenario | Bearbeta |
|---|---|
| Beräkningsskalning (användarinitierad) | Under beräkningsskalningsåtgärden tillåts aktiva kontrollpunkter att slutföras, klientanslutningar töms, eventuella ogenomförda transaktioner avbryts, lagringen kopplas från och stängs sedan av. En ny flexibel Azure Database for PostgreSQL-serverinstans med samma databasservernamn etableras med den skalbara beräkningskonfigurationen. Lagringen kopplas sedan till den nya servern och databasen startas, vilket vid behov utför återställning innan klientanslutningar godkänns. |
| Skala upp lagring (användarinitierad) | När en uppskalningslagringsåtgärd initieras tillåts aktiva kontrollpunkter att slutföras, klientanslutningar töms och eventuella ej utförda transaktioner avbryts. Därefter stängs servern av. Lagringen skalas till önskad storlek och kopplas sedan till den nya servern. En återställning utförs om det behövs innan klientanslutningar accepteras. Observera att nedskalning av lagringsstorleken inte stöds. |
| Ny programvarudistribution (Azure-initierad) | Nya funktioner för distribution eller felkorrigeringar sker automatiskt som en del av tjänstens planerade underhåll, och du kan schemalägga när dessa aktiviteter ska ske. Mer information finns i portalen. |
| Delversionsuppgraderingar (Azure-initierade) | Azure Database for PostgreSQL korrigerar automatiskt databasservrar till den delversion som bestäms av Azure. Det sker som en del av tjänstens planerade underhåll. Databasservern startas om automatiskt med den nya delversionen. För mer information, se dokumentationen. Du kan också kontrollera portalen. |
När Azure Database for PostgreSQL–instansen för flexibel server konfigureras med hög tillgänglighet utför tjänsten först skalning och underhållsåtgärder på väntelägesservern. Mer information finns i [Begrepp – hög tillgänglighet]/azure/reliability/reliability-postgresql-flexible-server.
Åtgärder för oplanerade driftstopp
Oplanerade driftstopp kan uppstå till följd av oförutsedda störningar, till exempel underliggande maskinvarufel, nätverksproblem och programvarubuggar. Om databasservern som konfigurerats med hög tillgänglighet oväntat minskar aktiveras standby-repliken och klienterna kan återuppta sina åtgärder. Om den inte har konfigurerats med hög tillgänglighet (HA) etableras en ny databasserver automatiskt om omstartsförsöket misslyckas. Det går inte att undvika en oplanerad stilleståndstid, men Azure Database for PostgreSQL hjälper till att minska stilleståndstiden genom att automatiskt utföra återställningsåtgärder utan mänsklig inblandning.
Även om vi kontinuerligt strävar efter att tillhandahålla hög tillgänglighet, finns det tillfällen då Azure Database for PostgreSQL orsakar avbrott som orsakar otillgänglighet för databaserna och därmed påverkar ditt program. När vår tjänstövervakning identifierar problem som orsakar omfattande anslutningsfel, fel eller prestandaproblem deklarerar tjänsten automatiskt ett avbrott för att hålla dig informerad.
Tjänstavbrott
I händelse av ett avbrott i Azure Database for PostgreSQL flexibel serverinstans kan du se mer information relaterad till avbrottet på följande platser:
- Azure Portal banderoll: Om din prenumeration identifieras påverkas aviseringar om avbrott i ett tjänstproblem i Azure Portal-meddelanden.
- Hjälp + support eller support + felsökning: När du skapar ett supportärende från Hjälp + support eller Support + felsökning kommer det att finnas information om eventuella problem som påverkar dina resurser. Välj Visa avbrottsinformation för mer information och en sammanfattning av påverkan. Det kommer också att finnas en avisering på sidan Ny supportbegäran.
