Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Service Fabric gör det enkelt att skapa skalbara program genom att hantera tjänster, partitioner och repliker på noderna i ett kluster. Att köra många arbetsbelastningar på samma maskinvara möjliggör maximal resursanvändning, men ger också flexibilitet när det gäller hur du väljer att skala dina arbetsbelastningar. Den här Channel 9-videon beskriver hur du kan skapa skalbara mikrotjänstprogram:
Skalning i Service Fabric utförs på flera olika sätt:
- Skala genom att skapa eller ta bort tillståndslösa tjänstinstanser
- Skala genom att skapa eller ta bort nya namngivna tjänster
- Skala genom att skapa eller ta bort nya namngivna programinstanser
- Skalning med partitionerade tjänster
- Skala genom att lägga till och ta bort noder från klustret
- Skalning med hjälp av Kluster resource manager-mått
Skala genom att skapa eller ta bort tillståndslösa tjänstinstanser
Ett av de enklaste sätten att skala i Service Fabric fungerar med tillståndslösa tjänster. När du skapar en tillståndslös tjänst får du en chans att definiera en InstanceCount. InstanceCount definierar hur många kopior som körs av tjänstens kod som skapas när tjänsten startas. Anta till exempel att det finns 100 noder i klustret. Anta också att en tjänst skapas med InstanceCount 10. Under körningen kan de 10 kopior som körs av koden bli för upptagna (eller så kan de inte vara tillräckligt upptagna). Ett sätt att skala den arbetsbelastningen är att ändra antalet instanser. Till exempel kan någon del av övervaknings- eller hanteringskoden ändra det befintliga antalet instanser till 50 eller till 5, beroende på om arbetsbelastningen behöver skalas in eller ut baserat på belastningen.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Använda dynamiskt instansantal
Specifikt för tillståndslösa tjänster erbjuder Service Fabric ett automatiskt sätt att ändra antalet instanser. På så sätt kan tjänsten skalas dynamiskt med det antal noder som är tillgängliga. Sättet att välja det här beteendet är att ange antalet instanser = -1. InstanceCount = -1 är en instruktion för Service Fabric som säger "Kör den här tillståndslösa tjänsten på varje nod". Om antalet noder ändras ändrar Service Fabric automatiskt antalet instanser så att det matchar, vilket säkerställer att tjänsten körs på alla giltiga noder.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Skala genom att skapa eller ta bort nya namngivna tjänster
En namngiven tjänstinstans är en specifik instans av en tjänsttyp (se Livscykel för Service Fabric-program) i någon namngiven programinstans i klustret.
Nya namngivna tjänstinstanser kan skapas (eller tas bort) när tjänsterna blir mer eller mindre upptagna. Detta gör att begäranden kan spridas över fler tjänstinstanser, vilket vanligtvis gör att belastningen på befintliga tjänster minskar. När du skapar tjänster placerar Service Fabric Cluster Resource Manager tjänsterna i klustret på ett distribuerat sätt. De exakta besluten styrs av måtten i klustret och andra placeringsregler. Tjänster kan skapas på flera olika sätt, men de vanligaste är antingen genom administrativa åtgärder som någon som anropar New-ServiceFabricServiceeller genom kodanrop CreateServiceAsync. CreateServiceAsync kan till och med anropas inifrån andra tjänster som körs i klustret.
Att skapa tjänster dynamiskt kan användas i alla typer av scenarier och är ett vanligt mönster. Tänk dig till exempel en tillståndskänslig tjänst som representerar ett visst arbetsflöde. Samtal som representerar arbete kommer att visas för den här tjänsten, och den här tjänsten kommer att utföra stegen i arbetsflödet och registrera förloppet.
Hur skulle du göra den här tjänstskalan? Tjänsten kan vara flera klientorganisationer i någon form och acceptera anrop och starta steg för många olika instanser av samma arbetsflöde samtidigt. Det kan dock göra koden mer komplex eftersom den nu måste oroa sig för många olika instanser av samma arbetsflöde, alla i olika skeden och från olika kunder. Att hantera flera arbetsflöden samtidigt löser inte heller skalningsproblemet. Det beror på att den här tjänsten någon gång förbrukar för många resurser för att få plats på en viss dator. Många tjänster som inte har skapats för det här mönstret i första hand upplever också svårigheter på grund av en del inneboende flaskhalsar eller långsammare kod. Dessa typer av problem gör att tjänsten inte fungerar lika bra när antalet samtidiga arbetsflöden som den spårar blir större.
