Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
AI-agenter transformerar hur program interagerar med data genom att kombinera stora språkmodeller (LLM) med externa verktyg och databaser. Agenter möjliggör automatisering av komplexa arbetsflöden, förbättrar noggrannheten i informationshämtningen och underlättar gränssnitt för naturligt språk till databaser.
I den här artikeln beskrivs hur du skapar intelligenta AI-agenter som kan söka efter och analysera dina data i Azure Database for PostgreSQL. Den går igenom konfiguration, implementering och testning med hjälp av en juridisk forskningsassistent som exempel.
Vad är AI-agenter?
AI-agenter går längre än enkla chattrobotar genom att kombinera LLM:er med externa verktyg och databaser. Till skillnad från fristående LLM:er eller RAG-system (Standard Retrieval Augmented Generation) kan AI-agenter:
- Plan: Dela upp komplexa uppgifter i mindre sekventiella steg.
- Använd verktyg: Använd API:er, kodkörning och söksystem för att samla in information eller utföra åtgärder.
- Uppfatta: Förstå och bearbeta indata från olika datakällor.
- Kom ihåg: Lagra och återkalla tidigare interaktioner för bättre beslutsfattande.
Genom att ansluta AI-agenter till databaser som Azure Database for PostgreSQL kan agenter leverera mer exakta, sammanhangsmedvetna svar baserat på dina data. AI-agenter sträcker sig bortom grundläggande mänsklig konversation för att utföra uppgifter baserat på naturligt språk. Dessa uppgifter krävde traditionellt kodad logik. Agenter kan dock planera de uppgifter som krävs för att köra baserat på användarspecifik kontext.
Implementering av AI-agenter
Implementering av AI-agenter med Azure Database for PostgreSQL omfattar integrering av avancerade AI-funktioner med robusta databasfunktioner för att skapa intelligenta, kontextmedvetna system. Med hjälp av verktyg som vektorsökning, inbäddningar och Foundry Agent Service kan utvecklare skapa agenter som förstår frågor på naturligt språk, hämtar relevanta data och ger användbara insikter.
I följande avsnitt beskrivs den stegvisa processen för att konfigurera, konfigurera och distribuera AI-agenter. Den här processen möjliggör sömlös interaktion mellan AI-modeller och din PostgreSQL-databas.
Ramverk
Olika ramverk och verktyg kan underlätta utvecklingen och distributionen av AI-agenter. Alla dessa ramverk stöder användning av Azure Database for PostgreSQL som ett verktyg:
Exempel på implementering
I den här artikelns exempel används Agent Service för agentplanering, verktygsanvändning och uppfattning. Den använder Azure Database for PostgreSQL som ett verktyg för vektordatabaser och semantiska sökfunktioner.
Följande avsnitt beskriver hur du skapar en AI-agent som hjälper juridiska team att undersöka relevanta fall för att stödja sina kunder i Delstaten Washington. Agenten:
- Accepterar frågor på naturligt språk om juridiska situationer.
- Använder vektorsökning i Azure Database for PostgreSQL för att hitta relevanta fallförekomster.
- Analyserar och sammanfattar resultaten i ett användbart format för jurister.
Förutsättningar
Aktivera och konfigurera tilläggen
azure_aiochpg_vector.Distribuera modeller
gpt-4o-miniochtext-embedding-small.Installera Visual Studio Code.
Installera Python-tillägget .
Installera Python 3.11.x.
Installera Azure CLI (den senaste versionen).
Anmärkning
Du behöver nyckeln och slutpunkten från de distribuerade modeller som du skapade för agenten.
Komma igång
Alla kod- och exempeldatauppsättningar är tillgängliga på den här GitHub-lagringsplatsen.
Steg 1: Konfigurera vektorsökning i Azure Database for PostgreSQL
Förbered först databasen för att lagra och söka efter juridiska falldata med hjälp av vektorinbäddningar.
Konfigurera miljön
Om du använder macOS och Bash kör du följande kommandon:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Om du använder Windows och PowerShell kör du följande kommandon:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Om du använder Windows och cmd.exekör du följande kommandon:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Konfigurera miljövariabler
Skapa en .env fil med dina autentiseringsuppgifter:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Läsa in dokument och vektorer
Python-filen load_data/main.py fungerar som den centrala startpunkten för att läsa in data i Azure Database for PostgreSQL. Koden bearbetar data för exempelfall, inklusive information om fall i Washington.
Filen main.py:
- Skapar nödvändiga tillägg, konfigurerar OpenAI API-inställningar och hanterar databastabeller genom att ta bort befintliga och skapa nya för lagring av ärendedata.
- Läser data från en CSV-fil och infogar dem i en tillfällig tabell och bearbetar och överför dem sedan till huvudfallstabellen.
- Lägger till en ny kolumn för inbäddningar i ärendetabellen och genererar inbäddningar för ärendeyttranden med hjälp av OpenAI:s API. Den lagrar inbäddningarna i den nya kolumnen. Inbäddningsprocessen tar cirka 3 till 5 minuter.
Starta datainläsningsprocessen genom att köra följande kommando från load_data katalogen:
python main.py
Här är utdata från main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Steg 2: Skapa ett Postgres-verktyg för agenten
Konfigurera sedan AI-agentverktyg för att hämta data från Postgres. Använd sedan Agent Service SDK för att ansluta DIN AI-agent till Postgres-databasen.
Definiera en funktion som agenten ska anropa
Börja med att definiera en funktion som agenten ska anropa genom att beskriva dess struktur och eventuella obligatoriska parametrar i en dokumentsträng. Inkludera alla funktionsdefinitioner i en enda fil , legal_agent_tools.py. Du kan sedan importera filen till huvudskriptet.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Steg 3: Skapa och konfigurera AI-agenten med Postgres
Nu konfigurerar du AI-agenten och integrerar den med Postgres-verktyget. Python-filen src/simple_postgres_and_ai_agent.py fungerar som den centrala startpunkten för att skapa och använda din agent.
Filen simple_postgres_and_ai_agent.py:
- Initierar agenten i ditt Foundry-projekt med en specifik modell.
- Lägger till Postgres-verktyget för vektorsökning i databasen under agentinitieringen.
- Konfigurerar en kommunikationstråd. Den här tråden används för att skicka meddelanden till agenten för bearbetning.
- Bearbetar användarens fråga med hjälp av agenten och verktygen. Agenten kan planera med verktyg för att få rätt svar. I det här användningsfallet anropar agenten Postgres-verktyget baserat på funktionssignaturen och dokumentsträngen för att göra en vektorsökning och hämta relevanta data för att besvara frågan.
- Visar agentens svar på användarens fråga.
Hitta projektanslutningssträngen i Foundry
I ditt Foundry-projekt hittar du projektanslutningssträngen från projektets översiktssida. Du använder den här strängen för att ansluta projektet till Agent Service SDK. Lägg till den här strängen i .env filen.
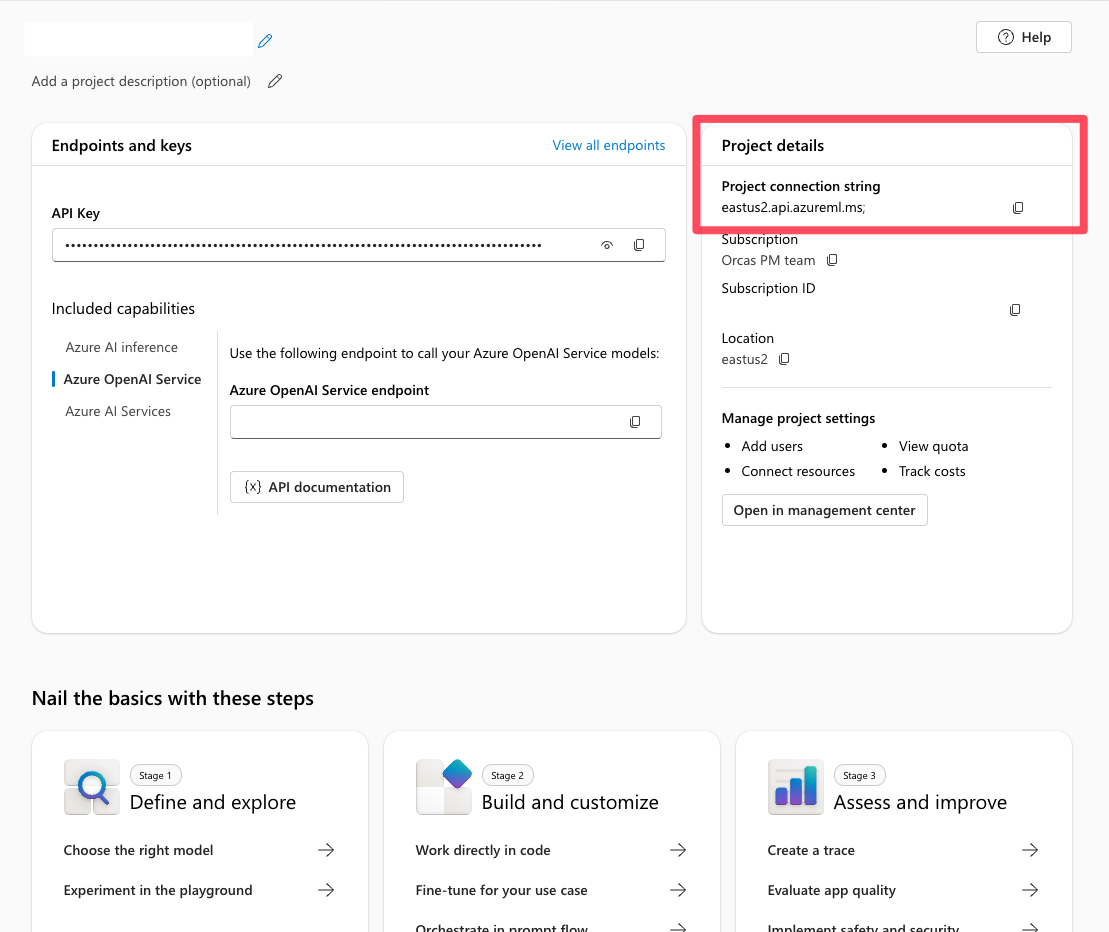
Ställer in anslutningsprogram
Lägg till dessa variabler i din .env-fil i rotkatalogen:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Skapa en kommunikationstråd
Det här kodfragmentet visar hur du skapar en agenttråd och ett meddelande som agenten bearbetar i en körning:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Bearbeta begäran
Följande kodfragment skapar en körning för agenten för att bearbeta meddelandet och använda lämpliga verktyg för att ge bästa resultat.
Med hjälp av verktygen kan agenten anropa Postgres och vektorsökningen på frågan "Vatten läcker in i lägenheten från golvet ovan" för att hämta de data som behövs för att besvara frågan bäst.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Kör agenten
Kör följande kommando från katalogen för att köra agenten src :
python simple_postgres_and_ai_agent.py
Agenten ger ett liknande resultat med hjälp av verktyget Azure Database for PostgreSQL för att komma åt ärendedata som sparats i Postgres-databasen.
Här är ett kodfragment med utdata från agenten:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
Steg 4: Testa och felsöka med agentens lekplats
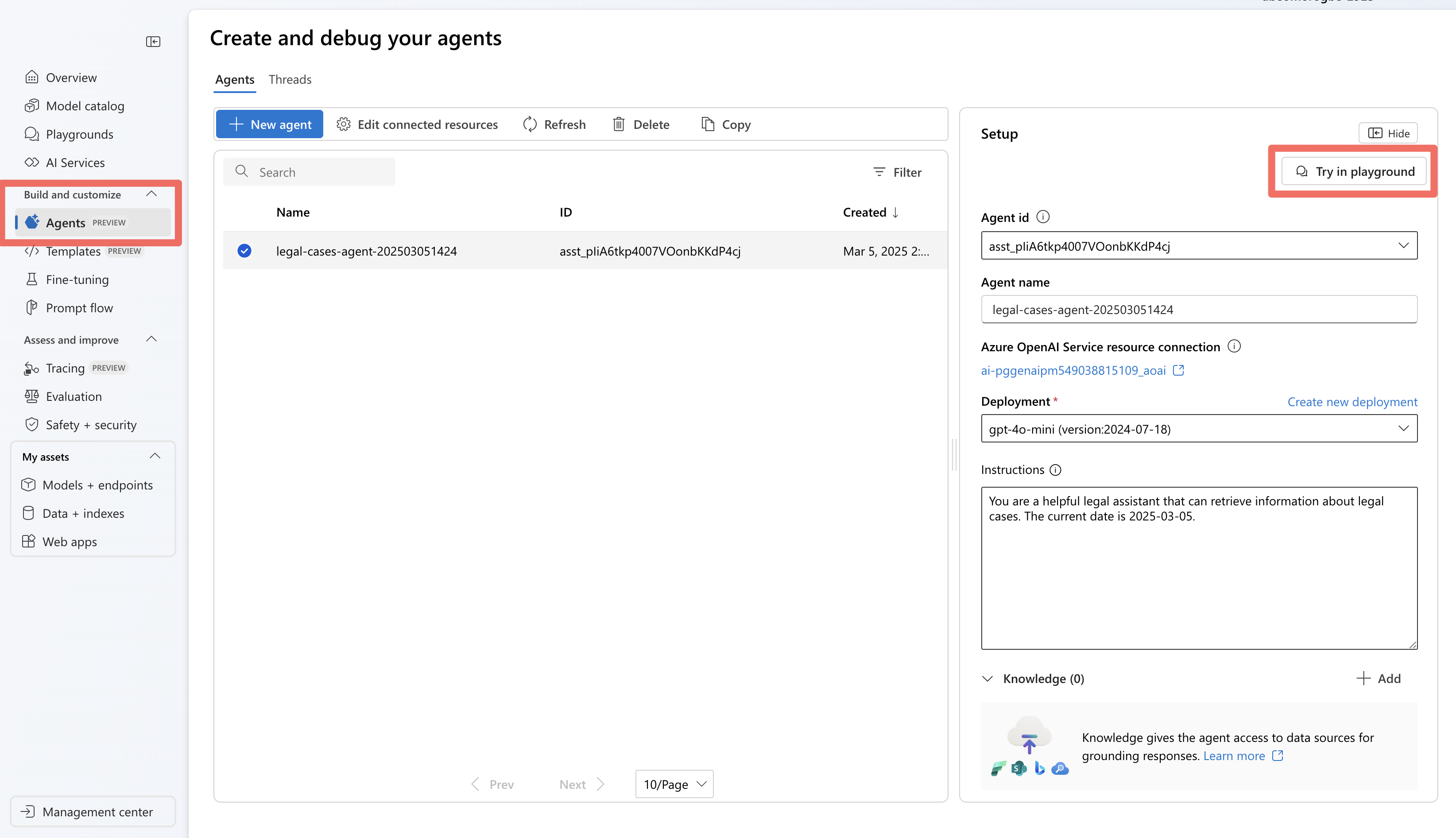
När du har kört din agent med hjälp av Agent Service SDK lagras agenten i ditt projekt. Du kan experimentera med agenten på agentens lekplats:
I Foundry går du till avsnittet Agenter .
Leta upp din agent i listan och välj den för att öppna den.
Använd playground-gränssnittet för att testa olika juridiska frågor.
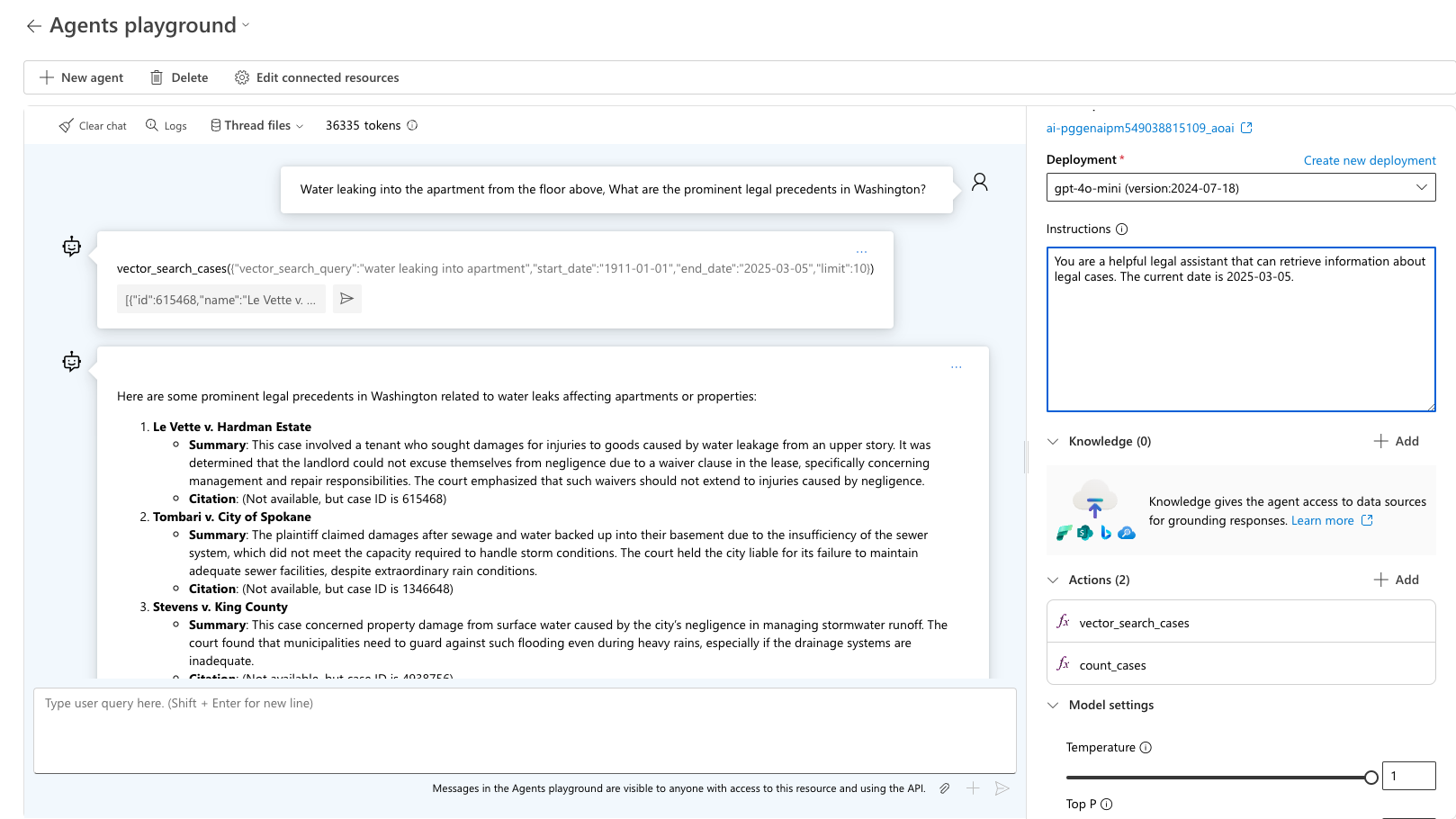
Testa frågan "Vatten som läcker in i lägenheten från golvet ovan, Vilka är de framträdande rättsliga prejudikaten i Washington?" Agenten väljer rätt verktyg att använda och frågar efter förväntade utdata för frågan. Använd sample_vector_search_cases_output.json som exempelutdata.
Steg 5: Felsöka med Foundry-spårning
När du utvecklar agenten med hjälp av Agent Service SDK kan du felsöka agenten med spårning. Med spårning kan du felsöka anropen till verktyg som Postgres och se hur agenten orkestrerar varje uppgift.
I Foundry går du till Spårning.
Om du vill skapa en ny Application Insights-resurs väljer du Skapa ny. Om du vill ansluta en befintlig resurs väljer du en i rutan Application Insights-resursnamn och väljer sedan Anslut.
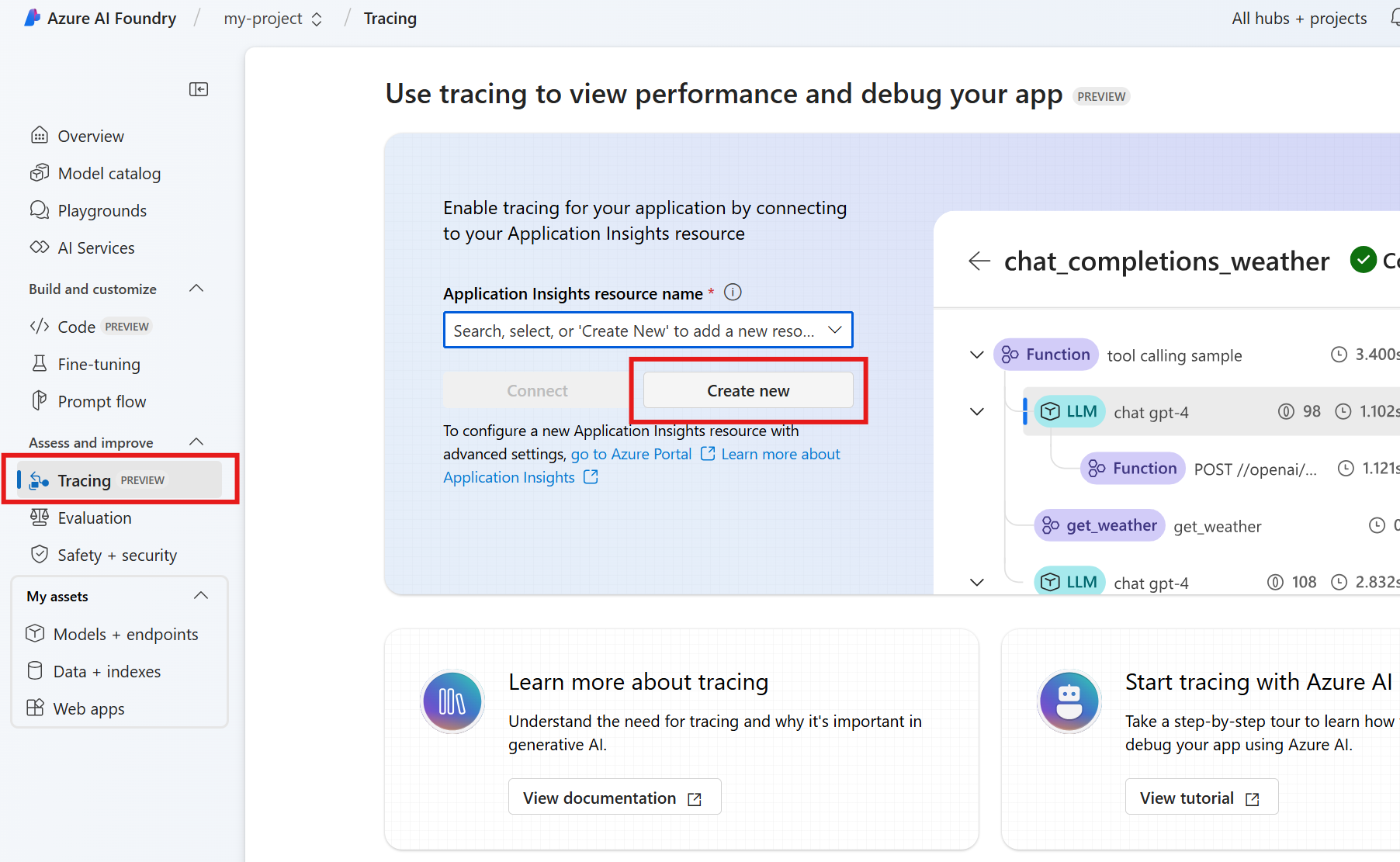
Visa detaljerade spår av agentens åtgärder.
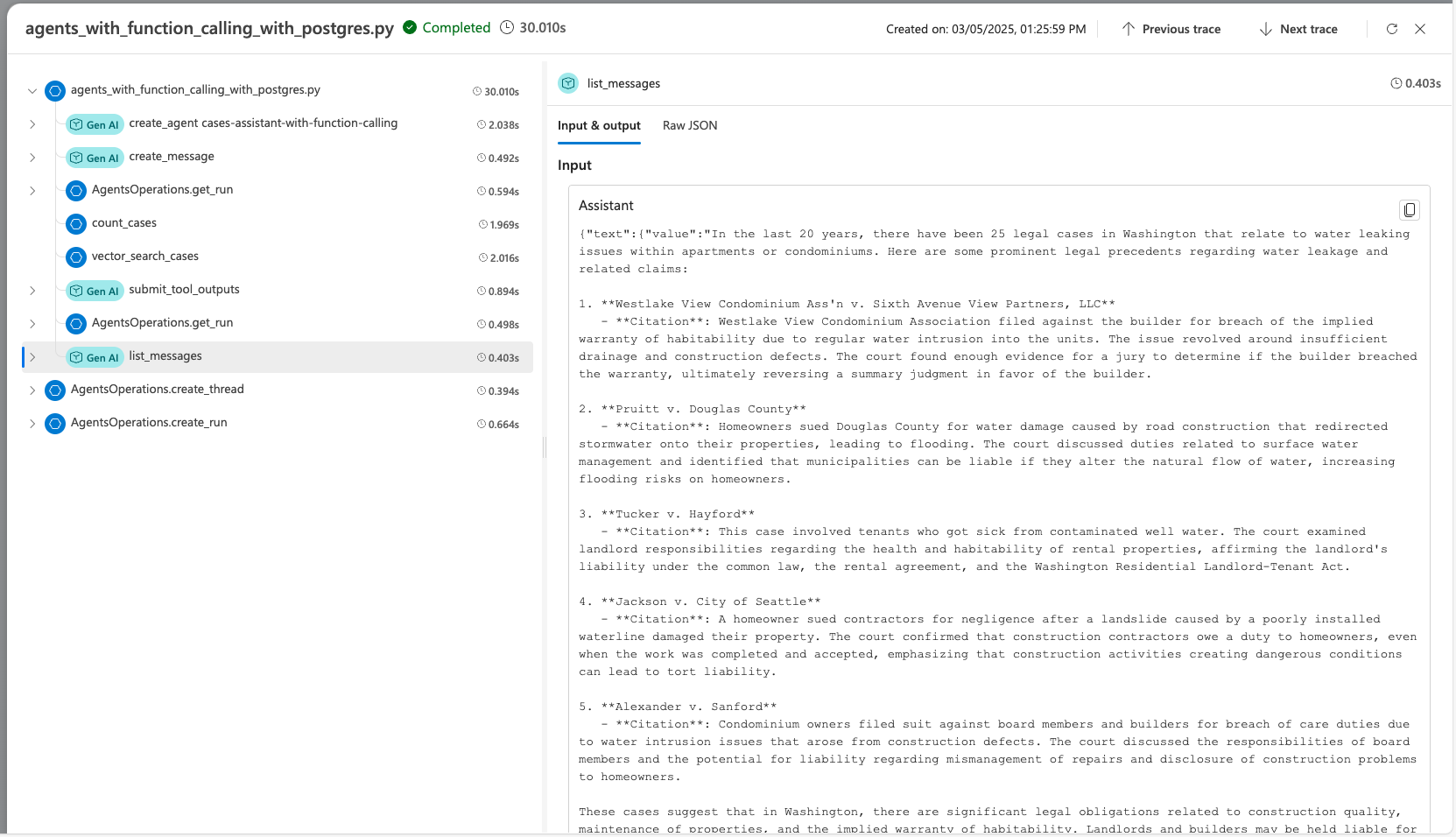
Läs mer om hur du konfigurerar spårning med AI-agenten och Postgres i filen advanced_postgres_and_ai_agent_with_tracing.py på GitHub.
Relaterat innehåll
- Azure Database for PostgreSQL-integreringar för AI-applikationer
- Använd LangChain med Azure Database for PostgreSQL
- Generera vektorinbäddningar med Azure OpenAI i Azure Database for PostgreSQL
- Azure AI-tillägg i Azure Database for PostgreSQL
- Skapa en semantisk sökning med Azure Database for PostgreSQL och Azure OpenAI
- Aktivera och använda pgvector i Azure Database for PostgreSQL