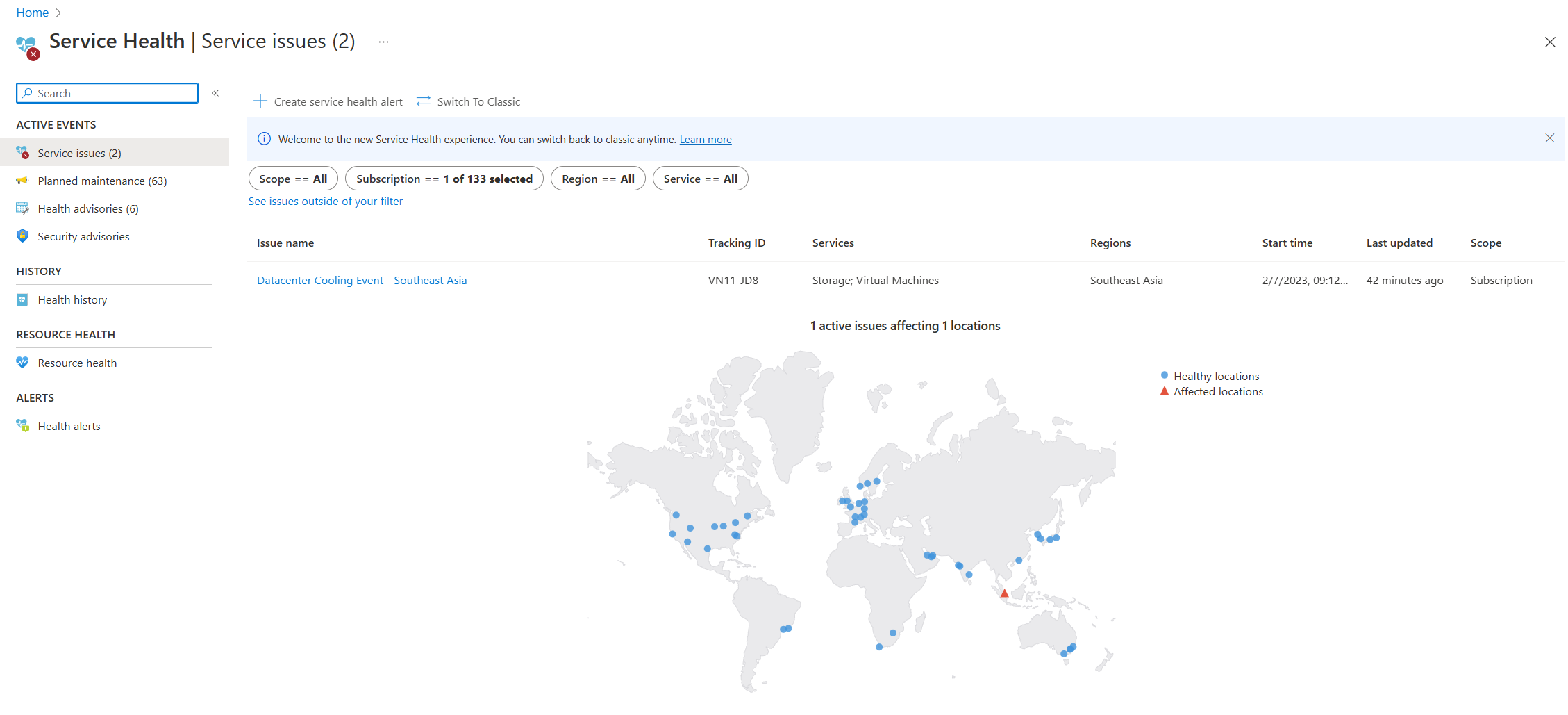
- Tjänsthjälp: Sidan Tjänsthälsa i Azure Portal innehåller information om Status för Azure-datacenter globalt. Sök efter "tjänsthälsa" i sökfältet i Azure Portal och visa sedan Tjänstproblem i kategorin Aktiva händelser. Du kan också visa hälsotillståndet för enskilda resurser på sidan Resurshälsa för alla resurser under hjälpmenyn. En exempelskärmbild av sidan Service Health följer med information om ett aktivt tjänstproblem i Sydostasien.
- E-postavisering: Om du har konfigurerat aviseringar kommer ett e-postmeddelande att tas emot när ett tjänstavbrott påverkar din prenumeration och resurs. E-postmeddelandena kommer från "azure-noreply@microsoft.com". Brödtexten i e-postmeddelandet börjar med "Aktivitetsloggaviseringen ... utlöstes av ett tjänstproblem för Azure-prenumerationen...". Mer information om tjänsthälsoaviseringar finns i Ta emot aktivitetsloggaviseringar på Azure-tjänstaviseringar med hjälp av Azure Portal.
Viktigt!
Som namnet antyder används tillfälliga tabellområden i PostgreSQL för tillfälliga objekt, samt andra interna databasåtgärder, till exempel sortering. Därför rekommenderar vi inte att du skapar användarschemaobjekt i ett tillfälligt tabellområde, eftersom vi inte garanterar hållbarheten för sådana objekt efter serveromstarter, HA-redundans osv.
Oplanerad stilleståndstid: felscenarier och tjänståterställning
Nedan visas några oplanerade felscenarier och återställningsprocessen.
| Scenario |
Återställningsprocess [Servrar som konfigurerats utan zonredundant HA] |
Återställningsprocess [Servrar som konfigurerats med zonredundant HA] |
|---|---|---|
| Databasserverfel | Om databasservern är nere försöker Azure starta om databasservern. Om det misslyckas startas databasservern om på en annan fysisk nod. Återställningstiden (RTO) är beroende av olika faktorer, inklusive aktiviteten vid tidpunkten för felet, till exempel stora transaktioner och den återställningsvolym som ska utföras under startprocessen för databasservern. Program som använder PostgreSQL-databaserna måste byggas på ett sätt som identifierar och försöker igen avbrutna anslutningar och misslyckade transaktioner. |
Om databasserverfelet identifieras redundas servern över till väntelägesservern, vilket minskar stilleståndstiden. Mer information finns på sidan [HA-begrepp]/azure/reliability/reliability-postgresql-flexible-server. RTO förväntas vara 60–120-talet, med noll dataförlust. |
| Lagringsfel | Program ser ingen inverkan på lagringsrelaterade problem, till exempel ett diskfel eller en fysisk blockskada. Eftersom data lagras i tre kopior hanteras kopian av data av den kvarvarande lagringen. Det skadade datablocket repareras automatiskt och en ny kopia av data skapas automatiskt. | För sällsynta och icke-återställningsbara fel, till exempel att hela lagringen är otillgänglig, redundas Azure Database for PostgreSQL flexibel serverinstans över till väntelägesrepliken för att minska stilleståndstiden. Mer information finns på sidan [HA-begrepp]/azure/reliability/reliability-postgresql-flexible-server. |
| Logiska/användarfel | Om du vill återställa från användarfel, till exempel oavsiktligt borttagna tabeller eller felaktigt uppdaterade data, måste du utföra en återställning till tidpunkt (PITR). När du utför återställningsåtgärden anger du den anpassade återställningspunkten, vilket är tiden precis innan felet inträffade. Om du bara vill återställa en delmängd av databaser eller specifika tabeller i stället för alla databaser på databasservern kan du återställa databasservern i en ny instans, exportera tabellerna via pg_dump och sedan använda pg_restore för att återställa tabellerna till databasen. |
Dessa användarfel skyddas inte med hög tillgänglighet eftersom alla ändringar replikeras till väntelägesrepliken synkront. Du måste utföra återställning till tidpunkt för att återställa från sådana fel. |
| Fel i tillgänglighetszon | Om du vill återställa från ett fel på zonnivå kan du utföra återställning till tidpunkt med hjälp av säkerhetskopieringen och välja en anpassad återställningspunkt med den senaste tiden för att återställa de senaste data. En ny flexibel Azure Database for PostgreSQL-serverinstans distribueras i en annan zon som inte påverkas. Den tid det tar att återställa beror på den tidigare säkerhetskopieringen och volymen av transaktionsloggar som ska återställas. | En flexibel instans av Azure Database för PostgreSQL växlar automatiskt över till standby-servern inom 60–120 sekunder utan dataförlust. Mer information finns på sidan [HA-begrepp]/azure/reliability/reliability-postgresql-flexible-server. |
| Regionfel | Om servern har konfigurerats med geo-redundant säkerhetskopiering kan du utföra geo-återställning i den kopplade regionen. En ny server etableras och återställs till de senast tillgängliga data som kopierades till den här regionen. Du kan också använda skrivskyddade repliker mellan regioner. I händelse av regionfel kan du utföra haveriberedskap genom att befordra din läsreplik till en fristående skrivbar server. RPO förväntas vara upp till 5 minuter (dataförlust möjlig) förutom vid allvarliga regionala fel när RPO kan vara nära replikeringsfördröjningen vid tidpunkten för felet. |
Samma process. |
Konfigurera databasen efter återställning från regionalt fel
- Om du använder geo-återställning eller geo-replik för att återställa från ett avbrott måste du se till att anslutningen till den nya servern är korrekt konfigurerad så att den normala programfunktionen kan återupptas. Du kan följa uppgifterna efter återställningen.
- Om du tidigare har konfigurerat en diagnostikinställning på den ursprungliga servern ska du göra samma sak på målservern om det behövs enligt beskrivningen i Konfigurera och komma åt loggar i Azure Database for PostgreSQL.
- Konfigurera telemetriaviseringar. Du måste se till att dina befintliga aviseringsregelinställningar har uppdaterats för att mappas till den nya servern. Mer information om aviseringsregler finns i Använda Azure-portalen för att konfigurera aviseringar för mått för Azure Database for PostgreSQL.
Viktigt!
Borttagna servrar kan återställas. Om du tar bort servern kan du följa vår vägledning Återställa en borttagen Azure-databas för återställning. Använd Azure-resurslås för att förhindra oavsiktlig borttagning av servern.