Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
I söklösningar kan strängar som har komplexa mönster eller specialtecken vara svåra att arbeta med eftersom standardanalysatorn tar bort eller feltolkar meningsfulla delar av ett mönster. Detta resulterar i en dålig sökupplevelse där användarna inte kan hitta den information de förväntar sig. Telefonnummer är ett klassiskt exempel på strängar som är svåra att analysera. De finns i olika format och innehåller specialtecken som standardanalysatorn ignorerar.
Med telefonnummer som ämne använder den här guiden REST API:er i söktjänsten för att hantera problem med mönstrad data med hjälp av en anpassad analysator. Den här metoden kan användas som för telefonnummer eller anpassas för fält med samma egenskaper (mönstrade med specialtecken), till exempel URL:er, e-postmeddelanden, postnummer och datum.
I den här handledningen kommer du att:
- Förstå problemet
- Utveckla en första anpassad analysator för hantering av telefonnummer
- Testa den anpassade analysatorn
- Iterera anpassad analysdesign för att ytterligare förbättra resultaten
Förutsättningar
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
Ladda ned filer
Källkoden för den här självstudien finns i filen custom-analyzer.rest i GitHub-lagringsplatsen Azure-Samples/azure-search-rest-samples.
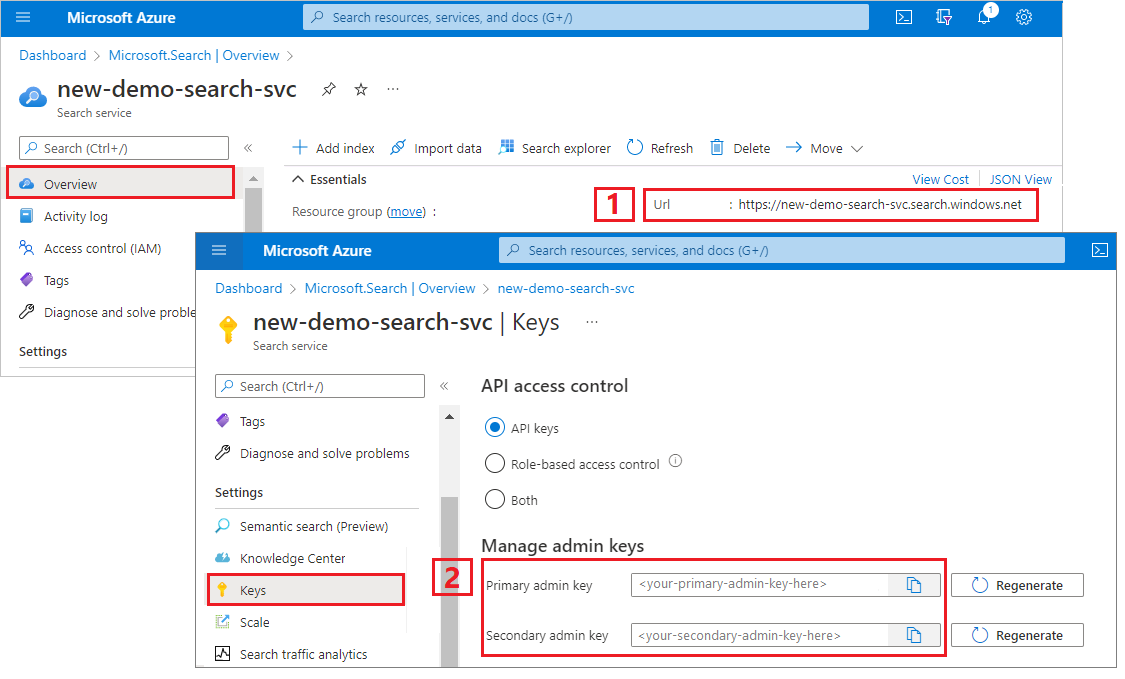
Kopiera en administratörsnyckel och URL
REST-anropen i den här självstudien kräver en slutpunkt för söktjänsten och en api-nyckel för administratörer. Du kan hämta dessa värden från Azure Portal.
Logga in på Azure-portalen och välj din söktjänst.
I den vänstra rutan väljer du Översikt och kopierar slutpunkten. Det bör vara i det här formatet:
https://my-service.search.windows.netI den vänstra rutan väljer du Inställningar>Nycklar och kopierar en administratörsnyckel för fullständiga rättigheter för tjänsten. Det finns två utbytbara administratörsnycklar som tillhandahålls för affärskontinuitet om du behöver rulla över en. Du kan använda antingen nyckel för begäranden för att lägga till, ändra eller ta bort objekt.
Skapa ett första index
Öppna en ny textfil i Visual Studio Code.
Ange variabler till sökslutpunkten och API-nyckeln som du samlade in i föregående avsnitt.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESpara filen med ett
.restfilnamnstillägg.Klistra in följande exempel för att skapa ett litet index med namnet
phone-numbers-indexmed två fält:idochphone_number.### Create a new index POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Du har inte definierat någon analysator än, så
standard.luceneanalysatorn används som standard.Välj Skicka begäran. Du bör ha ett
HTTP/1.1 201 Createdsvar och svarstexten bör innehålla JSON-representationen av indexschemat.Läs in data i indexet med dokument som innehåller olika telefonnummerformat. Det här är dina testdata.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Prova frågor som liknar vad en användare kan skriva. En användare kan till exempel söka efter
(425) 555-0100i valfritt antal format och fortfarande förvänta sig att resultat returneras. Börja med att söka i(425) 555-0100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }Frågan returnerar tre av fyra förväntade resultat men returnerar också två oväntade resultat.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Försök igen utan formatering:
4255550100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }Den här frågan är ännu värre och returnerar bara en av fyra korrekta matchningar.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Om du tycker att de här resultaten är förvirrande är du inte ensam. I nästa avsnitt förklaras varför du får dessa resultat.
Granska hur analysverktyg fungerar
För att förstå dessa sökresultat måste du förstå vad analysatorn gör. Därifrån kan du testa standardanalysatorn med hjälp av Analys-API:et, vilket ger en grund för att utforma en analysator som bättre uppfyller dina behov.
En analysverktyg är en komponent i den fulltextsökmotor som ansvarar för bearbetning av text i frågesträngar och indexerade dokument. Olika analysverktyg manipulerar text på olika sätt beroende på scenariot. I det här scenariot måste vi skapa en analysator som är skräddarsydd för telefonnummer.
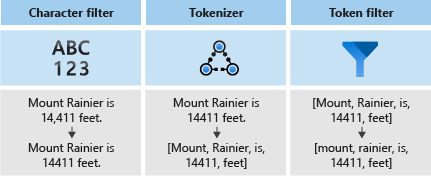
Analysverktyg består av tre komponenter:
- Teckenfilter som tar bort eller ersätter enskilda tecken från indatatexten.
- En tokeniserare som bryter indatatexten i token, som blir nycklar i sökindexet.
- Tokenfilter som ändrar token som skapas av tokenizern.
Följande diagram visar hur dessa tre komponenter fungerar tillsammans för att tokenisera en mening.
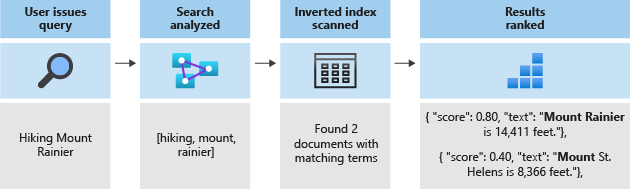
Dessa token lagras sedan i ett inverterat index, vilket möjliggör snabba fulltextsökningar. Ett inverterat index möjliggör fulltextsökning genom att mappa alla unika termer som extraheras under lexikal analys till de dokument där de inträffar. Du kan se ett exempel i följande diagram:

All sökning handlar om att söka efter de termer som lagras i det inverterade indexet. När en användare utfärdar en fråga:
- Frågan parsas och frågetermerna analyseras.
- Det inverterade indexet genomsöks efter dokument med matchande termer.
- Bedömningsalgoritmen rangordnar de hämtade dokumenten.
Om frågetermerna inte matchar termerna i ditt inverterade index returneras inte resultaten. Mer information om hur frågor fungerar finns i Fulltextsökning i Azure AI Search.
Kommentar
Partiella termfrågor är ett viktigt undantag till den här regeln. Till skillnad från vanliga termfrågor kringgår dessa frågor (prefixfråga, jokerteckenfråga och regex-fråga) den lexikala analysprocessen. Partiella termer sänks bara innan de matchas mot termer i indexet. Om en analysator inte har konfigurerats för att stödja dessa typer av frågor får du ofta oväntade resultat eftersom matchande termer inte finns i indexet.
Testa analysverktyg med hjälp av Analys-API:et
Azure AI Search tillhandahåller ett Analys-API som gör att du kan testa analysverktyg för att förstå hur de bearbetar text.
Anropa Analys-API:et med hjälp av följande begäran:
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API:et returnerar de token som extraherats från texten med hjälp av analysatorn som du angav. Lucene-standardanalysatorn delar upp telefonnumret i tre separata token.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Omvänt tokeniseras telefonnumret 4255550100 som formateras utan skiljetecken till en enda token.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Svar:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Tänk på att både frågetermer och indexerade dokument genomgår analys. När du tänker tillbaka på sökresultaten från föregående steg kan du börja se varför dessa resultat returneras.
I den första frågan returneras oväntade telefonnummer eftersom en av deras token, 555, matchade ett av de termer som du sökte i. I den andra frågan returneras bara ett tal eftersom det är den enda posten som har en token som matchar 4255550100.
Skapa en anpassad analys
Nu när du förstår de resultat du ser skapar du en anpassad analysator för att förbättra tokeniseringslogiken.
Målet är att ge intuitiv sökning mot telefonnummer oavsett vilket format frågan eller den indexerade strängen finns i. För att uppnå det här resultatet anger du ett teckenfilter, en tokenizer och ett tokenfilter.
Teckenfilter
Teckenfilter bearbetar text innan den matas in i tokenizern. Vanliga användningsområden för teckenfilter är att filtrera bort HTML-element och ersätta specialtecken.
För telefonnummer vill du ta bort blanksteg och specialtecken eftersom inte alla telefonnummerformat innehåller samma specialtecken och blanksteg.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Filtret tar bort -()+. och blanksteg från indata.
| Indata | Utdata |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokeniserare
Tokenizers delar upp text i token och tar bort vissa tecken, till exempel skiljetecken, längs vägen. I många fall är målet med tokenisering att dela upp en mening i enskilda ord.
I det här scenariot använder du en nyckelordstokeniserare, keyword_v2, för att avbilda telefonnumret som en enda term. Det här är inte det enda sättet att lösa det här problemet, som beskrivs i avsnittet Alternativa metoder .
Nyckelordstokeniserare matar alltid ut samma text som de ges som en enda term.
| Indata | Utdata |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Tokenfilter
Tokenfilter ändrar eller filtrerar bort de token som genereras av tokenizern. En vanlig användning av ett tokenfilter är att omvandla alla tecken till gemener med hjälp av ett tokenfilter. En annan vanlig användning är att filtrera bort stoppord, till exempel the, andeller is.
Även om du inte behöver använda något av dessa filter för det här scenariot använder du ett nGram-tokenfilter för att tillåta partiella sökningar av telefonnummer.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Filtret nGram_v2 token delar upp token i n-gram av en viss storlek baserat på parametrarna minGram ochmaxGram.
För telefonanalysatorn är minGram inställd på 3 eftersom det är den kortaste understrängen som användarna förväntas söka efter.
maxGram är inställd på att se till 20 att alla telefonnummer, även med tillägg, får plats i ett enda n-gram.
Den olyckliga bieffekten av n-gram är att det ibland returneras falska positiva resultat. Du åtgärdar detta i ett senare steg genom att skapa en separat analysator för sökningar som inte innehåller tokenfiltret n-gram.
| Indata | Utdata |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analysator
Med teckenfilter, tokenizer och tokenfilter på plats, är du redo att definiera analysatorn.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Med hjälp av följande indata från analys-API:et är utdata från den anpassade analysatorn följande:
| Indata | Utdata |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Alla token i utdatakolumnen finns i indexet. Om din fråga innehåller något av dessa villkor returneras telefonnumret.
Återskapa med hjälp av den nya analysatorn
Ta bort det aktuella indexet.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2025-09-01 HTTP/1.1 api-key: {{apiKey}}Återskapa indexet med hjälp av den nya analysatorn. Det här indexschemat lägger till en anpassad analysatordefinition och en anpassad analystilldelning i fältet telefonnummer.
### Create a new index POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testa den anpassade analysatorn
När du har återskapat indexet testar du analysatorn med hjälp av följande begäran:
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Nu bör du se samlingen med tokens som är resulterande av telefonnumret.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Ändra den anpassade analysatorn för att hantera falska positiva identifieringar
När du har använt den anpassade analysatorn för att göra exempelfrågor mot indexet bör du se att återkallandet har förbättrats och att alla matchande telefonnummer nu returneras. Men n-gram-tokenfiltret gör också att vissa falska positiva returneras. Detta är en vanlig bieffekt av ett n-gram tokenfilter.
För att förhindra falska positiva identifieringar, skapa en separat analysator för sökfrågor. Den här analysatorn är identisk med den tidigare, förutom att den utelämnar custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
I indexdefinitionen anger du både en indexAnalyzer och en searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Med den här ändringen är du redo. Här följer nästa steg:
Ta bort indexet.
Återskapa indexet när du har lagt till den nya anpassade analysatorn (
phone_analyzer-search) och tilldela analysatorn tillphone-numberfältetssearchAnalyzeregenskap.Ladda om data.
Testa frågorna igen för att kontrollera att sökningen fungerar som förväntat. Om du använder exempelfilen skapar det här steget det tredje indexet med namnet
phone-number-index-3.
Alternativa sätt
Analysatorn som beskrivs i föregående avsnitt är utformad för att maximera flexibiliteten för sökning. Men det gör det på bekostnad av att lagra många potentiellt oviktiga termer i indexet.
I följande exempel visas en alternativ analysator som är effektivare vid tokenisering, men som har nackdelar.
Med en indata av 14255550100kan analysatorn inte logiskt segmentera telefonnumret. Det kan till exempel inte skilja landskoden, 1, från riktnumret, 425. Den här avvikelsen leder till att telefonnumret inte returneras om en användare inte inkluderar någon landskod i sin sökning.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
I följande exempel delas telefonnumret upp i de segment som du normalt förväntar dig att en användare ska söka efter.
| Indata | Utdata |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Beroende på dina krav kan detta vara en effektivare metod för problemet.
Lärdomar
I den här handledningen demonstrerades processen att bygga och testa en anpassad analysator. Du skapade ett index, indexerade data och frågade sedan mot indexet för att se vilka sökresultat som returnerades. Därifrån använde du Analysera API för att se den lexikala analysprocessen i praktiken.
Även om analysatorn som definieras i den här självstudien erbjuder en enkel lösning för sökning mot telefonnummer, kan samma process användas för att skapa en anpassad analysator för alla scenarion som har liknande egenskaper.
Rensa resurser
När du arbetar i din egen prenumeration är det en bra idé att ta bort de resurser som du inte längre behöver i slutet av ett projekt. Resurser som fortsätter att köras kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure Portal med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Nästa steg
Nu när du vet hur du skapar en anpassad analysator kan du ta en titt på alla olika filter, tokenizers och analysverktyg som är tillgängliga för att skapa en omfattande sökupplevelse: