Arkitektur för Service Fabric
Service Fabric skapas med lagerundersystem. Med de här undersystemen kan du skriva program som är:
- Högt tillgänglighet
- Skalbarhet
- Hanterlig
- Testbara
Följande diagram visar de viktigaste delsystemen i Service Fabric.
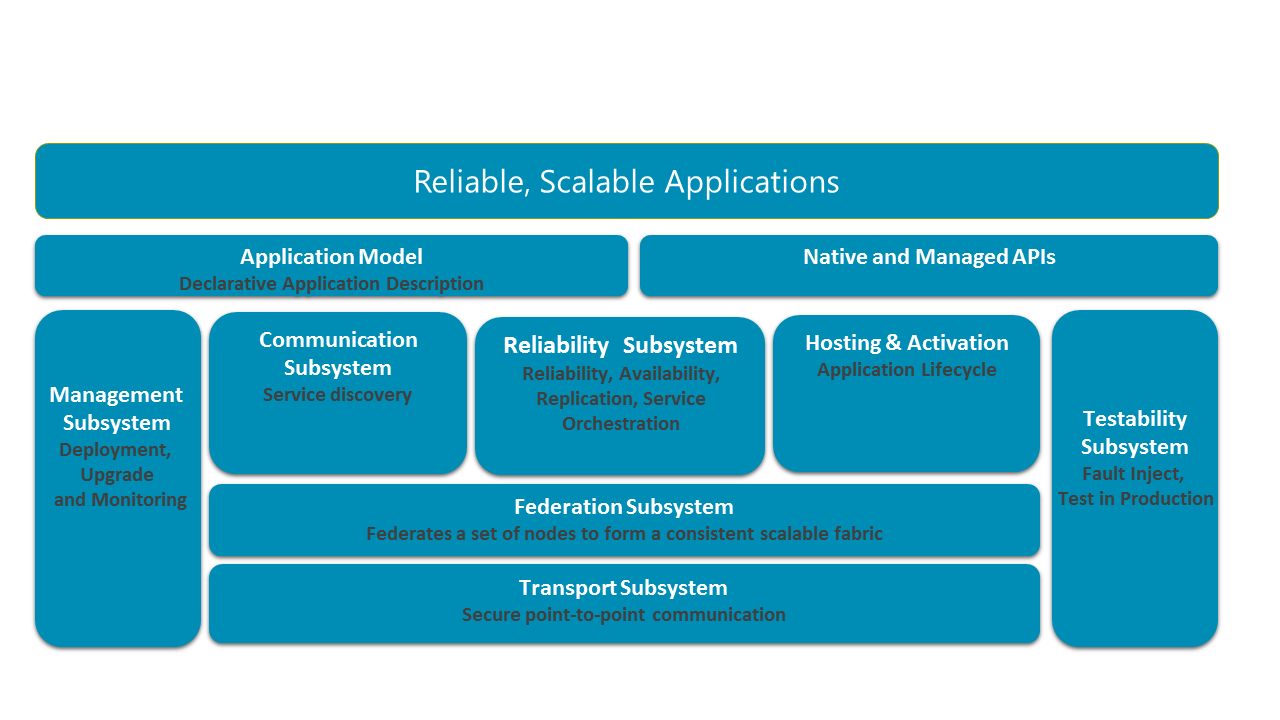
I ett distribuerat system är möjligheten att kommunicera säkert mellan noder i ett kluster avgörande. I basen av stacken finns transportundersystemet, som ger säker kommunikation mellan noder. Ovanför transportundersystemet ligger federationsundersystemet, som klustrade de olika noderna till en enda entitet (namngivna kluster) så att Service Fabric kan identifiera fel, utföra val av ledare och tillhandahålla konsekvent routning. Undersystemet för tillförlitlighet, som ligger ovanpå federationsundersystemet, ansvarar för Service Fabric-tjänsternas tillförlitlighet genom mekanismer som replikering, resurshantering och redundans. Federationsundersystemet ligger också till grund för värd- och aktiveringsundersystemet, som hanterar livscykeln för ett program på en enda nod. Hanteringsundersystemet hanterar livscykeln för program och tjänster. Undersystemet för testbarhet hjälper programutvecklare att testa sina tjänster genom simulerade fel före och efter distribution av program och tjänster till produktionsmiljöer. Service Fabric ger möjlighet att lösa tjänstplatser via dess kommunikationsundersystem. De programprogrammeringsmodeller som exponeras för utvecklare läggs ovanpå dessa undersystem tillsammans med programmodellen för att aktivera verktyg.
Transportundersystem
Transportundersystemet implementerar en punkt-till-punkt-kommunikationskanal för datagram. Den här kanalen används för kommunikation i Service Fabric-kluster och kommunikation mellan Service Fabric-klustret och klienterna. Den stöder kommunikationsmönster för enkelriktad och begärandesvar, vilket utgör grunden för implementering av sändning och multicast i federationsskiktet. Transportundersystemet skyddar kommunikationen med hjälp av X509-certifikat eller Windows-säkerhet. Det här undersystemet används internt av Service Fabric och är inte direkt tillgängligt för utvecklare för programprogrammering.
Federationsundersystem
För att kunna resonera om en uppsättning noder i ett distribuerat system måste du ha en konsekvent vy över systemet. Federationsundersystemet använder kommunikationspri primitiverna som tillhandahålls av transportundersystemet och syr de olika noderna i ett enda enhetligt kluster som det kan resonera kring. Den tillhandahåller de distribuerade systemprimitiver som behövs av de andra undersystemen – felidentifiering, val av ledare och konsekvent routning. Federationsundersystemet bygger på distribuerade hash-tabeller med ett 128-bitars tokenutrymme. Undersystemet skapar en ringtopologi över noderna, där varje nod i ringen allokeras en delmängd av tokenutrymmet för ägarskap. För felidentifiering använder lagret en leasingmekanism baserad på hjärtslag och skiljeförfarande. Federationsundersystemet garanterar också genom invecklade anslutnings- och avgångsprotokoll att endast en enskild ägare av en token finns när som helst. Detta ger val av ledare och konsekventa routningsgarantier.
Undersystem för tillförlitlighet
Undersystemet för tillförlitlighet ger en mekanism för att göra tillståndet för en Service Fabric-tjänst mycket tillgängligt med hjälp av Replicator, Failover Manager och Resource Balancer.
- Replikatorn ser till att tillståndsändringar i den primära tjänstrepliken automatiskt replikeras till sekundära repliker, vilket ger konsekvens mellan de primära och sekundära replikerna i en tjänstreplikuppsättning. Replikatorn ansvarar för kvorumhantering mellan replikerna i replikuppsättningen. Den interagerar med redundansenheten för att hämta listan över åtgärder som ska replikeras, och omkonfigurationsagenten tillhandahåller konfigurationen av replikuppsättningen. Den konfigurationen anger vilka repliker som åtgärderna måste replikeras. Service Fabric tillhandahåller en standardreplikator med namnet Fabric Replicator, som kan användas av API:et för programmeringsmodellen för att göra tjänsttillståndet mycket tillgängligt och tillförlitligt.
- Redundanshanteraren ser till att när noder läggs till i eller tas bort från klustret omfördelas belastningen automatiskt över de tillgängliga noderna. Om en nod i klustret misslyckas konfigurerar klustret automatiskt om tjänstreplikerna för att upprätthålla tillgängligheten.
- Resource Manager placerar tjänstrepliker över feldomäner i klustret och ser till att alla redundansenheter fungerar. Resource Manager balanserar även tjänstresurser över den underliggande delade poolen med klusternoder för att uppnå optimal enhetlig belastningsfördelning.
Undersystem för hantering
Hanteringsundersystemet tillhandahåller tjänst- och programlivscykelhantering från slutpunkt till slutpunkt. Med PowerShell-cmdletar och administrativa API:er kan du etablera, distribuera, korrigera, uppgradera och avetablera program utan förlust av tillgänglighet. Hanteringsundersystemet utför detta via följande tjänster.
- Klusterhanterare: Det här är den primära tjänsten som interagerar med Redundanshanteraren från tillförlitlighet för att placera programmen på noderna baserat på tjänstplaceringsbegränsningarna. Resource Manager i redundansundersystemet säkerställer att begränsningarna aldrig bryts. Klusterhanteraren hanterar livscykeln för programmen från etablering till avetablering. Den integreras med hälsohanteraren för att säkerställa att programtillgängligheten inte går förlorad ur ett semantiskt hälsoperspektiv under uppgraderingar.
- Health Manager: Den här tjänsten möjliggör hälsoövervakning av program, tjänster och klusterentiteter. Klusterentiteter (till exempel noder, tjänstpartitioner och repliker) kan rapportera hälsoinformation som sedan aggregeras till det centraliserade hälsoarkivet. Den här hälsoinformationen ger en övergripande hälsoögonblicksbild för tidpunkten för tjänster och noder som distribueras över flera noder i klustret, så att du kan vidta nödvändiga korrigerande åtgärder. Med API:er för hälsofrågor kan du köra frågor mot hälsohändelserna som rapporteras till undersystemet hälsa. API:erna för hälsofråga returnerar rådata som lagras i hälsolagret eller de aggregerade, tolkade hälsodata för en specifik klusterentitet.
- Image Store: Den här tjänsten tillhandahåller lagring och distribution av programbinärfilerna. Den här tjänsten tillhandahåller ett enkelt distribuerat filarkiv där programmen laddas upp till och laddas ned från.
Värdundersystem
Klusterhanteraren informerar värdundersystemet (körs på varje nod) vilka tjänster som krävs för att hantera en viss nod. Värdundersystemet hanterar sedan programmets livscykel på noden. Den interagerar med tillförlitlighets- och hälsokomponenterna för att säkerställa att replikerna är korrekt placerade och felfria.
Undersystem för kommunikation
Det här undersystemet tillhandahåller tillförlitliga meddelanden i klustret och tjänstidentifieringen via namngivningstjänsten. Namngivningstjänsten löser tjänstnamn till en plats i klustret och gör det möjligt för användare att hantera tjänstnamn och egenskaper. Med hjälp av namngivningstjänsten kan klienter kommunicera säkert med valfri nod i klustret för att matcha ett tjänstnamn och hämta tjänstmetadata. Med hjälp av ett enkelt API för namngivningsklient kan användare av Service Fabric utveckla tjänster och klienter som kan matcha den aktuella nätverksplatsen trots noddynamik eller storleksändring av klustret.
Undersystem för testbarhet
Testbarhet är en uppsättning verktyg som är särskilt utformade för testning av tjänster som bygger på Service Fabric. Med verktygen kan en utvecklare enkelt inducera meningsfulla fel och köra testscenarier för att träna och verifiera de många tillstånd och övergångar som en tjänst kommer att uppleva under hela sin livslängd, allt på ett kontrollerat och säkert sätt. Testbarhet ger också en mekanism för att köra längre tester som kan iterera genom olika möjliga fel utan att förlora tillgängligheten. Detta ger dig en test-in-production-miljö.