En lösning är att skapa en instans av den här tjänsten för varje annan instans av arbetsflödet som du vill spåra. Det här är ett bra mönster och fungerar oavsett om tjänsten är tillståndslös eller tillståndskänslig. För att det här mönstret ska fungera finns det vanligtvis en annan tjänst som fungerar som en "Workload Manager-tjänst". Tjänstens uppgift är att ta emot begäranden och dirigera dessa begäranden till andra tjänster. Chefen kan dynamiskt skapa en instans av arbetsbelastningstjänsten när den tar emot meddelandet och sedan skicka begäranden till dessa tjänster. Chefstjänsten kan också ta emot återanrop när en viss arbetsflödestjänst slutför sitt jobb. När chefen tar emot dessa återanrop kan den ta bort den instansen av arbetsflödestjänsten eller lämna den om fler anrop förväntas.
Avancerade versioner av den här typen av chef kan till och med skapa pooler av de tjänster som hanteras. Poolen hjälper till att se till att när en ny begäran kommer in behöver den inte vänta tills tjänsten har startats. I stället kan chefen bara välja en arbetsflödestjänst som för närvarande inte är upptagen från poolen eller dirigera slumpmässigt. Att hålla en pool med tjänster tillgängliga gör det snabbare att hantera nya begäranden, eftersom det är mindre troligt att begäran måste vänta tills en ny tjänst har spunnits upp. Det går snabbt att skapa nya tjänster, men inte kostnadsfritt eller omedelbart. Poolen hjälper till att minimera hur lång tid begäran måste vänta innan den tas i bruk. Du ser ofta det här hanteraren och poolmönstret när svarstiderna är som mest viktiga. Att köa begäran och skapa tjänsten i bakgrunden och sedan skicka den vidare är också ett populärt hanteringsmönster, liksom att skapa och ta bort tjänster baserat på viss spårning av mängden arbete som tjänsten för närvarande har väntande.
Skala genom att skapa eller ta bort nya namngivna programinstanser
Att skapa och ta bort hela programinstanser liknar mönstret för att skapa och ta bort tjänster. För det här mönstret finns det någon chefstjänst som fattar beslutet baserat på de begäranden som visas och den information som den tar emot från de andra tjänsterna i klustret.
När ska du skapa en ny namngiven programinstans i stället för att skapa nya namngivna tjänstinstanser i ett befintligt program? Det finns några fall:
- Den nya programinstansen är till för en kund vars kod måste köras under vissa specifika identitets- eller säkerhetsinställningar.
- Med Service Fabric kan du definiera olika kodpaket som ska köras under specifika identiteter. För att kunna starta samma kodpaket under olika identiteter måste aktiveringarna ske i olika programinstanser. Tänk dig ett fall där du har distribuerat en befintlig kunds arbetsbelastningar. Dessa kan köras under en viss identitet så att du kan övervaka och kontrollera deras åtkomst till andra resurser, till exempel fjärrdatabaser eller andra system. I det här fallet, när en ny kund registrerar sig, vill du förmodligen inte aktivera koden i samma kontext (processutrymme). Även om du kan gör detta det svårare för din tjänstkod att agera inom ramen för en viss identitet. Du måste vanligtvis ha mer kod för säkerhet, isolering och identitetshantering. I stället för att använda olika namngivna tjänstinstanser i samma programinstans och därmed samma processutrymme kan du använda olika namngivna Service Fabric-programinstanser. Det gör det enklare att definiera olika identitetskontexter.
