Hantering av affärskontinuitet i Azure
Azure har ett av de mest mogna och respekterade programmen för hantering av affärskontinuitet i branschen. Målet med affärskontinuitet i Azure är att skapa och främja återställning och återhämtning för alla oberoende återställningsbara tjänster, oavsett om en tjänst är kundinriktad (en del av ett Azure-erbjudande) eller en intern plattformstjänst.
För att förstå affärskontinuitet är det viktigt att notera att många erbjudanden består av flera tjänster. I Azure identifieras varje tjänst statiskt via verktyg och är den måttenhet som används för sekretess, säkerhet, inventering, hantering av affärskontinuitet för risker och andra funktioner. För att korrekt mäta funktioner i en tjänst ingår de tre elementen i personer, processer och teknik för varje tjänst, oavsett tjänsttyp.
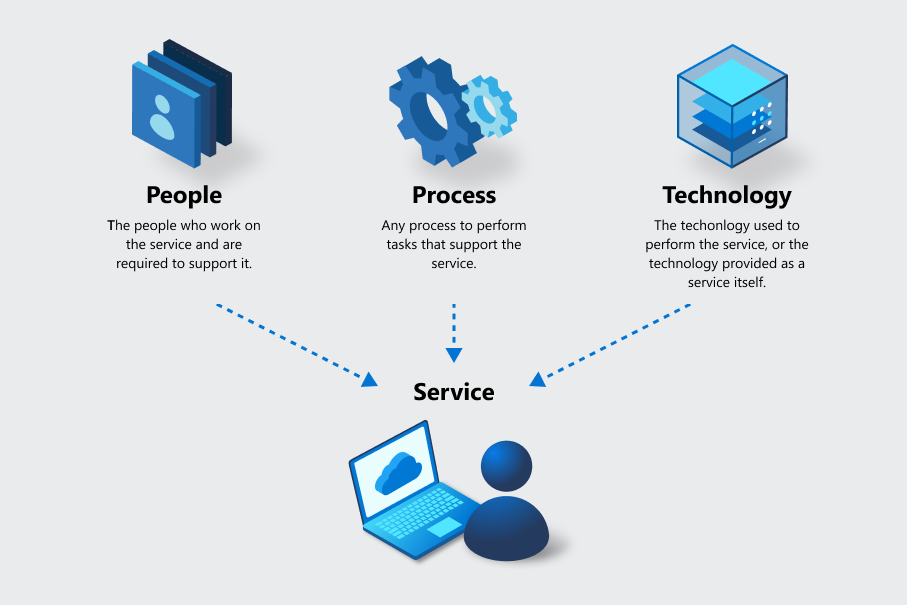
Till exempel:
- Om det finns en affärsprocess baserad på personer, till exempel en supportavdelning eller ett team, är tjänstleveransen vad de gör. Personerna använder processer och teknik för att utföra tjänsten.
- Om det finns teknik som en tjänst, till exempel Azure Virtual Machines, är tjänstleveransen tekniken tillsammans med de personer och processer som stöder dess drift.
Delad ansvarsmodell
Många av de erbjudanden som Azure tillhandahåller kräver att du konfigurerar haveriberedskap i flera regioner och inte är Microsofts ansvar. Alla Azure-tjänster replikerar inte data automatiskt eller återgår automatiskt från en misslyckad region för att korsreparera till en annan aktiverad region. I dessa fall ansvarar du för att konfigurera återställning och replikering.
Microsoft ser till att baslinjeinfrastrukturen och plattformstjänsterna är tillgängliga. Men i vissa scenarier kräver användning att du duplicerar dina distributioner och lagring i en kapacitet för flera regioner, om du väljer att göra det. De här exemplen illustrerar modellen med delat ansvar. Det är en grundläggande grundpelare i din strategi för affärskontinuitet och haveriberedskap.
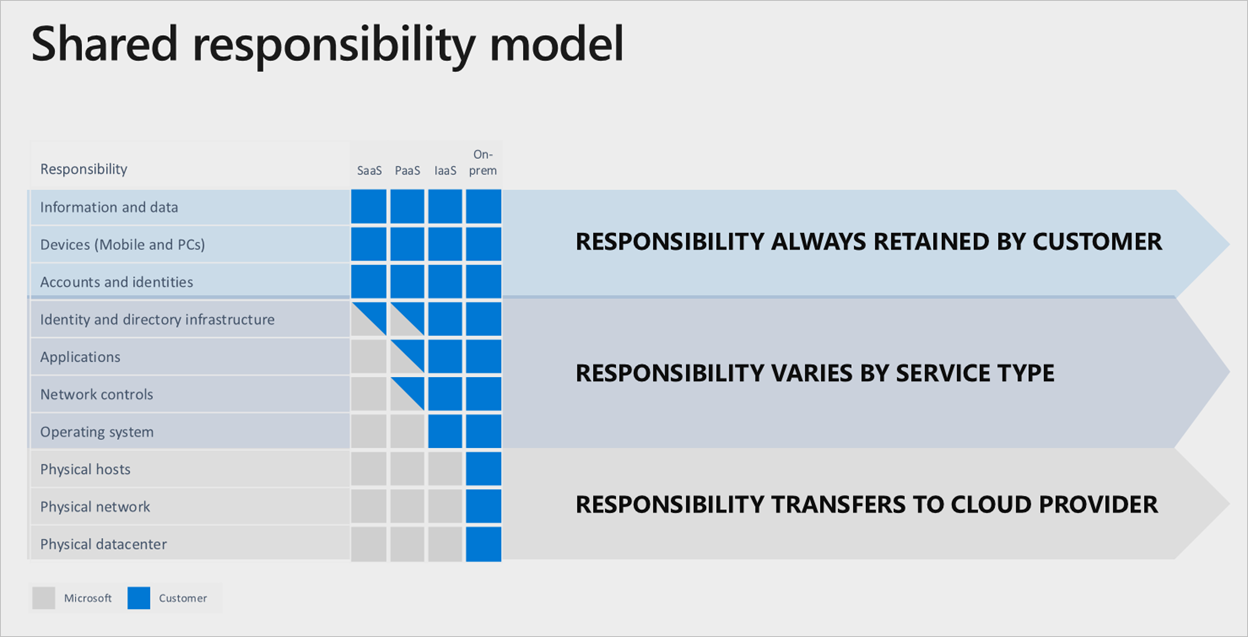
Ansvarsfördelning
I alla lokala datacenter äger du hela stacken. När du flyttar tillgångar till molnet överförs vissa ansvarsområden till Microsoft. Följande diagram illustrerar områden och ansvarsfördelning mellan dig och Microsoft beroende på typen av distribution.
Ett bra exempel på modellen med delat ansvar är distributionen av virtuella datorer. Om du vill konfigurera replikering mellan regioner för återhämtning om det uppstår regionfel måste du distribuera en duplicerad uppsättning virtuella datorer i en alternativ aktiverad region. Azure replikerar inte tjänsterna automatiskt om det uppstår ett fel. Det är ditt ansvar att distribuera nödvändiga tillgångar. Du måste ha en process för att manuellt ändra primära regioner, eller så måste du använda en trafikhanterare för att identifiera och automatiskt redundansväxla.
Kundaktiverade haveriberedskapstjänster har all offentlig dokumentation som vägleder dig. Ett exempel på offentlig dokumentation för kundaktiverad haveriberedskap finns i Azure Data Lake Analytics.
Mer information om modellen med delat ansvar finns i Microsoft Trust Center.
Efterlevnad av affärskontinuitet: Ansvar på servicenivå
Varje tjänst krävs för att slutföra haveriberedskapsposter för affärskontinuitet i Azure Business Continuity Manager-verktyget. Tjänstägare kan använda verktyget för att arbeta inom en federerad modell för att slutföra och införliva krav som omfattar:
Tjänstegenskaper: Definierar tjänsten och hur haveriberedskap och återhämtning uppnås och identifierar den ansvariga parten för haveriberedskap (för teknik). Mer information om ägarskap för återställning finns i diskussionen om modellen för delat ansvar i föregående avsnitt och diagram.
Analys av affärspåverkan: Den här analysen hjälper tjänstägaren att definiera mål för återställningstid (RTO) och mål för återställningspunkter (RPO) baserat på tjänstens allvarlighetsgrad i en tabell med påverkan. Drifts-, juridiska, regelmässiga, varumärkesmässiga och ekonomiska effekter används som målmål för återställning.
Kommentar
Microsoft publicerar inte RTO eller RRPOs för tjänster eftersom dessa data endast gäller för interna mått. Alla kundlöften och mått är SLA-baserade eftersom det täcker ett bredare intervall jämfört med RTO eller RPO, vilket endast gäller vid katastrofala förluster.
Beroenden: Varje tjänst mappar de beroenden (andra tjänster) som krävs för att fungera oavsett hur kritisk och mappad till körning, som endast behövs för återställning eller båda. Om det finns lagringsberoenden mappas en annan data som definierar vad som lagras, och om det till exempel kräver ögonblicksbilder från tidpunkt.
Personal: Som anges i definitionen av en tjänst är det viktigt att känna till var och hur många anställda som kan stödja tjänsten, vilket säkerställer att det inte finns några enskilda felpunkter och om kritiska anställda sprids för att undvika fel genom samlevnad på en enda plats.
Externa leverantörer: Microsoft har en omfattande lista över externa leverantörer och de leverantörer som bedöms vara kritiska mäts för funktioner. Om en tjänst identifieras som beroende jämförs leverantörsfunktionerna med tjänstens behov för att säkerställa att ett avbrott från tredje part inte stör Azure-tjänsterna.
Återställningsklassificering: Det här omdömet är unikt för Azure Business Continuity Management-programmet. Den här klassificeringen mäter flera viktiga element för att skapa en återhämtningspoäng:
- Villighet att redundansväxla: Även om det kan finnas en process kanske det inte är det första valet för kortsiktiga avbrott.
- Automatisering av redundans.
- Automatisering av beslutet att redundansväxla.
Den mest tillförlitliga och kortaste tiden för redundansväxling är en tjänst som är automatiserad och som inte kräver något mänskligt beslut. En automatiserad tjänst använder pulsslagsövervakning eller syntetiska transaktioner för att fastställa att en tjänst är avstängd och för att starta omedelbar reparation.
Återställningsplan och -test: Azure kräver att varje tjänst har en detaljerad återställningsplan och att den planen testas som om tjänsten har misslyckats på grund av ett oåterkalleligt avbrott. Återställningsplanerna måste skrivas så att någon med liknande kunskaper och åtkomst kan slutföra uppgifterna. En skriftlig plan undviker att förlita sig på att ämnesexperter är tillgängliga.
Testning görs på flera sätt, inklusive självtest i en produktionsmiljö eller nära produktionsmiljö, och som en del av detaljnivån för fullständig region i Azure i kanarieregionuppsättningar. Dessa aktiverade regioner är identiska med produktionsregioner men kan inaktiveras utan att påverka dina tjänster. Testning anses vara integrerat eftersom alla tjänster påverkas samtidigt.
Kundaktivering: När du ansvarar för att konfigurera haveriberedskap måste Azure ha vägledning om offentlig dokumentation. För alla sådana tjänster finns länkar till dokumentation och information om processen.
Kontrollera efterlevnaden av affärskontinuitet
När en tjänst har slutfört sin verksamhetskontinuitetshanteringspost måste du skicka den för godkännande. Den tilldelas en erfaren utövare av affärskontinuitetshantering som granskar hela posten för fullständighet och kvalitet. Om posten uppfyller alla krav godkänns den. Om den inte gör det avvisas den med en begäran om omarbetning. Den här processen säkerställer att båda parter är överens om att efterlevnad av affärskontinuitet har uppfyllts och att arbetet endast bekräftas av tjänstägaren. Azures interna gransknings- och efterlevnadsteam gör också regelbunden slumpmässig sampling för att säkerställa att bästa data skickas.
Testning av tjänster
Microsoft och Azure utför omfattande tester för både haveriberedskap och beredskap för tillgänglighetszoner. Tjänsterna är självtestade i en produktions- eller förproduktionsmiljö för att demonstrera oberoende återställning för tjänster som inte är beroende av större plattformsredundans.
För att säkerställa att tjänsterna på liknande sätt kan återställas i ett verkligt scenario med region-down utförs testning av typen "pull-the-plug" i kanariemiljöer som är fullständigt distribuerade regioner som matchar produktionen. Till exempel inaktiveras kluster, rack och energienheter bokstavligen för att simulera ett totalt regionfel.
Under dessa tester använder Azure samma produktionsprocess för identifiering, meddelande, svar och återställning. Inga personer förväntar sig ett detaljtest och tekniker som är beroende av återställning är de normala jourrotationsresurserna. Den här tidpunkten undviker beroende på ämnesexperter som kanske inte är tillgängliga under en faktisk händelse.
I de här testerna ingår tjänster där du ansvarar för att konfigurera haveriberedskap enligt Microsofts offentliga dokumentation. Serviceteam skapar kundliknande instanser för att visa att kundaktiverad haveriberedskap fungerar som förväntat och att instruktionerna är korrekta.
Mer information om certifieringar finns i Microsoft Trust Center och avsnittet om efterlevnad.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för