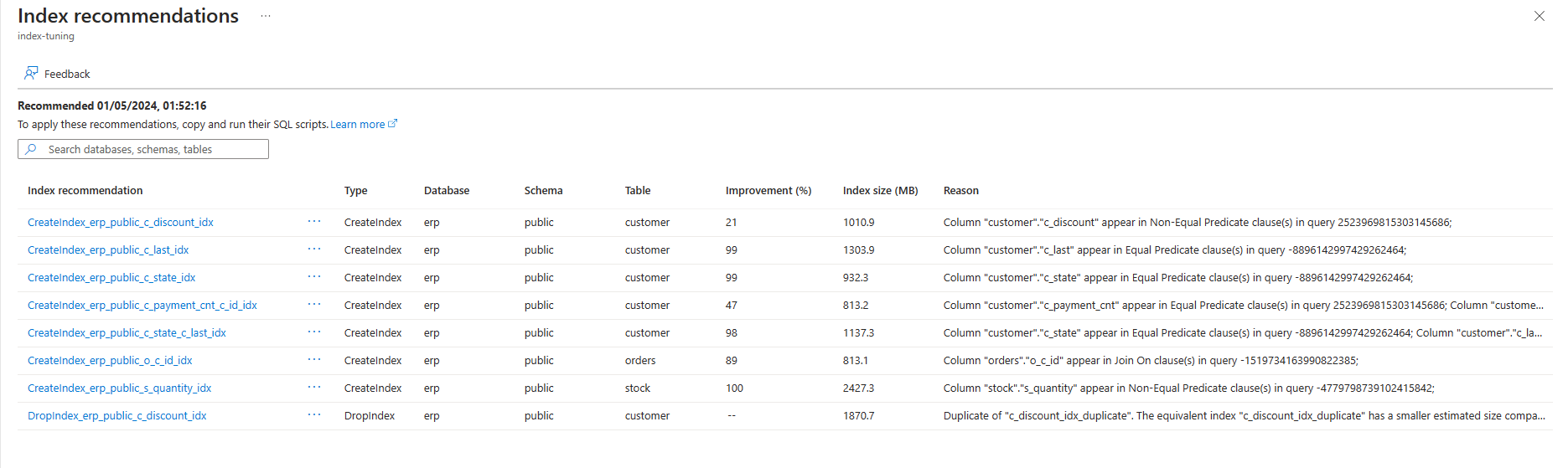
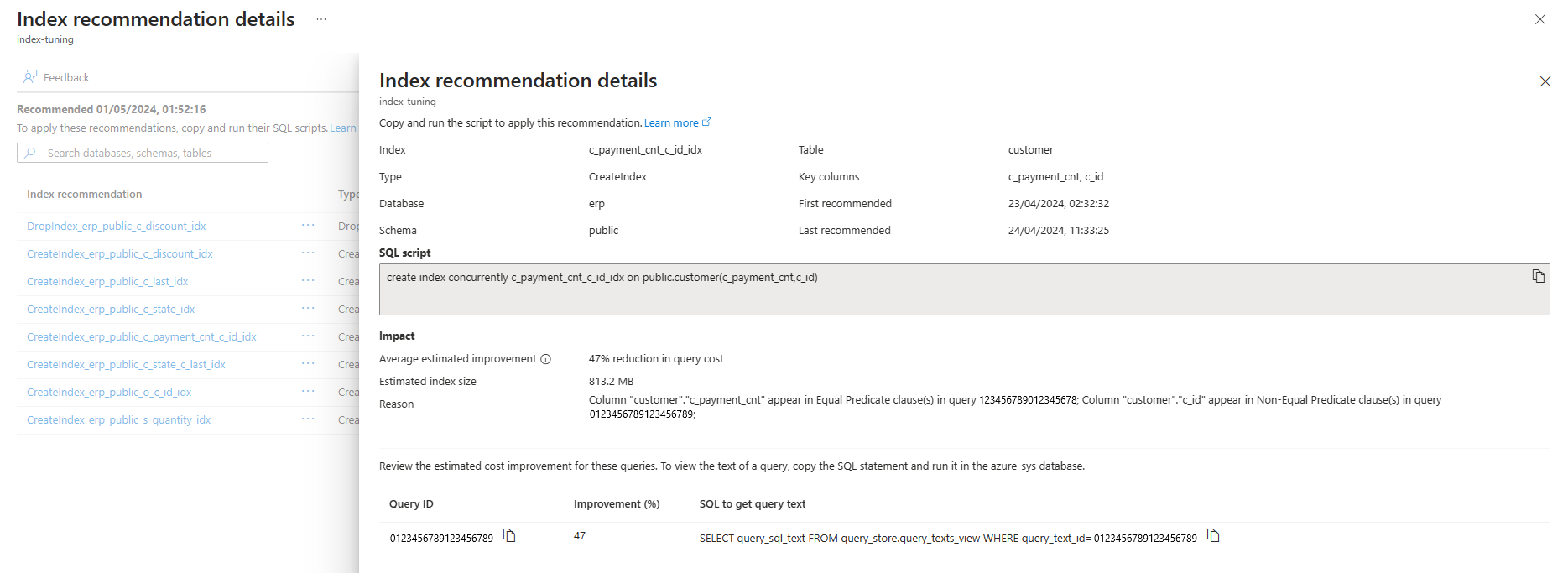
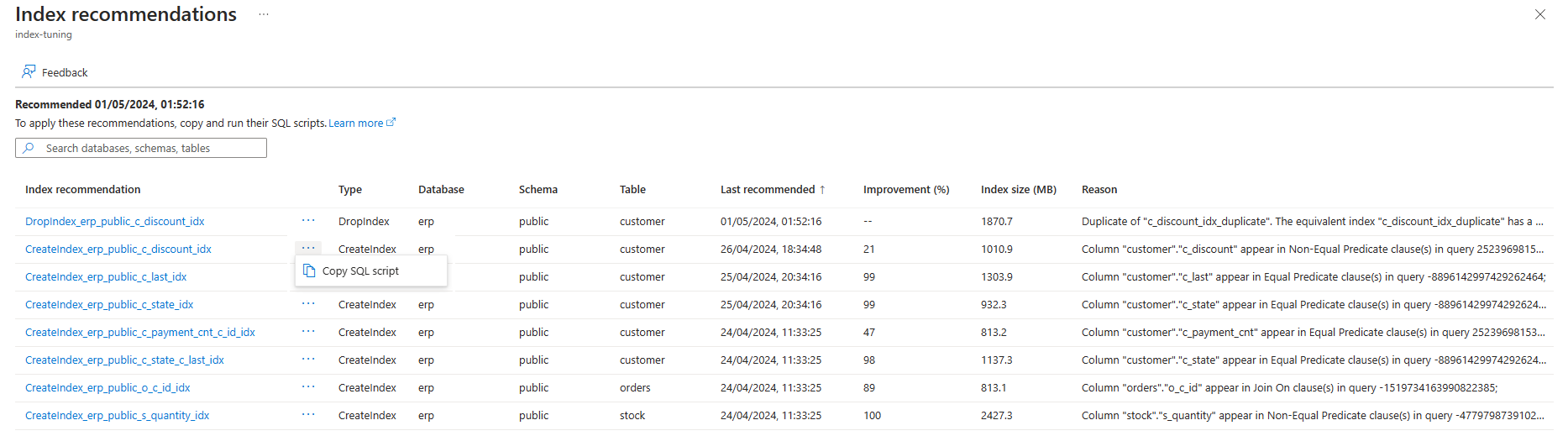
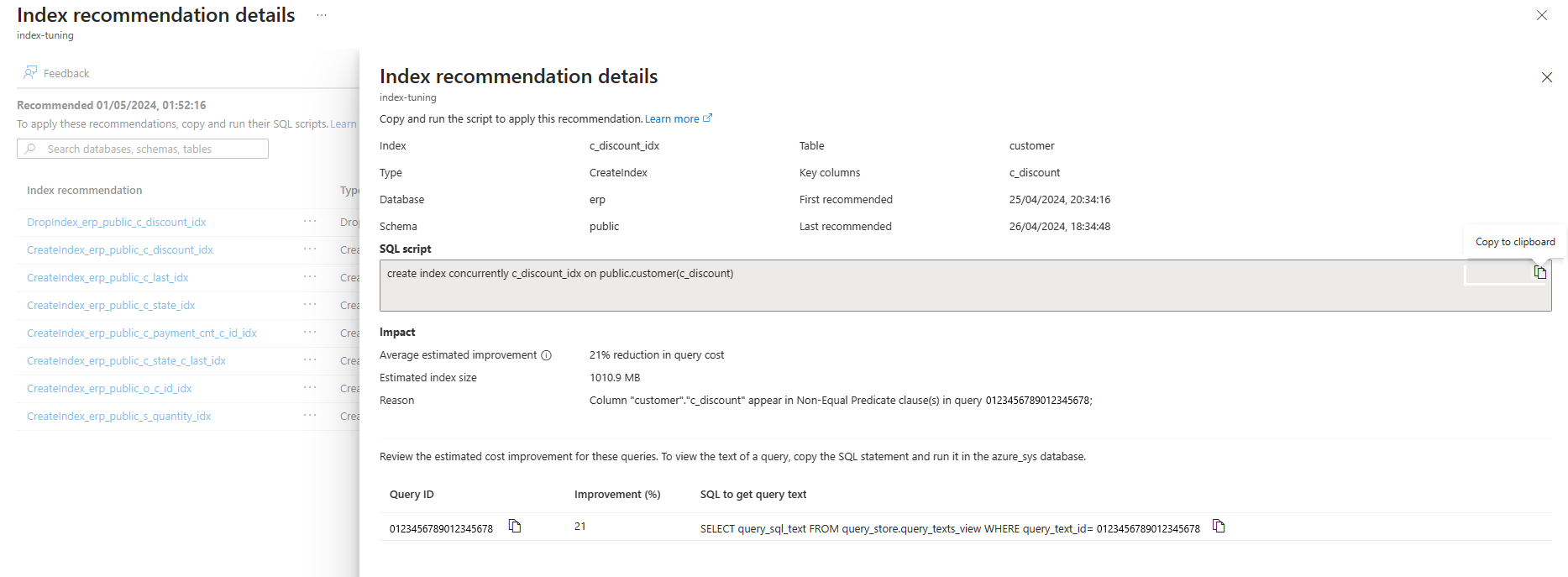
Du kan lista rekommendationer för indexjustering som skapas genom indexjustering på en befintlig server via kommandot az postgres flexible-server index-tuning list-recommendations .
Använd det här kommandot om du vill visa en lista över alla CREATE INDEX-rekommendationer:
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type createindex
Kommandot returnerar all information om CREATE INDEX-rekommendationerna som genereras av indexjustering, vilket visar något som liknar följande utdata:
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T14:40:18.788628+00:00",
"queryCount": 18,
"startTime": "2025-02-26T13:40:18.788628+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "\"<table>\".\"<column>\"",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 0.3984375,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
},
{
"absoluteValue": 62.86969111969111,
"dimensionName": "QueryCostImprovement",
"queryId": -555955670159268890,
"unit": "Percentage"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "create index concurrently <index> on <schema>.<table>(<column>)"
},
"improvedQueryIds": [
-555955670159268890
],
"initialRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"name": "CreateIndex_<database>_<schema>_<column>_idx",
"recommendationReason": "Column \"<table>\".\"<column>\" appear in Equal Predicate clause(s) in query -555955670159268890;",
"recommendationType": "CreateIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Använd det här kommandot om du vill visa en lista över alla DROP INDEX-rekommendationer:
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type dropindex
Kommandot returnerar all information om DROP INDEX-rekommendationerna som genereras av indexjustering, vilket visar något som liknar följande utdata:
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2025-01-22T19:02:47.522193+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "<column>",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 35.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 31.28125,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "drop index concurrently \"<schema>\".\"<index>\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"name": "DropIndex_<database>_<sechema>_<index>",
"recommendationReason": "Duplicate of \"<index>\". The equivalent index \"<index>\" has a shorter length compared to \"<index>\".",
"recommendationType": "DropIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
}
]
Använd valfritt PostgreSQL-klientverktyg enligt dina önskemål:
Anslut till azure_sys-databasen på din server med en roll som har behörighet att ansluta till instansen. Medlemmar i public rollen kan läsa från dessa vyer.
Kör sökfrågor på sessions i vyn för att hämta information om rekommendationssessionernas detaljer.
Kör frågor i recommendations vyn för att hämta rekommendationerna från indexjustering för CREATE INDEX och DROP INDEX.
Vyer
Vyer i azure_sys databasen är ett bekvämt sätt att komma åt och hämta indexrekommendationer som genereras av indexjustering. Mer specifikt innehåller vyerna createindexrecommendations och dropindexrecommendations detaljerad information om rekommendationer för CREATE INDEX respektive DROP INDEX. Dessa vyer exponerar data som sessions-ID, databasnamn, typ av rådgivare, start- och stopptider för justeringssessionen, rekommendations-ID, rekommendationstyp, orsak till rekommendationen och annan relevant information. Användare kan köra frågor mot dessa vyer för att enkelt komma åt och analysera indexrekommendationerna som skapas genom indexjustering.
Vyn sessions visar all information för alla indexjusteringssessioner.
| kolumnnamn |
datatyp |
beskrivning |
| session_id |
Universellt unik identifierare (UUID) |
Globalt unik identifierare tilldelad till varje ny justeringssession som initieras. |
| databasnamn |
varchar(64) |
Namnet på databasen i vars kontext indexjusteringssessionen kördes. |
| sessionstyp |
intelligentperformance.recommendation_type |
Anger vilka typer av rekommendationer som indexjusteringssessionen kan ge. Möjliga värden är: CreateIndex, DropIndex. Sessioner av CreateIndex typen kan ge rekommendationer av CreateIndex typen. Sessioner av DropIndex typen kan ge rekommendationer av DropIndex eller ReIndex typer. |
| körtyp |
intelligentperformance.recommendation_run_type |
Anger hur sessionen initierades. Möjliga värden är: Scheduled. Sessioner som körs automatiskt enligt värdet av index_tuning.analysis_interval, tilldelas körningstypen Scheduled. |
| tillstånd |
intelligentperformance.rekommendationsstatus |
Anger sessionens aktuella tillstånd. Möjliga värden är: Error, Success, InProgress. Sessioner där körningen misslyckades anges som Error. Sessioner som slutförde körningen korrekt, oavsett om de genererade rekommendationer eller inte, anges som Success. Sessioner som fortfarande körs anges som InProgress. |
| starttid |
tidsstämpel utan tidszon |
Tidsstämpel där justeringssessionen som producerade den här rekommendationen startades. |
| stopptid |
tidsstämpel utan tidszon |
Tidsstämpel där justeringssessionen som producerade den här rekommendationen startades. NULL om sessionen pågår eller avbröts på grund av ett fel. |
| antal rekommendationer |
heltal |
Totalt antal rekommendationer som tagits fram i den här sessionen. |
Vyn recommendations visar all information för alla rekommendationer som genereras för alla justeringssessioner vars data fortfarande är tillgängliga i de underliggande tabellerna.
| kolumnnamn |
datatyp |
beskrivning |
| rekommendations_id |
heltal |
Nummer som unikt identifierar en rekommendation på hela servern. |
| senast_kända_session_id |
Universellt unik identifierare (UUID) |
Varje indexjusteringssession tilldelas en globalt unik identifierare. Värdet i den här kolumnen representerar värdet för den session som senast skapade den här rekommendationen. |
| databasnamn |
varchar(64) |
Namnet på databasen i vars kontext rekommendationen skapades. |
| rekommendationstyp |
intelligentperformance.recommendation_type |
Anger vilken typ av rekommendation som har skapats. Möjliga värden är: CreateIndex, DropIndex, ReIndex. |
| initial_rekommenderad_tid |
tidsstämpel utan tidszon |
Tidsstämpel där justeringssessionen som producerade den här rekommendationen startades. |
| senast_rekommenderade_tid |
tidsstämpel utan tidszon |
Tidsstämpel där justeringssessionen som producerade den här rekommendationen startades. |
| antal gånger rekommenderat |
heltal |
Tidsstämpel där justeringssessionen som producerade den här rekommendationen startades. |
| orsak |
texten |
Orsak som motiverar varför den här rekommendationen har tagits fram. |
| rekommendationskontext |
json |
Innehåller listan med frågeidentifierare för de frågor som påverkas av rekommendationen, vilken typ av index som rekommenderas, namnet på schemat och namnet på den tabell där indexet rekommenderas, indexkolumnerna, indexnamnet och den uppskattade storleken i byte för det rekommenderade indexet. |
Orsaker till att skapa indexrekommendationer
När indexjustering rekommenderar att ett index skapas lägger det till minst en av följande orsaker:
| Anledning |
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Orsaker till rekommendationer för släppindex
När indexjustering identifierar eventuella index som har markerats som ogiltiga föreslår den att det tas bort med följande orsak:
The index is invalid and the recommended recovery method is to reindex.
Mer information om varför och när index markeras som ogiltiga finns i den officiella dokumentationen om REINDEX i PostgreSQL.
Orsaker till rekommendationer för släppindex
När indexjustering identifierar ett index som inte används i minst det antal dagar som anges i index_tuning.unused_min_periodföreslår den att det tas bort med följande orsak:
The index is unused in the past <days_unused> days.
När indextuning identifierar duplicerade index överlever en av dubbletterna, och den föreslår att de återstående tas bort. Orsaken som anges har alltid följande starttext:
Duplicate of <surviving_duplicate>.
Följt av en annan text som förklarar orsaken till att var och en av dubbletterna har valts för borttagning:
| Anledning |
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Om indexet inte bara är flyttbart på grund av duplicering, utan även är oanvänt i minst det antal dagar som anges i index_tuning.unused_min_period, läggs följande text till som orsak.
Also, the index is unused in the past <days_unused> days.