- Den nya programinstansen fungerar också som ett sätt att konfigurera
- Som standard körs alla namngivna tjänstinstanser av en viss tjänsttyp i en programinstans i samma process på en viss nod. Det innebär att även om du kan konfigurera varje tjänstinstans på olika sätt är det komplicerat att göra det. Tjänsterna måste ha en token som de använder för att leta upp konfigurationen i ett konfigurationspaket. Vanligtvis är detta bara tjänstens namn. Detta fungerar bra, men det kopplar konfigurationen till namnen på de enskilda namngivna tjänstinstanserna i den programinstansen. Det kan vara förvirrande och svårt att hantera eftersom konfigurationen normalt är en artefakt för designtid med specifika värden för programinstansen. Att skapa fler tjänster innebär alltid fler programuppgraderingar för att ändra informationen i konfigurationspaketen eller för att distribuera nya så att de nya tjänsterna kan leta upp sin specifika information. Det är ofta enklare att skapa en helt ny namngiven programinstans. Sedan kan du använda programparametrarna för att ange vilken konfiguration som krävs för tjänsterna. På så sätt kan alla tjänster som skapas i den namngivna programinstansen ärva vissa konfigurationsinställningar. I stället för att till exempel ha en enda konfigurationsfil med inställningarna och anpassningarna för varje kund, till exempel hemligheter eller resursbegränsningar per kund, skulle du i stället ha en annan programinstans för varje kund med dessa inställningar åsidosatta.
- Det nya programmet fungerar som en uppgraderingsgräns
- I Service Fabric fungerar olika namngivna programinstanser som gränser för uppgradering. En uppgradering av en namngiven programinstans påverkar inte koden som en annan namngiven programinstans kör. De olika programmen kommer att köra olika versioner av samma kod på samma noder. Detta kan vara en faktor när du behöver fatta ett skalningsbeslut eftersom du kan välja om den nya koden ska följa samma uppgraderingar som en annan tjänst eller inte. Anta till exempel att ett samtal kommer till chefstjänsten som ansvarar för att skala en viss kunds arbetsbelastningar genom att skapa och ta bort tjänster dynamiskt. I det här fallet gäller dock anropet för en arbetsbelastning som är associerad med en ny kund. De flesta kunder gillar att isoleras från varandra, inte bara av säkerhets- och konfigurationsskäl som angavs tidigare, utan för att det ger mer flexibilitet när det gäller att köra specifika versioner av programvaran och välja när de uppgraderas. Du kan också skapa en ny programinstans och skapa tjänsten där bara för att ytterligare partitionera mängden tjänster som en uppgradering kommer att beröra. Separata programinstanser ger större kornighet vid programuppgraderingar och aktiverar även A/B-testning och blå/gröna distributioner.
- Den befintliga programinstansen är full
- I Service Fabric är programkapacitet ett begrepp som du kan använda för att styra mängden resurser som är tillgängliga för vissa programinstanser. Du kan till exempel bestämma att en viss tjänst måste ha en annan instans skapad för att kunna skalas. Den här programinstansen har dock ingen kapacitet för ett visst mått. Om den här specifika kunden eller arbetsbelastningen fortfarande ska beviljas fler resurser kan du antingen öka den befintliga kapaciteten för programmet eller skapa ett nytt program.
Skalning på partitionsnivå
Service Fabric stöder partitionering. Partitionering delar upp en tjänst i flera logiska och fysiska avsnitt, som var och en fungerar oberoende av varandra. Detta är användbart med tillståndskänsliga tjänster, eftersom ingen uppsättning repliker behöver hantera alla anrop och manipulera hela tillståndet samtidigt. Partitioneringsöversikten innehåller information om vilka typer av partitioneringsscheman som stöds. Replikerna för varje partition är spridda över noderna i ett kluster, distribuerar tjänstens belastning och säkerställer att varken tjänsten som helhet eller någon partition har en enda felpunkt.
Överväg en tjänst som använder ett intervallpartitioneringsschema med en låg nyckel på 0, en högnyckel på 99 och ett partitionsantal på 4. I ett kluster med tre noder kan tjänsten läggas ut med fyra repliker som delar resurserna på varje nod enligt följande:
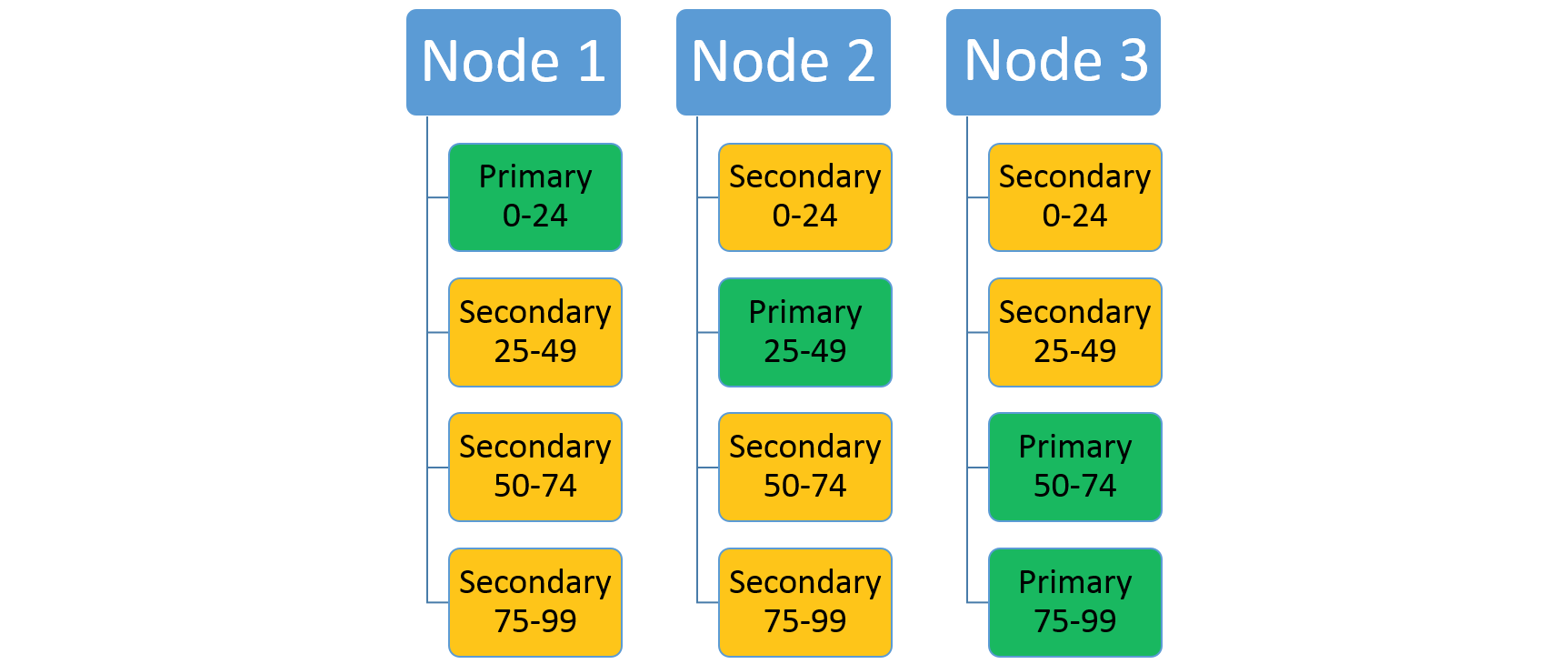
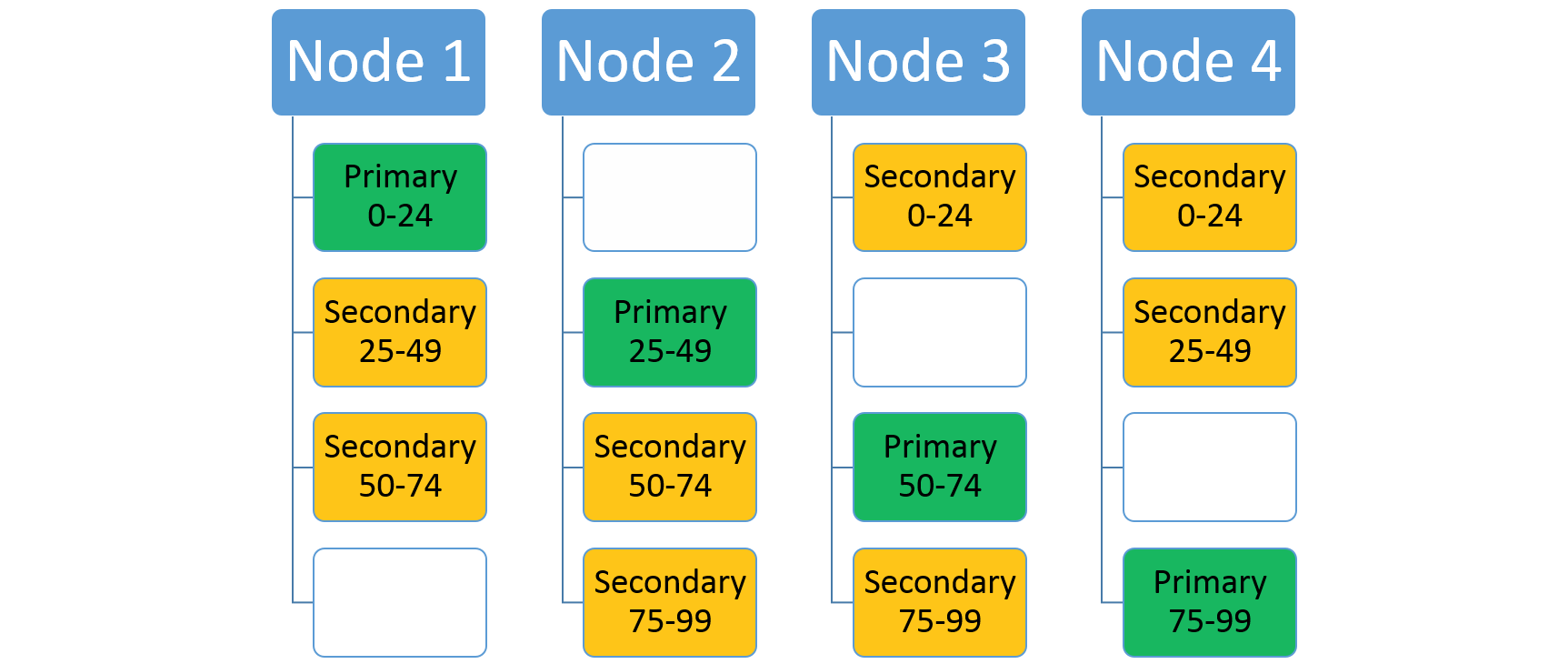
Om du ökar antalet noder flyttar Service Fabric några av de befintliga replikerna dit. Anta till exempel att antalet noder ökar till fyra och att replikerna distribueras om. Nu har tjänsten tre repliker som körs på varje nod, som var och en tillhör olika partitioner. Detta ger bättre resursanvändning eftersom den nya noden inte är kall. Vanligtvis förbättrar det också prestanda eftersom varje tjänst har fler tillgängliga resurser.
Skalning med hjälp av Service Fabric Cluster Resource Manager och mått
Mått är hur tjänster uttrycker sin resursförbrukning till Service Fabric. Med hjälp av mått får klusterresurshanteraren möjlighet att omorganisera och optimera klustrets layout. Det kan till exempel finnas gott om resurser i klustret, men de kanske inte allokeras till de tjänster som för närvarande arbetar. Med hjälp av mått kan Klusterresurshanteraren omorganisera klustret för att säkerställa att tjänsterna har åtkomst till de tillgängliga resurserna.
Skala genom att lägga till och ta bort noder från klustret
Ett annat alternativ för skalning med Service Fabric är att ändra storleken på klustret. Om du ändrar storleken på klustret innebär det att du lägger till eller tar bort noder för en eller flera av nodtyperna i klustret. Tänk dig till exempel ett fall där alla noder i klustret är heta. Det innebär att klustrets resurser nästan alla förbrukas. I det här fallet är det bästa sättet att skala att lägga till fler noder i klustret. När de nya noderna ansluter till klustret flyttar Service Fabric Cluster Resource Manager tjänster till dem, vilket resulterar i mindre total belastning på de befintliga noderna. För tillståndslösa tjänster med instansantal = -1 skapas automatiskt fler tjänstinstanser. Detta gör att vissa anrop kan flyttas från de befintliga noderna till de nya noderna.
Mer information finns i klusterskalning.
Välja en plattform
På grund av implementeringsskillnader mellan operativsystem kan valet av att använda Service Fabric med Windows eller Linux vara en viktig del av skalningen av ditt program. En möjlig barriär är hur stegvis loggning utförs. Service Fabric i Windows använder en kerneldrivrutin för en logg per dator som delas mellan tillståndskänsliga tjänstrepliker. Den här loggen väger cirka 8 GB. Linux använder å andra sidan en mellanlagringslogg på 256 MB för varje replik, vilket gör den mindre idealisk för program som vill maximera antalet enkla tjänstrepliker som körs på en viss nod. Dessa skillnader i tillfälliga lagringskrav kan potentiellt ligga till grund för den önskade plattformen för Distribution av Service Fabric-kluster.
Färdigställa allt
Låt oss ta alla idéer som vi har diskuterat här och gå igenom ett exempel. Tänk på följande tjänst: du försöker skapa en tjänst som fungerar som en adressbok och håller fast vid namn och kontaktinformation.
Direkt har du en massa frågor som rör skalning: Hur många användare kommer du att ha? Hur många kontakter kommer varje användare att lagra? Att försöka lista ut allt detta när du står upp din tjänst för första gången är svårt. Anta att du skulle gå med en enda statisk tjänst med ett specifikt partitionsantal. Konsekvenserna av att välja fel partitionsantal kan orsaka skalningsproblem senare. Även om du väljer rätt antal kanske du inte har all information du behöver. Du måste till exempel också bestämma storleken på klustret i förväg, både när det gäller antalet noder och deras storlekar. Det är vanligtvis svårt att förutsäga hur många resurser en tjänst kommer att förbruka under sin livslängd. Det kan också vara svårt att veta i förväg vilket trafikmönster som tjänsten faktiskt ser. Till exempel kanske folk lägger till och tar bort sina kontakter först på morgonen, eller så är det kanske jämnt fördelat under dagen. Baserat på detta kan du behöva skala ut och in dynamiskt. Du kanske kan lära dig att förutsäga när du behöver skala ut och in, men hur som helst måste du förmodligen reagera på att din tjänst ändrar resursförbrukningen. Detta kan innebära att ändra storleken på klustret för att tillhandahålla fler resurser när det inte räcker med att organisera om användningen av befintliga resurser.
Men varför ens försöka välja ut ett enda partitionsschema för alla användare? Varför begränsa dig till en tjänst och ett statiskt kluster? Den verkliga situationen är vanligtvis mer dynamisk.
När du skapar för skalning bör du överväga följande dynamiska mönster. Du kan behöva anpassa den efter din situation:
- I stället för att försöka välja ett partitioneringsschema för alla i förväg skapar du en "manager-tjänst".
- Jobbet för chefstjänsten är att titta på kundinformation när de registrerar sig för din tjänst. Beroende på den informationen skapar hanteringstjänsten sedan en instans av din faktiska kontaktlagringstjänst bara för kunden. Om de kräver viss konfiguration, isolering eller uppgraderingar kan du också bestämma dig för att starta en programinstans för den här kunden.
Det här mönstret för dynamiskt skapande har många fördelar:
- Du försöker inte gissa rätt partitionsantal för alla användare i förväg eller skapa en enda tjänst som är oändligt skalbar helt på egen hand.
- Olika användare behöver inte ha samma partitionsantal, antal repliker, placeringsbegränsningar, mått, standardinläsningar, tjänstnamn, DNS-inställningar eller någon av de andra egenskaper som anges på tjänst- eller programnivå.
- Du får ytterligare datasegmentering. Varje kund har en egen kopia av tjänsten
- Varje kundtjänst kan konfigureras på olika sätt och beviljas fler eller färre resurser, med fler eller färre partitioner eller repliker efter behov baserat på deras förväntade skala.
- Anta till exempel att kunden betalade för "Gold"-nivån – de kan få fler repliker eller större partitionsantal och potentiellt resurser som är dedikerade till deras tjänster via mått och programkapaciteter.
- Eller säg att de tillhandahöll information som anger hur många kontakter de behövde var "Liten" - de skulle bara få några partitioner, eller till och med kunna placeras i en delad tjänstpool med andra kunder.
- Varje kundtjänst kan konfigureras på olika sätt och beviljas fler eller färre resurser, med fler eller färre partitioner eller repliker efter behov baserat på deras förväntade skala.
- Du kör inte en massa tjänstinstanser eller repliker medan du väntar på att kunderna ska dyka upp
- Om en kund lämnar tjänsten är det lika enkelt att ta bort informationen från din tjänst som att låta chefen ta bort den tjänst eller det program som den skapade.
Nästa steg
Mer information om Service Fabric-begrepp finns i följande artiklar: